Barking up the right tree: an approach to search over molecule synthesis DAGs
化学反応を陽に学習した生成物予測器を使った化合物生成
4年前の論文ですが動かすのに難儀したので色々メモ書きしておきます。
環境
Bradshawさんらが提案しているDoG-AE/DoG-Genを動かすための環境と、生成物予測のためのMolecular Transformer (MT) を動かすための環境がいります。ymlがリポジトリに提供されていますが、2024年5月時点で、GPUがRTX A4000だとそのままenv createしても動きませんでした。結局、以下の環境でDoG-AE/DoG-GenはGPUが動きましたが、MTの方は色々やったけど無理で、大昔にMTを動かしたときに作った古のpython3.5環境でやってみると強制的にCPUモードに変更されますがなんやかんや動くようになりました。mtの方はGPUが動かなかったのでcuda_toolkitとか入ってますが意味なさげ...
name: dogae
channels:
- rdkit
- pytorch
- defaults
- conda-forge
dependencies:
- python=3.7
- pip=20.0.2
- numpy=1.18.1
- cudatoolkit=10.1
- ignite=0.3.0
- ipython=7.11.1
- jsonschema=3.2.0
- jupyter=1.0.0
- jupyterlab=1.2.6
- networkx=2.4
- pytorch=1.4.0
- rdkit=2020.03.1.0
- torchtext=0.5.0
- tqdm=4.42.0
- matplotlib
- pytest=6.1.2
- pip:
- protobuf==3.14
- docopt==0.6.2
- keras==2.3.1
- fcd==1.1
- h5py==2.10.0
- guacamol==0.5.2
- ipdb==0.13.2
- multiset==2.1.1
- tabulate==0.8.7
- tensorboard==2.1.0
- tensorflow==2.0
- scikit-learn==0.22
- jug==2.0.0
- lazy==1.4
- git+https://github.com/PatWalters/rd_filters.git@451d5cf92ac630df11851bce2dde98609967e5b4
name: mt
channels:
- rdkit
- pytorch
- conda-forge
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- blas=1.0=mkl
- bzip2=1.0.8=h7b6447c_0
- ca-certificates=2022.12.7=ha878542_0
- cairo=1.16.0=hb05425b_3
- certifi=2020.6.20=pyhd3eb1b0_3
- colorama=0.4.4=pyhd3eb1b0_0
- cudatoolkit=10.2.89=hfd86e86_1
- expat=2.4.9=h6a678d5_0
- fontconfig=2.14.1=h52c9d5c_1
- freetype=2.12.1=h4a9f257_0
- future=0.16.0=py35_2
- glib=2.69.1=h4ff587b_1
- icu=58.2=he6710b0_3
- intel-openmp=2022.1.0=h9e868ea_3769
- jpeg=9e=h7f8727e_0
- lerc=3.0=h295c915_0
- libboost=1.65.1=habcd387_4
- libdeflate=1.8=h7f8727e_5
- libffi=3.3=he6710b0_2
- libgcc-ng=11.2.0=h1234567_1
- libgfortran-ng=7.5.0=ha8ba4b0_17
- libgfortran4=7.5.0=ha8ba4b0_17
- libgomp=11.2.0=h1234567_1
- libpng=1.6.37=hbc83047_0
- libstdcxx-ng=11.2.0=h1234567_1
- libtiff=4.4.0=hecacb30_2
- libuuid=1.41.5=h5eee18b_0
- libwebp-base=1.2.4=h5eee18b_0
- libxcb=1.15=h7f8727e_0
- libxml2=2.9.14=h74e7548_0
- lz4-c=1.9.4=h6a678d5_0
- mkl=2022.1.0=hc2b9512_224
- ncurses=6.3=h5eee18b_3
- ninja=1.10.2=h06a4308_5
- ninja-base=1.10.2=hd09550d_5
- numpy=1.14.2=py35hdbf6ddf_0
- olefile=0.46=py35_0
- openssl=1.1.1s=h7f8727e_0
- pandas=0.23.4=py35h04863e7_0
- pcre=8.45=h295c915_0
- pillow=5.2.0=py35heded4f4_0
- pixman=0.40.0=h7f8727e_1
- py-boost=1.65.1=py35hf484d3e_4
- python=3.5.6=h12debd9_1
- python-dateutil=2.8.2=pyhd3eb1b0_0
- pytorch=1.5.1=py3.5_cuda10.2.89_cudnn7.6.5_0
- pytz=2021.3=pyhd3eb1b0_0
- rdkit=2018.03.4.0=py35h71b666b_1
- readline=8.2=h5eee18b_0
- setuptools=40.2.0=py35_0
- six=1.16.0=pyhd3eb1b0_1
- sqlite=3.40.0=h5082296_0
- tk=8.6.12=h1ccaba5_0
- torchvision=0.6.1=py35_cu102
- tqdm=4.63.0=pyhd3eb1b0_0
- wheel=0.37.1=pyhd3eb1b0_0
- xz=5.2.8=h5eee18b_0
- zlib=1.2.13=h5eee18b_0
- zstd=1.5.2=ha4553b6_0
- pip:
- chardet==4.0.0
- click==7.1.2
- flask==1.1.4
- idna==2.10
- importlib-resources==3.2.1
- itsdangerous==1.1.0
- jinja2==2.11.3
- markupsafe==1.1.1
- pip==20.3.4
- requests==2.25.1
- torchtext==0.3.1
- urllib3==1.26.9
- werkzeug==1.0.1
- zipp==1.2.0
あとはリポジトリに書いてある通りset_up.shを実行してから DoG-AEなりDoG-Genを学習します。
(optional) 学習
DoG-AEとDoG-Genは独立しています。最初論文を読んだときはDoG-AEで学習したエンコーダ・デコーダのうちデコーダだけを取り出してz=0を入力し、評価関数を使ってファインチューニングするのがDoG-Genかと思っていました。実際にはそうではなく、単にz=0を使ってDoG-AEのデコーダをゼロから学習するのがDoG-Genです。DoG-AEを使いたければ自分で300エポックくらいまわさないといけませんが、DoG-Genはパラメータが最初から入っているのでわりとすぐに使えます。パスはscripts/dog_gen/chkpts/です。
評価関数の設定
syn_dags/script_utils/opt_utils.py に評価関数のコードがあります。QEDのが分かりやすいので、それを真似して自分用に書き換えて、下の方の get_task(name_of_task: str):に自分で定義した関数を付け加えます。
ファインチューニング
パラメータのパスと自分で名付けたtask_nameを指定してコマンドを実行します。
python scripts/dog_gen/run_hillclimbing.py scripts/dog_gen/chkpts/doggen_weights.pth.pick task_name
mtの環境で立てたサーバが(私はCPUしか動きませんでしたが)ちゃんと動いていればこれでファインチューニングできます。ファインチューニングの回数はsyn_dags/script_utils/doggen_utils.pyで指定できます。デフォルトは2です。
結果の確認
scripts/dog_gen/hc_results/ に、生成された化合物の中で評価関数の値top100のSMILESのファイル、reaction tree付きの生成された全ての化合物のpickleが保存されます。
top100のSMILESだけ見てもしょうがないので全部入ってるpickleの方を見ます。中身はOrderedDictになっています。
with open('./scripts/dog_gen/hc_results/hoge.pick', 'rb') as f:
mol_dict = pickle.load(f)
f.close()
print(f'len of seen_molecules: {len(mol_dict["seen_molecules"])}')
print(f'len of sorted_tts: {len(mol_dict["sorted_tts"])}')
print(f"task name: {mol_dict['opt_name']}")
seen_moleculesは、生成されたreaction treeのrootの化合物であり、評価関数で評価された化合物です。
sorted_tts (sorted tuple trees?) の方がややこしく、2分子の1段階の反応であるとすると、以下の例のようなタプルの入れ子構造になっています。
(生成物1, [(反応物1, []), (反応物2, [])])
さらに反応物1が2分子の反応で合成されるような例だと、
(生成物1, [(反応物1, [(反応物の反応物1, []), (反応物の反応物2, [])]), (反応物2, [])])
みたいな感じです。
ttsが、著者が作ったなんとかTupledTreeみたいなクラスで定義されていて面倒なので、別の環境でも使えるようにとりあえずcsvにしておきます。
import csv
with open('./out_tts.csv', 'w', newline='') as f:
writer = csv.writer(f)
# header
writer.writerow(['root_smi', 'tuple_tree']
for i in range(len(tts)):
writer.writerow([root_smis[i], tuple_trees[i]])
f.close()
キレイなreaction treeを描画する気力はないので、全て一段階の反応の形式でとりあえず絵を出していきます。
自分の場合、seen_moleculesからとってきた評価関数の値が高い化合物群について、ttsを確認していきたかったので、とりあえず検索するSMILESを用意して、smis:listを作って経路を見ていきました。1つの化合物について複数の経路が出ることもあるので、1つのSMILESに対して複数のreaction treeを格納するtree_listを作って、それをtreesにぶち込んでいます。つまりlen(smis) == len(trees)です。
def print_v(text, v):
if v:
print(text)
# root SMILESのreaction treeをttsから検索してtreesに追加
def get_tts_from_smis(smis, tts):
trees = []
for smi in smis:
matched_trees: list = tts.loc[tts['root_smi'] == smi, 'tuple_tree'].tolist()
trees.append(matched_trees)
return trees
# reaction treeを、root SMILESごとに分解して表示
def draw_reactions(trees, Draw=False, verbose=True):
'''
If Draw is True, draw reaction images.
If verbose is True, print root SMILES and reaction trees.
rxns = decomposed tree = [rxn1, rxn2, ...], [rxn1, rxn2, ...]
reaction_smis = [rxns1, rxns2, ...] = [tree1, tree2, ...]
reaction_smiles_list = [reaction_smi1, reaction_smi2, ...]
len(smis) == len(reaction_smiles_list)
'''
reaction_smiles_list = []
for i, tree_list in tqdm(enumerate(trees)):
reaction_smis = []
print_v('*'*100, verbose)
print_v(f'SMILES: {smis[i]}', verbose)
if tree_list[0] is None:
print_v('None', verbose)
else:
print_v(f'find {len(tree_list)} trees.', verbose)
for j in range(len(tree_list)):
rxns = []
print_v('='*100, verbose)
print_v(f'tree {j+1}: {tree_list[j]}', verbose)
# str to tuple
tuple_tree = ast.literal_eval(tree_list[j])
print_v(f'root SMILES: {tuple_tree[0]}', verbose)
mol_root = Chem.MolFromSmiles(tuple_tree[0])
if Draw:
display(mol_root)
tts_queue = [tuple_tree]
while len(tts_queue) != 0:
tuple_tree = tts_queue[0]
product = tuple_tree[0]
rtrees = tuple_tree[1]
reactants = []
for rtt in rtrees: # rtt = reactant tuple tree
reactant = rtt[0]
reactants.append(reactant)
# reactantに子ノードが存在すれば、tts_queueに追加
if len(rtt[1]) != 0:
tts_queue.append((reactant, rtt[1]))
if len(reactants) != 0:
reactants_smi = '.'.join(reactants)
rxn_smi = reactants_smi + '>>' + product
rxns.append(rxn_smi)
if Draw:
display(Reactions.ReactionFromSmarts(rxn_smi, useSmiles=True))
tts_queue.pop(0)
reaction_smis.append(rxns)
reaction_smiles_list.append(reaction_smis)
return reaction_smiles_list
tts = pd.read_csv('./path/to/.csv')
smis = hoge # 用意したroot SMILESのリスト
trees = get_tts_from_smis(smis, tts)
rxn_smi_list = draw_reactions(trees, Draw=False, verbose=False)
tuple treeの取り扱いについて、毎回反応物側のリストの要素数をチェックし、空ならスルー、反応物が入っていればtts_queueに追加していく仕様です。もっとイケイケなreaction treeの表示ができる方がいれば教えてください
試しに、自作の tree = "('c2ccc(c1ccccc1C)cc2C(=O)NCCC', [('c1ccc(Br)cc1C(=O)NCCC', [('c1ccc(Br)cc1C(=O)Cl',[]),('CCCN',[])]), ('B(O)(O)c1ccccc1C', [('Brc1ccccc1C',[])])])" を使って表示してみると以下のような感じです。
tree = "('c2ccc(c1ccccc1C)cc2C(=O)NCCC', [('c1ccc(Br)cc1C(=O)NCCC', [('c1ccc(Br)cc1C(=O)Cl',[]),('CCCN',[])]), ('B(O)(O)c1ccccc1C', [('Brc1ccccc1C',[])])])"
_ = draw_reactions([tree], Draw=True, verbose=True)
root SMILESの絵と、バラバラになった反応の絵が出てきます。
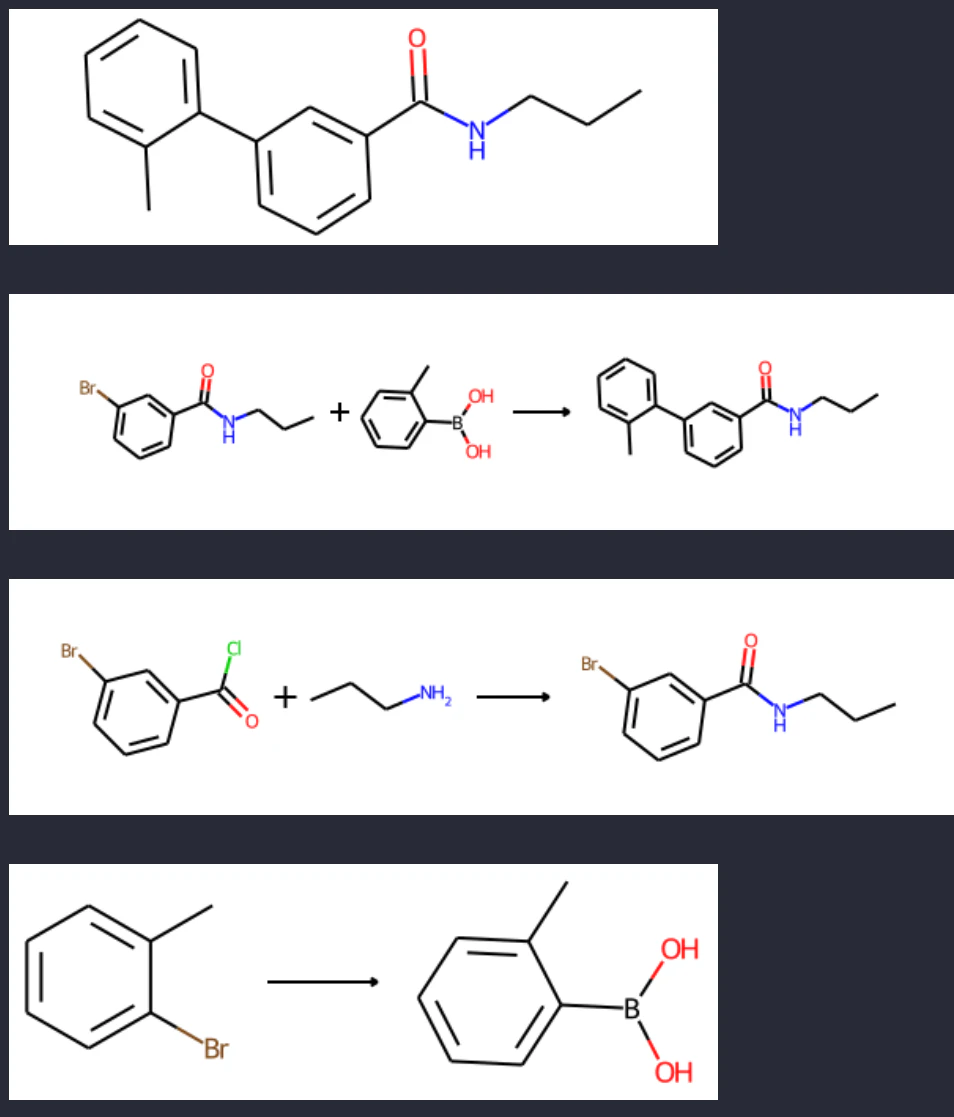
以上