2021年9月に Amazon MemoryDB for Redis が一部のリージョンからリリースされました。
Usage Fee
公式ドキュメントからAWS Elastic Cache for Redisと比較してみました。
MemoryDB においても東京リージョンでの利用料金が公開されているようです。
Amazon ElastiCache の料金
https://aws.amazon.com/jp/elasticache/pricing/
Amazon MemoryDB for Redis Pricing
https://aws.amazon.com/jp/memorydb/pricing/
- ノード
スペックが同じ単一ノードの料金を比較した場合、MemoryDB が1時間あたり $0.124 ほど高いようです。また、ElastiCache はリザーブドノードが適用対象に対して、MemoryDB はオンデマンドのみ適用可能となるようです。
| サービス | キャッシュノードタイプ | vCPU | メモリ (GiB) | ネットワークパフォーマンス | 1時間あたりの料金 |
|---|---|---|---|---|---|
| MemoryDB | db.r6g.large | 2 | 13.07 | Up to 10Gib | $0.371 |
| ElastCache | cache.r6g.large | 2 | 13.07 | Up to 10Gib | $0.247 |
- スナップショット
MemoryDBのスナップショットはクラスター全体のコピーを示すものです。
リージョン内のMemoryDBクラスターで総ストレージ量の100%まではスナップショットの追加料金は発生しません。保存期間が1日の場合、スナップショットの追加料金はありません。
追加のスナップショットストレージがストレージ料金**$0.023/GB-month**で請求されるようです。
これに対して、ElastiCacheでは自動スナップショット、および手動スナップショットがクラスターごとに、1 つのスナップショットのストレージ領域を無料で利用できますが、追加のバックアップストレージは、$0.085/GB-monthほどかかってくるようです。
状況次第ですが、ElastiCacheの方が高いように感じます。
ElastiCache for Redis
MemoryDBに入る前にElastiCache for Redisの構成について考えます。
ElastiCache for Redisは、ノードをキャッシュサーバーとして立てて、多様な構成を取ります。
シャード
- 複数ノードをもつ集合体を一つのグループとして定義します。
- このグループには、読み書き可能な Primaryノードと 読み取り専用の Replica ノード(0~5ノードまで)が属します。
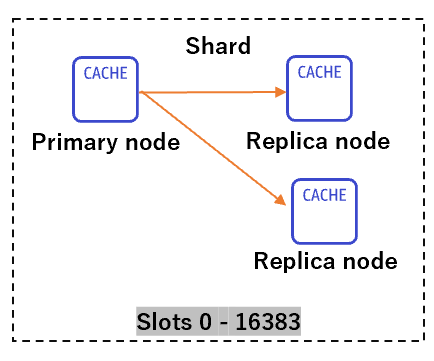
-
また、Primaryノードのみを使用する単一のシャードも可能です。
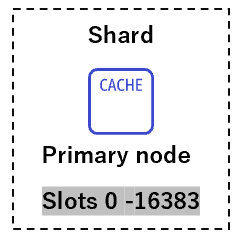
-
各シャードで slotがあり、スロット範囲を均等分散あるいはカスタム値で分散する事が可能です。これにより、スロットの範囲に応じてデータが分散され格納されます。
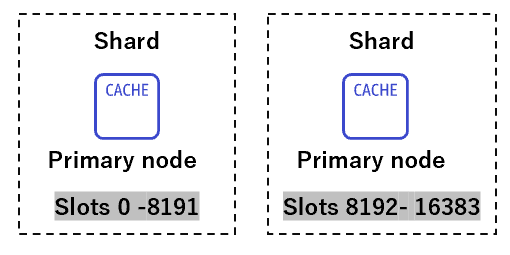
クラスター
-
シャードをまとめたグループです。
-
クラスターモードと呼ばれ、無効化する事も可能です。クラスタモードが無効な場合、Redis は1つのシャードで構成されます。
-
クラスターが有効な場合、シャードを最大で500個まで増やす事が可能で、シャードの数が多いほどデータの分散化が可能です。クラスタは2つのサブネット(AZ)が必要となり、クラスターモードが無効でもシャードを介したレプリケーション自体はサポートされます。
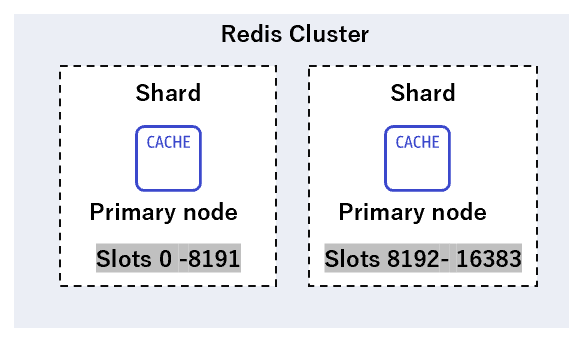
Redis レプリケーショングループ
レプリケーショングループとは、前述に挙げた以下の構成でレプリケーションが行われるグループ単位です。
- クラスタが無効化の状態ですべてのデータが単一シャードに含まれているケースでは、1 つの Primary ノードと、最大5個のReplicaノードで構成され、Replicaノードは、クラスターのプライマリノードにあるデータのコピーを非同期レプリケーション機能により保持します。
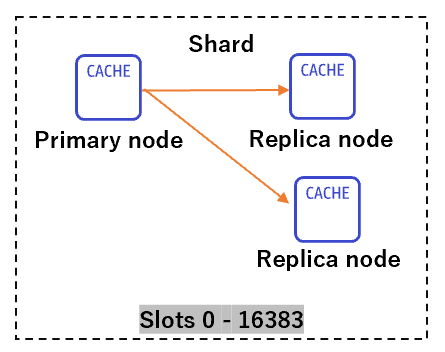
- クラスタが有効化の状態で、最大 500 個のシャードに渡ってデータが分割されるケースでは、1 〜 500 個のシャードで構成され、1 つの Primary ノードと、最大5個のReplicaノードで構成されます。シャード内の各リードレプリカは、シャードのプライマリからのデータのコピーを非同期レプリケーション機能により実装しています。
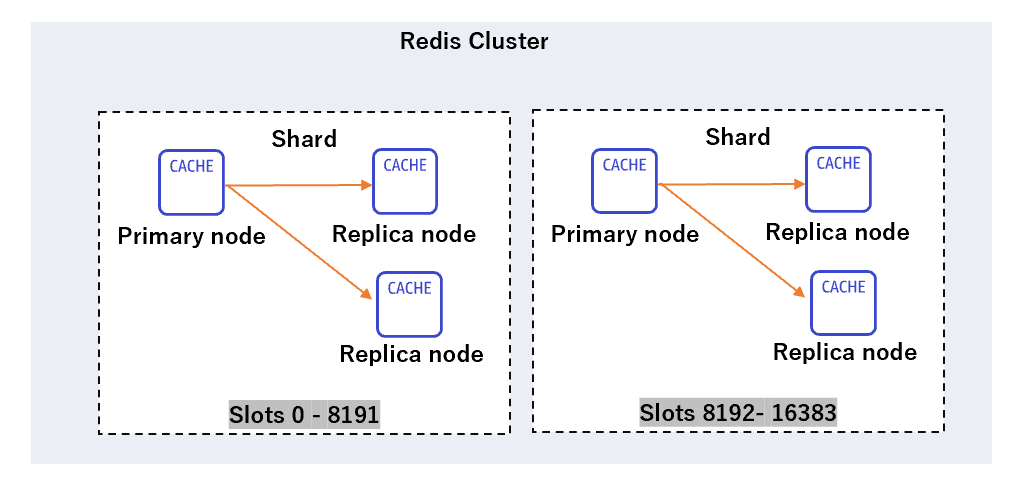
障害時のプロセス
Primary ノードに障害が発生した場合のプロセスです。
- クラスタが無効な場合
① ElastiCache がPrimary Nodeで失敗を検出します。
② ElastiCache がPrimary NodeをOFFLINEにします。
③ ElastiCache が新しいPrimary Nodeを作成してプロビジョニングし、失敗したPrimary Nodeと置き換えます。
④ ElastiCache が、新しいPrimary Nodeを既存のReplica Nodeのいずれかと同期させます。
⑤ 同期が終了すると、新しいノードはクラスターのPrimary Node となります。
このプロセスのステップが終了するまで、アプリケーションはプライマリノードに書き込めません。ただし、アプリケーションはレプリカノードから読み込みを続けることができます。
- クラスタ有効化の場合
① ElastiCache がPrimary Nodeで失敗を検出します。
② レプリケーションの遅延が最も小さいReplica NodeをPrimary Nodeに昇格します。
③ 他のレプリカと新しいPrimary Nodeを同期します。
④ 障害が発生したプライマリの AZ のReplica Nodeをスピンアップします。
⑤ 新しいノードが、新たに昇格されたPrimary Nodeと同期されます。
レプリカノードへのフェイルオーバーは、通常、新しいプライマリノードを作成してプロビジョニングするより高速です。
つまり、マルチ AZ が有効でない場合と比べて、アプリケーションはプライマリノードへの書き込みをすばやく再開できます。
Amazon MemoryDB for Redis
ElastiCache for Redis に比較します。
MemoryDBでは、Redis クラスタが必須の構成となります。
その他、構成に大きく違いはありません。
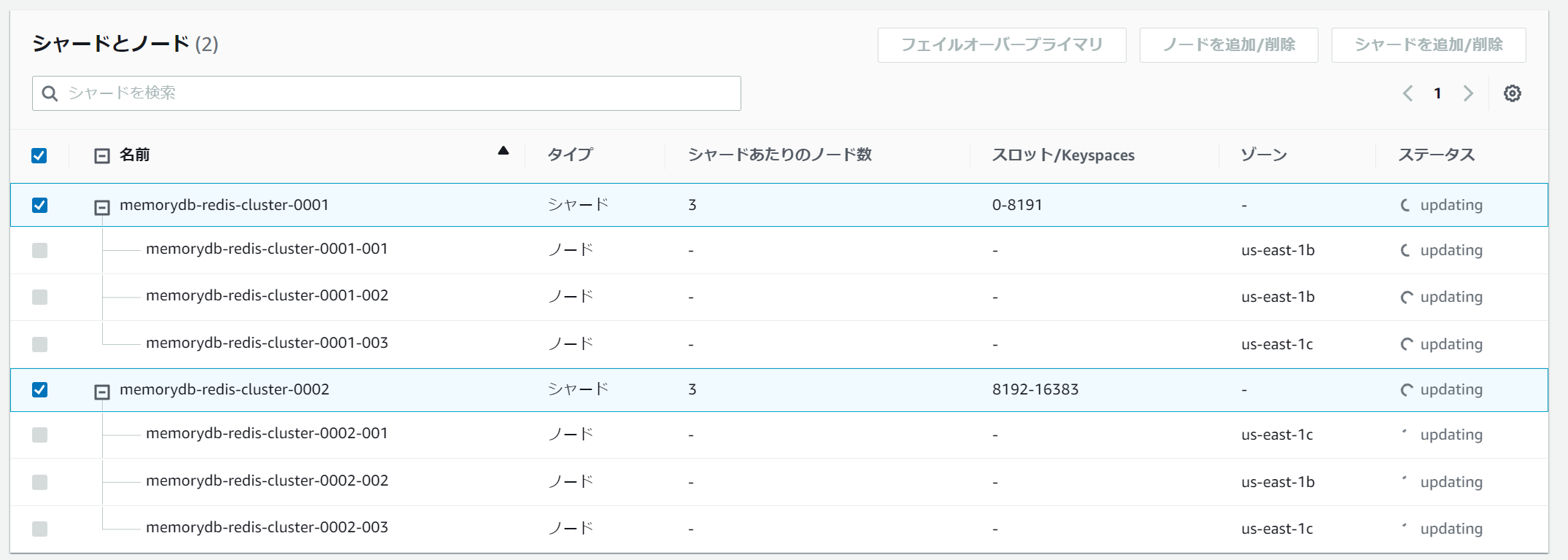
ノードの配置で考えると、クラスタ毎のシャード数、レプリカ数を選択する事となります。
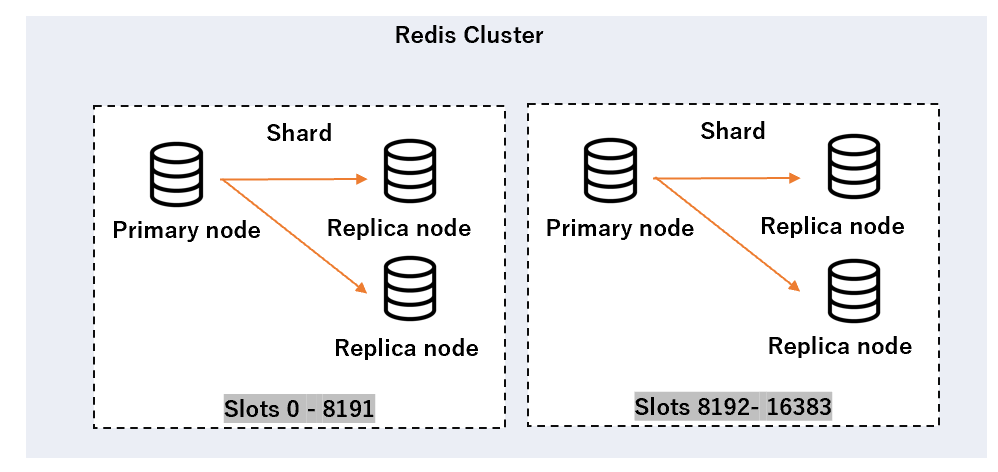
障害時のプロセス
MemoryDB のノードに障害が発生した場合のプロセスです。
ElastiCache と挙動が少し異なるようです。
- リードレプリカ
①MemoryDBがreplica Nodeの障害を検出します。
②MemoryDBは対象Replica NodeのをOFFLINEにします。
③MemoryDBは、同じAZで代替ノードを起動してプロビジョニングします。
④新しいノードは、トランザクションログと同期します。
この間、アプリケーションは他のノードを使用して読み取りと書き込みを継続できます。
- プライマリー
①MemoryDB がPrimay Nodeの障害を検出します。
②MemoryDB は、障害が発生したプライマリとの整合性を確認した後、レプリカにフェイルオーバーします。
③MemoryDBが故障したプライマリのAZにレプリカをスピンアップする。
④新しいノードは、トランザクションログと同期します。
レプリカノードへのフェイルオーバーは、通常、新しいプライマリノードを作成してプロビジョニングするよりも高速です。つまり、アプリケーションはより早くプライマリノードへの書き込みを再開することができます。
Let's use it
-
東京リージョンは正式にリリースされていないようでしたので、バージニアリージョンで作成しました。
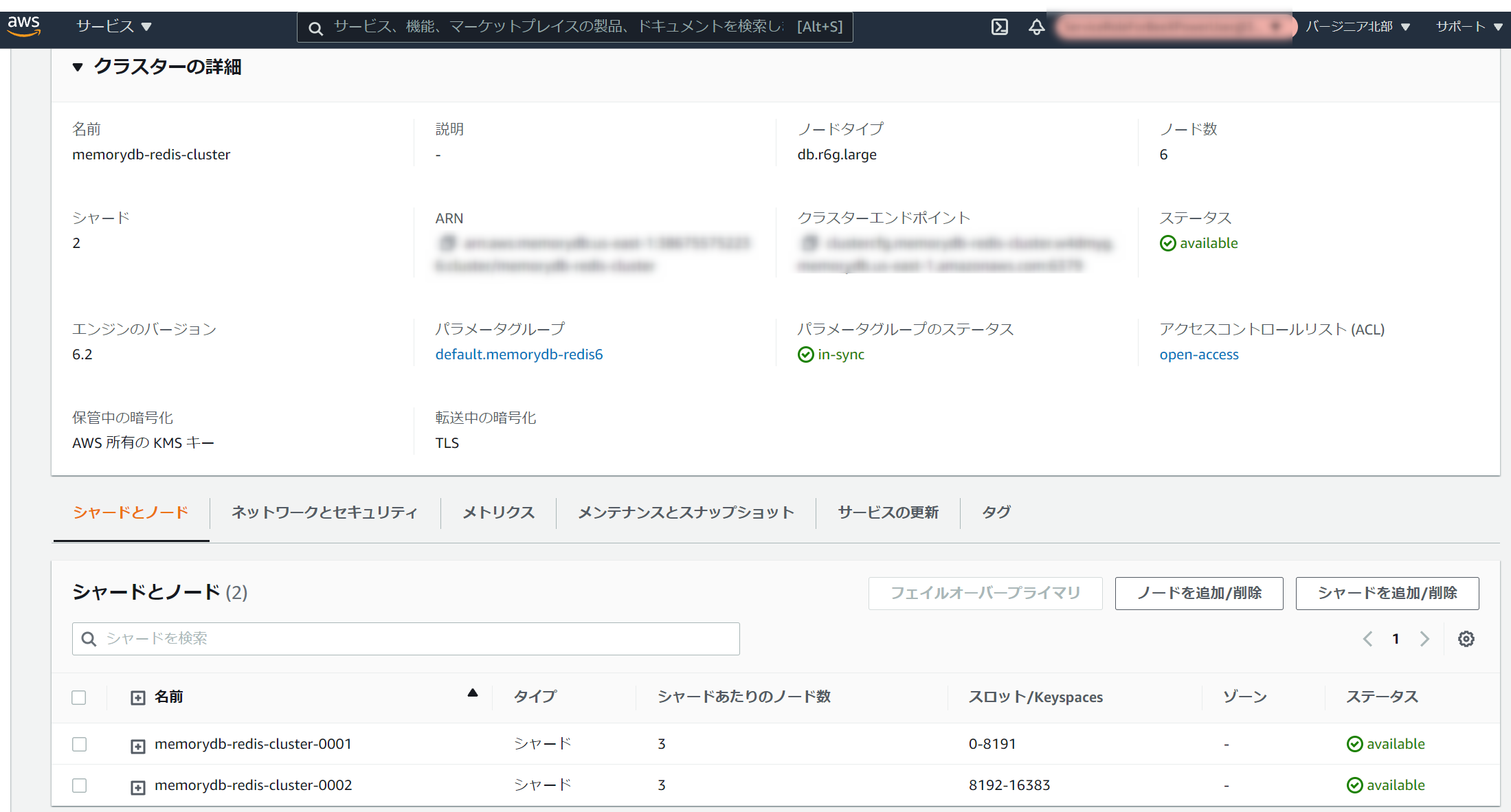
-
クラスターが必然的な設定となるので、シャードとレプリケーション数だけを指定します。
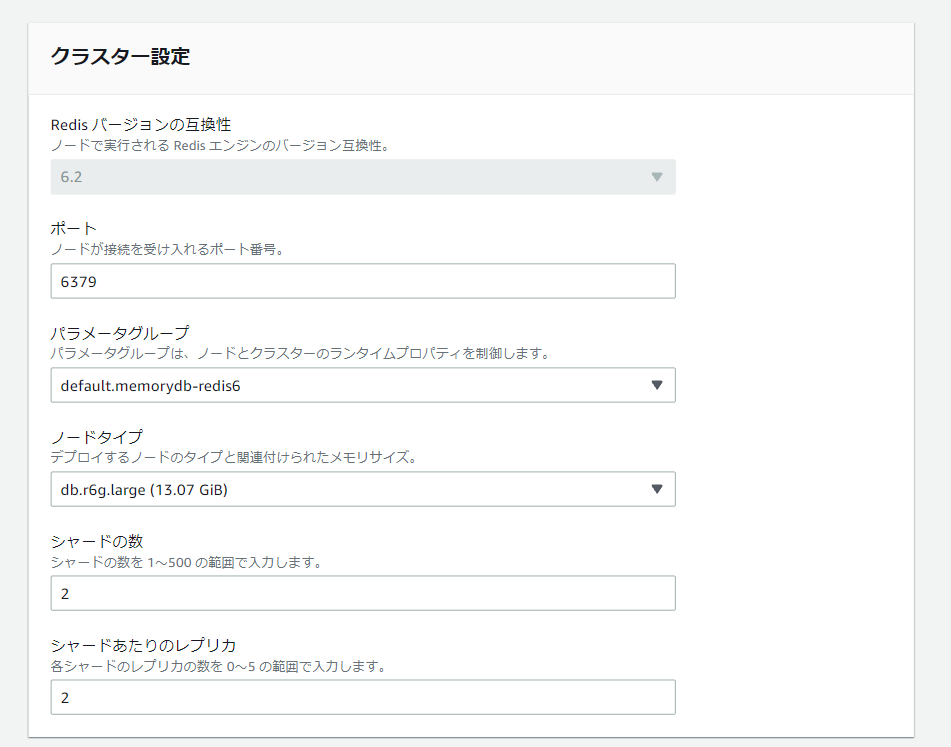
-
クラスターの作成が完了した後、ガイダンスに従って、AmazonLinux2から接続を redis へ接続します。
$ sudo yum -y install openssl-devel gcc
$ wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ make distclean
$ make redis-cli BUILD_TLS=yes
$ sudo install -m 755 src/redis-cli /usr/local/bin/
Redis に接続する際は以下のコマンド
redis-cli -h <Cluster Endpoint> --tls -p 6379 -c
データは追加できました。
set test2 2
-> Redirected to slot [8899] located at memorydb-redis-cluster-0002-001.memorydb-redis-cluster.xxxx.us-east1.amazonaws.com:6379
OK
設定ファイル(config)の確認できないようです。
> config *
(error) ERR unknown command `config`
bgsaveやAOFは使えないようです。
> bgsave
(error) ERR unknown command `bgsave`
> bgrewriteaof
(error) ERR unknown command `bgrewriteaof`, with args beginning with:
特定時点のスナップショットは自動/手動で取得できるようです。
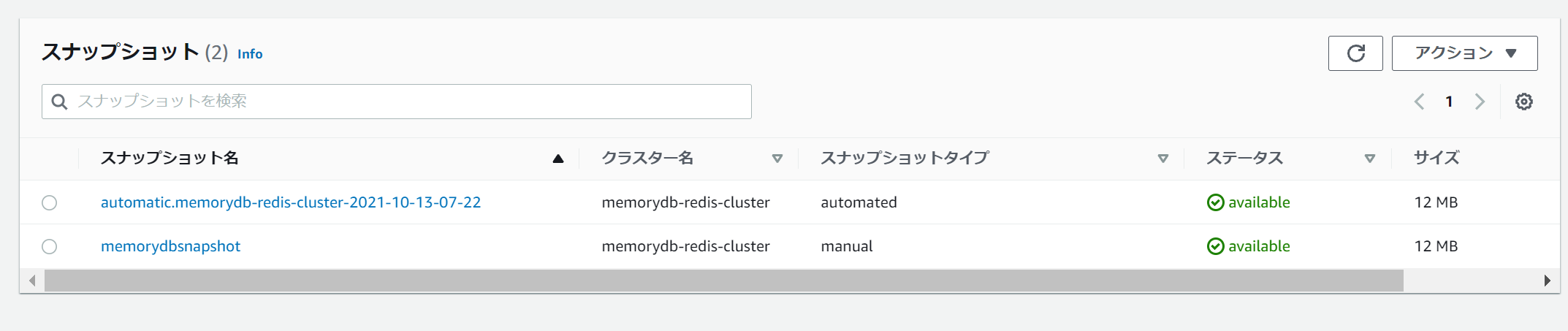
手動のフェイルオーバーは可能なようです。
書き込み中のPrimary ノードに障害を意図的に発生させて、フェールオーバー後のトランザクションに差異が無いかを確認出来ればよいのですが、方法が見当たらず一旦断念。
Usability
- ドキュメントからは、いずれのノードも一貫性を保つため、障害時にデータロストをする事は無いと記載がありますが、肝心のトランザクションログがMemoryDB の画面からも確認出来ず、 S3 や Cloudwatch にも無いようだったので、具体的にどこに保管されているかが可視化出来ませんでした。
- 任意に取得した時点のスナップショットから復元は可能なようですが、PITR(ポイントインタイムリカバリー)はどうやら使えないようです。
Consideration
MemoryDB for Redis を採択するメリットを考察してみます。
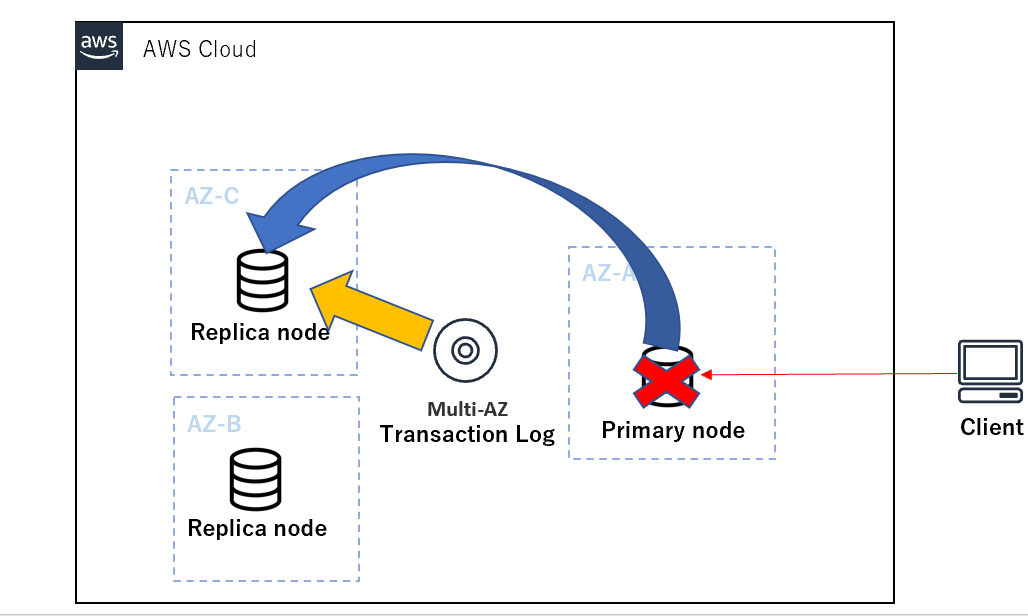
- MmoryDBは処理をMulti-AZ トランザクションログ で管理し、データの書き込み操作が成功すると、クライアントに戻る前に分散したMulti-AZトランザクションログに永続的に保存されます。
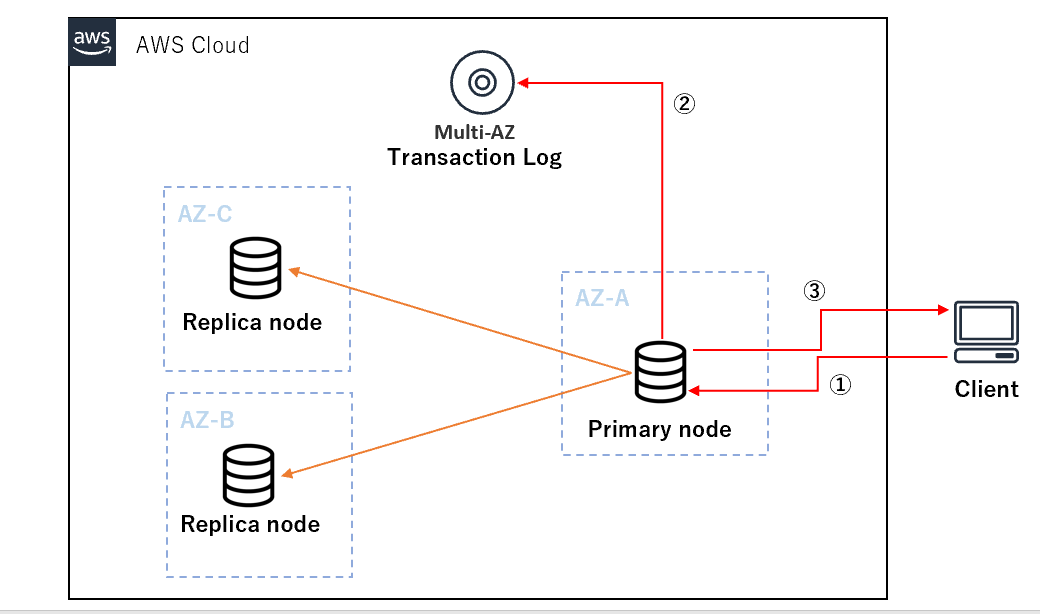
- Primaryノードに対する読み込み操作は、それ以前に成功したすべての書き込み操作の影響を反映して、常に最新のデータを返すプロセスとなっているようです。
この観点からトランザクションログが先行してデータの整合性を保持しているため、ノードダウンによる、データロストが無い、あるいは一貫性が保たれるという事が考えられます。
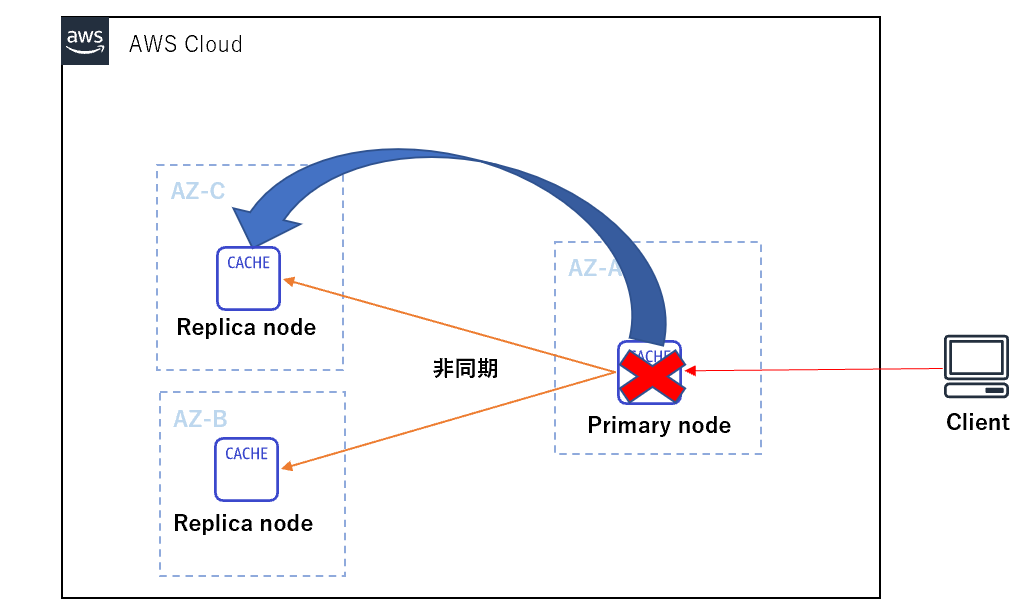
一方、ElastiCache for Redisは、多様な構成を取りつつも、データロストを最小限に抑える事が重要であり、障害の軽減という観点からドキュメントの記載があります。
-
レプリケーショングループについては、障害の影響を最小限に抑えるために、各シャードに複数のノードを実装して、複数のアベイラビリティーゾーンにノードを分散することが推奨されていますが、ElastiCache for Redis のレプリケーションは非同期で行われます。そのため、プライマリノードが他方のAZのレプリカへフェイルオーバーする際に、レプリケーションの遅延のためにデータが失われる可能性があるようです。
-
Elastic for Redisでは、Redis のデータ永続化するための機能にあたる AOF(Append Only File) が、Redis バージョン 2.8.22 以降サポートされていないようです。
また、マルチ AZ レプリケーショングループ(複数のAZに跨るレプリケーショングループを構成しているクラスタ)では、AOF は有効化出来ません。
そして、物理サーバー上のハードウェア障害が発生し、ノードにエラーが発生した場合、ElastiCache は別のサーバーで新しいノードをプロビジョニングします。この場合、AOF ファイルは使用できなくなり、データの復旧には使用できません。 -
その他の対策としてバックアップ(BGSAVE)がサポートされています。
Redis .rdb のバックアップを書き込み時には、キャッシュメモリを使用し、書き込み負荷に高いメモリを使用する場合に、キャッシュへの書き込みが遅延します。
この遅延により、ほとんどの変更が累積されないため、結果バックアップが正常に行われなくなります場合もあり、上述した追加のバックアップのストレージ領域については $0.085/GB の料金が発生します。
ElastiCaheではトランザクションによる一貫性が担保されていないため、データロストの可能性がある事が考えられ、これを最小限に抑えるためにはコスト、パフォーマンスに影響を与える構成にする必要があると考察しました。
MemoryDB for Redis は、ElastiCache for Redis に比べて書き込みが多少遅く、運用コストも高いようですが、データロスト、障害時のリスクという観点からこちらを採択する条件もあるのではないかと考えます。
しかしながら、検証不足かつまだリリース間もなく情報も少ないため、これから採択に向けて情報収集していきたいと思います。
Appendix
MemoryDBは ElastiCache for Redisから取得したスナップショット(.rdb) を元に MemoryDBとしてリストアが可能なようです。
いずれも比較をしていましたが、移行自体も出来るようです。
参考文献
- Amazon MemoryDB for Redis Developer Guide