目的
- Qiitaの使い方を学ぶ。
- Javaの学習の備忘録とする。
2023年4月23日投稿
更新履歴
更新有り
4/23 誤字の修正、一部の言い回しの訂正(言い切りからですます調へ)目次
- 記述者の前提経験
- Javaの概要
- 理解しておきたい概念
- 公式リファレンスの読み方
- 変数
- 基礎的な構文
- ArrayとArrayListの違い
- クラスファイル
- StringとStringBuilder
- ComparatorとComparable
- 検査例外と非検査例外
- ラムダ式
- モジュールシステムについて
- エントリーポイント
- 別枠
記述者の前提経験
2023年新卒未経験で都内のIT系の企業に就職しました。
大学生時代は、pythonでWebサイトの構築を挑戦して5回くらい挫折しています。
この三つの理由で挫折しました。
- 憧れだけで、作りたいものがなく、モチベーションが続かなかったこと。
- コピーサイトを作るのは嫌だったこと。
- 一つ一つ理解するのは時間が足りなかったこと。
専攻は元々化学でした。縁もゆかりもないところに現在着地しております。
今回は、Java Silverの範囲に絞って今回は問題で問われがちな部分を復習しようと思います。
今回の記事はこういった方向けです。
- 新卒の研修としてJavaを勉強していて、基礎を疎かにしたくない人
- JavaSilverの資格の取得を考えている人(レベル感の確認になるかと思います。)
- 現在JavaSilverの勉強を行なっている人
筆者の得点率
1度目 43% 不合格
2度目 89% 合格
キャリアの積み方としてQiita,Zenn,GithubPages等で学習内容を投稿するのが良いと教わったので、今回初投稿します。資格は取るだけでは意味がなく、個人開発等の実務的な側面の勉強も絶対に必要とのことでした。
初回なので、書き方の勉強を含みます。お見苦しい部分がありましたらご指摘ください
今回の学習にあたっては以下の書籍を主に参考にしました。
独習Javaを一通り読んだ後、 黒本に取り組みました。3週もしたくない…。と最初は思っていましたが、解くごとに回答速度も上がってくるので、最終的には丸一日で一冊分の問題が解けるくらいの速度感でした。
このページの末尾にも綺麗な形で参考文献を載せます。
独習Java 第一版第四刷
https://amzn.asia/d/c1sde0p
Java SE11 Silver 問題集 第一版第八刷
https://amzn.asia/d/fUiA1sB
Javaの概要

標準APIドキュメントはこちらから参照できます。
標準API
(余談ですが、Pythonに触れていたので、標準ライブラリというワードで検索かからなくて驚きました。)
また、言語仕様についてはこちらから確認できます。英語の資料でとてつもないページ数なので、実はちゃんと読んでいません。公式ドキュメントの存在を認識したかったので探しました。
言語仕様
Java言語は、Java仮想マシン(JVM)上で中間コード(.classファイル)をバイナリコードに変換して駆動するプログラミング言語です。OSに依存しないので、一度コンパイルしたファイルはMacでもWindowsでも起動します。MacでMincraftが起動するのはJavaのおかげです。
現在は半年ごとにバージョンの更新がOracleによって行われています。2023年4月現在、最新版はSE19になっています。いくつか変更点がありますが、概ねは現在試験が行われているSE11と変わりません。
forなどの制御構文については、標準APIの範囲ではなく、言語仕様に組み込まれているものなので、言語仕様を参照してください。(自分は標準APIをひたすら探して時間を浪費しました。)
eclipseにおけるmodule-info.javaの場所
独習Javaに従って、eclipseを使用して学習しました。
packageのフォルダ構造がimport宣言からは読み取れず、モジュールシステムの分野を落としがちでした。
デフォルトでは、新規Javaプロジェクトからモジュールの作成が可能です。
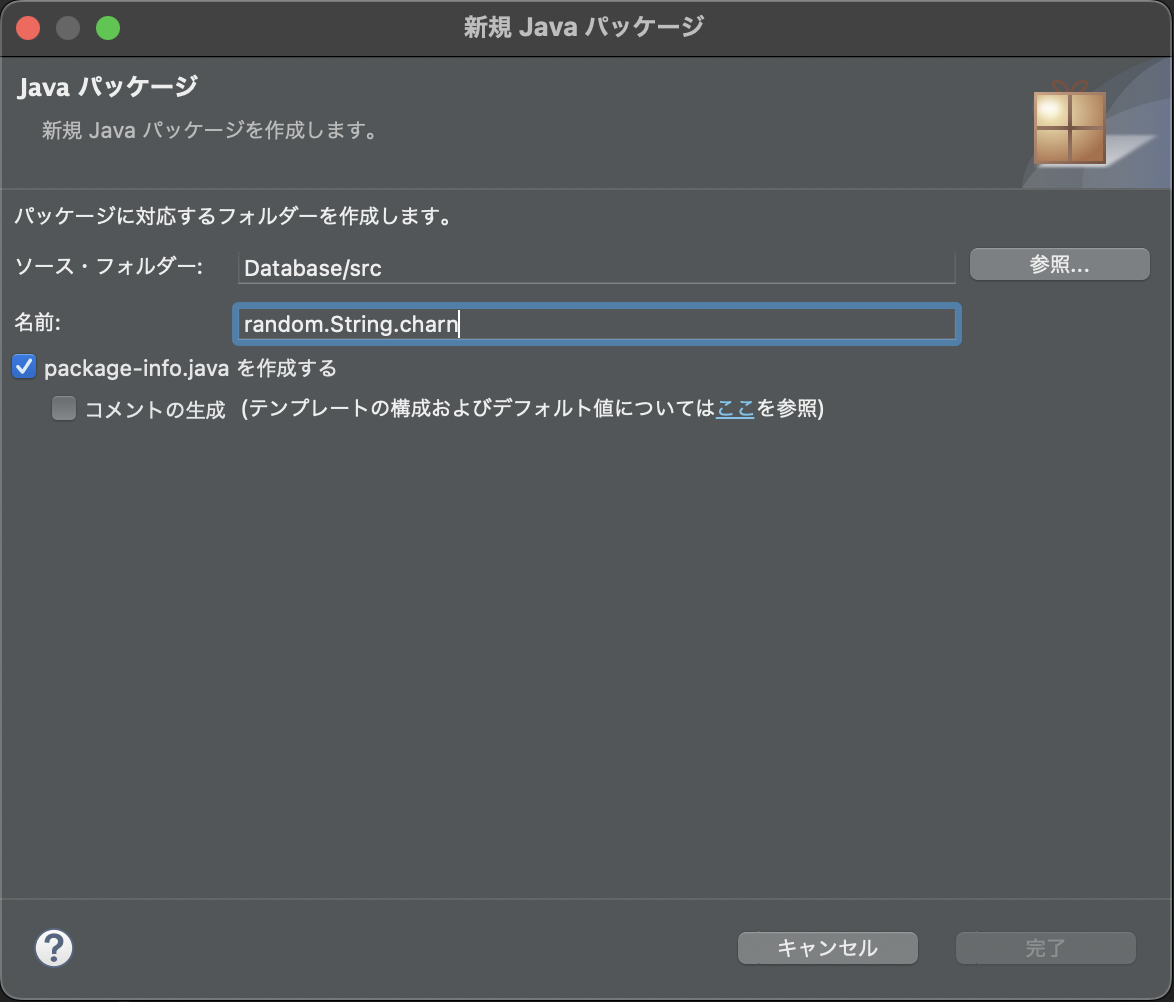
今回はDatabaseという新規Javaプロジェクトを作成し、その中に新規パッケージの作成を行おうとしています。
プロジェクトとして、モジュールが設定され、パッケージの中にクラスファイルを記述していくという流れは、eclipseを利用するにあたって理解しておくべきかと思います。
詳しくは、moduleシステムの部分で説明します。
ディレクトリ構造としては、この画像のような形になります。

標準APIは、このモジュールの集まりとなっています。
Java言語の基礎となっているモジュールは、Java.baseです。
そのJava.baseの中にはJava.langというimport宣言が不要なクラスが集まっているパッケージが存在します。
Java言語は、Java.baseモジュールを最初から含んでおり、Java.langパッケージを最初からimportしています。
Javaで扱えるデータとして、二種類に区分することが可能です。
リテラルとは、データの型に格納する値そのものを指します。
それらを図で関係をまとめたのがこれになります。

この基本型と参照型は、同一か同値かの比較に非常に重要な概念です。
Stringはリテラルと定義されています。しかし、他の基本型とは違い、参照型です。
Javaは、以下の特徴を持っています。
- JVMによる処理を行います。
- 実行時、OSとの依存関係がありません。
- 頻出するコードはメモリに保存して実行をサポートします。
- 自動的にガベージコレクションによってメモリ管理を行います。
- 開発環境はOS依存です。
- 検査例外という概念が存在します。他のプログラミング言語ではあまりみられないようです。
ガベージコレクションは、参照されなくなったインスタンス等を自動削除する機能です。
理解しておきたい概念
- オブジェクト指向
- オブジェクト指向とは、全てのものをオブジェクトとして扱うという概念です。
- 考え方の例 : 家庭用の冷蔵庫と洗濯機は、コンセントに常時差して使用する。この共通概念を「家電」とおいて、抽象化しよう。
- いろいろな説明がありますが、個人的にはこのような具体と抽象という概念が好みです。
- 静的型付け
- 静的型付けとは、変数の宣言時に宣言した型に扱いが依存することを言います。
- Pythonなどのモダンな言語では、動的型付けをすることが多いです。
- これと、ポリモーフィズムのせいでかなり試験がややこしくなっています。
- 多様性(ポリモーフィズム)
- ポリモーフィズムとは、オブジェクト指向において、サブクラスをスーパークラスとして扱うことができるという概念を指します。
- 非常にややこしく、整理がきちんとできないとつまづきます。
実践プラクティス(ポリモーフィズム)
Javaでは静的型付けが原則ですが、それに少しだけ反する概念がポリモーフィズムです。
ポリモーフィズムとは、クラス継承において、親クラスの型で、(スーパークラスの型で、既定クラスの型で)子クラス、(サブクラス、派生クラス)のインスタンスを扱えることを指します。
↓↓↓↓↓↓↓ あなたの記事の内容
親クラスで定義されたメソッド名のみサブクラスのインスタンスは使用することが可能です。この時、次の要素に気をつけましょう。
- 親クラスで定義されたメソッド名のみ、サブクラスのインスタンスで使用可能です。
- サブクラスのインスタンスが代入されている親クラス型の変数、aのフィールド変数にアクセスする際、その値は同一の名前で親クラスとサブクラスに定義されていたとしても、親クラスのフィールド変数が使用されます。
- 親クラスのメソッドとサブクラスのメソッドが同一名でオーバーライド(再定義)されていた場合、a.メソッド名はサブクラスのメソッドを使用します。。
- a.メソッド名でメソッドを宣言して、super等を呼び出した時、フィールドに定義されている同一の変数はそのメソッドが定義されているクラスを参照します。
───────
親クラスで定義されたメソッド名のみサブクラスのインスタンスは使用することが可能です。この時、次の要素に気をつけましょう。 - 親クラスで定義されたメソッド名のみ、サブクラスのインスタンスで使用可能。
- サブクラスのインスタンスが代入されている親クラス型の変数、aのフィールド変数にアクセスする際、その値は同一の名前で親クラスとサブクラスに定義されていたとしても、親クラスのフィールド変数が使用される。
- 親クラスのメソッドとサブクラスのメソッドが同一名でオーバーライド、再定義されていた場合、a.メソッド名はサブクラスのメソッドを使用する。
- a.メソッド名でメソッドを宣言して、super等を呼び出した時、フィールドに定義されている同一の変数はそのメソッドが定義されているクラスを参照する
↑↑↑↑↑↑↑ 編集リクエストの内容
このような特徴があります。
class A{
int num = 1;
private void print() {
System.out.println("A");
System.out.println(num);
}
public void b() {
print();
}
}
class B extends A{
int num = 2;
void print() {
System.out.println("B");
System.out.println(num);
}
public void b() {
print();
}
}
class C extends B{
int num = 3;
void print() {
System.out.println("C");
System.out.println(num);
}
/*
public void b() {
print();
}
*/
}
class Main {
public static void main(String[] args) throws Exception {
A s = new C();
s.b();
System.out.println(s.num);
}
}
実行結果
C
3
1
フィールドは型、メソッドはインスタンスに依存します。
勉強初期に頑張って書いていたものです。供養。
オブジェクト指向
オブジェクト指向とかの概念はできれば理解しておくべきなんだろうけど、それを知ったからっていいことがあるかって対してない気がする。
簡単に説明すると、印鑑作る時に佐藤さんと内藤さんがいたとき、「 藤」っていう印鑑の鋳型を作って新しい印鑑を作ってからそれぞれ佐と内を掘る、みたいなことがオブジェクト指向の内容。
究極的に言ってしまえばだるいから使いまわせるところは全部使いまわしちゃえってこと。
型
一番困惑したのは、クラスを作るとその型が生まれるということ。次がわかりやすいかもしれない。
Scanner scanner = new Scanner(System.in);
Scanner型のscannerという変数を定義して、そこにScannerのインスタンスを入れている。
要は次の感じである。
A「モグラのシェンシェンは穴を掘れるんだよね」
B「なるほど、じゃあミジンコのモグ太郎も穴を掘れるはずだね」
モグラ シェンシェン = new モグラ();
ミジンコ モグ太郎 = new モグラ();
モグ太郎.穴掘り();
シェンシェン.穴掘り();
error!
そりゃそうと言われるとそうなのだが、この型の違う何かを他の部分に代入するとエラーが出てしまうわけなので、この違いは大事である。
この時はモグ太郎の代入のタイミングで既にエラーが出るが、定義されていないメソッドを使用してもエラーが出るのでミジンコインスタンスを作ってあげて穴掘りメソッドをやってもエラーになるというわけ。
シェンシェンは問題ない。
…わかりづらいな。
インスタンスを作成する際、そのインスタンスを渡す変数にはそのインスタンスにあった型を指定してあげる必要があるということ。String型がわかりやすい…かな?あれも基本リテラルではなく参照型だし。
よく見るとクラス型って独習Javaに書いてあった。
実際にアプリを作ってみようと思うと、クラスが保持している値に気軽にアクセスできるようになるため、かなり重要な概念だった。
class A{
public String a;
}
class F extends A{
public String a = "16" ;
}
class Test1 {
Test1(A c){
//A型のcという名前の変数を定義している。引数としてA型もしくはA型のサブクラスを受け取れる。
System.out.println(c.a);
}
}
public class Main{
public static void main(String[] ホゲホゲ) {
A b = new F();
Object d = new Test1(b);
}
}
かなり簡素化するとこのような形。ちなみにエラーが出る。
クラスメソッド(静的メソッド)とインスタンスメソッド
度々出る概念なんだけど、大事なので…。
クラスメソッドとは、static修飾子で就職されたメソッドのことを指す。
インスタンスを生成せずに使用できるメソッド。標準ライブラリのメソッドがこれに該当することが多いような気がする。Math.pow()とか。
インスタンスメソッドはインスタンスを生成しないと使えない。
staticのフィールドは多数のインスタンスから参照し、結果を変更しても、コピーが生成されるわけではなく、すべて同一の参照先を見て、すべて同一の値を変更しようとする。
これはメソッドの話ではなくstatic修飾子でやればいいか
公式リファレンスの読み方
公式ドキュメント、公式リファレンスとも呼びます。
プログラミング言語の開発側が書いた正確な仕様がまとまっているものになります。
言語によって複数あり、また呼称も変わってくるので、探すのには一苦労です。
インターネット上で検索をすると、プログラミングスクールが書いた記事ばかり検索に引っかかります。どこを参考にして書かれたものかわからず、正確な仕様がわからないため、ネットリテラシー的にもあまり良くありません。
ここでは、特に標準API(SE11)の読み方を簡単に共有してみます。
書いてて思いましたが上司にちゃんと読み方聞けばよかったよ。自己流です。間違いがあったら教えてください。
API仕様書トップページ(モジュール一覧)

トップページ。Java Silverの範囲は、java.baseモジュールの中のみを扱うので、基本的にJava.baseモジュールを開けば問題ないです。
パッケージ一覧

java.baseモジュールの中に入っているパッケージの一覧です。abc順に並んでいるので、java.langが一番上に無いのに戸惑うかもしれません。
java.langはimportせずに含まれるパッケージなので、全ての基本となるパッケージです。
これを開いてみましょう。ちなみにですが、JDKのファイルはSEの範囲内ではありません。
エクスポートで表示されているのは、外部モジュールからアクセス可能なパッケージ一覧です。
クラスファイル一覧

パッケージを開くと、パッケージの機能の説明が書かれたページが開きます。
(余談ですが、自作パッケージのpackage-info.javaに説明を追加すると、Web上で同じフォーマットでpackage-info.javaの内容が見れるらしいです。まだ詳しいことは知りません。)
Java.langパッケージには、以下の内容が含まれます。
- Interfaceファイル
- クラスファイル
- 列挙型
- 例外
- エラー
- アノテーション
これも余談ですが、eclpse上でコマンドを押しクラスやインターフェース名にカーソルを合わせると、どのような定義をされているか確認ができます。
難しくてよくわからない可能性も多分にありますが、読み方だけは記憶しておくと良さそうです。(実際自分は、読んでも何を言っているかさっぱりわかりませんでした。)
Objectクラス
一番重要と言ってもおかしくない、Objectクラスを例に説明していきます。

関連項目については、継承された抽象クラス、インターフェース、クラス等があった場合、この近辺にリンクが貼られます。特に抽象クラスとインターフェースを継承しているクラスについては、オーバーライドされているメソッドがなんなのか等の確認ができるので重要です。
「コンストラクタのサマリー」については、オーバーロードされているコンストラクタの一覧が並びます。引数なしのコンストラクタのみ定義されているようです。フィールドを保持するクラスの場合、「コンストラクタのサマリー」の前に「フィールドのサマリー」が表示されます。

修飾子と型については、そのメソッドに定義されているアクセス修飾子と戻り値の型が定義されています。
メソッドについて、引数がある場合、受け付ける引数を定義しています。
オーバーロードされている場合、例えばこの場合wait()メソッドがそれに当たりますが、引数の型、引数の変数名、引数の数がここからわかります。ただし、引数の変数名は内部的な処理のために必要なものであり、これらのメソッドを使用する際は不要な情報です。読み飛ばしてください。
メソッドのサマリー直下のタブには、具象メソッド等の分類を自動で行なってくれる機能があります。Objectクラスは静的メソッドがなく、抽象メソッドも無いため、全てインスタンスメソッドであり、具象メソッドです。
簡単に説明すると、対になる概念は以下です。
インスタンスメソッド <-> staticメソッド(静的メソッド)
具象メソッド <-> 抽象メソッド
メソッドをクリックすると、メソッドの詳細説明(ページ内遷移、ページ下部)に移行します。
例えばget.class()メソッドの詳細を読んでみましょう。
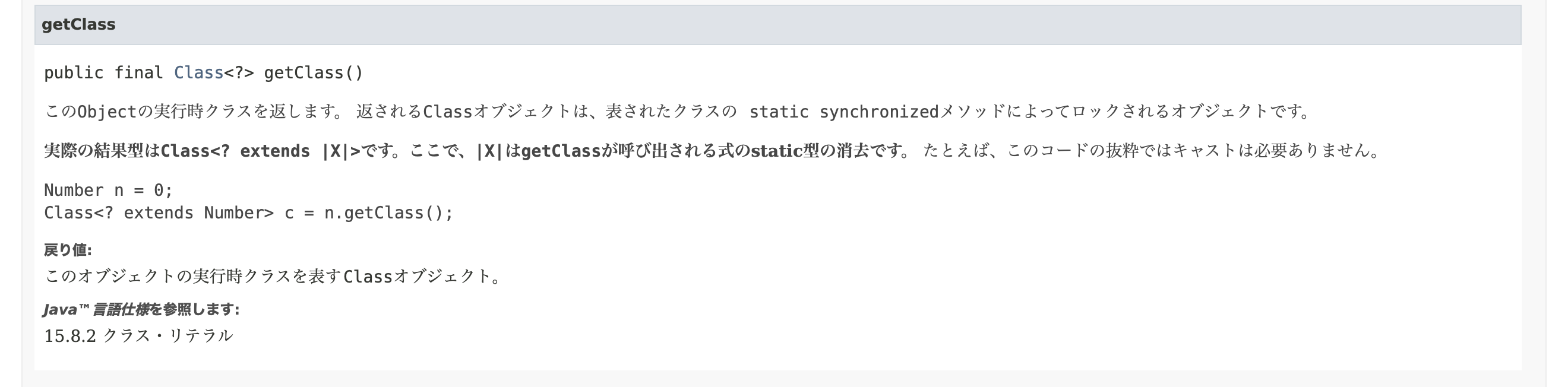
詳細の最初は、メソッドの宣言の部分になります。publicであるため、どのクラスからもアクセス可能であり、finalであるため、オーバーロード禁止です。これは、どのクラスからこのメソッドを使用しても、独自定義していなかった限り同一の処理を保証する意味があります。
ざっくり概要を説明すると、多様態、ポリモーフィズムを使用してスーパークラスの型宣言を行った変数にサブクラスのインスタンスを入れて、変数を主体としてget.classメソッドを使用すると、サブクラスの名前が返ってくるという形です。
例えば、一次元のint配列の場合、[intといったような表示を戻り値として出します。
<>これは型パラメータです。オーバーライド、オーバーロードが絡むとかなり複雑なのですが、今のところ、この型パラメータ以外の値を要素として含むものはコンパイル時に拒否してもらえる、といった認識で構わないと思います。未だに理解できていない。
getclass()メソッドでは?として取り入れられているので、なんでも許容する、という意味になります。
最後に、ようわからん大文字が公式のドキュメントを読んでいるとたくさん出てくるので、それについての解説をコピーして終わります。
E - Element (used extensively by the Java Collections Framework)
K - Key
N - Number
T - Type
V - Value
S,U,V etc. - 2nd, 3rd, 4th types
引用元[ https://docs.oracle.com/javase/tutorial/java/generics/types.html ]
きちんと説明できず…。供養
#### 公式リファレンスの読み方 公式リファレンスの読み方のメモ。Javaの公式ドキュメント、たくさんあるけれど初学者にはこの中から目当てのものを探すのはなかなかしんどい。(for構文の説明を探すだけで一日費やし、最終的に上司に教えてもらうくらいには大変。) 言語仕様書はこちらのURLから読める。 https://docs.oracle.com/javase/specs/ とりあえず一番新しいやつを読めば良さそう。前編英語ですが。こちらにちゃんとforの説明が入っていた。 java.io等の標準ライブラリの説明はここから読める。 https://docs.oracle.com/javase/jp/11/docs/api/index.html ただ日本語で表現してくれてはいるけど、最新のものではないので注意。2023年現行でのJava SilverはSE11で出題されているので、初学者はこれを読めば問題ないはず。 探す際は、ファイル内検索を駆使すれば欲しいのが探しやすい。コマンド + Fで行ける。ちなみに、標準ライブラリのことを、JavaではAPIと呼ぶようだ。
なんでかさっぱりわからんかったが、広義のAPIに含まれるらしい。
参照 : https://zenn.dev/kazmaendo/articles/4e126a4fda31e3
なるほど確かにJava.io等、他のファイルにアクセスできるものは標準ライブラリに含まれている。
APIを探すには、メソッド単体で検索するのではなく、所属クラスや所属パッケージ、所属モジュール
で検索をかける方が良い。
例えばScannerクラス。Java.utilパッケージに属す。

このようにコンストラクタで何を引数として受け取ることが可能なのか示してある。
中はオーバーロードで定義されてるはず。
このように引数の形を何個も別のものを定義して、処理自体は大体一緒のメソッドを作るとき、それをメソッドのオーバーロードという。
変数
型宣言
変数を定義するときは、型宣言を行う必要があります。
構文は以下です。
アクセス修飾子 修飾子 型宣言 変数名;
アクセス修飾子は、以下の種類があります。
| アクセス 修飾子 |
説明 |
|---|---|
| public | どこからでもアクセス可能です。 |
| protected | 同一パッケージ内からのアクセスを許可します。 他のパッケージでも、そのクラスのサブクラスからアクセス可能です。 |
| (default) | アクセス修飾子を指定しなかった場合適用されます。 同一パッケージ内からのみアクセス可能です。 パッケージプライベートとも呼びます。 |
| private | 同一クラス内からのみアクセス可能です。 |
修飾子は、JavaSilverの範囲では以下の二つが使用されます。
| 修飾子 | 説明 |
|---|---|
| final | 変数の再代入を規制します。 |
| static | 通常インスタンスごとに設定される変数をクラス共通にします。 |
型宣言においては、通常int等の基本型の名称を代入します。
変数名を識別子とも呼びます。
変数名のルールで以下の二つは気をつける必要があります。
- $_以外の記号
- 一文字目の数字
型宣言の際、以下のルールを確認しておく必要があります。
- ローカル変数は初期化しなくてはエラーになる。
- フィールド変数は初期化しなくてもエラーにならず、初期値が代入されます。
- ローカル変数にstatic修飾子は使用できません。
- フィールド変数にfinal修飾子を使用した場合、初期化しなくてはエラーになります。
- ただし、初期化子(static初期化子)やコンストラクタで必ず初期化されるようにコードを書くとエラーになりません。
型推論
また、型の宣言の際、特定のものを使用せず、varという宣言を使用することも可能です。
varは型推論と呼ばれる機能があり、初期化の際に代入されたものの型に従います。
- varで型宣言を行うと、コンパイラが自動で型を決定する。
- 初期化を同時に行わない場合、コンパイルエラーとなる。
- 複数の変数をまとめて宣言できない。
- フィールド変数にvarは使用できません
- メソッドの戻り値にvarは使用できません。
静的型付けの概念から反していますが、使用可能です。
基本型
このような順番で解説を行う。
基本型の概要
基本型とは、メモリの確保後に値をそのまま格納するデータ型です。参照型のように、ハッシュコードを変数として確保したメモリに格納せず、変数として確保したメモリに値をそのまま格納します。
変数から変数への代入や、return文では値をそのままコピーします。
そのため、以下のような変更では、片方しか変更されません。
int a = 11;
int b = a;
System.out.print(a + " " + ++b);
実行結果 : 11 12
基本型にはnullを代入できません。
数値以外の基本型
char
16ビットUnicode文字 (2バイト)
- 一文字のみを格納する。格納の際は’’シングルクォートで囲む。
- varでの型推論の際、’’シングルクォートで囲んだ一文字のデータはchar型と認識される。
- ‘’シングルクォートで囲んだ文字列があった場合、これはchar型とも見做されず、コンパイルエラーとなる。
- char型には数字の代入が可能である。これはUnicodeにしたがって文字を指定しているため、数字に対して文字が相互変換可能であるためである。
- ¥uxxxx形式の16進数文字コードでも表現が可能である。
- charの初期値は""(blank)
実践Practice
public class Main {
public static void main(String args[]) {
char a = 100;
int b = 100;
a = b;
}
}
実行結果 :
Main.java:8: error: incompatible types: possible lossy conversion from int to char
a = b;
ただし、char型への変換は暗黙的に行われるものであり、静的型付けとして宣言してある変数を代入することはエラーが発生する。int型へのキャストを行なった数字に対してはエラーが発生せず、問題なく、コンパイルと実行が可能である。
public class Main {
public static void main(String[] args) {
char a = '\u0044';
System.out.print(a);
}
}
実行結果 : D
このようにchar変数に対してUnicodeを直接代入することも可能である。
boolean
true or false(1ビット)
- 数値型との相互変換はできません。(0=false,1=trueなどの変換は行われません。)
- boolean型の初期値はfalse
整数の基本型
byte
8ビット整数(-128~127)(1バイト)
- バイトデータ、文字を扱うための型です。
- byte型の初期値は0
short
16ビット整数(2バイト)
- まず利用する機会はないとのことです。
- 外部のデータソースと16ビットの符号付き整数のやり取りをする際に、ビット長を明確にするために用いられることもあります。
- short型の初期値は0
int
32ビット整数 <-これがデフォルト(4バイト)
- 基本的にはこれが用いられます。
- 現在のコンピュータが最も効率的に扱うデータサイズであるとのことです。
- int型の初期値は0
long
64ビット整数(8バイト)
long型の初期値は0
- 型サフィックスが用意されており、接尾辞はLもしくはl(小文字のL)
浮動小数点の基本型
float
32ビット浮動小数店 (4バイト)
- float型の初期値は0
- 型サフィックスが用意されており、接尾辞はFもしくはf(小文字のF)
double
64ビット浮動小数点 (8バイト)←これがデフォルトである。
- double型の初期値は0
- 型サフィックスが用意されており、接尾辞はDもしくはd(小文字のD)
浮動小数点の表し方について
- 内部的には、指数と仮数という扱い方で保存している。仮数とは、1.2 ×10^3 の、1.2の部分です。
- このため、浮動小数点の数を演算する時、厳密な値が出ない可能性があります。
浮動小数点の正規化という概念
11.2×10^3→1.12×10^4と表す。
- 仮数が1以上2未満になるように表現を行う。これを正規化と呼びます。
- ちなみにJavaでは、乗数の記号として^これを使うのは許容されません。
- Javaでは指数の表現としてe,Eを用います。1.12×10^4 = 1.12E4=1.12e4
基本型の拡大変換
基本型はこの図のような拡大変換を自動的に行うことが可能である。
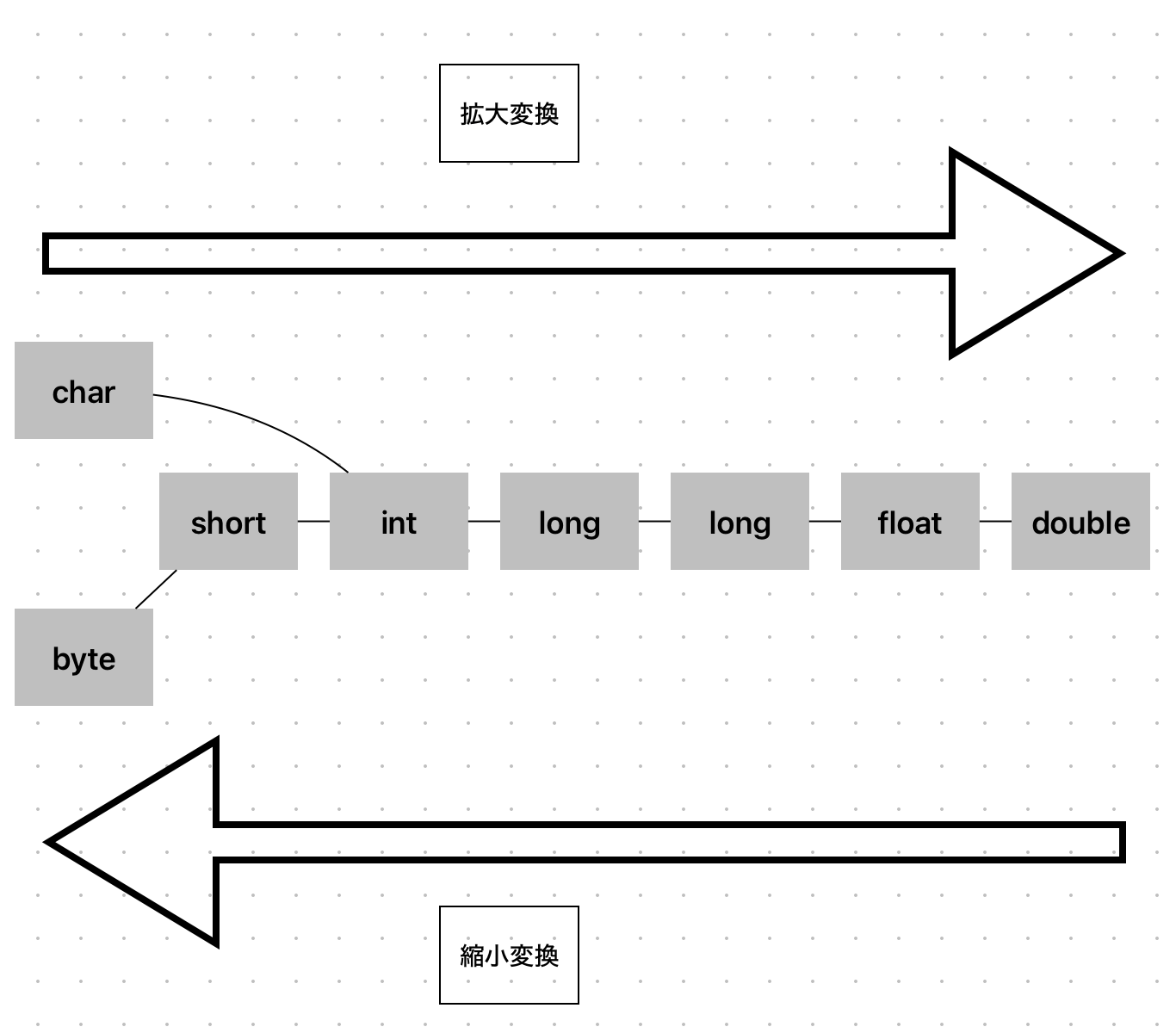
縮小変換は自動的に行われず、行った場合コンパイルエラーとなる。
実践プラクティス
拡大変換は自動で行われる。
public class Main {
public static void main(String args[]) {
char b = 'A';
int a = b;
System.out.println(a);
}
}
実行結果 : 65
public class Main {
public static void main(String args[]) {
char b = 'A';
float a = b;
System.out.println(a);
}
}
実行結果 : 65.0
public class Main {
public static void main(String[] args) {
char a = '\u0044';
System.out.print(a);
}
}
実行結果 : D
char型はUnicodeをエスケープシーケンスを用いて代入することが可能である。
public class Main {
public static void main(String[] args) {
char a = '\u0044';
short b = a;
System.out.print(b);
}
}
実行結果 : コンパイルエラー
互換性の無い型への自動変換はコンパイルエラーとなる。
public class Main {
public static void main(String[] args) {
char a = 88;
System.out.print(a);
}
}
実行結果 : X
char型に直接整数を入れることも可能である。
public class Main {
public static void main(String[] args) {
byte A= 1110;
System.out.print(A);
}
}
二進数のつもりで代入しても、数値プレフィックスを行わない限り、10進数として扱われるので、値の範囲外となる。
こんなの作ってみました。
public class RandomName {
private static void firstname() {
int randomCount = (int)(Math.random() * 3 + 1);
String randomString = "";
for(int i=0 ; i < randomCount ; i++) {
int randomInt = (int)(Math.random() * (0x9FFF - 0x4E00 + 1) + 0x4E00);
char randomChar = (char)randomInt;
randomString += String.valueOf(randomChar);
}
System.out.print(randomString + " ");
}
private static void lastname() {
int randomCount = (int)(Math.random() * 3 + 1);
String randomString = "";
for(int i=0 ; i < randomCount ; i++) {
int randomInt = (int)(Math.random() * (0x9FFF - 0x4E00 + 1) + 0x4E00);
char randomChar = (char)randomInt;
randomString += String.valueOf(randomChar);
}
System.out.println(randomString);
}
public static void Createname(int a) {
for(int i = 0 ; i< a ; i++) {
firstname();
lastname();
}
}
}
Unicodeの日本語漢字を用いて、ランダムな名前っぽいものを生成する関数です。
何回作成するかを引数に取っているCreateName()を外部から呼び出すことで、実行が可能です。
firstnameメソッドとlastnameメソッドはカプセル化として、外部から参照されないようにしています。
よりこのコードの汎用性を高くするには、Unicodeの文字範囲を変数として明確化するのが良いでしょう。今回はChatGPTを使用し、常用漢字の範囲を出してもらいました。
実行してみるとわかりますが、全然知らない感じばっかり出力されるもんで笑ってしまいました。
- long型(8バイト)→float(4バイト)のバイト数が少ないものも拡大変換とされています。
- 浮動小数点のメモリの使い方は指数+仮数という形でメモリを使用しています。
- 浮動小数点は上記の理由から表現可能範囲がlongより広いです。
- float,doubleの浮動小数点の基本型では桁が足りないということが発生しません。
- 指数部分のメモリ確保のため、桁の端数部分が拡大変換の際に切り捨てられれます。
- 浮動小数点の演算は精度が怪しいことに気をつけてください。
基本型の縮小変換
広い型から狭い型への代入は縮小変換と呼ばれる。
縮小変換を行いたい場合、キャストという手法が用意されている。構文は以下
(基本型の名前)変数名or実際の値
注意点
- String型は参照型であるため、明示的なキャストが不可能です。
- (参照型への明示的なキャストは全て不可能、逆も同じです)
- 暗黙的な縮小変換は実際の値に関わらずエラーとなります。
- 型キャストを用いて変換し、値が範囲外だった時や、互換性のないキャストを行なった場合例外がスローされます。
- char型は符号なし整数を表す型であり、すべての型から見て縮小変換となります。
- キャストではビット換算を内部で行なっているため、値の範囲外にキャストを行うと、ビット落ちが発生し、意味不明な値が出現する可能性があります。
実践プラクティス
```Main.java public class Main { public static void main(String args[]) { char b = 'A'; byte a = 11; b=a; System.out.println(b); } } ``` `Exception in thread "main" java.lang.Error: Unresolved compilation problem: ` `型の不一致: byte から char には変換できません` 縮小変換を暗黙的に行おうとしているため、エラーが発生する。型サフィックス
型サフィックスとは接尾辞をつけ、型を明示することを言います。
サフィックスの意味は接尾辞という意味です。
以下がリストです。
| データ型 | サフィックス | 例 |
|---|---|---|
| long | L,l | 100L |
| float | F,f | 3.5F |
| double | D,d | 3D |
数値セパレーター
Javaではカンマを使わず、アンダースコアを使用して数字の可読性を高める。
アンダースコアを利用できない場合
- 記号(0bのb )の前後(数値プレフィックスの前後)
- 数値の先頭、末尾
- 小数点の前後
- 型サフィックスの前後
実践プラクティス
public class Main {
public static void main(String[] どこどこ) {
int A= 1111_111;
A++;
System.out.println(A);
}
}
実行結果:1111112
これはコードを書くときの可読性を上げるために使われる。
public class Main {
public static void main(String[] どこどこ) {
int A= _1111_111;
A++;
System.out.println(A);
}
}
実行結果:Exception in thread "main" java.lang.Error: Unresolved compilation problem:
_1111_111 を変数に解決できません
アンダースコアは最初と最後には使えない。
public class Main {
public static void main(String[] どこどこ) {
int A= 1111_111_;
A++;
System.out.println(A);
}
}
実行結果:Exception in thread "main" java.lang.Error: Unresolved compilation problem: Underscores have to be located within digits
翻訳すると、アンダースコアはdigits(数字)within(以内)に位置していなければならない。とのこと。
頭と尻尾にあるのでエラーメッセージが違うのは変な感じだね。
public class Main {
public static void main(String[] どこどこ) {
int A= _1111_111_;
A++;
System.out.println(A);
}
}
実行結果:Exception in thread "main" java.lang.Error: Unresolved compilation problem:
_1111_111 を変数に解決できません
先に出てくるエラー項目を基本的に表示している。
基本型での演算について
(1) どちらかの値が double 型の場合は他の値を double 型に変換する
(2) どちらかの値が float 型の場合は他の値を float 型に変換する
(3) どちらかの値が long 型の場合は他の値を long 型に変換する
(4) (1)から(3)に該当しない場合は両方の値を int 型に変換する
引用[https://www.javadrive.jp/start/var/index12.html]
- 除算で、整数の基本型同士で除算した場合、端数が切り捨てされます。
- キャストは優先して後置の値を変化させます。
- キャストの順番について、()を使用して明示的に先を示した場合は、かっこ内の演算が先です。
実践プラクティス
public class Main {
public static void main(String args[]) {
var i = (float)(11 / 2);
System.out.println(i);
実行結果5.0
public class Main {
public static void main(String args[]) {
var i = (float)11 / 2;
System.out.println(i);
}
}
実行結果 5.5
オートボクシング
Integerなどのラッパークラス(参照型)とintなどのプリミティブ型との間で、自動的に相互変換が行われることを「オートボクシング」と呼びます。基本形からラッパークラスへの変換を「ボクシング」、ラッパークラスから基本型への変換を「アンボクシング」と呼称が用意されています。
「ボクシング」は、Box + ing のようなイメージで説明できるようです。つまり、基本型を箱(オブジェクト)に入れるようなイメージから来ているようです。(Wikipedia参照)
- オートボクシングによって、オブジェクトクラスに使用するメソッドを使用できます。
- オートボクシングによって、オブジェクトクラスのみに使用できるジェネリクスに基本型の値を指定できます。
- オートボクシングによって、ラッパークラスとしてnullを代入することは可能です。ただしその際アンボクシングは行えず、エラーになります。
nullの扱いについて
nullの扱いについて ```Main.java public class Main { public static void main(String[] args) { int A = null; System.out.println(A); } } ``` `Exception in thread "main" java.lang.Error: Unresolved compilation problem: ` `型の不一致: null から int には変換できません`これはnullは参照型にしか入れられないからだね。
逆にラッパークラスだと参照型になるのでnullを入れられる。
public class Main {
public static void main(String[] args) {
Integer A = null;
System.out.println(A);
}
}
実行結果:null
実践プラクティス
public class Main {
public static void main(String[] どこどこ) {
Integer A = 1;
A++;
System.out.println(A);
}
}
実行結果:2
integerクラスに数字を代入してインクリメントはできる。
public static void main(String[] どこどこ) {
Integer A = Integer.valueOf(1);
A++;
System.out.println(A);
}
}
IntegerのインスタンスをStaticメソッドで作成しても通る。
実行結果:2
ラッパークラスは以下のようにインスタンスを作成できます。
Integer a = Integer.valueOf(1);
これは、整数型のラッパークラスのインスタンスの生成に用います
ラッパークラス 変数名 = ラッパークラス.valueOf();
汎用的な構文としては上記の構文をラッパークラスインスタンスの生成に用います。
余談ですが、基本型をgetclass
メモリについて
ボクシングは都度オブジェクトの生成が行われるため、使用頻度が高くなるとコードの効率が悪くなる。
ただし、キャッシュ機能を備えているメソッド等の使用によってのボクシング的な操作はその効率はわずかに上がるとのこと。
数値プレフィックス
| 2進数 | 8進数 | 16進数 | |
|---|---|---|---|
| 接頭辞 | 0b (binaryより) |
0 / 0o (Octaより) (0で始める方が先に生まれた) |
0x (Hexより) |
これらの接頭辞を数値プレフィックスと呼ぶ。
これらの接頭辞をつけた適当な値を定義して出力しようとしても、内部的には同じ値なため、10進数として出力される。Javaにとっては全て10進数で同じ値である(デフォルトが10進数なので出力も10進数である。)
当然だが、2進数では2以上の一桁の数字は使えず、8進数では8、9の数字は使用できない。その際数字プレフィックスを使っていたら、コンパイルエラーとなる。
実践プラクティス
public class Main {
public static void main(String[] args) {
int A= 0b1111_111;
A++;
System.out.println(A);
}
}
実行結果:128
自動で10進数に戻ることを確認した。
参照型
参照型を変数に代入する際、インスタンスの生成を行います。
インスタンスの生成の際、変数が確保したメモリとはまた別のメモリにインスタンスを作成します。
通常、基本型は値を直接変数が確保したメモリにコピーします。
対照的に、参照型では、ハッシュコードを型宣言のときに変数が確保したメモリに格納します。ハッシュコードを元に値を確認するため、参照型と呼ばれます。
この違いによって、コピーの動きが変わってきます。
基本型の変数に対して基本型を代入し、変数を別の基本型変数へ代入すると、その基本型の変数同士は別のメモリに最初に渡されたデータをコピーします。この時、片方に変更を加えても、もう片方のメモリは独自にデータを保持しているので、関係はありません。
逆に参照型でこの動きと同様のことをした時、メモリはお互いに同一のハッシュコードを保持し、同一の値を参照しています。そのため、参照先の値の変更は両方の変数から確認できます。
フィールド変数
フィールド変数とは、クラス内部かつメソッドの外部で宣言される変数の総称を言います。
コンストラクタ内部で定義したものはローカル変数であり、フィールド変数ではありません。
フィールド変数は外部からのアクセスが可能で、アクセス修飾子はすべて使用可能です。
また、finalとstaticも使用可能です。
フィールド変数は、final修飾子を使用して定数化しない場合、初期化をしなくても問題ありません。
その場合、それぞれの変数型に応じた初期値が代入されます。
概ね、0とnull,falseが入るという認識で間違いないと思います。
同一クラスのフィールド変数名同士で同一の名前を使用することは禁止されています。
ローカル変数
ローカル変数とは、メソッド内で宣言される変数の総称を言います。
メソッドの引数も同様にローカル変数です。
ローカル変数は、そのスコープ内からのみアクセス可能です。内部の変数の処理は外部から関与できないので、これも一種のカプセル化と言えると思います。
ローカル変数はフィールド変数と違い、初期化が必須です。
アクセス修飾子はデフォルトのみが使用可能です。内部の変数は外部からアクセスできないのが基本となっているので、アクセス修飾子を使用する意味もないということでしょう。
また、final修飾子は使用可能ですが、static修飾子は使用できません。static修飾子が使用できないのは、前述の、「内部の処理には関与できない」という設計上当然になるかと思います。
変数名は、フィールド変数名と重複可能ですが、
this
フィールド変数とローカル変数を見分けるために使用します。
this.numberというふうに書けば、フィールド変数numberを指定しているとJavaは認識します。
反対に、numberとだけ書けば、ローカル変数numberを指定していると認識します。
コンストラクタの呼び出しにthis()というものもありますが、概ねこのクラスのインスタンスを表す単語であるという認識で問題ないと思います。
また、変数名がローカル変数とフィールド変数で重複していない場合、フィールド変数を呼び出したい時にthisを使用しなくても問題はありません。
しかし、フィールド変数であることが読み手にわかりづらく、可読性が落ちることもあるので、基本的にはthisを使用した方が良いでしょう。
基礎的な構文
switch文
構文は以下
switch(引数){
case 1:
//処理1;
break;
case 2:
//処理2;
break;
default:
//処理3;
}
switch文にはcaseとして指定できるのは以下のものです。
- 数値 32bit以下の整数
- 文字 文字列も含む
- 定数(final)
逆にcaseとして指定できないのは以下になります。
- 小数であるfloat,daouble
- 64bitであるdoubleとlong
- 真偽値
また、同じ値をcaseに含むとコンパイルエラーとなります。
duplicate case label
また、引数とおなじ、もしくは暗黙のキャストができない場合もエラーになる。
incompatible types: int cannot be converted to String
これはStringを引数に渡して判定するとき、caseがintであったときに出てきたエラーです。
returnを返すとswitch文は中断されます。
これはswitch文に限らずだが、returnの後にテキストを書くとエラーになリマス。。
unreachable statement
これがエラー文です。到達不可能とのことです。
default文はどこにでもおけるが、フォールスルーが発生します。
これはbreakを置かない場合と一緒です。
ただし、dafault文はどこに記述したとしても、caseが全て一致しなかったときに実行されます。
break;
これを忘れると条件を満たしたあとの文章を全部実行してしまいます。
資格試験のときは注意しましょう。
これをフォールスルーと呼びます。
実はcaseはラベルだったらしい。マジ?
Java SE12よりの新要素
String A = “QQ”
String a = switch(A){
case “A”,”B” -> “Hello”;
case “E”,”G” -> “Yahoo”;
default -> “yeah”;
通常switchとの違いは以下です。
- breakを記述しなくても良くなりました。
- 今までcaseを必ず記述しなくてはいけなかったものが、コンマで並列可能になりました。
- アロー演算子というものを使うようになりました。ラムダ式等で使用されているものですね。
- 戻り値を返すことが可能になりました。
for文
for文の形として、以下である。
for(初期化式 ; 条件式 ; 継続式)
並列記述
- 初期化式は型が同一であれば並列して記述可能です。
- 条件式は論理演算子を含めば並列して記述可能です。
- 継続式は基本的に何でも並列記述可能です。
- 初期化式と継続式は、コンマを用いて並列が可能です。
省略 - forの初期化式、条件式、継続式の全ては省略可能です。
- 条件式の省略 : 常にtrue、無限ループになります。
- 初期化式の省略 : 特に何もなし。
- 継続式の省略 : 特に何もありません。
初期化式は、for文の実行の最初に行われます。ここで変数の宣言を行うことが多いです。ここで変数の宣言をする際は、forの中にだけスコープがあることに注意してください。
条件式は==等、boolean値を戻り値で返す必要があります。単一のイコールだけではエラーが発生しますので注意してください。boolean値を返すメソッドの実行も可能です。
条件式では、継続式でインクリメントを用いる際、<や<=等の処理を行うことが多いです。ループ回数の指定はiを0と指定して、i<n(iがn以下)と条件式を設定すると、n回動作してくれます。条件式は毎回のループの一番最初に確認され、条件式がfalseを返した場合終了します。(前置判定とも呼びます。)
継続式は、forのブロック内のメソッドが終了した時に行われます。
流れとしては以下のようになります。
初期化式(並列可能、同じ型のみ可能)
↓
条件式(並列可能、ただし論理演算子のみ可)
↓
ブロック内メソッド
↓
継続式(インクリメント等が用いられる、同じ型のみ可能)
↓
条件式
使い方としては基本的に固定の数字まで処理を回すことが多い。
この初期化式に、System.out.println()メソッドを複数並列して記述しても、問題ない。ただし、変数の型が違うものの宣言と初期化はエラーが出るようだ。
また、継続式にもSystem.out.println()などの式を書いても問題ない。種類問わず並列可能である。
拡張for文
拡張for(型 変数名 : 配列系統のやつ) {}
処理
例えば、以下のような拡張for文を考えてみる。
class Member{
private String name;
private int age;
Member(String name, int age){
this.name = name;
this.age = age;
}
public int getage() {
return this.age;
}
public String getname() {
return this.name;
}
}
public class Main{
public static void main(String[] ホゲホゲ) {
Member[] a = { new Member("太郎" , 11) , new Member("はなこ" , 12) , new Member("先生" , 25)};
System.out.println(a.getClass());
for(Member memberlist : a) {
System.out.println(memberlist.getname() + memberlist.getage());
}
}
}
class [Lmy.name.Member; 太郎11 はなこ12 先生25
これは、クラス型(オブジェクト型)の配列を作成し、拡張for文によってそのクラス型の一つを変数に参照を代入し、クラス型に定義されているゲッターで値を取って出力しています。
ちなみにMemberクラスは外部クラスですが、クラスファイルにエントリーポイントがすでに記載されています。
publicをつけると失敗するので、注意が必要です。これはトップレベルクラス等の概念を確認してください。
また、エントリーポイントが別のファイルにあったとしても、ファイル名とクラス名を統一しなければpublicで修飾できません。
while文(do-while文)
while文
構文は以下になります。
while(条件式) { }
do-while文の構文は以下になります。
do{ }while(条件式);
whileはループ処理に入る前に条件式を評価し、trueを返した場合実行します。do-whileはループ処理を一度行った後、条件式を評価し、trueを返した場合もう一度実行します。
使い分け
forとの使い分けについて色々な条件式を満たしたらfalseを代入する、もしくはbreakする、が一番ベストな使い道に思う。
基本trueであればどこの条件を満たせばいいか中を見ればわかる(複雑でなければ条件式の中に書くのがベストではあるが)
whileとdo-whileの使い分けについて、do-whileは必ずブロック内のコードを実行するため、一度でも実行が必要な場合にはdo-whileで、実行が必ずしも必要でなければwhileを使うと良いとのこと。
二重ループとラベルとbreakとcontinueとラベル
簡単にまとめると、continue;だとインクリメント回数が保存されるが、ラベルのついたbreakだとそのラベル前までインクリメント回数が保持されず、再度仮変数が作成され、初期化されます。
そもそもbreakとは、ループを脱出するもので、ラベルは、その部分の外側へと処理を移すものです。
ただし、内側のforのラベルに対してbreak;した場合は外側のカウントも進行します。
これについては他のループ系制御構文でも同様です。スコープの範囲から一回外に出てしまえばその変数はなかったことになります。
浮動小数点をカウンター変数として設定した場合、小数点以下をJavaでは厳密に表現できないため、forの挙動が予想していなかったような挙動となる可能性があることに留意する必要があるようです。
カウンター変数は増減式のみで更新する方が良いコードとのことです。
ブロックを省略して継続式を任意の回数実行する場合、文末はセミコロンとなります。(ブロックによってセミコロンを省略可能なのであって、ブロックがない場合、メソッド扱いと考えても良いでしょう。
Array と ArrayList の違い
日本語でArrayは配列等と訳され、この辺りの違いがごちゃごちゃしてしまうことが非常に多い。
それぞれの型宣言の違いから、メソッド等にも触れて違いを明確化する。
int[] →配列
ArrayList →リスト等
概ね配列と言われたら、言語仕様で定義されている方と認識すれば良いと思います。
Array
- int[] a = new int[]{};
- int[] a = new int[3];
- int[] a = {};
この時、以下に注意する。 - 右辺で数字を指定しない場合、ブロックが付属しなければエラーになる。
int[] a = new int[]; //これはエラー。eclipse上ではディメンション式の定義が必要と出る。 - 左辺の[]は型の部分にも変数名にも記述可能。分けても問題ない。
int[] a[] = new int[][]{}; //実行可能 - 配列は固定長である。
int[] A = new int[3];
A.add(1); //コンパイルエラー
int[] A = new int[3];
System.out.println(a.length); //出力は3
int[][] A = new int[][2]//コンパイルエラー、一次元目を定義せず、二次元目を定義できない。 - これは、配列はオブジェクトであり、二次元目の定義を無視して二次元目より大きい配列を一次元目の要素に挿入できることから生まれた使用であると思われる。
- つまり、new int[3][2]は、配列を三つ作成し、それぞれの要素が長さが2の配列を代入され、それを参照しているだけと言える。
- 当然、配列ごと入れ替えて仕舞えばサイズの定義は変わる。
- 配列の要素数の定義と要素の代入を一度に行うのは許可されない。
int[] A = new int[3]{1,2,3}; コンパイルエラー// - Array.mismatchでは、一致しない要素の一番若い番号を返す。
- 配列の初期化と宣言を別で行うとエラーが起きる。
int[] A;
A = {2};//コンパイルエラー
別で初期化する場合、new int[]のように配列インスタンスの生成が必要である。
また、 - 配列の要素数を決定した場合、そこには初期値が入る。
*配列は固定長だが、immutableオブジェクトではない。入れ替えることが可能だからである。sort等も適用できる。 - 可変長引数として受け取られた引数は配列となる。
- 配列でオーバーライドされているcloneメソッドは以下の特徴がある。
* clone対象がオブジェクトであれば参照をそのままコピーする
- clone対象がプリミティブ型であれば値をそのままコピーする。この場合変更はclone元に反映されない。
- new int[]{} これは無名配列の生成と呼ばれる。無名配列はこの{}部分である。
- 配列の要素数は固定であり、定義された要素より外へアクセスしようとした時、例外がスローされる。ArrayIndexOutOfBoundである。
- 配列もオブジェクト(参照型)なので、配列自体を初期化しなければ、フィールド変数で宣言した配列はnullである。また、
その時は要素がnullとは違ってadd等の値の処理も使えない。代入のみ可能。
class Main{
public static void main(String[] ホゲホゲ) {
Object[] a = new Object[4];
for (Object b : a) {
System.out.println(b);
}
}
}
実行結果
null
null
null
null
```Main.java
class Main{
public static void main(String[] ホゲホゲ) {
int[] a = new int[4];
for (int b : a) {
System.out.println(b);
}
}
}
実行結果
0
0
0
0
- 配列は言語仕様に含まれた仕様である。
ArrayList
-
ArrayListはListインターフェースを実装している。
List A = new ArrayList(); //ほとんどのメソッドはListインターフェイスで定義されているため、問題なく実行できることが多い。 -
ArrayListはジェネリクスの実装が可能。左辺にジェネリクスの型指定があれば成立する。
ArrayList<> a = new ArrayList<>(); //コンパイルエラー
ArrayList<> a = new ArrayList(); //コンパイルエラー
ArrayList a = new ArrayList<>();
ArrayList a = new ArrayList(); //これら二つもコンパイルと実行は可能。
ArrayList a = new ArrayList(); //これら二つもコンパイルと実行は可能。 -
ArrayListは動的であり、長さは自由に変更可能である。
ArrayList A = new ArrayList<>();
A.add(“問題ない”); //エラー、例外ともに無し。 -
ArrayList型は、配列のように要素は取り出せず、getを指定する必要がある。
ArrayList A = new ArrayList<>();
A.add(“問題ない”);
System.out.println(A.get(0)); //出力[問題ない]
なお、この時、A.get(1)ではIndexOutOfBoundsExceptionエラーが出る。要素数の指定をしない場合、常に要素数は最適化された状態でArrayListは保持される。 -
ArrayListは要素数の初期化が可能。(引数部に代入可能)
ただし、要素が決定されていない部分にset,addメソッドは使用不可能 -
ArrayListのgetメソッド等はnullに対しても使用可能。
-
拡張forを使う際はジェネリクスで宣言した型を変数の型宣言として用いる必要がある。
-
参照型を要素として保持する場合、その参照型のクラスが比較可能であることを実装していなければ、ソートができない。基本型はソートが常に可能である。
-
ArrayListはlengthが使用できず、sizeというメソッドによって要素数を見ることが可能である。
-
ArrayListは要素の取得はArrayのようにはできず、getメソッドによって行える。
A[1] //コンパイルエラー
A.get(1) //正しい -
ArrayListの要素数は可動的だが、固定長のArrayListも作成可能。
Array.asList() //引数に配列を使用、戻り値として固定サイズのリストを返す。これをnew ArrayListの引数として使用することで、固定長のArrayListが作成可能である。
List.of() //引数に配列を使用。戻り値に固定サイズリストを返す。 -
固定サイズのリストに対してremoveやaddを行うとunsupportedExceptionである。ただし、replace等の要素数の変化がないものは受け付ける。不可変なオブジェクトというわけではないのだ。
-
list.forEach()の引数にはConsumer型インターフェースが規定されているため、これによってラムダ式を引数の中で定義可能である。
これはコレクションクラスの階層構造を図にしたものです。

.javaファイル

このCircleApp.javaであったり、Main.java等のファイルのことを指します。
(これ実際にはなんて言うんだろう。)このファイルにはそれぞれトップレベルクラス(publicの修飾子がつくやつ)であったり、インターフェース、抽象クラスが定義可能です。
抽象クラスとトップレベルクラス、インターフェースはそれぞれ併存が可能ですが、トップレベルクラスだけは複数作成できません。内部クラス、staticクラス等はJava Silverの範囲ではありませんが、コードを書く際はこれはトップレベルクラスであると意識しながら書いた方が役割が明確化するかと思います。
ここからは、トップレベルクラス、抽象クラス、インターフェースの制限について簡単にまとめていきます。
使用可能なアクセス修飾子について振れていますが、おそらくJava Silverの範囲では問われることは無いため、抽象クラスとインターフェースの特徴だけを掴んでおけばおおむねが把握できるはずです。
トップレベルクラス
.javaファイル一つに対して一つしか定義できないものです。ファイル名に対して同一のクラス名であることが求められます。

public型であるものが内部的にトップレベルクラスであると判断されます。

補足ですが、内部クラス(クラス内に定義されるクラス)では、private,protectedの修飾子を使用できません。
- 使用可能な修飾子はpublic,final(そして抽象クラスであることを規定するabstract)の三つです。
- トップレベルクラスは抽象メソッド(実装を持たないメソッド)を保持できません。
- publicではなく、修飾子無しを定義することも可能です。その場合他にpublicなクラスがあれば、そちらをトップレベルクラス(.javaファイルと同一の名称を要求)とします。
抽象クラス
抽象クラスは、実装を持つメソッド(具象メソッド)と抽象メソッドを保持できます。

抽象クラスもpublic修飾子を使用するとトップレベルクラスとして判断されるようで、共存できません。
実装を持つメソッドというのは、メソッド名と{}(ブロックと呼びます。初期化,forの範囲の規定,メソッドが保持するローカル変数の有効範囲(スコープ)を規定します。

Cメソッドは、abstractを規定されていないのにも関わらず、{}ブロックを省略しているのでエラーが発生します。
Eメソッドはabstractを規定しているのにも関わらず、{}ブロックを省略しているのでエラーが出ます。
抽象クラスの特徴はこの四つです。
- インスタンス化できません。
- 静的メソッドは規定できます。
- 抽象メソッドは{}実装を保持できません
- 抽象クラスは、抽象メソッドを必ず一つ持つ必要があります。
- 抽象クラスは、継承(extends)が前提となるクラスです。
- 抽象クラスは、フィールド変数を定義できます。
- 抽象クラスは、コンストラクタを定義可能です。
インターフェース
インターフェースは、defaultとstatic以外に実装を持つメソッドを持たないクラスです。
インターフェースの特徴は以下の四つです。
- 実装を持つメソッドを保持できません
- 保持できるメソッドは、publicかつabstract(もしくは上記のdefaultかstatic)です。
- publicとabstractは省略可能です。これは省略した場合、自動的に補完されます。
- インターフェースは多重実装、多重継承が可能です。
- インターフェースは、定数(final)で静的(static)なフィールド変数のみ定義可能です。
- インターフェースのフィールド変数のfinalとstaticを省略した場合、自動で補完されます。
- 多重継承を行った時、複数のインターフェースが同じ識別子のフィールド変数を保持していた場合、エラーが発生します(曖昧なフィールド呼び出し、などと呼ばれます。)
- インターフェースの実装を持たないメソッドをオーバーライドした場合、アクセス修飾子はpublicのみ規定できます。
コンストラクタ
コンストラクタとは、クラスのインスタンスを生成するときに必ず使用されるメソッドっぽい何かです。クラスインスタンスの初期化の際に必ず使用されるメソッド、という認識で概ね間違いはないかと思います。
コンストラクタは次の条件を満たします。
- 戻り値を持ちません。
- コンストラクタを作成しなかった場合、引数なしのデフォルトコンストラクタが自動で追加されます。
- コンストラクタは、所属しているクラスの名前と一緒でなくてはいけません。
- コンストラクタを持つクラスが継承されたとき、サブクラスは必ず、親クラスのコンストラクタを呼び出します。明示的に追加しなかった場合、必ずsuper()という親クラスの呼び出しが補完されます。このとき、引数を持たないコンストラクタを所持していない親クラスであれば、super()の呼び出しによってコンパイルエラーになります。
- コンストラクタを呼び出すことも可能です。このとき、this()を使用します。
- 二階層上の親クラスのコンストラクタを明示的に呼ぶことはできません。
- コンストラクタはオーバーロード可能です。
- コンストラクタの呼び出しは、必ずメソッドの処理、コンストラクタの処理の一番最初に行う必要があります。
- コンストラクタにはアクセス修飾子が使用可能です。仮にprivateを使用した場合に外部でインスタンスを作成しようとするときを考えます。このとき、同一クラス内に静的メソッドを作成し、そこからインスタンスを作成することが可能です。
メソッド
ここでは改めてメソッドについてまとめます。
- メソッドは、戻り値を必ず規定する必要があります。
- メソッドは、通常実装({})を持たなければいけません。
- メソッドは、通常アクセス修飾子の全てを規定できます。
- メソッドは、通常(final修飾子を使用しない場合)オーバーライド可能です。
- メソッドは、オーバーロード可能です。
オーバーライド
クラスの継承、抽象クラスの継承、インターフェースの実装において、メソッドのオーバーライドが可能です。
オーバーライドは、継承、実装元で定義されたメソッドのシグニチャに基づいて、別の処理を書くことを指します。この機能を使用すると、ポリモーフィズムに基づいて、継承元のクラス(親クラス)の型で継承先のクラス(子クラス)のインスタンスが、継承元の保持しているメソッドを使用しようとした時、子クラス側で定義したメソッドの処理が実行されます。
メソッドのオーバーライドは、以下の条件を満たしている必要があります。
- メソッド名、引数の型と数、戻り値がオーバーライド元と等しいこと
- オーバーライドは、継承元メソッドの引数に対してジェネリクスが設定されていた時、それを変更してはいけません。
- 戻り値の型のみ、サブクラスの型を許容します。(共変戻り値)
- 戻り値の型に対してジェネリクスが定義されていたとき、そのジェネリクスが元のジェネリクスサブクラスになることは許容されません。
- オーバーライド元のアクセス修飾子よりも、オーバーライドしたメソッドのアクセス修飾子がゆるくなること。
実践プラクティス

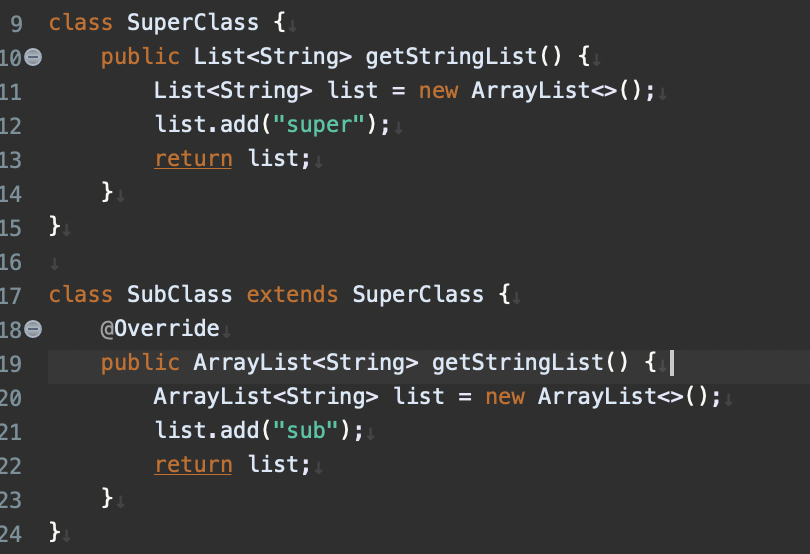
共変戻り値を使用して、ListのサブクラスArrayListに戻り値は変更可能ですが、ジェネリクスは変更できません。
オーバーロード
クラスが保持するメソッドに対して、引数の型、数が違うメソッドを定義することで、違う処理のメソッドとして定義することが可能です。これをオーバーロードと呼びます。
オーバーロードは以下の条件を満たしている必要があります。
- メソッド名が同一である必要があります、(メソッド名が違えばそもそも違うメソッドです。)
- メソッドのシグネチャのうち、引数の型、もしくは数が違う必要があります。
- 戻り値はオーバーロードの要件に含まれず、同一のメソッド名でも違う戻り値を返すことが可能です。
オーバーロードの際、引数の型パラメータのみが変更されるのはオーバーロードの要件を満たさないため、コンパイルエラーが発生します。
StringとStringBuilder
ざっくりいうと違いは可変なインスタンスを作成するのか不可変なインスタンスを作成するかの違いですが、大事です。概ね両者の処理は共通しますが今回はString型に準拠して説明します。(StringBuilderはほとんどJava Silverでは問われないかと思います。)
-
判定
通常参照型で同一かどうかは==演算子で確認します。
StringやStringBulderでは、equalsメソッドがオーバーライドされていて、equalsメソッドによって同値であることを確認可能です。
Objectクラスのequalsは同一であることを判定するメソッドです。(instanceOfで判定している。)
Stringクラスのequalsメソッドは大文字と小文字の区別を行います。
大文字と小文字の区別を行わない、equalsIgnoreCaseメソッドも用意されています。 -
キャスト
String型へ数値のキャストを(String)で行うことはできません。
String型は valueOfでキャストと同様の処理を行うことが一般的です。
数値がそのままprintできるのはvaluOfメソッドでキャスト(意味は違いますが…)を内部的に行っているからです。 -
可変、不可変
Stringは不可変の値で、StringBuilderは可変の値です。
可変の値であるとき、Stringクラスに用意されているメソッドは戻り値としてStringの変化分を渡し、参照元のStringの値は変化しません。
String以外にはLocalDatetimeなどが不可変、immutableと呼ばれます。
StringBuilderは可変であるため、参照元のStringBuilderクラスオブジェクトが用意されているメソッドによって変更されます。
メソッド
-
a.intern() コンスタントプールにすでに同値のStringオブジェクトがある場合、そこへの参照を戻り値として返します。
-
比較
StringクラスでオーバーライドされているcompareToメソッドは、主体の文字列オブジェクトに対して引数のオブジェクトがabc順で遅ければ正の数を、早ければ負の数を返します。重要なのは、正数と負数と規定されているだけであり、1,0,-1と戻り値の絶対値が規定されているわけではない点です。
StringクラスのcompareToメソッドは、大文字小文字を区別する。区別したくない場合、compareToIgnoreCaseメソッドが用意されています。 -
含まれるかどうかの判定
startwith(),endwith(),contains()
boolean値を返すメソッドです。引数のStringが含まれているかどうか判定します。 -
replace,replaceAllメソッドの違い
replaceAllは正規表現での検索が可能です。replaceは正規表現での検索ができません。最初に出現した文字列の置換はreplaceFirstというメソッドがあります。 -
substringメソッ
文字列から文字列を切り出して返します。
範囲を指定するのですが、その文字数の数え方が独特で、この画像のような数え方をします。

引数を一個指定する方法と、二個指定する方法でオーバーロードされています。
一個のメソッドは、その文字数の部分から最後までを切り出す処理を行います。

String型はCharSequenceを実装したものです。
抽象メソッドはオーバーライドされているはずなので、確認してみてください。


ComparatorとComparable
ComparatorとComparableは、自作クラスのインスタンスをリストにいれ、順番を入れ替えることが必要になったときに使用します。どちらかを使用しなくては、自作のクラスの順番を入れ替えることはできません。順番を整理するときは、sortメソッドを使用します。

Comparableインターフェース
Comparableは比較対象となるクラスに対して実装するインターフェースです。
このインターフェースを実装するときは、compareToというメソッドの実装を持つ必要があります。
compareToメソッドの内部処理を記述する際、三項演算子を使用することがかなり多いです。なので、三項演算子にも触れつつ、解説を書いていきます。
三項演算子(補足)
三項演算子は、以下のような書き方をします。
boolean ? A:B
boolean値がtrueを返せばAの処理をして、falseを返せばBの処理を行います
通常、sortを行う際、戻り値が負であれば順番は変更せず、戻り値が正であれば順番を入れ替え、0であればいい感じの処理を行います。
数字の大小を比較して、通常通り-1,0,1を返す場合を三項演算子を用いて考えてみます。
オブジェクトが表す数値が第二引数より大きかった場合、1を返すとすると次のように書けます。
this.Number > Number ? 1 : B
次にBの処理を考えます。前提条件から、同一であったときは0を返し、違うのであれば第二引数の方が大きいことになります。それは、三項演算子を用いて次のように書けます。
this.Number == Number ? 0 : -1
三項演算子を組み合わせて、一つの式とすると、次の式が完成します。
Number1 > Number2 ? 1 : (Number1 == Number2 ? 0 : -1)
これをcompareToで実装すると、以下のようになる。
public int compareTo(Member m){
return compare(this.age,m.age);
}
private int compare(int age2, int age3) {
return (age2 > age3)? 1 : ((age2 == age3)? 0:-1);
}
通常、メソッドのオーバーロードを用いれば、引数に応じて返す値も変えられます。
リストのソートを行う際、内部的にクラス内部で利用されているcompareToを呼び出し、順番を決めるために必要な情報を手に入れます。
そのため、複数のcompareToが実装されていると例外をスローします。これは引数のArrayListインスタンスだけではどのcompareToを使用すれば良いかわからないためです。曖昧なメソッド呼び出しと同様のようです。
Comparatorインターフェース
Comparator というインターフェースを別のクラスで実装する手段もあります。
これはインスタンスに対して定義されたsortメソッドを利用するために必要なインターフェースです。
インスタンス名.sort(comparator実装クラスのインスタンス)でソートが可能である。
Comparatorは関数型インターフェースでもあるので、インスタンスを使用せず、ラムダ式を用いることで行数の削減が可能です。
インスタンス名.sort(ラムダ式)
Comparatorを用いてsortを行うときは、Comparatorの戻り値に従って順序を入れ替えています。
- o1 が o2 より小さい場合は、負の整数を返します。 →このとき、順序は変更されません。
- o1 が o2 より大きい場合は、正の整数を返します。 →このとき、順序はo2が前に移動します。
- o1 が o2 と等しい場合は、0を返します。→このとき、順序は変更されません。
今判定を一つずつ行い、順序の並び替えが行われます。
comparatorの戻り値の値を反対にすれば、順序も反対になります。
また、Arrayクラスのcompareメソッドは、概ねCompareToと一緒です。
第一引数が第二引数より先なら負の値、第一引数が第二引数より後なら正の値です。
先なら負、後なら正。昇順なら負、降順なら正。として考えると概ねの統一した理解が可能かと思います。
参考
Java公式API SE11: sort
Java公式API SE11: Comparable
Java公式API SE11: Comparator
Qiita : Java ComparableとComparator どちらを使うか
検査例外と非検査例外
Javaでコードを書いていると、ExceptionとErrorと二つの言葉を目にすると思います。Errorは大概文法がおかしいコンパイルエラーなのですが、Exceptionは
検査例外と非検査例外の二種類ある。
基本的に、検査例外を作成する時はRuntimeEception以外を継承し、非検査例外を作成するときはRuntimeExceptionを継承する、と考えると良いと思います。
検査例外をthrowする(throwするとは、アプリケーションの外に出す、のような意味があると思われます。)ときは、try-chachの構文を使用するか、throws句をメソッドに追加させる必要があります。例外をthrowするとは、例外を発生させるという意味で使用されることが多いようです。
検査例外とは、コンパイル時に補足される例外のことを指します。
非検査例外とは、コンパイル時には補足されない例外のことを指します。
検査例外はJava Silverの範囲であれば、自ら例外を作り出してthrowすることのほうが多いと思います。検査例外をthrowするには、次の二つをどちらか満たしていなくては、コンパイルエラーとなります。
- throws句を使用する
- try-catch句の中で例外をthrowする
一つずつ簡単に解説を入れます。
例外のthrows
public void a()throws Exception{
throw new Exception();
}
throws句はメソッドの引数宣言の後に記述可能な構文です。
try-catch句の中でthrowするわけでないのであれば、throws句のみの使用でコンパイルエラーにはなりません。ただし、このメソッドはtry-catch構文の中でのみ使用可能です。
ここでthrows句として宣言された検査例外は、実際にthrowしている例外に問わず、それそのもの、もしくはより上位クラスとして補足されなければいけません。
throwsで宣言してある例外と、その下位クラスのみthrow可能です。
例外のtry-chach
public void a(){
try{
throw new Exception();
}catch(Exception e){
}
try部分で、検査例外が発生する記述を行い、発生したときの記述を行います。
この構文の中で検査例外をthrowする場合、メソッドにはthrows句を記述する必要はありません。catch句では、例外の論理和として「|」の演算子が使用可能です。
ただし、この演算子は、継承関係にある例外同士には使用不可能です。
実践プラクティス
class test {
test() throws IOException{
throw new FileNotFoundException();
}
}
class Main{
public static void main(String[] ホゲホゲ) {
try {
test a = new test();
}catch (FileNotFoundException e) {
System.out.print("大丈夫じゃん!");
}
}
}
実行結果 : Exception in thread "main" java.lang.Error: Unresolved compilation problem:
処理されない例外の型 IOException
throwsで宣言した検査例外は、catchが可能であることを明示しなくてはならない。
class test {
test() throws IOException{
throw new FileNotFoundException();
}
}
class Main{
public static void main(String[] ホゲホゲ) {
try {
test a = new test();
}catch (FileNotFoundException | IOException e) {
System.out.print("大丈夫じゃん!");
}
}
}
実行結果 : Exception in thread "main" java.lang.Error: Unresolved compilation problem:
例外 FileNotFoundException はすでに代替の IOException でキャッチされています
論理和でスーパークラスとサブクラスを並べるとエラーが発生してしまう。
到達不可能
到達不可能な場合コンパイルエラーである。
例えば以下のような場合。
try{
}catch(RuntimeException e){
}catch(NullPointerException e){
}
これはRuntimeExceptionがNullPointerExceptionのスーパークラスであるため、NullPointerExceptionの例外がスローされても、RuntimeExceptionでキャッチされてしまうため、NullPointerExceptionでキャッチする部分が到達不可能になってしまう。
このような場合はコンパイルエラーになるため、順番を逆にするなどの対応が必要である。
ただし、RuntimeExceptionは非検査例外であるため、try-catchの中で補足する必要はないため、実際にはこのような構文は使用しない。
例外はざっくりとこのような階層構造となっています。

NullPointerException
オブジェクトが必要な場合に、アプリケーションがnullを使おうとするとスローされます。 ややこしい部分なので、公式から説明を持ってきました。
- nullオブジェクトのインスタンス・メソッドの呼出し。
- nullオブジェクトのフィールドに対するアクセスまたは変更。
- nullの長さを配列であるかのように取得。
- nullのスロットを配列であるかのようにアクセスまたは修正。
- nullをThrowable値であるかのようにスロー。
引用 : NullPointerExceptionについての説明
tryはcatchもしくはfinally抜きでの記述はできない。try-finallyのみでの記述は可能。
try-with-resouces構文
try(リソース){}
リソースでは、ファイルを開いたり閉じたりする操作が行えるオブジェクトが宣言され、基本的に開かれる処理が行われると思います。
この構文ではこのファイルをtryブロックが終了したときに自動的にクローズします。
リソースは、AutoCloseableを実装するオブジェクトであることが条件です。
このtry構文でもfinally句は記載可能であり、その場合ファイルが閉じて最後に実行されます。
throws
throwsは、try catchの中以外で例外をthrowする場合に必要な言葉で、なければエラーになる。
逆に、try catchの中でいくら検査例外を投げていてもthrowは必要ない。
try-catchブロックはオーバーヘッドが大きくかかるため、なるべく避けるようにする。
class test {
test() throws IOException{
throw new FileNotFoundException();
}
}
class Main{
public static void main(String[] ホゲホゲ) {
try {
test a = new test();
}catch (FileNotFoundException e) {
System.out.print("大丈夫じゃん!");
}
}
}
実行結果 : Exception in thread "main" java.lang.Error: Unresolved compilation problem:
処理されない例外の型 IOException
throwsで宣言した検査例外は、catchが可能であることを明示しなくてはならない。
class test {
test() throws IOException{
throw new FileNotFoundException();
}
}
class Main{
public static void main(String[] ホゲホゲ) {
try {
test a = new test();
}catch (FileNotFoundException | IOException e) {
System.out.print("大丈夫じゃん!");
}
}
}
実行結果 : Exception in thread "main" java.lang.Error: Unresolved compilation problem:
例外 FileNotFoundException はすでに代替の IOException でキャッチされています
論理和でスーパークラスとサブクラスを並べるとエラーが発生してしまう。
例外はざっくりとこのような階層構造となっています。
コンパイルエラーか実行時エラーか
コンパイルエラーは、コンパイル時に明確な文法の違いや参照先の有無を確認して、間違いがあった時に吐き出すものであす。
例外は、文法や参照先の有無としては正しいが、参照先があったとしてもnullであったり、メソッド自体は存在するがそれに対しては不適用であったり、そういった時に例外が発生します。コンパイル時に確認可能なものは検査例外となります。
簡単な例外の表を作成しました。
-
明示的なキャストをしたけど依存関係がない → ClassCastException
-
Listof,AsList等の固定長でremoveを行った → UnsupportedException
-
nullを参照した → NullPointerException
-
String型へ明示的にint型(というか数字全般)をキャストした -> NumberFormatException
-
引数が不適、例えば配列の要素数に-1等負の数を指定したとき。→ IllegalArgumentException
-
配列の要素外アクセス→ArrayIndexOutOfBoundException
-
Stringの要素外アクセス→StringindexOutOfBoundException
-
それ以外の要素外アクセス-> IndexOutOfException
-
文法が間違っている → コンパイルエラー
-
検査例外をスローするのにthrows句の挿入、もしくはcatchでの例外を捉えることができていない。→ コンパイルエラー
-
ビット落ちが発生する処理がある→コンパイルエラー(例: short <- int)ただし、暗黙的に変換可能であればそのまま処理が可能
-
アクセス修飾子が不適→コンパイルエラー
-
引数が間違っている→コンパイルエラー
補足
なお、この際、引数として変数を渡す場合、インスタンスのクラスを参照するのではなく、変数宣言の際定義したクラスの型依存であるため、サブクラスの引数定義でスーパークラスの型宣言の変数でサブクラスのインスタンスが入っている変数を代入しようとするとエラーになる。キャストは自動で行われない。
エラー
ほとんどJavaSilverの範囲では触れられないかと思いますので、特徴を簡単にまとめて終わりとします。
- エラーは、プログラムの実行環境に例外が発生したときにスローされます。
- エラーは全てErrorクラスを継承しています。
- エラーはthrows句に宣言する必要はありません。
- エラーは例外処理を記述可能です。
ラムダ式
ラムダ式は関数型インターフェースと呼ばれる、抽象メソッドが一つのみ定義されているインターフェースを用いて利用することができます。
ラムダ式は通常、次のような構文で表されます。
()->{}
ラムダ式は、左側の()に引数の名前を定義し、右側に処理を定義します。
この括弧は一定条件のもと省略が可能です。
ラムダ式は型と変数名を定義して、クラスが持つ処理として実装可能です。
Function a = (String b) → {return b.length();}
この構文によって、インスタンスaは、もともと定義されていた一つのメソッド名の処理が決まります。
また、引数にラムダ式を受け付ける場合もあります。
例えば、Comparatorインターフェースは関数型インターフェースなのですが、リストのソートにこの関数型インターフェースを型として受け付ける.sortメソッドがあります。
このsortメソッドの引数にラムダ式()->{}を代入しても問題なく動作します。
ただし、このような使い方をする場合、メソッド側が定義している、関数型インターフェースの内部実装にシグネチャと戻り値の型を合わせなくてはいけません。
また、引数に関数型インターフェースを指定しており、ラムダ式を引数へ代入できる場合を考えます。この場合、一度ラムダ式で初期化された変数を引数に代入することが可能です。
メソッド参照という仕組みもあり、これはSystem.out::printlnのように、コロンを二つ挿入し、引数の括弧を省略することで機能します。
ラムダ式で使用できる変数は、実質的な定数(finalでなくても、変更が加えられなければ可)のみです。定数以外を処理しようとした場合、コンパイルエラーになります。
また、引数の変数名は、新しい変数名をローカル変数として定義しているに等しいので、ラムダ式を持っているスコープの範囲で同一の名前を宣言していた場合、コンパイルエラーになります。
この関数型インターフェースについては、無名クラス(匿名クラス)などの概念が関わってきます。ただし、その範囲はJava Goldの試験範囲です。
モジュールシステムについて
モジュールシステムとは、Javaのクラスファイルをモジュールとして梱包し、外部からアクセスできる範囲と、そのモジュールが要求する別のモジュールを設定するものです。
モジュールは単品で保守管理が可能でなくてはなりません。(そもそもモジュールシステムはそういったメリットを実現するために生まれたものです。)
Java Silverの試験範囲では、モジュールシステムということでコマンドラインについて問題が出題されると思います。
eclipseやVScodeを使用している場合、コマンドラインを使用することはほとんどありません。
しかし実務で使用する可能性もあるため、全体像を把握しておく必要はあるようです。
requires,exports
どちらもsがつくことに気をつけましょう。
Requiresは他のモジュール名の指定を行い、exportは所属パッケージからどのパッケージを公開するのかを規定します。
オプションとして、export to として、別のモジュール一つにのみアクセスを許可可能です。
##コマンドラインオプション
-d 出力先ディレクトリパスの指定を行います。後置されたものがそのパスになります。
—module -mオプションの完全形です。
-m モジュールを指定して実行するオプションです。後置されたものがそのモジュールになります。
構文 -m モジュール名/完全修飾クラス名
—modile-path -pオプションの完全形です。
-p モジュールのルートディレクトリを指定するオプションです。使用するモジュールが置かれている直上のディレクトリのパスを指定します。
—classpath -cpの完全形です。
-cp クラスファイルや外部ライブラリが保存されているディレクトリを指定するオプションです。
-dオプションを使用する場合 指定ディレクトリ ソースファイルパス の順番になるためかなりコマンドラインが長くなります。
コンパイル時にファイルを生成するという指定がある場合、-dオプションの使用が必要です。(無いファイル上に自動的にコンパイルしてくれることはありません。
実行コマンドについて
①実行コマンド:java ファイル名(.javaなどの拡張子は不要)/java ファイル名.java(拡張子をつけることでコンパイルが不要になる) ②コンパイルコマンド:javac ファイル名.java(拡張子必要) ③モジュールコマンド: jmod
コンパイル時(javac)には.javaの拡張子の付帯が必要です。
その一方で、(java)実行時には.java拡張子が不要です。これは、そもそもクラスファイルの拡張子は.classであることが前提なので、.javaは不適な上に、.classは冗長なので書かなくていいということだと思われます。
クラスパスとモジュールパスの違い
クラスパスは無名モジュール、モジュールに含まれていないファイルの指定に使用します。省略は-cp
モジュールパスはモジュールに含まれているファイルの指定に使用します。省略は-m
どちらもコンパイルにも実行にも使用するオプションです。
モジュールの設定情報
モジュールの依存関係とモジュールの設定情報は違います。
違う点は以下の通りです。
- モジュールの依存関係は、指定したモジュールが何を必要としているのかを調べるのに必要です。
- モジュールの設定情報は、指定したモジュールが何を必要として何を公開しているのかを調べるのに必要です。
module-info.javaを見ると依存関係、require先がわかります。
module-info.javaを見ると、設定情報がわかります。
モジュールの設定情報(モジュール記述子、module-info.java)を確認するコマンドライン
- java —describe-module
- jmod describe
モジュールの依存関係を確認するコマンドライン - jdeps —list-deps
- java —show-module-resolution
補足
package,import,classの順番を聞く問題は頻出っぽいです。(黒本と紫本でよく確認された覚えがあります。) import文がもしなかったとしても、完全修飾クラス名でのアクセスは可能です。(モジュールがrequires,exportの関係をきちんと構築していたらの話ではありますが…。) 名前の解決というワードは常用しません。しかし、概念としてこんな感じかな、くらいの認識はしておけると良さそうです。(テストには出ないが、使用するワードだと独習Javaに書いてありました。)エントリーポイント
Javaで使用可能なエントリーポイントは、次を満たします。
- publicであること
- staticであること
- 戻り値が無い(void)であること
- 引数として、String型の配列、もしくは可変長引数を受け取ること。
エントリーポイントのバリエーションとして、以下の三つを許容します。
public static void main(String args[]) {}
public static void main(String… args) {}
public static void main(String[] args) {}
そして、変数名のargsを変更しても、エントリーポイントとしては影響がありません。Javaでは日本語での変数定義も認められているため、日本語も含むことが可能です。推奨はされません。
以上でJava Silverの範囲の解説で、必要と思った部分は終了です。
間違いなく教科書等での勉強は必須ですが、携帯触っちゃうんだよな…みたいなタイミングで時間を潰してもらえれば良いかと思います。
別枠
Qiitaの書き方でつまづいたこと
ページ内リンクが飛ばない。
公式リファレンスの読み方
以下の点をチェックしてみると良かったです。
- 括弧は半角ですか?
- きちんとリンク先のタイトルと同一ですか?
あとはタイトル指定のシャープに対して、半角スペースを入れましょう。なんか十五分くらい格闘してました。
なんかエンターキーが押せない。
これは書くとき最後まで陥っていました。エンターキーが押せないというよりかは、改行ができない、という方が正しいのですが…。
主に、以下の方法でゴリ押ししていました。
- 行の頭にカーソルを合わせて改行する
-
を用いて改行する - そもそもたくさん改行しておく
データが飛ぶ
Gitみたいに編集履歴がついているわけでは無いので、間違えてタブを閉じてControl+Zでタブを開き直すと、編集が戻っていたり…。それならいいのですが間違えて変更を加えてしまうと、保存されてしまって全部飛ぶという。
あんまりQiita上で文章を書くのは良く無いかもしれません。
あとパソコン二つで開いていると、ロードせずに別のパソコンでいじろうとしたりします。
そうすると別のパソコンが編集したのが全部吹っ飛ぶわけで…。
都合3回くらいやってました。こまめな下書き保存が大事です。
記事書くのしんどい問題
本当は3/28に投稿予定でした。
ただ1回目の試験に落ちたり、記事全部リライトしたり、記事より優先度高いタスク出てきたり…。
毎日投稿とか半端じゃないです。
今回は特定の問題を解決するための記事ではなく、Java Silverで勉強したことの総まとめなので、なおさらモチベも上がらず時間もかかり…。
コンスタントに書き上げたい理想だけがあります。
匿名投稿恐ろしい問題
なんかやべーこと言ってても気づかない可能性が一番恐ろしいですね。
リアネで投稿するのも恐ろしいですが、SNSの投稿と同様でどっからバレるかもわからんですし…。
自我をどの程度出すのかと言う問題も多々あり…。自我出したいけど恥ずかしいし、そもそも自我出す前に読みやすい文章の構成を優先した方がいいでしょみたいなものもあり…。なんとなくはこんな感じで補足に感想を入れるのがベストと言う気持ちです。
向き不向きがあり、かなり不安になります。めちゃめちゃ頑張って書いた文章、すげー読みづらいですし。これに関しては書き続けるしかなさそうですね。ドキュメンテーション能力の向上にもつながるということでモチベーションを上げるしか無いという…。
感想
Java Silver受かってみての感想
役に立ってるかはさっぱりわからんですね。IT、業界が広すぎてどの分野で役に立つのかってわかってから学習したほうが良いような気がします。ただ、こんだけ頭に基本文法叩き込むと基礎力にはつながりそうです。SoringBootとか使おうとすると言語の知識だけじゃどうしようもなかったりしますし。フレームワークの知識が必要で、それはさっぱりJavaの知識じゃないような気がして。でも受かったことで資格試験のモチベーションは上がりました。個人的にはこういうのは学校でドリル解いたらテストの点数上がったみたいな成功体験があるとうまくいく気がします。基本仕様の勉強の仕方を学べるという意味でもいい経験になりました。でも資格試験の受験費用高すぎる気がします。安い方なんですけどね。個人で取るにはかなりの理由がないと出しづらい金額。
ついでに言うと、Java Silverで検索かけても「こんなに短期間で受かりました!」みたいな記事ばっかで腹立ちました。情報系学部卒とは元々の知識量が絶対的に違うので仕方ないのですがね…。
試験を受けるときにJava Silverで検索に引っかからないのも腹がったって言えば立ちましたが。
感想
書いてて気づいたのは、構造化を考えて記事を書かんといかんということ。
何をコードで書くのか、どう表現するか。表現方法の構造化をしなくては読み手の読解コストが上がってしまいます。
システム設計とかタスク設計でもそうですし、もう全部にやらなければいかんということ。
これを考えながら、コンスタントに投稿できたら良いと思います。
参考文献、名前入れたらどっかのAPIから引っ張ってきてコピーしたらいい感じになるサービス無いんかな
間違い等ありましたら、なんかいい感じの機能があるとお聞きしたので、ご指摘お願いします。
質問もありましたらお聞きください。人間の生きる意味は寂しさの解消が割とあるというのが座右の銘的なサムシングでございます。(自分の学習にもつながると思うので是非)
お読みいただきましてありがとうございました。
参考文献
著者:山田祥寛,書籍名:独習Java,版:第一版,出版社:翔泳社,刷:第四刷(2021),発刊:2019年初版
著者:志賀 澄人,書籍名:徹底攻略Java SE 11 Silver問題集[1Z0-815]対応,版:第一版,編集社:インプレス,出版社:株式会社ソキウス・ジャパン,刷:第八刷,発刊:2019年初版
JavaSE11 公式API 2023/3~2023/4 参照
https://docs.oracle.com/javase/specs/
https://docs.oracle.com/javase/jp/11/docs/api/index.html