【追記(2020/06/08)】
本投稿に頂いたコメントを基に加筆しました。以下に挙げた項目に対して加筆し、加筆した部分は【追記】と記載しています。
- View Presenter / View Model
【追記(2020/05/31)】
同期の子から貰ったコメントを基に加筆しました。以下に挙げた項目に対して加筆し、加筆した部分は【追記】と記載しています。
- SOLID原則
- Form Request
新卒研修で「Laravelを使ってアプリケーションを自分で作ってみよう。」という趣旨のコーナーがあり、同期がやっていることを真似てClean Architectureを導入してみるも、無事、爆死することに成功しました。この投稿は、爆死するまでに得た知見についてまとめたものです。
この記事を読むことで得られる知見
投稿の要旨を載せておきます。
- MVCアーキテクチャに愚直に沿うと、Fat Controller / Fat Modelに行き着く
- Fat Controllerの何が悪なのか。
- Fat Controllerを解消するためにSOLID原則を適用しよう。
- メインロジックに関してはDependency Injectionを利用して責務を切り分けよう。
- Laravelが提供している「Facade」とDependency Injectionとは、どう違うのか。
- サブロジックに関してはEventを利用して責務を切り分けよう。
- Validationに関するロジックはForm Requestを利用して責務を切り分けよう。
- Viewに関するロジックはView ComposerとView Modelを利用して責務を切り分けよう。
- OR MapperとActive Record PatternとData Mapper Patternについて知ろう。
- データアクセスに関するロジックはRepository Patternを利用して責務を切り分けよう?
- ここまでの内容でClean Architectureの根幹は理解できてるんじゃね?
この投稿の最後にReferenceを載せているので、そちらも参考にして下さい。
Laracastsは良かった。
雑談ですが、Laravel初学者の自分にとって、Laracastsというサイトは非常に良かったです。
 【転載】https://laracasts.com
【転載】https://laracasts.com
月$15のサブスクリプションサービスですが、その価値はあると思います。非常にコンテンツが豊富です。Laravelだけでなく、PHPに関するコンテンツなども含まれています。
日本語字幕が無さげなのと、一部コンテンツが2015年などにアップロードされていて古いものが含まれているところがネック。ですが、それ以外は完璧でした。無料コンテンツもあるので、是非。
入会しようとすると、Laravel作者のTaylorさんから謎に煽られます。
 【転載】https://laracasts.com
【転載】https://laracasts.com
MVCとFat ControllerとFat Model
MVCアーキテクチャ
LaravelはMVCアーキテクチャを採用しています。

【転載】https://martinfowler.com/eaaCatalog/modelViewController.html
MVCアーキテクチャとは、アプリケーションを構築する際に、ModelとViewとControllerというレイヤに分けるデザインパターンです。
Modelはドメインに関する情報をもつオブジェクトであり、ViewはUIに関するテンプレート、そしてControllerはその間を取り持ちます。MVCアーキテクチャの最も重要な関心ごととして、「Patterns of Enterprise Application Architecture」では以下のように述べています。
Of these the separation of presentation from model is one of the most fundamental heuristics of good software design. This separation is important for several reasons.
【引用】https://www.amazon.co.jp/Enterprise-Application-Architecture-Addison-Wesley-Signature/dp/0321127420
ModelとViewの分離が最も重要だそうです。ModelとViewではそもそもの関心ごとが異なります。また、Viewはテストがしにくい場所です。そのためModelとViewは分離しておく方が得策だというわけです。
Fat Controller
Fat Controllerとは、色々詰め込みすぎて肥え太ってしまったControllerを指します。自分がLaravelを使って初めて作ったアプリケーションでは、以下のようなControllerになりました。(storeアクションメソッドのみを切り出しています。)
class ExampleController extends Controller
{
public function store(Request $request)
{
// Authを使ってcurrent_userを取得
// Requestの値によってRequestを整形
// Validatorを使ってvalidation
// 保存する際に関連テーブルの情報取得
// saveメソッドを使ってデータを保存
// Mailを送信
// redirect
}
}
上のコードは簡単にしたものだからコンパクトですが、実際の自分の書いたコードだと60行くらいに及んでいます。Requestを受け取り、Validationを行い、Requestを整形し、時にはDB操作を行い、、、、etc
このように初学者で陥りがちなのは、何でも屋っぽく見えるControllerにどんなロジックでもガリガリ書いてしまうことです。
保守性を考慮しなくて良いような小規模なサービスだったらFat Controllerでも良いでしょう。ロジックは全てControllerに突っ込んで終わりです。ただ、中・大規模なサービスになってくると、保守性も重要になってくるため、これは悪いコード例として捉えられてしまうと思います。(この理由については後に見ていきます。)
ただ、MVCアーキテクチャに愚直に沿うと、こんな感じになってしまうのは仕方がないと思います。中・大規模なサービスを立ったの3層に分けるのであれば、どこかの層がFatになるのは自明です。自分が作ったような小規模なサービスですら60行にも及ぶアクションメソッドが爆誕しています。
自分のような初学者の場合は、「ViewはUIに関するものであり、Modelはデータベースに関するもの」と大雑把に捉えていると思うので、その他の処理は全て、必然的にControllerに寄せられてしまうわけです。
ちなみになんですが、Modelという用語にも幅広い解釈が存在するようです。Modelには全てのビジネスロジックが入っているべきと捉える層もいるようで、そう捉えた場合、Fat ControllerではなくFat Modelが爆誕することでしょう。
Modelに対する解釈が多様であるため、LaravelにはModelディレクトリは存在しません。以前は存在したようですが削除されたようです。
Laravelを学習し始めるとき、多くの開発者はmodelsディレクトリが存在しないことに戸惑います。しかし、意図的にこのディレクトリを用意していません。多くの別々の人達にとって、その意味合いはさまざまなため、"models"という言葉の定義は曖昧であることに私達は気づきました。ある開発者たちはすべてのビジネスロジックを総称してアプリケーションの「モデル」と呼び、一方で別の人達はリレーショナルデータベースに関連するクラスを「モデル」として参照しています。
【引用】Laravel 7.x ディレクトリ構造
以下の記事では、Laravelの作者であるTaylorさんの、Fat ControllerとFat Modelに対する意見について言及されています。
なぜFat Controllerは悪なのか
UnderstandabilityとReusability、Changeabilityが損なわれることになるからです。(Testabilityも損なわれると思いますが、理由に自信がないので省略させていただきます。)
Understandability
Fat Controllerには様々な処理が詰め込まれているので、結局何の処理をしているのか理解しにくいです。
自分の先の例を見ても、storeメソッドだから、DBにsaveしているということは想像できます。しかし想像できるのはそこまでです。実際には、メールを送ったりもしていますし、Requestを整形したりもしていますが、それらについては実際の処理を追わないと把握できません。
実際に処理を追わないと何をしているか分からないプログラムは、間違えなく悪いプログラムと言えるでしょう。Becoming a better developer by using the SOLID design principles by Katerina Trajchevskaという動画では、プログラマはコードを書いている時間よりもコードを読んで理解している時間の方が多いという事実を導入部分で紹介しています。それ故に、Understandabilityはプログラマの生産性に直結する非常に重要な要素といえます。
Reusability
Controllerのアクションメソッド内に記述されたロジックを他所で再利用することは難しいでしょう。
再利用できないため、再度他所で同じロジックを組むしかなくなり、DRY原則に背いたController群が出来上がり、結果一箇所のロジックを変更する場合、変更箇所がほかでも多く出てくることにになります。
Changeability
プログラムを変更する時、既存のプログラムの正しさを確実に保ったままプログラムの該当箇所を変更できると、変更に強いプログラムとなり保守性も高まります。
Fat Controllerのように沢山の処理を担う関数の場合、一部を変更するとその大きな関数に含まれている全ての処理に変更が波及し、バグの温床となってしまいます。
SOLID原則
というわけで、プログラムの保守性を高めるために、Fat Controllerを解消しましょう。
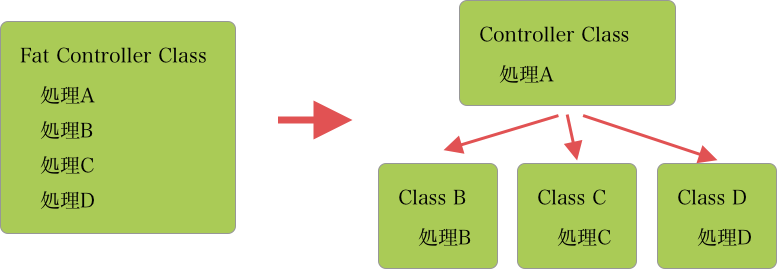
どうすれば良いかというと、Fat Controllerに書かれている処理を、別クラスに分けて責務を切り離します。この責務の切り分けの際に則るべき原則である「SOLID原則」についてここから見ていきます。
先にもリンクを貼りましたが、Laravel Conference EUの動画で、LaravelをSOLID原則の観点で解説した動画があるのでリンクを貼っておきます。(Laravel Conference EUの動画の中で一番視聴回数が多いです。)
SOLID原則は、ソフトウェア設計の原則であり、クラスをどのように設計すれば良いかについて言及した原則です。以下の5つの原則から構成されます。
S : Single-responsibility principle
O : Open–closed principle
L : Liskov substitution principle
I : Interface segregation principle
D : Dependency inversion principle
SとOを理解することが重要だと考えているので、その他の3つについては省略します。
Lは、インタフェースと抽象クラスを理解していれば自動的に満たされます。IはPHPなどの動的型付け言語にはあまり関係がありません(全く関係がないわけでもないですが。)。またDはOに内包されていると捉えることもできます。
Single Responsibility Principle
Single Responsibility Principle(以下、SRP)の概要については、wikipediaに簡潔にまとまっているので引用します。
1つのクラスは1つだけの責任を持たなければならない。すなわち、ソフトウェアの仕様の一部分を変更したときには、それにより影響を受ける仕様は、そのクラスの仕様でなければならない。
【引用】https://ja.wikipedia.org/wiki/SOLID
1つのクラスに1つの責任を持たせようという原則です。では、「1つの責任」とは何を表すのでしょうか。
Martin defines a responsibility as a reason to change, and concludes that a class or module should have one, and only one, reason to be changed
【引用】https://en.wikipedia.org/wiki/Single-responsibility_principle
つまり責任とは「変更可能性」です。将来的に生じる可能性がある変更を指しています。つまりSRPは、変更の可能性のある部分は別クラスに切り分けましょうということを説いた原則です。
なぜそうすることが重要かというと、変更を他の部分に波及させないようにすることができるからです。では、どうすれば「変更可能性」を見出し、うまくSRPを利用できるのでしょうか。
A module should be responsible to one, and only one, actor.
【引用】Clean Architecture
書籍「Clean Architecture」では、そのプログラムを利用しているアクターの数が1グループだとSRPを満たしていると説いています。原著では、CTOやCFOが例として挙げられ、プログラムに対するそれぞれのグループの変更依頼は、別のグループに影響を与えてはならないとしています。
自分はここまでの説明が抽象的すぎてあまり上手く噛み砕けせんでした。書籍「clean code」で、SRPに沿った設計になっているかを判別する、より具体的な方法が2つ紹介されていたので、そちらを併せて紹介します。
まず1つにクラス名が具体的な責務を表現しているかに注目することでSRPに沿ったクラス設計となっているかを判断できます。例えば抽象的な名前(ProcessorやManagerなど)がクラス名に含まれていれば、それはSRPを違反している可能性が高いです。また、もしそのクラスの概要を説明する際に、ifやand、or、butなどを含んだ説明になってしまう場合、SRPを違反している可能性が高いそうです。
2つ目に、凝集度(cohesion)を考慮することでSRPを違反しているかどうかが判別できます。例えば、privateでメソッドやプロパティを定義しているものの、それらがクラス内の極一部の関数でしか使われていない場合は、SRPを違反している可能性が高いそうです。この場合は、それらを別クラスに抽出することができるはずです。
ここまででSRPの説明を終わりますが、最後に1つ加えます。
SRPに忠実に則ると、クラスで氾濫して分かりにくくなるやんって思ってしまいませんか?自分はそう思ってました。この懸念に対して、書籍「clean code」でAnswerぽいことが述べられていたので、引用します。
However, a system with many small classes has no more moving parts than a system with a few large classes. There is just as much to learn in the system with a few large classes. So the question is: Do you want your tools organized into toolboxes with many small drawers each containing well-defined and well-labeled components? Or do you want a few drawers that you just toss everything into?
【引用】clean code
大きなクラスの中でごちゃつかせとくよりも、小さなクラスに処理を切り分けて「整理整頓」してた方が良いんじゃないのって言ってます。確かに、そう言われてみれば、そんな気もする。ただ、SRPに則って小さなクラスに分けすぎるのも問題かなとも思うので、適度に則るようにしたいものです。
Open Closed Principle
wikipediaから定義を引用します。
「ソフトウェアのエンティティは(中略)拡張に対して開かれていなければならないが、変更に対しては閉じていなければならない。」
【引用】https://ja.wikipedia.org/wiki/SOLID
分かるようで分からない文章ですね。
機能を拡張する際に、既存のプログラムに変更を加えずに、新しいプログラムを加えることでプログラムの変更が可能になるように設計することを、この原則は説いています。そうすることで既存のプログラムに対して変更を波及させず、既存のプログラムの正しさを保ったまま、プログラムを変更することができます。
では、それをどうやって実現することができるのでしょうか。
先に紹介した原則であるSRPによって、変更可能性のある部分は別クラスに切り分けられているわけです。そこで、大元のコードが変更可能性のあるクラスに依存してしまうと、変更可能性のあるクラスに変更が発生した際に変更が大元に波及してしまいます。
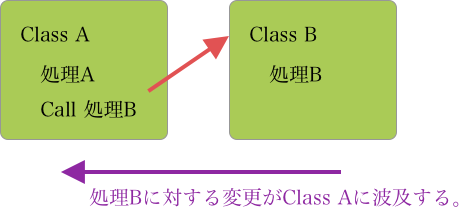
そこで、切り出した別クラスが大元のクラスに依存するように依存関係を逆転させます。つまり、このような振る舞いをするクラスが欲しいですというInterfaceを設けておき、それを周りに実装させるようにするのです。

Class AはClassBの処理を呼び出しているわけですから、普通に考えて、Class AがClass Bに依存しているはずです。ですが、この図を見ても分かりますが、Class A側で、欲しい処理であるInterfaceを設けておき、それに合わせてClass Bを開発することで、Class AはClass Bに依存しなくなっています。
この手法は、SOLID原則のDであるDependency inversion principleにて定義されています。Dependency inversion principleの定義をwikipediaから引用します。
「具体ではなく、抽象に依存しなければならない」
【引用】https://ja.wikipedia.org/wiki/SOLID
Interfaceは、具象クラスについての契約を定めているものなので、具象クラスよりも安定しているポジションにいます。Interfaceという契約だけ定めておいて、それに合わせるように具象クラスを開発するわけです。Interfaceに影響しないように具象クラスを実装するわけです。このようにプログラムを組むことで、クラスBに対する変更は、Interfaceに沿うように変更する限り、既存のプログラムであるクラスAに変更が波及しないようになります。
またInterfaceに依存するように実装することで、具象クラスを取り替えることができるようになります。その契約を実装したクラスなら何でも取り替えられるわけです。これにより既存のプログラムであるクラスAに変更を波及させずに機能を拡張することができます。よくOpen Closed Principle原則の例としてFactory Patternが紹介されていますが、この振る舞いは、Factory Patternに通ずるところがあります。
ただし注意が必要なのですが、何でもかんでもInterfaceに依存せよと言っているわけではありません。もしも具象クラスの実装に変更が入る可能性が高いなら、より安定しているInterfaceに依存するようにしようということです。ライブラリに入っているような、絶対に変更しないであろう具象クラスのInterfaceを実装しなければいけないわけではありません。
依存関係の逆転に話を戻します。正しい依存関係の在り方は、「より重要であるクラスに依存する」ことです。
Clean Architectureの文脈に沿うのであれば、最も重要なのはDomain Modelであり、それに依存するように周りのクラス設計をします。
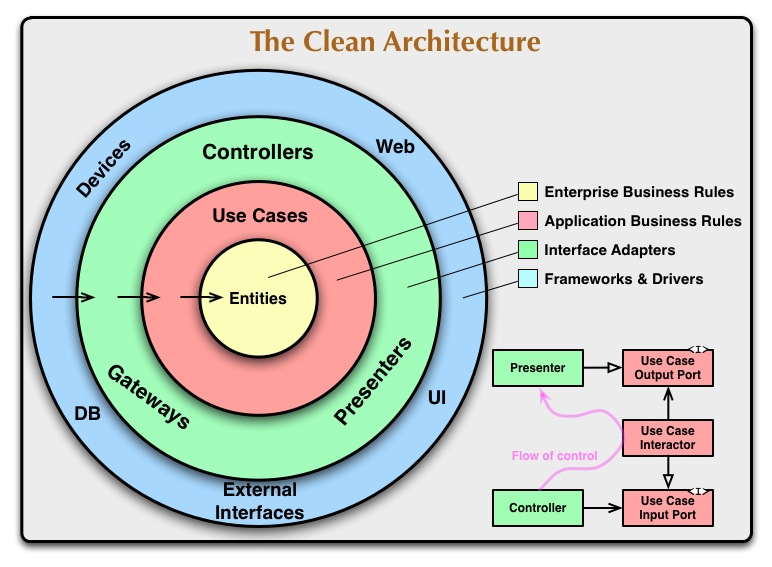
もしもRDBを中心に設計された簡単なCRUD機能のみのアプリケーションなのであれば、Active Recordを用いてRDBのテーブル構造をin-memoryに移し、そのModelクラスを中心に据え、それに依存するようにクラス設計をします。
要するに、「何が最も重要か」を考えた上で、それを中心に据え置き、それに依存するようにアプリケーションを開発していくことが重要なのです。
付け加えておきますが、「重要なクラスや層」が「重要でないクラスや層」に依存しないように、依存関係を逆転させます。もしも、もともと「重要なクラスや層」が参照される側であり、「重要でないクラスや層」に依存していないのであれば、依存関係を逆転させる必要はありません。
【追記】
SOLID原則で重要なのは、SとOであり、DはOに内包されていると先に述べています。それ故にDに対してあまり着目した記述はしていませんでした。が、Dは重要な役割を果たしており、Dのおかげで、内側、つまりClean Architectureの文脈でいう「Entity」に依存させたアプリケーション設計が可能になります。
また、「重要なものを中心に据え置く」という表現をしていますが、より詳細に記述すると、「安定していて、抽象度が高いものを中心に据え置く」です。詳しくは原著をお読み下さい。
【追記終わり】
Dependency Injection / Facade
SOLID原則に基づいて、変更可能性のある処理を別クラスに切り分けます。その際に切り出したクラスと切り出されたクラスでクラス間の依存関係が発生することは先に述べました。
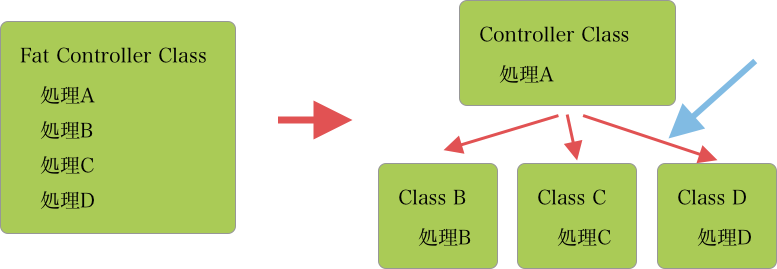
上の図では、Class Aから、例えばClass Dの処理を呼び出しています。Class Aでは、どのようにしてClass Dの処理を呼び出せば良いのでしょうか。そのクラス間の依存関係を記述する手法の1つとしてDependency Injectionというデザインパターンが存在します。
Dependency Injection
では実際にClass AからClass Bのメソッドを呼び出すプログラムを見ていきます。このプログラムを実現する方法として、コンストラクタ内でインスタンスを作成し委譲する手法が、まず頭に浮かびます。
class ClassA
{
protected $instanceB;
public function __construct()
{
$this->instanceB = new ClassB();
}
public function someFunction()
{
$result = $this->instanceB->classBFunction();
// ...
}
}
こうすると、クラスAとクラスBが密結合(tightly coupled)になってしまいます。密結合になると何がまずいのかというと、Unit Testの実施が難しくなることです。
Unit Testをする際には、クラスAのインスタンスを作成するわけですが、上のプログラムだと、自動的にクラスBのインスタンスの作成も強制されてしまいます。するとクラスBについて実装を完了していて、かつ動作が正常でないとクラスAのUnit Testができなくなります。
というわけで、上のプログラムを書き直して以下のようにコーディングしましょう。
class ClassA
{
protected $instanceB;
public function __construct(ClassB $instanceB)
{
$this->instanceB = $instanceB;
}
public function someFunction()
{
$result = $this->instanceB->classBFunction();
// ...
}
}
これが、Dependency Injectionです。(以下、Dependency InjectionをDIと略します。また、Dependency Injectionにはメソッドインジェクションやプロパティインジェクションなど複数のパターンが存在するようですが、本投稿ではコンストラクタインジェクションを扱っています。)
クラスの依存(depenendency)を外から注入(inject)するようにコーディングすれば、Unit TestにおいてクラスA作成時にクラスBのMockを注入することができるようになります。この、FlexibilityとTestabilityを得られるのがDIの旨みであり、LaravelのDocumentでも、そのように述べられています。
依存注入の最大の利便性は、注入するクラスの実装を入れ替えられるという機能です。モックやスタブを注入し、そうした代替オブジェクトのさまざまなメソッドのアサートが行えるため、テスト中に便利です。
【引用】Laravel 7.x ファサード
さて、これだけでも十分なのですが、もしも具象クラスBが変更される可能性が高かったり、具象クラスAnotherClassBを流し込みたい場合もあるのであれば、先に紹介したSOLIDのDの原則を適用させて、Interfaceに依存するようにさせましょう。
class ClassA
{
protected $instanceB;
public function __construct(InterfaceB $instanceB)
{
$this->instanceB = $instanceB;
}
public function someFunction()
{
$result = $this->instanceB->classBFunction();
// ...
}
}
ちなみに、LaravelのDocumentでは、Interfaceの旨味を「疎結合さ」と「単純さ」であると述べています。(Laravel 7.x 契約)
前者の「疎結合さ」については先のSOLID原則の項目で述べたのですが、「単純さ」という面もあります。どういうことかというと、Interfaceには実装が含まれていないので、そのクラスにどのような関数が定義されているかということを簡単に知ることができるdocumentがわりにもなりますよね、ってことです。
DIに話を戻します。先のコード例でいうと、クラスAのインスタンスを作成している側のコードは以下のようになります。
$instanceA = new ClassA(new ClassB());
このように、DIする際に、クラスのインスタンスを作成している側では毎回そのクラスが依存しているインスタンス(この例だとクラスBのインスタンス)を作成しないといけないのでしょうか。クラスAが依存しているクラスBは、もしかしたらクラスPに依存しているかもしれません。その場合は以下のようにコーディングする必要が出てきます。
$instanceA = new ClassA(new ClassB(new ClassP()));
非常に手間なのもありますが、そのクラスが依存しているインスタンスについて毎回作成していると、保守性が損なわれてしまいます。例えばクラスBのコンストラクタに新しい依存が追加され、クラスBのインスタンス作成方法が変わった場合には、クラスBのインスタンスを作成していた全ての箇所で変更が発生してしまいます。
そこでDI Containerの出番になります。LaravelではService ContainerがDI Containerの役割を担っており、そのService ContainerをTaylorさんはLaravelの基盤だと述べています。
The foundation of the Laravel framework is its powerful IoC container. To truly understand the framework, a strong grasp of the container is necessary. However, we should note that an IoC container is simply a convenience mechanism for achieving a software design pattern: dependency injection. A container is not necessary to perform dependency injection, it simply makes the task easier.
【引用】From Apprentice to Artisan
Service container(旧名はIoC Container)は、DIを容易にするものではあるが、必須のものではありません。簡単に言うと、DIの際に注入するインスタンスを管理する場所がDI Container(Service Container)です。
Service Containerについては、まだ深く理解できていないので、詳細については省略しますが、LaravelでDIを実現するためにService Containerを使う場合、知っておきたいポイントを1つだけ述べておきます。
基本的に具象クラスが注入(inject)されている場合は、LaravelがPHPのReflectionクラスを利用して自動でインスタンスを作成してくれます。つまりService Containerに何も指定する必要はありません。
Tip!! インターフェイスに依存していないのであれば、コンテナでクラスを結合する必要はありません。コンテナにオブジェクトを結合する方法を指示する必要はなく、リフレクションを使用してそのオブジェクトを自動的に依存解決します。
【引用】Laravel 7.x サービスコンテナ
一方で、Interfaceに基づいたインスタンスを注入(inject)している場合、もしくはインスタンス作成の際に引数(具象クラス以外の何か)を必要とする場合、Reflectionで自動解決することは難しいため、Service Containerでbindというメソッドを使って具体的にどのようなインスタンスを注入したいかを指定する必要があります。
Facade
Laravelではクラス間の依存を管理する際にDIとは別に「Facade」という機能が提供されています。
ファサード(facade、「入り口」)はアプリケーションのサービスコンテナに登録したクラスへ、「静的」なインターフェイスを提供します。Laravelのほとんどの機能に対して、ファサードが用意されています。Laravelの「ファサード」は、サービスコンテナ下で動作しているクラスに対し、"static proxy"として動作しています。これにより伝統的な静的メソッドよりもテストの行いやすさと柔軟性を保ちながらも、簡潔で記述的であるという利点があります。
【引用】Laravel 7.x ファサード
DIでは、コンストラクタ、もしくはメソッドの引数にクラスをタイプヒントしてインスタンスを渡すことで依存関係を解決しています。しかしそうではなく、静的に依存関係を記述したい時に利用できるのがFacadeです。
例えば、Laravelで提供されているDBクラスを利用したい場合、DIを使うなら以下のようなコーディングになります。
class HomeController extends BaseController {
private $users;
public function __construct(Illuminate\Database\Connection $db)
{
$users = $db->table('users')->get();
}
}
一方で、Facadeを使うと以下のようにコーディングできるというわけです。
class HomeController extends BaseController {
private $users;
public function __construct()
{
$users = DB::table('users')->get();
}
}
Facadeを使った例では、tableという静的メソッドを利用しているように見えます。しかしFacadeの実態は静的メソッドではありません。内部的にはサービスのインスタンス化が行われています。
上の例でいうと、内部的にはDIと同じく、DBオブジェクトがインスタンス化されて、そのインスタンスメソッドであるtableが呼ばれているだけです。従って静的メソッドと違ってUnit Testも簡単に行えます。
ではDIとは、どう異なるのでしょうか。それはFacadeの方がコードがスッキリするという点です。コンストラクタとかメソッドの引数にクラスやインタフェースをタイプヒントしてインスタンスをDIしなくても済みます。
じゃあコードがスッキリするから、DIじゃなくてFacadeを使えば良いのか、というとそうでもないようです。Laravelの作者であるTaylorさんがFacadeは使わない方がいいよー的なことを言っているので、引用します。
However, if you are using Facades to push to the queue, send an e-mail, and validate some data all within a single class, that class’ core responsibilities are obscured. It is concerned about way too many things
【引用】Response: Don’t Use Facades
Facadeを使うと、依存関係が見えにくくなり、SRPを容易に違反してしまいます。Facadeを使うことで、内部の責務が知らぬ間に増えてしまうということです。一方で、コンストラクタインジェクションを使うと、どのクラスに依存しているかが明確に分かります。
Facadeを使わずにコンストラクタにinjectしまくると、コンストラクタが肥大化する恐れがあると考えるかもしれませんが、それは純粋にそのクラスが他のクラスに依存し過ぎていることに他ならないです。なのでその場合はFacadeを使って依存関係を隠蔽するのではなく、依存関係を改めて整理しましょう。
Facadeで用いられているクラスをDIで利用する場合はクラス名をタイプヒントしなければいけません。その際には以下のリンクを参考にしましょう。
Event Driven
では他のクラスに対して依存したい場合、全てDependency Injectionを利用すれば良いのかというとそうでもないと思っています。例えばstoreメソッドの中で、登録に際してlogを取るためのクラスに依存していたり、メールを送信するためのクラスに依存していたりしているとしましょう。
これらを全てコンストラクタでDIしていくと、コンストラクタが肥え太っていきます。何より、それらの処理はメインロジックではないので、それらによってメインの処理のフローを見にくくさせたくありません。
そういう場合にはEventとして切り出すという手法が考えられます。storeメソッド内でEventを発火させ、そのEventのリスナとしてlogの処理とメール送信の処理を登録しておきます。そうすることでメインロジックの流れを見やすく保つことができます。また新しく何かしら副次的なロジックを加えたくなった場合にも、イベントリスナクラスを追加するだけで処理を加えることができます。
一方で、このEvent Drivenなアプローチには、裏側で何が起こっているのかがメインフローから見えにくくなるというデメリットが存在します。基本的には、イベントとリスナの対応関係はサービスプロバイダに定義します。なので、イベントが発火しているメソッド内では何のリスナが紐づいているのか分からないです。もしもリスナを調べたい場合は、サービスプロバイダをたどるか、php artisan event:listコマンドを使う必要があります。
Laracastsでは、この問題に対する対策として、サービスプロバイダでリスナを登録するのではなく、Eventを発火しているクラスのコンストラクタでリスナを登録する方法が紹介されていました。あくまで紹介であり、この方法を勧めている訳ではなかったので参考まで。(例えばUsersControllerで、Userがregisterした時に発火するイベントがあるのであれば、UsersControllerのconstructorでリスナを登録する処理を書く。)
Separation of Concerns
ここまでをまとめると、SOLID原則に基づきクラス設計をし、そしてそのクラス間の依存関係の管理についてはDIを主に利用しましょう、という話でした。では実際に、SOLID原則に基づき、関心を分離していきましょう。ここからは、以下の3つのクラスについて紹介します。
- Form Request
- View Composer / View Presenter / ViewModel
- Repository?
これらは、あらゆる場面で導入すると良いというものでもなく、場合によっては導入しない方が良いこともあります。「そういうパターンもあるんだ」という感じで受け取ってもらえると嬉しいです。
Form Request
ユーザからのリクエストに対するValidationの責務を持つクラスです。ControllerにValidationの責務を持たせると、コードが煩雑になります。なのでValidationの責務を別クラスに切り分けましょう。
ただし、Controllerの中でValidationを定義した方が、処理の流れの中でどのようなValidationをしているか分かるからこっちの方が良いやん、っていう方もいると思います。一方で、SRP原則に従うと、Controllerは、「requestを受け取り、responseを返す」ことのみを行うLayerであり、ValidationはControllerの責務ではないと捉えられます。
個人的に、ユーザからのリクエストのパラメータが多い場合、Validationが膨らんでしまい実際のロジックに入るまでに場所を取ってしまうので、やはり別にValidationロジックを実行するためのクラスを作成した方が良いのでは、と考えています。
Form Requestを利用すると、以下のようなコードになります。
public function store(ValidatedRequest $request)
{
}
ここでいうValidatedRequestがForm Requestです。こうすることで、ValidatedRequestというクラスに記述されているValidationをPassしたリクエストがアクションメソッドに入ってきます。
Form RequestにValidation以外のロジックを持たせることもできるようですが、ロジックが散らかってしまうので良くないと思います。Form Requestについて詳しくはドキュメントを参照して下さい。(Laravel 7.x バリデーション)
【追記】
Clean Architectureの文脈では、「可能な限りフレームワークに依存しない」ということも重要とされています。それが明言されている箇所をブログから引用します。
Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
【引用】https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
そして、この項で紹介したForm Requestという機能は、Laravelによって提供されている機能です。何が言いたいかというと、Form Requestを使うことで、一部ではありますがLaravelに依存したアプリケーションとなってしまい、Clean Architectureの文脈には沿わなくなるということです。
では、Clean Architectureの文脈ではValidationはどこに置かれるかというと、Entityです。何故ならValidationというのは、例えば文字数制限などですが、これはビジネスロジックに該当するからです。
とはいえ、Laravelという重量なフレームワークを選択している時点で、Laravelによって提供されているForm Requestといった機能を利用しないのはナンセンスだと思います。それらを利用しないようにするのであれば、もっと軽量なフレームワークで良いのでは、と思います。
【追記終わり】
View Composer / View Presenter / View Model
Viewに関するロジックは果たしてどこに定義すればいいのでしょうか。ここではView ComposerとView Model/View Presenterについて述べていきます。
View Presenter / View Model
例えば、DBにfirst_nameカラムとlast_nameカラムが存在し、それらを組み合わせてユーザーのfull nameを表示するケースがあるとします。その場合のロジックは以下のようになるでしょう。
$user->first_name.' '.$user->last_name
このロジックはどこに置けば良いでしょうか。Viewに直接書きましょうか。
1つのページの1箇所だけで使うロジックであり、特に複雑でもなく重要でもないロジックなのであれば、Viewに直接書き込むのも個人的に手だと思います。しかし、さっきのfullNameのロジックの場合、恐らくユーザ情報を表示する複数ページで利用することになるのではないでしょうか。
そうなると、Viewに直接ロジックを書き込んでしまうと、再利用性や変更容易性に問題が生じてきます。またViewはhtmlの中にロジックが埋め込まれることになるのでテストもしにくいです。ということで、Viewに直接書き込むのもアウトでしょう。
では、以下のようにして関数に括り、Modelに持たせますか?
public function fullName(){
return $this->first_name.' '.$this->last_name
}
が、これも良くないと思います。~~View用に使うロジックをModelに書いていくと、たちまちFat Modelに行き着きそうです。~~それに、さっきのfullNameのロジックは一部のViewで整形するためだけのロジックでしょう。なので、Modelに書くのはアウトです。
【追記】
「View用に使うロジックをModelに書いていくと、たちまちFat Modelに行き着きそうです。」と言う文言に関して、「全ての場合でそうとも言い切れず、場合によってはModelクラスにロジックを書くのも良いのでは。」というご指摘をいただいたため、文言を打ち消しております。詳しくはコメント欄を参考にして下さい。
となると必然的にMVCの最後の1つ、Controllerに書き込むことになるでしょう。MVCに沿うとそうなるのが妥当だと思います。ただし再利用性と変更用意性、テスタビリティあたりは気にしたいところです。今回の例のロジックだとユーザ情報を表示する複数のページ、つまりController内の複数のアクションメソッド内で使われると思うので、アクションメソッド内に直に書き込まず、別に関数として定義してアクションメソッドから呼び出したいところです。
というわけで、まとめます。
SOLID原則に従い、Viewに関するロジックを別クラスにまとめ、それをControllerのアクションメソッドから利用するという形にしましょう。この切り出し方としては複数考えられます。以下にそれぞれの手法について解説している記事を紹介しますので、詳細についてはそれらを参照してください。
以下の記事では、ViewのためのDecoratorクラスを作成し、そこにViewで使うためのロジックを定義しています。そしてEloquentによって返されるModel Objectを、ControllerにてDecoratorクラスで包みこみ、その包み込んだオブジェクトをViewに渡すという形を取っています。
Laracastsの以下の動画でも手法が紹介されています。
- https://laracasts.com/series/whip-monstrous-code-into-shape/episodes/11
- https://laracasts.com/lessons/view-presenters-from-scratch
こちらもViewのためのロジックを別のクラスに定義するという点では同じなのですが、呼び出し方が少し異なっていて、Model Objectを包み込むためのロジックを、関数としてModelクラス内に定義している点が異なります。
public function present()
{
return new UserPresenter($this);
}
こうすることで、Viewではロジックを使いたい場合、以下のように書くことになります。
{{ $user->presenter()->getCapitalTitle() }}
この手法は以下のqiitaの記事でも紹介されています。
また以下の記事も参考になると思います。
View Composer
では例えば、全てのページで共通しているヘッダーやサイドバー・フッターなどに、Userの情報を表示したい場合を考えてみましょう。この場合、ページに表示しているメインのモデルとは無関係なので、先に紹介したViewModelなどを使うのはよろしくないでしょう。
ということで、こういう場合に、Laravelで提供されているView Composerの出番だと思っています。View Composerというのは、Viewをレンダリングする際に自動的に行われる処理を指します。
しかしView Composerを使うと、ControllerにView Composerを使った痕跡が一切残らないので、ロジックの流れが掴みにくくなります。例えばviewに{{ $message }}という謎の変数があったとき、まずView Composerを見にいくのではなくControllerを見にいくと思います。しかし実際は、View Composerがメインフローとは別の場所で処理を実行しているという訳です。
こういった理由でView Composerを多用しない方が良いのは自明ですが、先の例のような全てのページに表示するなどの場合、全てのアクションメソッドでVIewModelを使ってユーザ情報を含ませる処理を書くよりも、チームの共通認識としてヘッダーのユーザ情報はView Composerを使っているという風に設計した方が良いと思います。
Repository Pattern
Repository Patternについて考えるためには、OR Mapper、そしてOR Mapperを実装する際のデザインパターンの代表例であるActive Record PatternとData Mapper Patterntについて理解する必要があるので、先にそちらを見ていきます。
ちなみにLaravelのEloquentは、Active Record Patternで実装されたOR Mapperです。
OR Mapper
OR Mapperは、Object-Relational Mapperの略で、オブジェクトとRDBをMappingしてくれます。
ORMによってデータアクセスのためのロジックをラップしたメソッドが提供されるので、多くの場合SQLを書く必要は無くなります。OR Mapperは、色々議論が勃発している分野であり、OR Mapperについて深く知るためには、それらの批判を認識しておくべきだと思うので紹介します。
Martinさんによると、OR Mapperは以下のように批判されるようです。
Essentially the ORM can handle about 80-90% of the mapping problems, but that last chunk always needs careful work by somebody who really understands how a relational database works.
【引用】https://martinfowler.com/bliki/OrmHate.html
またMartinさんは、以下のようにも述べています。
The charges against them can be summarized in that they are complex, and provide only a leaky abstraction over a relational data store. Their complexity implies a grueling learning curve and often systems using an ORM perform badly - often due to naive interactions with the underlying database.
【引用】https://martinfowler.com/bliki/OrmHate.html
まとめると、OR MapperはアプリケーションからRDBを隠蔽することが期待されているにも関わらず、RDBを隠蔽することに失敗しているという点がよく批判されていると述べています。
例えば、OR Mapperを使っても、複雑なSQLになってくると実際にSQLを書かないといけなくなってきます。それにOR Mapperを通すと、内部でどういうSQLが実行されているのかも分からないので、パフォーマンスの低下を招く場合もあります。結局のところ、SQLも理解した上でOR Mapperも理解しないといけないことになり、手間を増やしている点が批判されています。
というわけで、OR Mapper使わんでいいやん、と。SQL使って直接RDBから引っ張ってこようぜっていう意見が出てきます。ただしMartinさんはこの意見に対して反論を述べています。
David Heinemeier Hansson, of Active Record fame, has always argued that if you are writing an application backed by a relational database you should damn well know how a relational database works. Active Record is designed with that in mind, it takes care of boring stuff, but provides manholes so you can get down with the SQL when you have to. That's a far better approach to thinking about the role an ORM should play.
【引用】https://martinfowler.com/bliki/OrmHate.html
OR Mapperは元々、RDBを完全に隠蔽するものではなく、RDBに関する理解を前提に利用されるものだそうです。
OR Mapperの実装には大きく、Active Record PatternとData Mapper Patternの2つのデザインパターンが利用されます。そのうちの一つであるActive Record Patternを利用して実装されていて、Railsで利用されているOR Mapperである「Active Record」は、SQLを知っていることを前提に作られていると述べています。
また、もしもOR Mapperなしで全てSQLを書くと、結局重複されたSQLが出てきてそれらをまとめるためにOR Mapperを作る結末になるのではないでしょうか。もちろん軽量になるのかもしれませんが、そのために壮大な車輪の再開発をする必要はないでしょう。
SQLは分解・構築・抽象化が弱いという意見もありました。というか、OR Mapperってどうやって作っているんだろう。(https://www.slideshare.net/kwatch/sqlor)
まぁなんやらかんやらメリット・デメリットあると思います。結論的には、RDBとOOPを使うなら、OR Mapperのデメリットは目を瞑るしかないよねってなります。そこに文句を言うんだったら、RDBを捨てるかOOPを捨てるかしなはれ、ってことです。ちなみにこのような状態をImpedence Mismatchと表現するようです。
以下の記事は、OR Mapperに関する議論中で両記事としてよく引用されているので、ぜひ参考にしてください。
OR Mapperをベトナム戦争に例えて説明しています。ただし、導入部分のベトナム戦争のくだりが長すぎて心が折れちゃう方が多いと思います。(自分が心折れました。)
上の記事の、まとめ部分だけ抽出したのが以下の記事です。
Active Record Pattern

【転載】https://www.martinfowler.com/eaaCatalog/activeRecord.html
LaravelのEloquentは、Active Record Patternで実装されたOR Mapperです。Active Record Patternの定義を引用します。
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.
【引用】https://www.martinfowler.com/eaaCatalog/activeRecord.html
テーブルとモデルクラスを1対1対応させて、RDBとオブジェクトをMappingします。テーブルをモデルクラスに、テーブルのcolumnをモデルクラスのfieldに対応させています。またテーブルの行がクラスのインスタンスに該当します。
そしてそのモデルクラスにinsertやsaveなどのデータアクセスのためのメソッドを継承して持たせるというデザインパターンがActive Record Patternです。実際、Eloquentではデータアクセスロジックを持ったModelクラスを継承する形を取っています。
namespace App;
use Illuminate\Database\Eloquent\Model;
class SomeModel extends Model
{
}
Active Record Patternの特徴はRDBとDomain Objectの密結合です。(Domain Objectとは、Domainに関するデータと振る舞いを持ったObjectを指します。Eloquentでいうところのモデルクラスと考えて良いでしょう。)
Active Record Patternを利用すると、RDBのテーブル構造によってアプリケーション内でのモデルクラスのデータ構造が決定されます。RDBに存在するデータ構造をin-memoryに持ってきているだけなので、一方の変更は、もう一方に当然波及します。
また多くの場合、Active Record Patternを通して取得したModel ObjectをControllerやViewに渡します。そしてそのModel Objectは、ビジネスロジック、RDBのテーブル構造、データアクセスロジックを持っています。つまり、ViewやControllerに渡されるModel Objectを通して、どこからでもRDBにアクセスができてしまいますし、RDBのテーブル構造が全てに影響を与えてしまう訳です。
この「RDBとDomain Objectの密結合」という特徴は、諸刃の剣です。
RDBを中心に据え置いた、CRUD Basedなアプリケーションを実装する場合は、このRDBとDomain Obejct(モデルクラス)の密結合は、高速に、そして容易にアプリケーション開発することを可能にするメリットとして捉えられるでしょう。小規模なアプリケーション開発でも、Active Recordは向いていると思います。
一方で、中-大規模なアプリケーションになる場合、関心の分離に基づき層を分けることによる保守性を考慮する必要が出てきます。ControllerやViewからデータアクセスできるのは困る訳です。
また、RDBのテーブルとDomain ObjectがOR Mapperを通して1対1対応してしまっているため、アプリケーションが大きくなり複雑なDomain Objectを扱うようになるなど、1対1対応ではなくなってしまった場合に、困ることになります。
個人的に思うのは、RDBのテーブルのcolumn名を変えれば、Model Objectのproperty名も変わり、その結果、ViewやControllerの至る所で変更が発生してしまうのは、小規模であれ何であれ大問題なのではと思ってしまいます。
またUncle Bobさんは、ブログの以下の投稿で、Active Record Patternによって生成されるモデルクラスはObjectではないということを認識するべきだと指摘しています。
Active Record Patternによって生成されるModel Objectは一見オブジェクト指向に沿っていて、情報を隠蔽しているように見えますが、実際はデータアクセスのためのロジックを持っただけのDTOです。クラスが抽象データ型になっていません。何の情報も隠蔽していませんし、プロパティを抽象化したメソッドというインタフェースも提供していないのです。
The problem is that Active Records are data structures. Putting business rule methods in them doesn’t turn them into true objects. In the end, the algorithms that employ Active Records are vulnerable to changes in schema, and changes in type. They are not immune to changes in type, the way algorithms that use objects are.
【引用】Active Record vs Objects
DTOとは、Data Transfer Objectの略です。DTOとは、詰まる所、データ構造です。(関数を持たず、publicなvariableのみを持つ。)そしてデータ構造とは、オブジェクトと対をなす概念であるとUncle Bobさんは述べています。
Active Recordはデータ構造としてのみ扱い、それとは別に、ビジネスロジックと、情報隠蔽されたプロパティを持つオブジェクトを用意するべきなのかもしれません。(詳しくはActive Record vs Objects参照してください。)
Laravelでデフォルトで利用されているEloquent(Active Record Patternで実装されたOR Mapper)を利用しつつ、関心の分離にしたがってRDBとアプリケーションとを分離させるためには、新しくデータ構造をApplicationとModelクラスの間に挟む必要があると思います。つまりEloquentを通して取得され、データアクセスメソッドを継承してしまっているModel Objectを、別のデータ構造、例えばEntityクラスを定義してそちらに移す必要性が出てきます。
そうすることで、RDBのテーブル構造や、データアクセスのためのメソッドを別の階層に流出させずに済みます。このデータ構造の移し替えは、恐らくのちに紹介するRepository層の中で実装することになるでしょう。
ただし、RDBとアプリケーションの分離をしようと思うのであれば、Active Record Patternを利用したEloquentではなく、Data Mapper Patternを利用したDoctrine 2などを利用した方が良いでしょう。
Data Mapper Pattern

【転載】https://martinfowler.com/eaaCatalog/dataMapper.html
Data Mapper Patternの定義は以下です。
A layer of Mappers (473) that moves data between objects and a database while keeping them independent of each other and the mapper itself.
【引用】https://martinfowler.com/eaaCatalog/dataMapper.html
Symphonyで利用されているDoctrine 2は、Data Mapper Patternで実装されたOR Mapperです。ドキュメントには以下のような記述があります。
Doctrine を使用することで、データベースへのデータの保存を二の次にして、オブジェクトと、それらがアプリケーション内でどの様に使われるかに集中できます。 その訳は、Doctrine が、データを保持するのに、どんな PHP オブジェクトを使うことも可能にしていることや、マッピングメタデータ情報に基いて、オブジェクトのデータを特定のデータベーステーブルにマップしているからです。
【引用】http://symdoc.kwalk.jp/doc/book/doctrine
Data Mapper Patternを利用したOR Mapperの最大の特徴は、Domain ObjectとPersistence層の分離です。
Domain ObjectとRDBとの間にMapperというLayerを挟んでいるので、一方に対する変更がもう一方に波及しなくなります。テーブルとDomain Objectを一対一に紐付ける必要性もありません。また分離されているが故に、Domain Modelの設計の際にDatabaseを気にせずに設計できます。
Active Record Patternと異なり、Data Mapper Patternでは、Domain Objectとデータアクセスのためのロジックを切り分けています。そうすることで、Domain Objectはフレームワークから独立して純粋なPHPで記述することができるようになります。
では、Active Record PatternとData Mapper Patternをどのように使い分ければいいのか。「Patterns of Enterprise Application Architecture」では以下のように述べられています。
Active Record is a good choice for domain logic that isn’t too complex, such as creates, reads, updates, and deletes. Derivations and validations based on a single record work well in this structure.
【引用】Patterns of Enterprise Application Architecture
もしもdomain logicが複雑なのであれば、Data Mapper Patternを取り入れ、RDBとDomain Objectを分離させることに利があるでしょう。一方で、domain logicが複雑ではなく、RDBと分離されたDomain Objectが必要ない場合、Active Record Patternを選ぶべきだと述べられています。
Repository Pattern
ということで、満を持してRepository Patternを見ていきます。「Patterns of Enterprise Application Architecture」で紹介されているRepository Patternの図は個人的に分かりにくかったので、別の図を載せておきます。
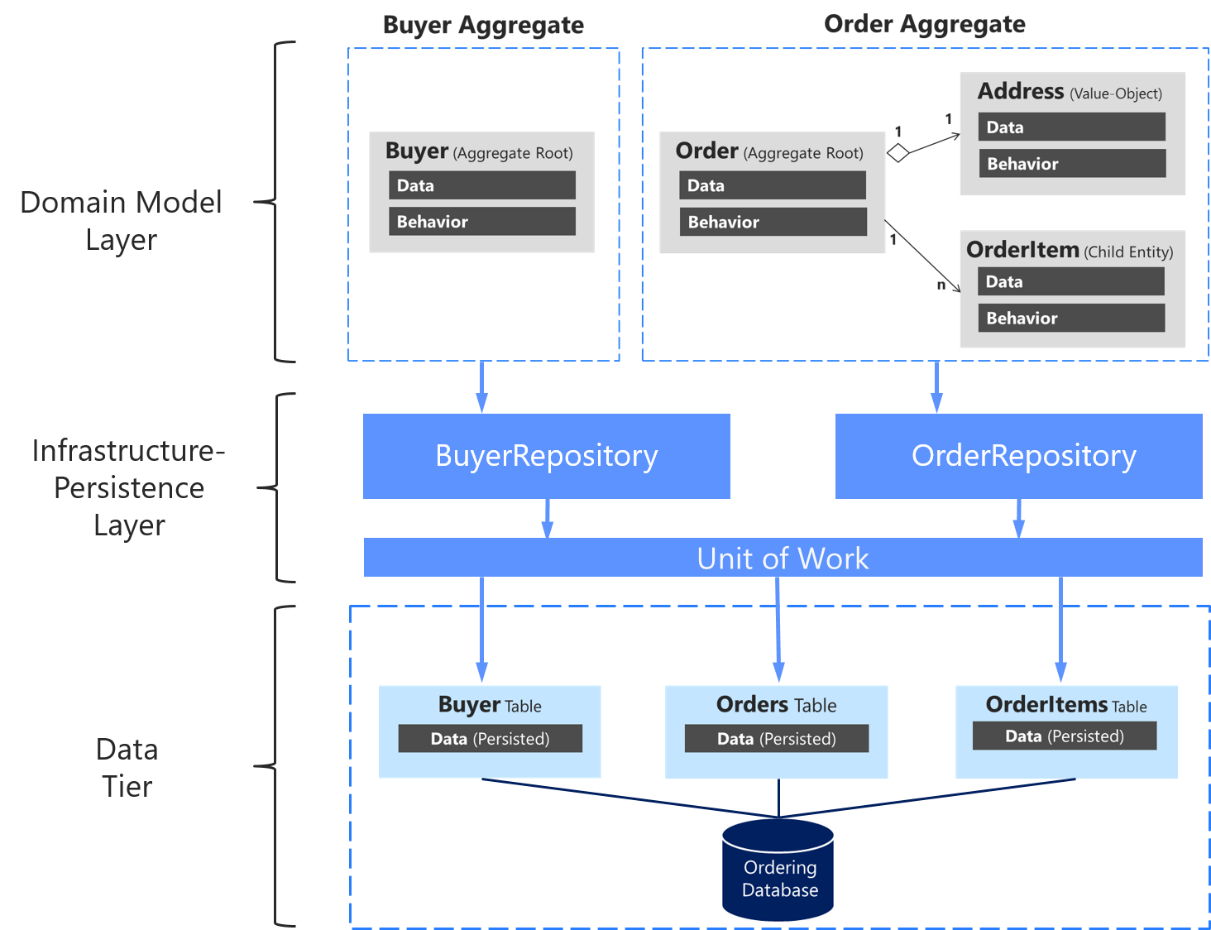
Repository PatternはRDBなどのPersistence層とApplicationを分離するためのLayerです。Application側がRepository層にデータアクセスすると、まるでRepository層がin-memoryのデータを取得してきて返してくれているかのようにデータにアクセスすることができます。
またRepositoryは集約ルートごとに定義するのが定石です。
Repository Patternを導入するメリットとして、「Persistence層を隠蔽することでData Storageを容易に変更できる」ことが挙げられます。
例えばUserに関するデータアクセスを扱いたいケースがある場合、UserRepositoryInterfaceというInterfaceを作っておき、そのInterfaceをimplementしたEloquentUserRepositoryクラスやFileSystemUserRepositoryクラスを作成します。そうすることで、Eloquentの場合とFileSystemの場合を容易に入れ替えることができるようになります。SOLID原則のDですね。
EloquentとRepository
まず、Active Record Patternで実装されているOR MapperであるEloquentを利用するということは、RDBとDomain Objectとの密結合を求めているということなので、Data Storageを変更することはあまりないと思います。なのでEloquentを用いているアプリケーションにRepository Patternを導入するメリットは無いと思います。(というかこの行為は、Eloquentの良さを打ち消そうとしている。)
ただし、複数モデルクラスが関わってくるような複雑なロジックの置き場所のためであれば、それをRepository層と呼ぶのかは分かりませんが、Modelクラスの前に層を導入することは有効だと思います。
ここからは例えばの話ですが、LaravelでEloquentを使いながら、Data Storageを変更する可能性を考慮してRepository層を導入しようとする場合の不便について述べます。
Eloquentでデータを取得した際の戻り値は、Model Objectです。テーブル構造をさらけ出していて、かつデータアクセスメソッドを持っているModel ObjectをRepository層を通したデータ取得関数の戻り値とするわけにはいきません。Repository層はPersistence層の全てを隠蔽するものだからです。そこで、Model Objectとは別にDomain Object / DTOを用意しておき、Model Objectのデータをそれに移し替える必要性が出てきます。
つまり流れとしては、RDBからデータを取得→Eloquentを通してデータをModel Objectに格納する→そのデータをDomain Objectに格納するという流れになります。要するに、1つ余分な流れが発生してしまっているというわけです。
という訳で、まとめると、Eloquentを使っている場合、Repository Patternの実現のためにRepository層を導入するのは、あまり良い案ではないでしょう。
Clean Architecture
(そもそも小規模アプリケーションにclean architectureを導入するのがおかしいというのもありますが、)自分は、研修中にclean architectureを習得できずに爆死した身なので、Clean Architectureについて詳しく触れることはできないです。
ただ、ここまでに説明してきた内容は、Clean Architectureを理解するための根幹であると考えています。
The Clean Architectureでも説明されていますが、Clean Architectureとして示されている上の図のような4層構造が、必ずしも是とされる訳ではありません。重要なのは4つの層に分けることではなくて、きちんと関心の分離を行い、そして「The Dependency Rule」、つまり依存の流れを重んじることが重要なのです。内側、つまり最も重要とするものに依存が向かうように設計することで、重要ではないものに対する変更を重要なものに波及させないようにします。
また層分けを行なった後、層間で受け渡されるのはDTOであるべきであるとも、The Clean Architectureで述べられています。Eloquentによって生成されるModel Objectを受け渡すことが不適切であることは先に述べました。
また、ここまでに紹介させてもらったRepository Patternや、Data MapperとDomain Model、ViewModelなどの考え方などは、Clean Architectureで実際に使われている考え方です。
 【転載】Clean Architecture
【転載】Clean Architecture
ということで、Clean Architectureについての紹介はここまでにします。良かったと思うコンテンツをいくつか紹介して終わりにします。
結局のところ、提唱者が書いているため、原著 is 最強です。それにこの原著、自分は一部しか読んでないのですが、すごく分かりやすく書かれている印象を受けました。
上の動画は同期の子に紹介してもらいました。めちゃ分かり易かった、、、!
最後に
投稿に関してご意見もしあれば、ブラッシュアップのため是非いただきたいです。🙇♂️
関心の分離や依存関係に関することなど、アーキテクチャのための基礎は理解できたような気がせんこともないです。しかし同時に、考えれば考えるほど泥沼にはまっていった感が残っています。言葉遊びをしているかのような感覚。実際の現場でアーキテクチャに関する事案に遭遇するまで、アーキテクチャについての探求はこれにて終了しようと思います。
グッバイ アーキテクチャ、また会う日まで。
Reference
Video
-
Laracasts
https://laracasts.com -
Becoming a better developer by using the SOLID design principles by Katerina Trajchevska
https://www.youtube.com/watch?v=rtmFCcjEgEw&t=693s
Books
-
Clean Architecture: A Craftsman's Guide to Software Structure and Design (Robert C. Martin Series)
https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164 -
Clean Code: A Handbook of Agile Software Craftsmanship (Robert C. Martin Series)
https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship-ebook/dp/B001GSTOAM -
Head First Design Patterns: A Brain-Friendly Guide
https://www.amazon.com/Head-First-Design-Patterns-Brain-Friendly-ebook/dp/B00AA36RZY -
Patterns of Enterprise Application Architecture
https://www.martinfowler.com/books/eaa.html -
From Apprentice to Artisan
https://leanpub.com/laravel
Articles
Active Record / Data Mapper / OR Mapper
-
SQL上級者こそ知って欲しい、なぜO/Rマッパーが重要か?
https://www.slideshare.net/kwatch/sqlor -
The Vietnam of Computer Science
http://blogs.tedneward.com/post/the-vietnam-of-computer-science/ -
Object-Relational Mapping is the Vietnam of Computer Science
https://blog.codinghorror.com/object-relational-mapping-is-the-vietnam-of-computer-science/ -
ORM is an anti-pattern
https://seldo.com/posts/orm_is_an_antipattern -
OrmHate
https://martinfowler.com/bliki/OrmHate.html#footnote-oss -
What's the difference between Active Record and Data Mapper?
https://culttt.com/2014/06/18/whats-difference-active-record-data-mapper/ -
How is Doctrine 2 different to Eloquent?
https://culttt.com/2014/07/07/doctrine-2-different-eloquent/ -
Data Mapper
https://martinfowler.com/eaaCatalog/dataMapper.html -
Active Record vs Objects
https://sites.google.com/site/unclebobconsultingllc/active-record-vs-objects
Repository Pattern
-
Repository
https://martinfowler.com/eaaCatalog/repository.html -
Repositories Simplified
https://laracasts.com/lessons/repositories-simplified -
The Repository Trap, and Other Ramblings
https://laracasts.com/lessons/the-repository-trap-and-other-ramblings -
Repositories and Inheritance
https://laracasts.com/lessons/repositories-and-inheritance -
インフラストラクチャの永続レイヤーの設計
https://docs.microsoft.com/ja-jp/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/infrastructure-persistence-layer-design -
Laravel におけるリポジトリ実装のポイント
https://blog.shin1x1.com/entry/laravel-repository -
What are the benefits of using Repositories?
https://culttt.com/2014/09/08/benefits-using-repositories/ -
The Repository Pattern
https://shawnmc.cool/2015-01-08_the-repository-pattern
Dependency Injection
-
Laravelで始める依存性の注入(DI)
https://qiita.com/harunbu/items/079ea728d2c9cf4f44d5 -
Thorough IoC In Laravel 4 With Unit Test
https://www.youtube.com/watch?v=F1VyHfoUuLU -
Service Container
https://laracasts.com/series/laravel-6-from-scratch/episodes/38
Facade
-
Laravel Facades
https://phpnews.io/feeditem/laravel-facades -
Response: Don’t Use Facades
https://phpnews.io/feeditem/response-don-t-use-facades
Event Driven
-
Event-Driven Laravel Applications
https://blog.pusher.com/event-driven-laravel-applications/ -
Event-Driven Code
https://laracasts.com/lessons/event-driven-code
View Composer / View Creater / View Model
- Consider View Models
https://laracasts.com/series/whip-monstrous-code-into-shape/episodes/11
Clean Architecture
-
The Clean Architecture
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html -
【プログラミング】実践クリーンアーキテクチャ 音ズレ修正Ver.
https://www.youtube.com/watch?v=BvzjpAe3d4g
Others
-
Laravel Document
https://readouble.com/laravel/7.x/ja/lifecycle.html -
Maintain Slim PHP MVC Frameworks with a Layered Structure
https://www.toptal.com/php/maintain-slim-php-mvc-frameworks-with-a-layered-structure -
Single Responsibility Principle: A Recipe for Great Code
https://www.toptal.com/software/single-responsibility-principle -
A Lesson in Refactoring
https://laracasts.com/series/lets-build-a-forum-with-laravel/episodes/15 -
Taylor Otwell: “Thin” Controllers, “Fat” Models Approach
https://laraveldaily.com/taylor-otwell-thin-controllers-fat-models-approach/ -
Chapter 1. Layered Architecture
https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/ch01.html#idm46148422387048
Architecture -
俺が悪かった。素直に間違いを認めるから、もうサービスクラスとか作るのは止めてくれ
https://qiita.com/joker1007/items/25de535cd8bb2857a685 -
Comparison of Domain-Driven Design and Clean Architecture Concepts
https://khalilstemmler.com/articles/software-design-architecture/domain-driven-design-vs-clean-architecture/ -
マイクロサービス ドメイン モデルの設計
https://docs.microsoft.com/ja-jp/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/microservice-domain-model