昨日の続きです。
卒業制作で「気がついたらYoutubeを観て1日が終わってた撲滅ツール!動画内の音声を検索!」というのを作ります。
Youtubeの字幕ファイルを抜き出すところまで成功しましたが、できたのはvtt形式のファイルだけでした。
使いたいのはテキスト本文だけなのでどうしよう、というのが今回の話です。
vttとttml形式の違いを調べる。
HTML5 の 要素で使えるキャプションファイルには、「WebVTT」と「TTML」の2種類があります。WebVTT 形式のほうがフォーマットとしてはシンプルで、字幕の表示タイミング (タイムコード) と文面を、時系列に記述するだけです。
どうやらvttでも問題ない、というかいっそそちらのほうが可読性ありそうな感じです。今できないことをがんばってttmlにこだわる必要もないので、vttで行きましょう。
vttからテキストだけを抽出する
以下のサイトで簡単に変換できるようです。(システムとして考えるとコード公開されてないと組み込みにくい気がしますが一旦やれるか否かの確認をします。)
簡単にできましたー。同じ文章が繰り返したりしているけど、これはYoutubeから抜いたときからそうなのでおいおい重複を削除できるかTODOに追加しておきましょう。
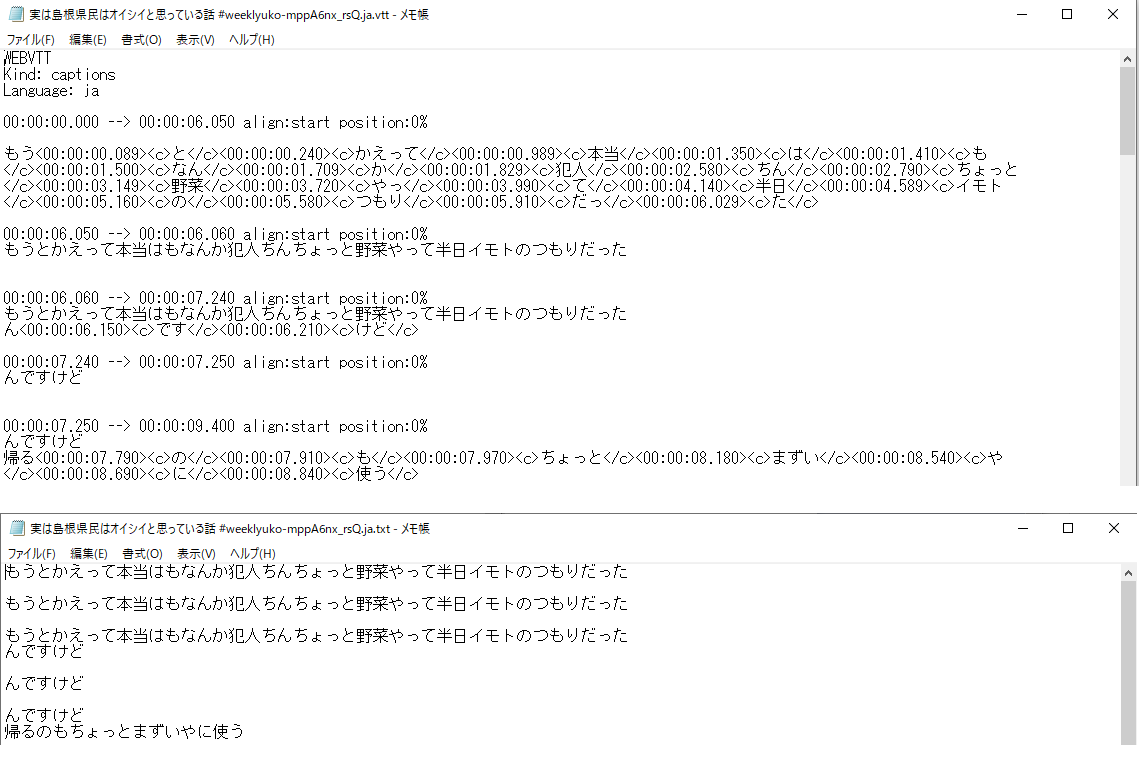
その発言の時刻があったほうが動画の場所をみつけやすいかな、とも思いましたが流石にvttのままはそもそもの日本語が読みにくいので、やはりtxtにしてしまいましょう。
Subtitles Converterのサンプルコードを探す
npmで「Subtitles Converter」で検索してみます。
Convert and modify subtitle files with NodeJS.
字幕ファイルの変換と修正をNodeJSで行います。
There are many subtitle tools written in node, but there are none that support all popular subtitle and caption formats. subtitle-converter builds off of the work of others (most notably node-captions, node-webvtt, and subtitles-parser) in order to ultimately become the only subtitle module necessary to include in your node project.
nodeで書かれた字幕ツールはたくさんありますが、一般的な字幕やキャプションのフォーマットをすべてサポートしているものはありません。 subtitle-converterは、他の人たち(特にnode-captions, node-webvtt, subtitles-parser)の仕事をベースにして、最終的にあなたのnodeプロジェクトに含める必要のある唯一の字幕モジュールになるようにしています。
Currently supported input file types: dfxp, scc, srt, ttml, vtt, ssa, ass
現在サポートされている入力ファイルタイプ: dfxp, scc, srt, ttml, vtt, ssa, ass
Currently supported output file types: srt, vtt
現在サポートされている出力ファイルの種類: srt, vtt
All output files are encoded with UTF-8. In the future we may support more encoding types.
すべての出力ファイルは UTF-8 でエンコードされています。将来的には、より多くのエンコードタイプをサポートするかもしれません。
見つけたー! と思ったけど出力ファイルがtxtじゃない(´・ω・`)
Universal Subtitle Parser
ユニバーサルサブタイトルパーサー
Identifies a subtitle type by its text and converts it to a JavaScript object.
字幕タイプをテキストで識別し、JavaScriptオブジェクトに変換します。
おや? アウトプット形式をtxtで調べてたけどaudacityかassでも可読性あってこれで十分だな。というか時刻もあってむしろ良い。

うーん、npmを「ass vtt」で検索してみたけどassをvttにするのは見つかるけど逆はないな。
見つけたー! assでもいいかな、と思ったけどtxtに変換できるの見つけたー! 「keywords:captions」で検索するのが正解だったか。
npm i -S vtt-to-text
でインストールしてサンプルコードの中にvttの中身をコピペして実行。できた!
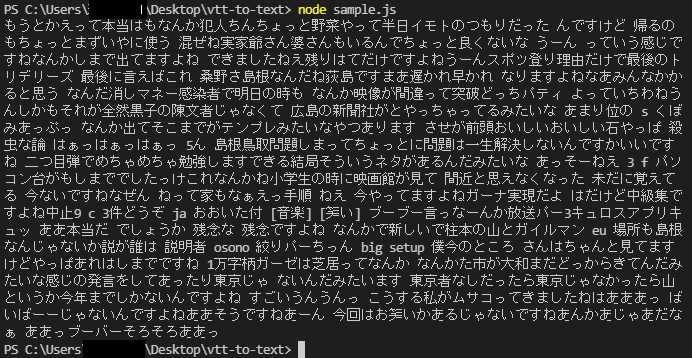
前述のサイトであった文章の重複もなくってる! これはうれしい誤算。
今回対応したTODO
vttとttml形式の違いを調べる。→済
参考記事の"xmlでもあるttml形式が個人的には加工しやすそうだなと感じた。"が本当か調べる。→済
vttフォーマットでテキストを検索してカウントできるかやってみる。→テキスト化できたので済
次回へのTODO
サーバー側で動かす実装方法を調べる。
Linuxサーバーに乗せる?
そこまでするよりユーザーのクライアント動作としてしまう?
自動字幕ではなく、ちゃんと字幕がある場合はそちらをダウンロードするような仕組みを考える。
公式字幕つきの動画をみつけてコマンドが正しく動くか確認する。
Youtube側の仕様変更の際のバージョンアップマニュアルを作成する。