概要
- やりたかったことはタイトルの通り
-
wikidata では、記事を識別するのに「単語」ではなくQやPから始まるID(
entity ID)を利用しているため、その考慮が必要であった- wikidata においては、「トヨタ自動車」みたいな文字列は
Labelなどに相当する - 「トヨタ自動車」の
entity IDは Q53268
- wikidata においては、「トヨタ自動車」みたいな文字列は
- 企業名の表記ゆれも吸収してあげる必要があった
- 「トヨタ自動車」のラベルはあるが、「トヨタ」のラベルは無い
- でも、「トヨタ」で問い合わせても子会社一覧を取得できてほしい
- 例えば、「トヨタ自動車」に対して、wikidata 上の表記ゆれ情報(
alias、alos known as)には、以下の通りで「トヨタ」も含まれている
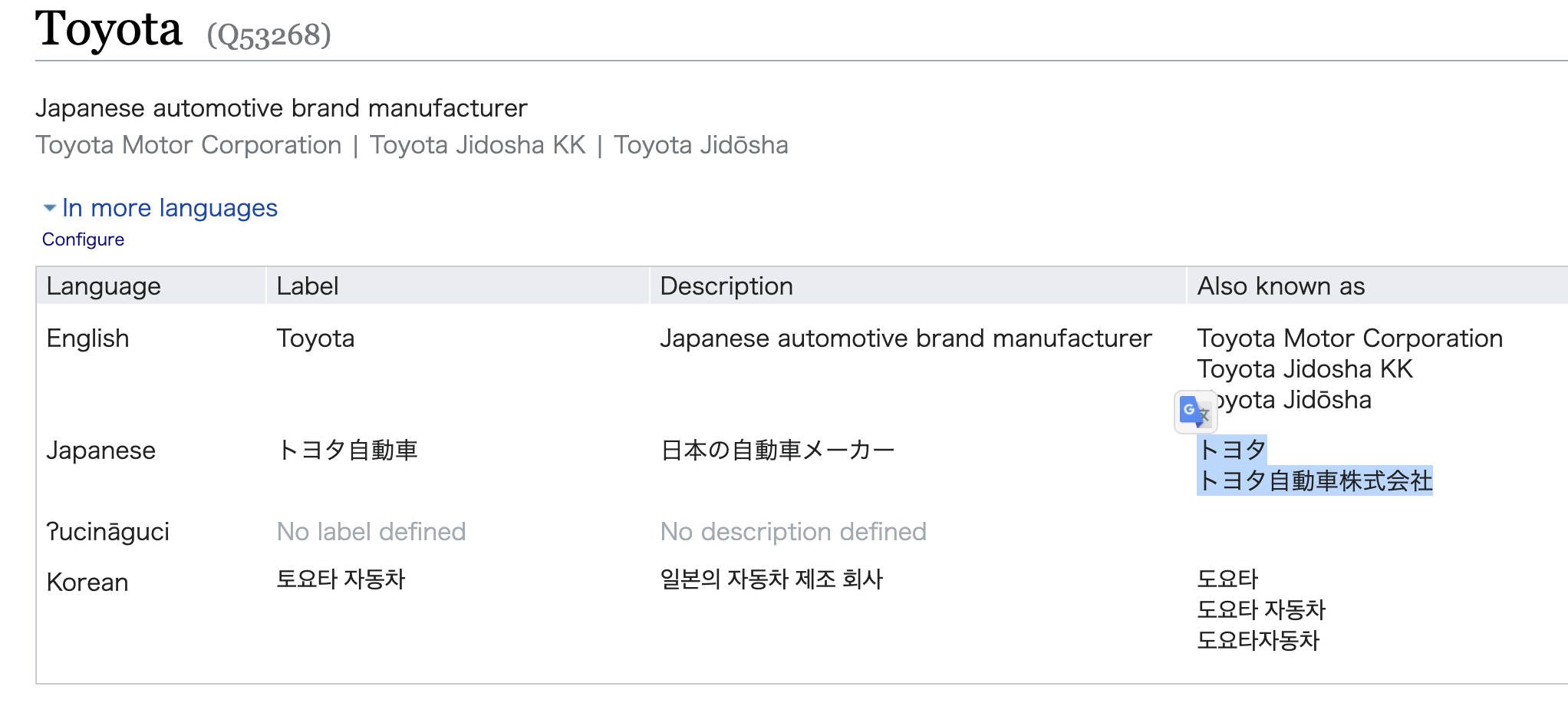
- 言語(
language)の情報もしっかり与えないとうまく結果表示されなかったので注意 - それらを考慮して得られたのが以下の結果とクエリ
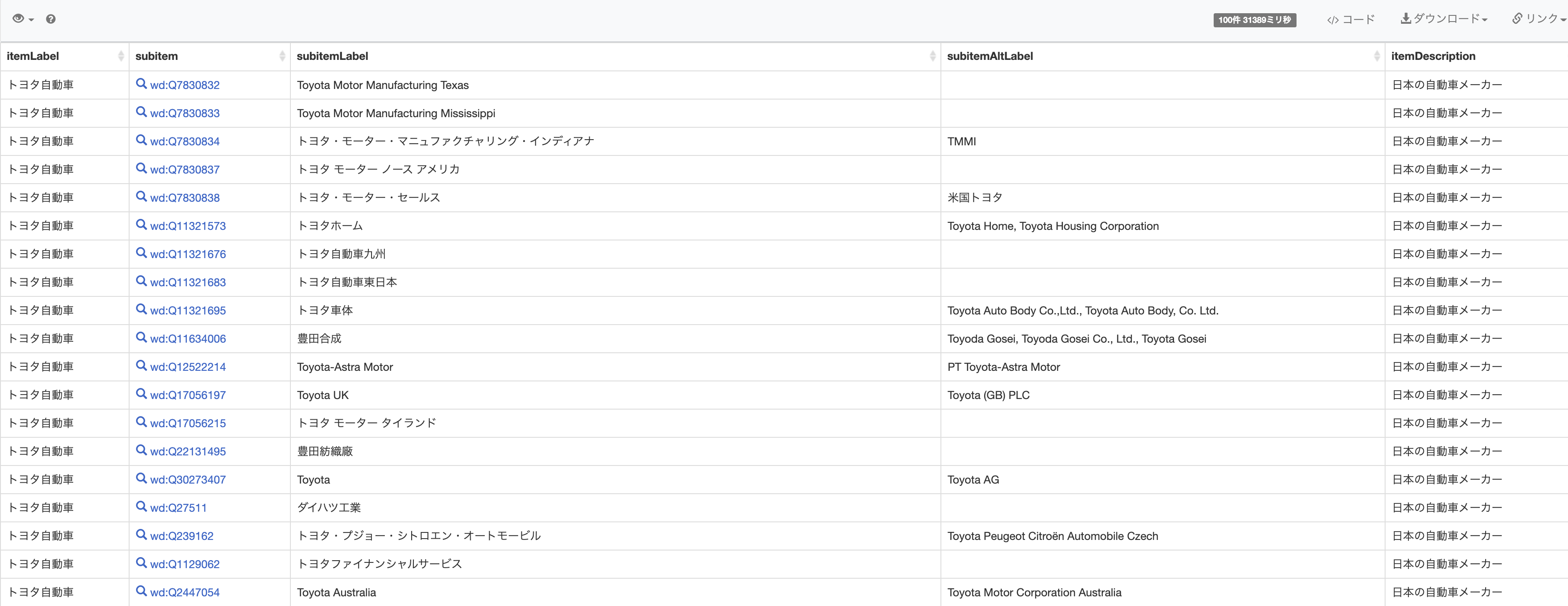
-
ここ から以下のクエリ相当がどなたでもブラウザ経由で実行できます
- 「トヨタ自動車」を「トヨタ」に変えても結果が得られます
- というか、「富士通」などに変えてもうまくいきます
-
ここ から以下のクエリ相当がどなたでもブラウザ経由で実行できます
SELECT ?itemLabel ?subitem ?subitemLabel ?subitemAltLabel ?itemDescription WHERE {
?item wdt:P31 wd:Q4830453.
?item skos:altLabel ?altabel .
?item rdfs:label ?label .
FILTER(?label = "トヨタ自動車"@ja || ?altabel = "トヨタ自動車"@ja )
?subitem wdt:P31 wd:Q4830453.
?subitem wdt:P749 ?item
SERVICE wikibase:label { bd:serviceParam wikibase:language "ja,en". }
}
LIMIT 100
詳細
事前知識
wikidata 周りに関する基本中の基本情報のみ
wikidata について
- wikipediaなどを運用している、wikimedia財団 のプロジェクトの1つ
- 知識ベースの辞典みたいな感じ
- こういう知識ベース的なものはいろんなところで作られたりはするけど、オープンで知名度が高いといえば wikidata が最有力候補かも
- 言語に依存しない方法でウィキペディアの記事を作成するプロジェクトにもwikidataが使われるとか
- SPARQLを用いて、wikidataのデータを探索することができる
- 業務で使うようなRDBへのSQLのクエリより、もう少し抽象化された、もはやQAシステム的な探索というか問い合わせもできる
- 例えば、「もっとも多くの俳優に演じられたキャラクターは?」みたいな問い合わせをすることができる
- この回答は、ドラキュラが正解そう?
- あくまでも、wikidata上のデータをソースとしての暫定的な回答であることに注意
SPARQL について
- RDFクエリ言語の1つ
- クエリ言語なので、SQLのように、何かしらのデータ集合から特定のデータ(集合)を検索するためのものである
- 上で述べたように、抽象的な問い合わせを作ることができる
- RDFについては後述するが、RDFのクエリ言語であるため、クエリの形もRDFの性質に則してる
- Prolog 触ったことある人なら、似た印象を感じるかも
- Python などから実行できるライブラリもいくつかあるぽい
RDF について
- 主語、述語、目的語の形でリソースに関する情報を表す枠組み
- W3Cによって、規格化されている
- 余談だが、 RDFにも意味論が与えられており 、これはかなり Prolog の宣言的意味論に近い感じがする
- もともとは、セマンティックwebのための規格であったが、知識ベースを操るうえでも基本的な枠組みとしてよく採用されている感じがする
WikidataQueryService(WQS)について
- ブラウザからwikidataへのSPARQLクエリを誰でも手軽に試せるやつ
- 例題も豊富
- [猫ちゃんであるもの(猫のインスタンス)一覧を出す] (https://query.wikidata.org/#%23%E3%83%8D%E3%82%B3%0ASELECT%20%3Fitem%20%3FitemLabel%20%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20wdt%3AP31%20wd%3AQ146.%0A%20%20SERVICE%20wikibase%3Alabel%20%7B%20bd%3AserviceParam%20wikibase%3Alanguage%20%22%5BAUTO_LANGUAGE%5D%2Cen%22.%20%7D%0A%7D) とか
- 画像とかグラフとかのUIもあってマジすごい
- 大統領の関係グラフ とか
- クエリによっては、timeout になりがちなので、その場合は limit を入れると結果を(限定的かもしれないけど)得られるのでお試しを
- ってこの動画でお聞きしました
- URLにSPARQLのクエリが埋め込まれるので、自分が作ったクエリはURLでやり取りができて便利
試行錯誤の記録
後で書く
考察
-
PythonコードからSPARQLを呼び出すライブラリなどを用いて、企業名を自由変数としてクエリ文字列に埋め込んで Python コードとして実行するともっと柔軟になりそう
- その際には、en OR ja も一緒に与えたほうが良さそう
- 今回、子会社を抽出するのに、 wdt:P749(上部組織) の述語を用いたが、ここは別の述語を試してそれとのORを取るほうがいいかも
- 資本提携とか、そういう関係で定義されている子会社的企業もありそうなので