はじめに
一般的なストリーム処理では、アプリケーションはProducer API経由でTopicからイベントを取り込み、処理後に別のTopicに加工したイベントを送ることによりデータ処理をします。しかしKafkaと通信するアプリケーションにはそれ以外の利用パターンも多く存在し、場合によってはアプリケーションのスループットが充分引き出せない場合もあります。。Partitionによる並列処理能力を超えるスループットが必要な場合、DBやその他ストレージにデータを書き込んだり、処理内で別の同期通信処理 (e.g. REST API通信) を行う場合です。
この課題への解法には、Goで書いたり、Reactiveプログラミングモデルのアプローチを取ったり様々ありますが、それなりに抜本的な解法の変更となるのが一般的です。
本エントリではまた別のアプローチとしてConfluentがオープン化したConfluent Parallel Consumerについて説明します。
Kafka ConsumerとPartitionと並列処理能力
Kafka Consumerを利用したアプリケーションは同じID (group.id) を指定することによりConsumer Groupとして並列処理をする事が可能です。しかしこの並列処理能力は無尽蔵に増加させる事は出来ず、対象TopicのPartition数がその並列処理能力の限界値となります。それ以上のConsumerを追加しても処理には参加できません。
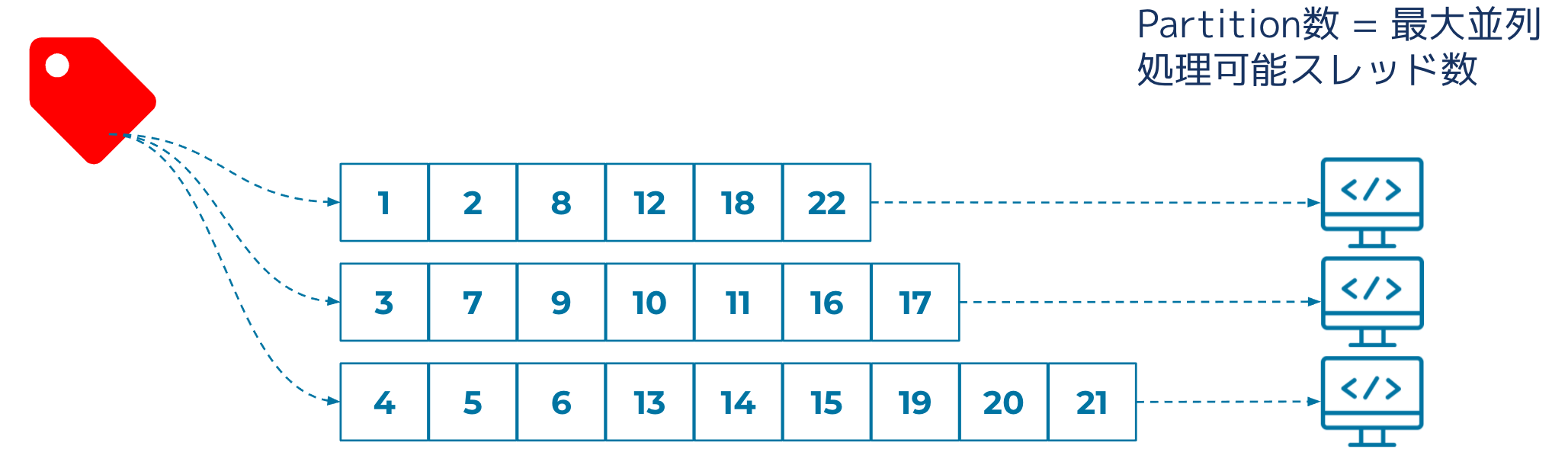
これは技術的なという理由ではなく論理的な理由で制限が設けられています。KafkaはStreamにおけるイベント順序を保証しますが、これはStream (より具体的にはTopic) 全体ではなく分割されたPartition単位での保証です。複数のConsumerに同一Partitionへのアクセスを許容するとイベントの処理順序の保証ができません。
Partitionの数を増やし、Consumer Groupのサイズをそれに合わせて増やせば処理能力はほぼ線形に延びますが、KafkaがPartitionを管理する上での制約や負荷もあり無尽蔵に増やす事は出来ません。また、本来欲しいのはPartition単位の順序保証ではなくKey単位の順序保証であるケースがほとんどですが、KafkaはOFFSET (ストリームのどの地点までConsumer Groupが処理を終えたのか) 情報をPartition単位で管理する仕組みでありKey単位のOFFSETトラッキングができません。
Confluent Parallel Consumerのアプローチ
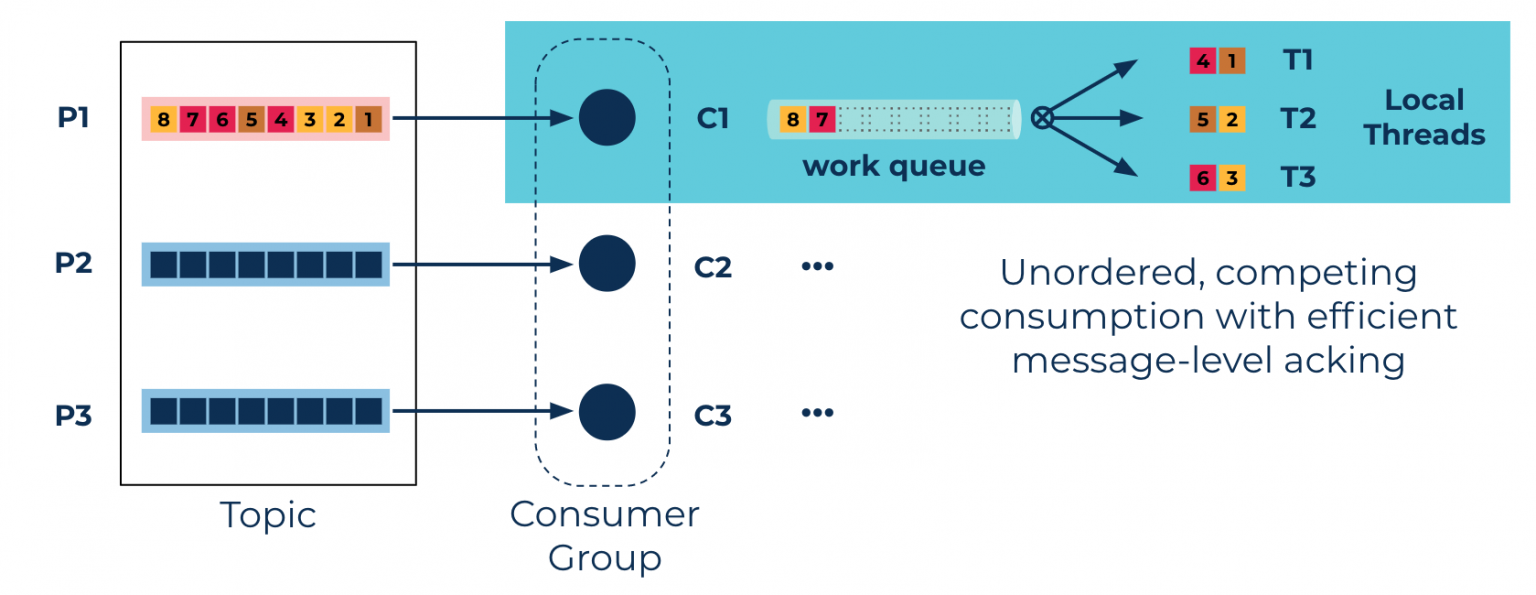
Confluent Parallel Consumerのアプローチは、PartitionではなくKey単位の順序保証をする事による並列処理能力の向上です。Consumerというだけあってクライアント側で作動するライブラリですが、Consumer Groupベースでの並列処理に加えて1 Consumerが複数のスレッドを扱うことにより並列処理をするモデルです。 (ここでのスレッドはJVMが管理する論理的なスレッド) 内部で処理管理用のキューを利用します。
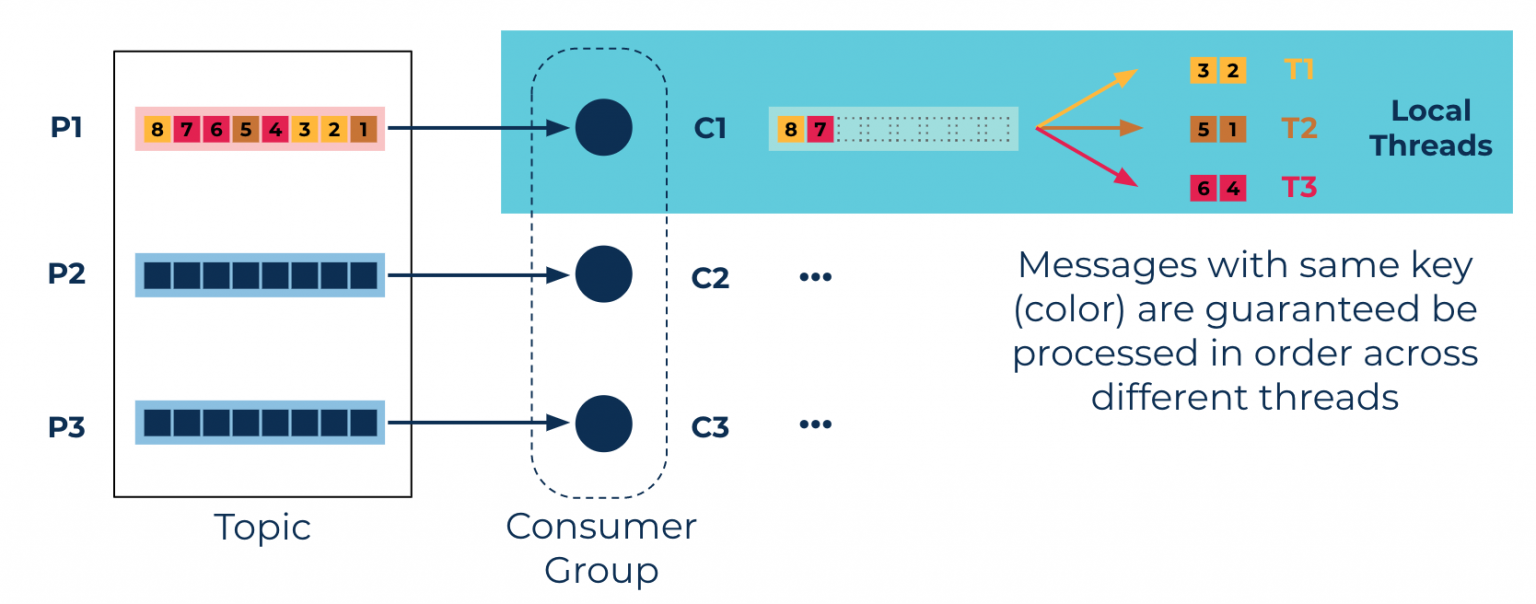
Keyの順序保証が不要なモードもあります。最大スレッド数は指定できるので、処理順序保証が不要な場合にはスレッド数の指定で並列処理能力を制御できます。Keyベースでの順序保証をするモードではKeyの数が並列処理能力の上限とはなりますが、Keyの数が多ければ多いだけ高い並列能力が見込めます。
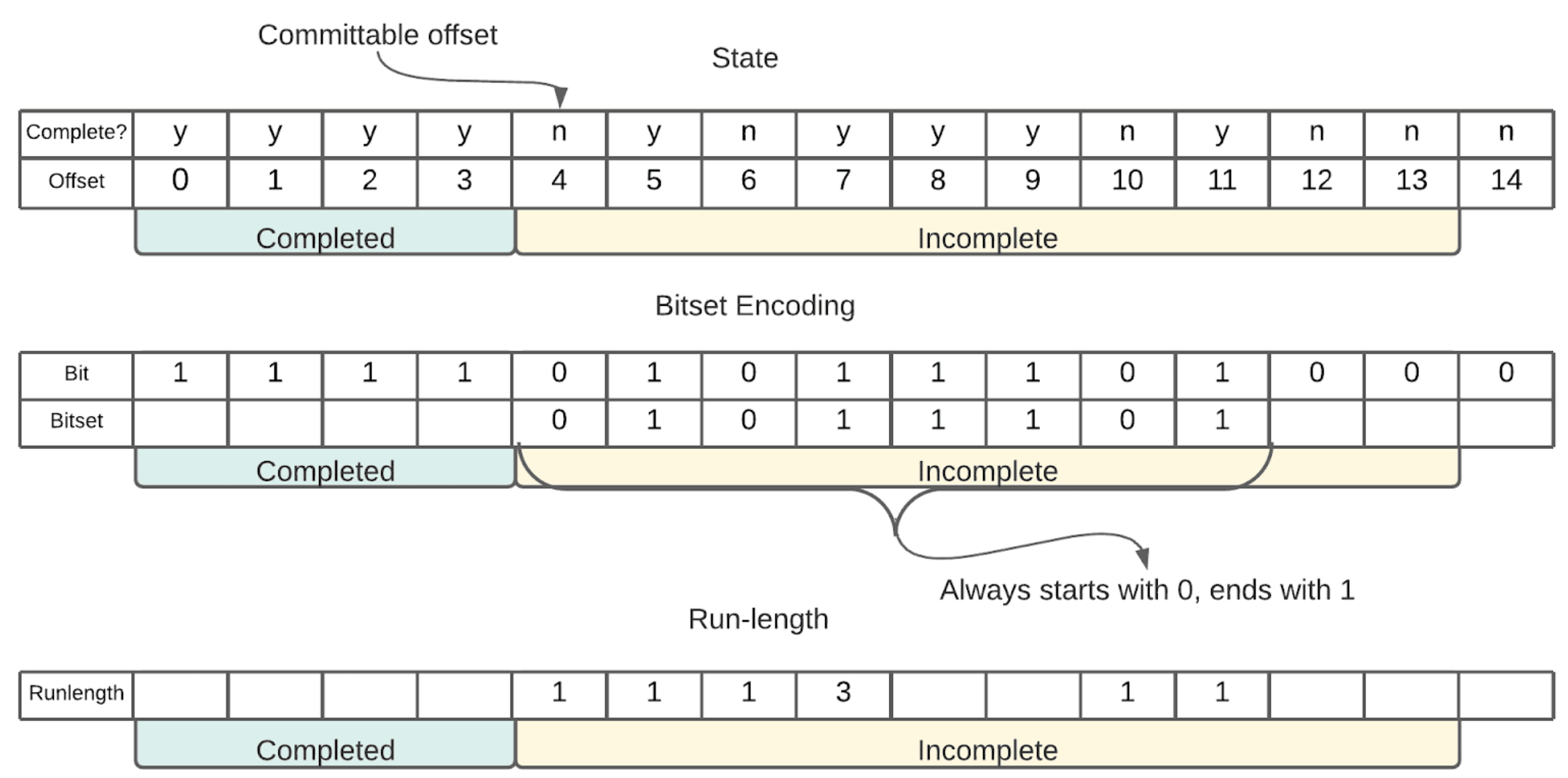
Key単位のOffset管理 - Offset Encoding
Confluent Parallel Consumerは通常のKafka Consumer同様にTransactionやExactly Onceセマンティックスをサポートしますが、その為にはKey単位のOffset管理をする必要があります。Confluent Parallel Consumerでは、PartitionとしてCommit可能 (それ以前の全てのOffsetが処理済み) なOffsetをコミットし、以降の不完全な状態のオフセットをシリアライズ&圧縮&BASE64エンコードした上で、Offsetコミット時にメタデータの一部として合わせて送ります。
このOffset Encodingの処理ではさらに、データによって圧縮効率の異なる2つの方法でシリアライズ&圧縮し、サイズの小さい方を採用して保存しています。
おわりに
Confluent Parallel ConsumerはCSID Accelerator (Customer Solutions & Innovations Division)というプロジェクトの一環で、Confluentがプロフェッショナルサポートを別途提供しているものです。実際のお客様エンゲージメントから派生した要望であり、かつConfluent Platformとして機能提供が出来ない領域を補完する役割を果たしています。
中でもこのParallel ConsumerのソースはApache Licence 2.0でオープン化されており、どなたでもご利用する事が可能です。