** 本エントリはDistributed computing Advent Calendar 2021の12/1エントリです。
はじめに
Apache Kafkaはメッセージブローカーであると同時にストレージの役割も果たす、それまでのMQの世界観とは少し異なった機能性を有しています。またデータのグループとなるTopicの構成やKafkaを利用するクライアントの設定如何によって全く異なるワークロードを同一クラスタ上で処理する事が可能です。
Kafka創世記には、マイクロサービス間の非同期コミュニケーションやData Lakeへのデータ投入、そしてIoTやサーバー/アプリログのように大量のデータを捌く用途で広く活用されました。その後Kafka ConnectやKafka Streamsの出現により、データソース/シンクとの繋がりやストリーム処理、Exactly Once Semanticsのアプローチが注目され、Kafka上のストリーム処理へとユースケースが広がりました。
ここで改めて、Kafkaが元々思想するStream-Table Duality (ストリーム/テーブル双対性)の現実的なアプローチと、改めてKafkaを「整合性を保ちつつデータを運ぶデータ基盤」として見る動きがエンタープライズで活発になりました。__メッセージブローカー__から__データプラットフォーム__へとKafkaに対する市場の見方が変わったのもこの時期です。
本エントリでは、Kafkaのデータデータモデルとそれを扱う論理構成、Stream-Table Duality、そしてデータ整合性の考え方についてご説明します。
本エントリは先日 (2021/09/24) 実施されたApache Kafka Meetup Japan #9での登壇内容をなぞらえたものとなっています。
参考
Apache Kafka Meetup Japan #9
登壇資料:「カフカはデータベースの夢をみるか」
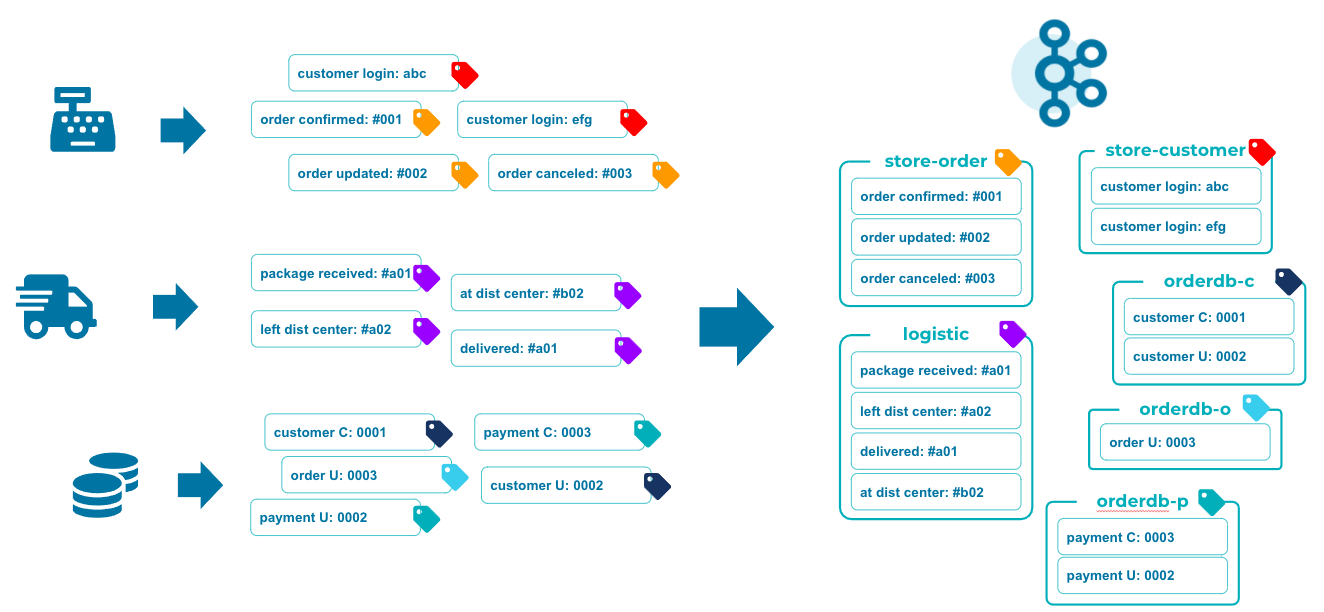
Kafkaのデータモデル - StreamとLog
KafkaにEventを送信する際には「何に関するイベントか」を指定するTopicを指定して送付します。KafkaはこのTopicごとにEventを集約し、到着した順序通りに格納します。この集約は論理的には__Stream__として扱われ、物理的には__Log__として格納されます。このStreamとLogは同じものを異なる側面から捉えた見方であり、これらを同じものの様に説明したり、異なるものとして扱ったり、見る角度によって扱い方が変わる事があります。
この際Eventの順序は厳密に扱われる、というよりはKafkaの物理的なデータの格納方法によって自然と厳密なものとなります。具体的には、全てのイベントはその順序及びデータ自体は普遍 (Immutable) として扱われ、新たなイベントは常にアペンドされる形で追加されます。あくまでEventは事実 (Fact) であり解釈によって変わらないものとして見ており、この格納方法の為Logと呼称されます。
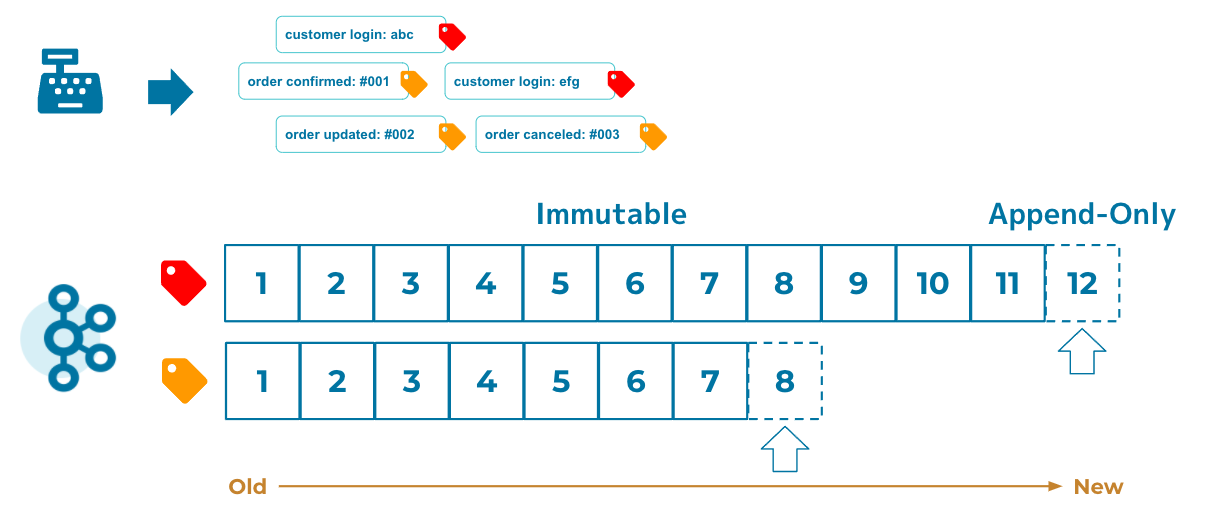
この格納方法がデータの整合性を保つ重要な要素であり、各Eventが普遍なだけでなくEventの順序もデータ整合性を保つ上で必要な要素です。
チェスとデータベース
チェスや将棋、囲碁の様なボードゲームでは、プレーヤーの手を一手一手を__漏れなく__、__順序通り__記録する事によりその対局の移り変わりを再現出来る事が知られています。囲碁における棋譜には数百年前の伝説の対局の棋譜が残っているものもあり、現在の棋士が棋譜によって時間を超えてその対局を再現する事ができます。
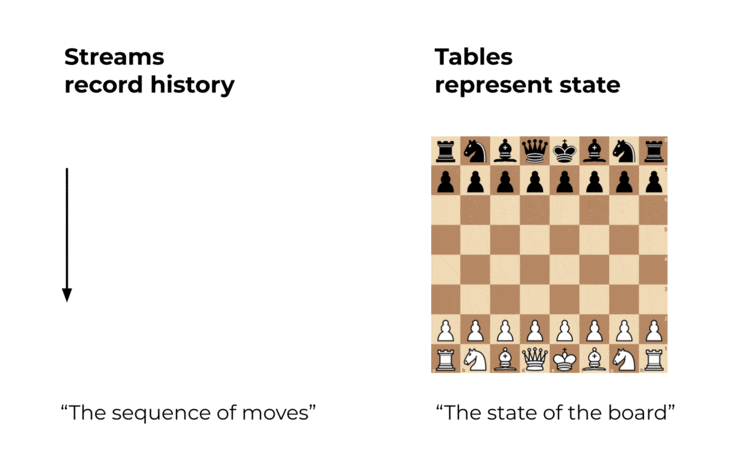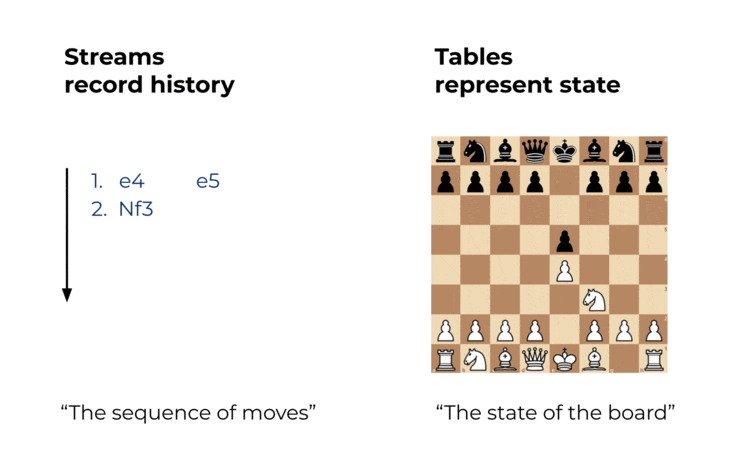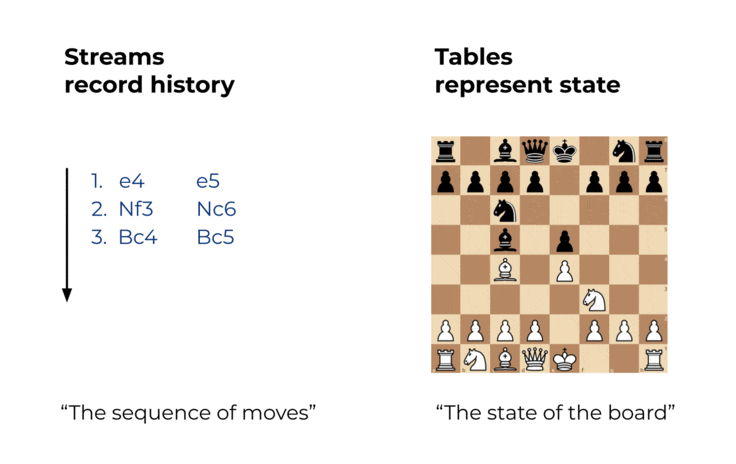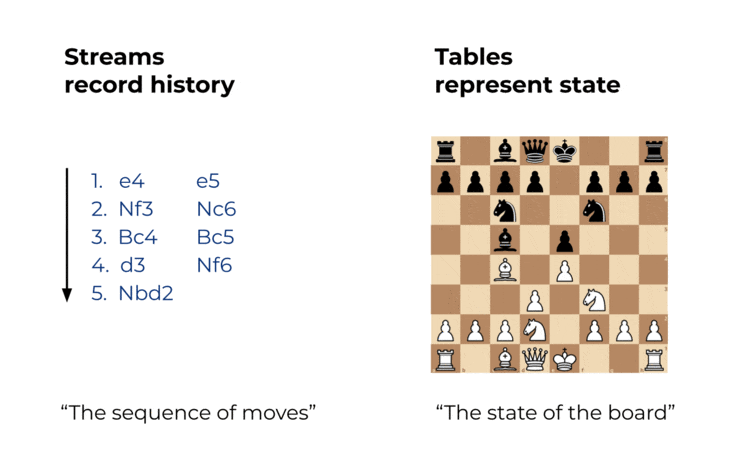
この思想はデータの世界でも有効です。
データベースレプリケーションはKafkaの登場よりずっと前からあった技術ですが、異なるサイトに設置した2つのデータベースのデータを常に同じ状態に保つ事ができます。一般的にはこれらデータベースはPriamryとSecondaryと位置付けられ、データ更新が発生するのはPrimaryのみです。更新はPrimaryに、そしてPrimaryで発生したデータ更新がSecondaryにも反映されます。
このレプリケーションはPriamryのデータをExportしてSecondaryにImportしている訳でも、Primaryに対して発行されたクエリをSecondaryに対しても発行している訳でもありません。前者では書き込みが発生している状態のPrimaryに対して完全なスナップショットを取る事が困難であり、後者ではクエリの転送だけでなくクエリが失敗した場合の再実行等の配慮も必要となります。実際にはPrimaryに発生したトランザクションログ (OracleのredoログやMySQLのbinlogに該当するもの) を転送し適用することにより達成しています。
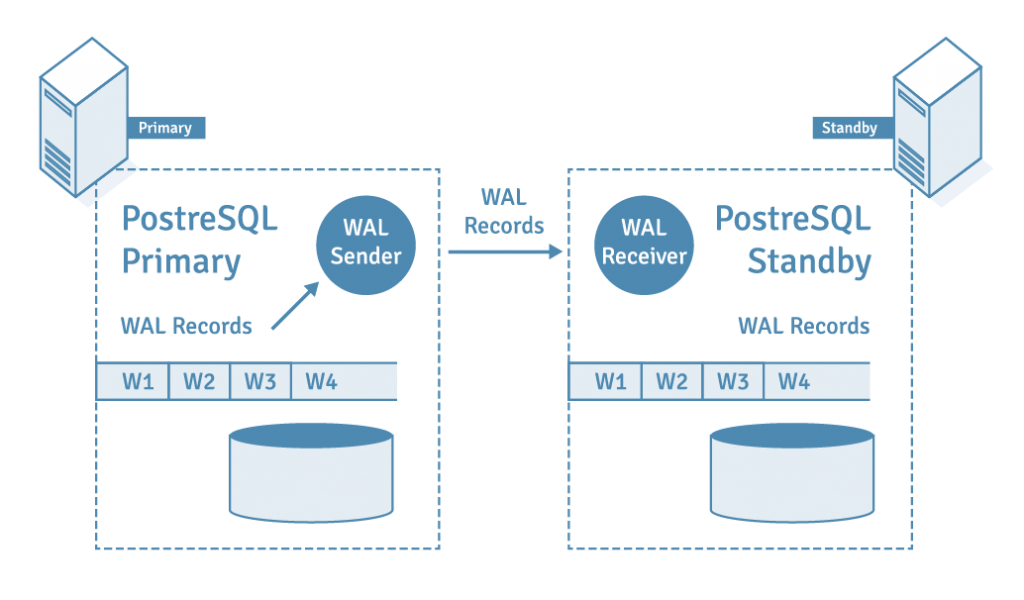
PostgreSQL Replication and Automatic Failover Tutorial
データベースは全ての加工処理をメモリで行い、その結果をドライブと同期を取ることにより効率的にデータを永続化しています。一方メモリは揮発性の高いストレージであり、障害時にはそれまでのデータの状態を失っています。トランザクションログはデータとは別にログとしてデータの更新オペレーションを永続化しており、障害時にはドライブへの同期が未だなされていない処理をログに沿って、漏れなく順序通り実行することで復元しています。
レプリケーションはこの内部構造の応用として、データではなくトランザクションログ自体を利用することによりデータを同期しています。チェスにおける一手一手を順序通り打つことにより盤面の状態を再現するのと理屈としては同じです。
Kafkaとデータ
Kafka Connectはデータソース/シンクとKafkaとを繋げる役割を果たす技術です。特にデータベースをソースを見立てた場合にはクエリではなくトランザクションログをEventとして抽出し、順序通りKafkaに渡す事が可能です。アプローチとしてはデータベースのレプリケーションと同じではありますが、このログを運ぶ基盤としてKafkaという汎用的なモデルである為データベースベンダー特有技術への依存関係がありません。
具体的には、例えば:
- データソース/シンクで異なるデータベースを指定したデータのレプリケーション
- 特定のテーブルに限定したレプリケーション
- 連携データのフィルタリング
- 必要なカラムのみの抽出や加工(マスキング、複数カラムから新規のカラム作成、etc.)
をレプリケーションの途中過程で含む事が出来ます。
これらアプローチはデータ加工に別途中間データを格納するストレージを必要とせず、ストリーム自体に対して処理を行う事が出来ます。 (Stream Processing - ストリーム処理) さらにはストリームに対する集約処理(SUM、COUNT、AVG等)や条件によるグルーピング、特定時間枠 (WINDOW) におけるデータ演算等、さらに複雑な処理を行うことも可能です。
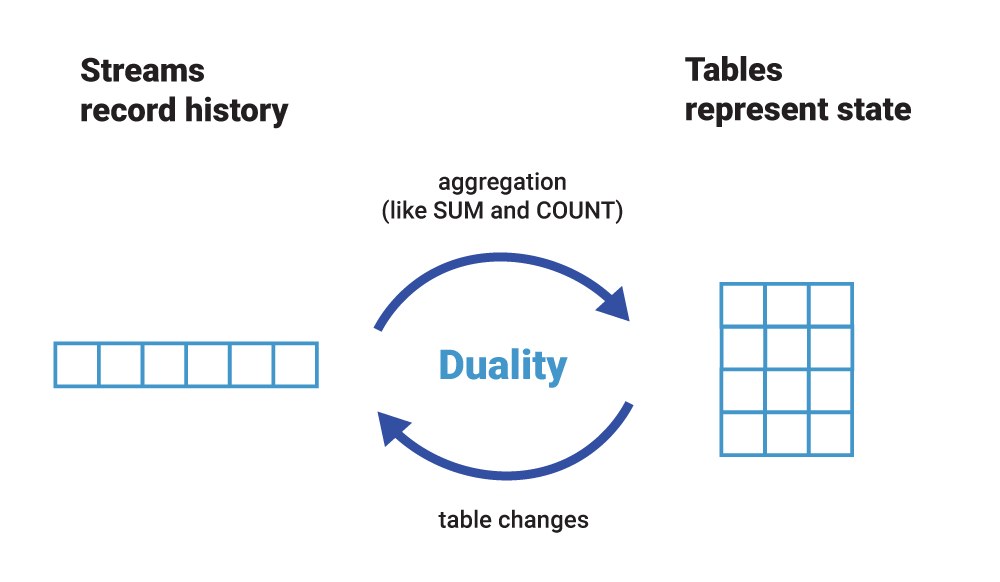
Stream-Table Duality
StreamからTableの状態を再現でき、かつTableの更新情報はStream化できる。StreamとTableは同じデータの異なる側面であるという思想がStream-Table Duality (ストリーム/テーブル双対性) です。Streamはデータの更新推移を記録できる一方、ある特定タイミングでのデータ状況を再現する為には全てのEventを順序通り処理する必要があります。Tableはある特定タイミングにおけるデータ状態を表現しクエリによって柔軟な組み合わせのデータ抽出が可能である一方、データの更新推移を表現する事が出来ません。

Stream、Table、いずれもデータを表現する上では不完全なものであり、求める課題によっては一方では達成が難しかったり、非効率であったりします。Kafkaのエコシステムではこの双方を活用することにより、これまで困難であった課題に対してより柔軟なアプローチを提供しています。StreamからTableへ、TableからStreamへ、StreamとTableのJOINやStream同士のJOIN等、Stream Table Dualityによってデータ処理のアプローチに奥行きを持たせる事が可能です。
おわりに
本エントリではApache Kafkaのデータに対する思想について少し踏み込んでご説明しました。この思想はKafkaが誕生した際にあった構想であり、機能追加や技術の成熟によってエンタープライズで活用出来る領域まで到達する事が出来ました。また、Kafkaに新たな役割をもたらすようになったことにより、さらに機能の改善や成長、そして時間経過と共に古くなった設計やコードを捨てつつ進化を続けています。
Distributed computing Advent Calendar 2021では次回には続きとしてストリーム処理について、そしてその後ではCloud NativeなKafkaの成長についてご紹介します。
おまけ
「ちょっとKafka触ってみようかな?」とお感じになった方は是非フルマネージドのConfluent Cloudをお試しください。インタラクティブチュートリアルやハンズオンデモ等、多くのリソースも合わせてご利用いただけます。
Confluent Cloud
トライアルでは400USDのクレジットが利用できますが、KAFKA101のプロモコードでさらに101USD追加でご利用できます。
developer.confluent.io ではApache Kafka 101を始めとして、ksqlDBやKafka Streams等Kafkaエコシステムにおける様々な技術のチュートリアルシリーズをご用意しております。