こんにちは。株式会社ジールの@Shin-Nakamura224です。
案件で異なるデータベースのテーブルを比較する機会がありましたので、
テーブル比較の効率的な方法について投稿したいと思います。
目次
1.はじめに
-- テーブル比較の効率的な比較方法
2.テーブル比較方法
-- 2-1 テーブル比較の考え方
-- 2-2 テーブル比較の整合性におけるハッシュ値の役割
3.ハッシュ値の取得方法
-- 3-1 ハッシュ関数の作成
-- 3-2 SQLクエリでのハッシュ関数の使用
4.ハッシュ値比較の注意点と課題
-- 異なるデータベースのデータ形式違いとその対策
5.まとめ
1. はじめに
テーブル比較の効率的な比較方法
実例に基づいて、テーブル比較の効率的な比較方法についてご紹介いたします。
【実例】
TeradataとSnowflakeのテーブルを比較
※データは11種類のデータ型を網羅したテストデータを使用しております。
・比較するテーブル(11種類のデータ型を持つテーブル)
Teradata

Snowflake

・テーブル比較実行
テーブル比較は、テーブル件数とテーブルのハッシュ値(テーブル全レコードのハッシュ値の合計)を
取得して比較します。
【Teradata】
件数取得

ハッシュ値取得

【Snowflake】
件数取得

ハッシュ値取得

上記で取得したデータ件数とハッシュ値を比較することで、データが一致していることが確認できます。
2.テーブル比較方法
2-1. テーブル比較の考え方
どうやってテーブル比較を行っているのか考え方を説明いたします。
今回は「データ件数」と「データハッシュ値」の2つを比較することで、
テーブル比較を行っています。
「データ件数」
こちらは想像しやすいと思います。
比較対象テーブルのレコード件数を取得して比較することで、
テーブルに入っているデータ数が一致するのかを確認することができます。
しかしこれだけでは、テーブルのレコード数だけが一致しているだけで、
データの中身が一緒であることを担保することができません。(テーブル比較の整合性が取れない)
「データハッシュ値」
そこで今回は、テーブルデータのハッシュ値を取得して比較することで、
テーブル比較の整合性を担保することにしました。
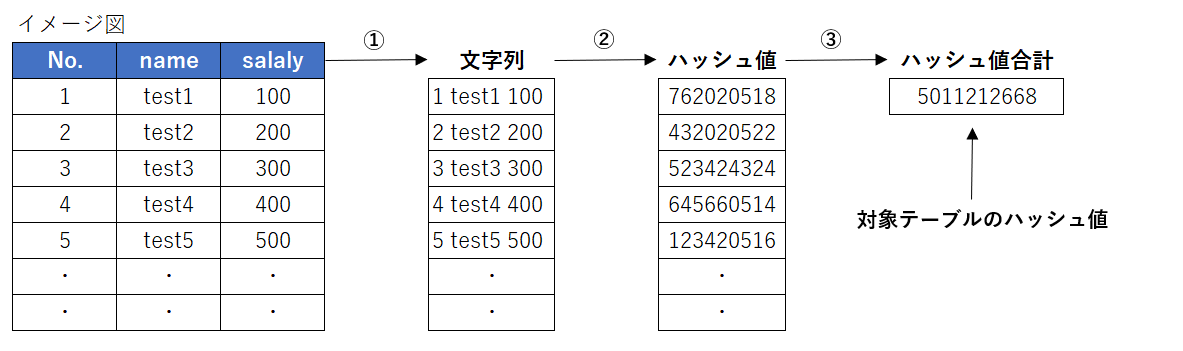
テーブルハッシュ値取得の流れは、下記の通りになります。
①. テーブルレコード毎にデータを1つの文字列として連結
②. 「①」で取得した文字列を引数として、レコード毎にハッシュ関数を実行
③. 「②」で取得したハッシュ値を合計して、テーブル全レコードのハッシュ値の合計値を取得
2-2. テーブル比較の整合性におけるハッシュ値の役割
参考程度に、今回テーブル比較の整合性を担保するのにハッシュ値を採用した理由を説明いたします。
簡潔にまとめると下記の利点からハッシュ値を採用しました。
【高速な比較が可能】
ハッシュ値は固定長の値で表され、大量のデータを迅速に比較できます。
【整合性の検出が容易】
ハッシュ値の比較によってテーブル間の差異を素早く検出し、データの整合性を確保できます。
【データの完全性を保証】
ハッシュ値はデータの一意の識別子であり、データの改ざんや欠落を検出するため、
データの完全性を保証します。(完全に衝突は避けられないが限りなく低い確率)
【リソースを効率的に利用】
ハッシュ値の計算はリソースを比較的少なく使用し、
テーブル比較の処理を効率的に行うことができます。
【機密情報の保護が可能】
ハッシュ値は逆算が困難であり、機密情報の漏洩を防ぎます。
参考 ↓
3.ハッシュ値の取得方法
ハッシュ値を取得するためには、ハッシュ関数を使用してデータからハッシュ値を取得します。
3-1. ハッシュ関数の作成
ハッシュ関数の作成方法について、説明いたします。
今回はTeradataとSnowflakeのデータを比較するために、ハッシュ値を取得する必要があったのですが、
デフォルト機能では共通するハッシュ値を取得するハッシュ関数がありませんでした。
| ハッシュ関数 | Snowflake | Teradata |
|---|---|---|
| MD5 | ○ | × |
| SHA-1 | ○ | × |
| SHA-2 | ○ | × |
| SHA-256 | × | × |
参考↓
そのため、TeradataではMD5ハッシュ関数(UDF)を作成、
Snowflakeではデフォルト機能のMD5関数を使用してハッシュ値を取得・比較することにしました。
Teradata MD5ハッシュ関数(UDF)作成
Teradataの公式ページからMD5ハッシュ関数UDF(C言語)がダウンロードできます。
今回はそのまま使用するのではなく、下記のように修正したものを使用しました。
・デフォルトでは、ハッシュ値を文字列として返すのでSUMすることができないため、
数値として返却させる
・Teradataリソース節約のためにハッシュ値の上位4バイトのみを取得する
※修正したファイルを所定の場所に設置後、関数を使用したいユーザに接続して
「.run file = hash_md5_high4bytes.btq」を実行すると関数が作成されます。
修正後のファイル ↓
【hash_md5_high4bytes.btq】
ファイルの中身を表示
/* script to install the UDF */
replace function hash_md5_high4bytes
(arg varchar(32000) character set unicode, arg2 integer)
returns bigint
language c
no sql
external name 'ci:md5:md5.h:cs:md5:md5.c:cs:md5_latin:udf_md5_high4bytes_latin.c:F:md5_high4bytes_latin'
parameter style td_general;
【md5.c】
ファイルの中身を表示
/* Copyright (c) 2008 by Teradata Corporation. All Rights Reserved. */
/*
* The md5 function implements the MD5 message-digest algorithm.
* The algorithm takes as input a message of arbitrary length and produces
* as output a 128-bit "fingerprint" or "message digest" of the input. The
* MD5 algorithm is intended for digital signature applications, where a
* large file must be "compressed" in a secure manner before being
* encrypted with a private (secret) key under a public-key cryptosystem
* such as RSA.
*/
#include <stdlib.h>
#include <string.h>
#define SQL_TEXT Latin_Text
#include "sqltypes_td.h"
#include "md5.h"
#define R1(a, b, c, d, xk, s, ti) (b + LROT((a + F(b, c, d) + xk + ti), s))
#define R2(a, b, c, d, xk, s, ti) (b + LROT((a + G(b, c, d) + xk + ti), s))
#define R3(a, b, c, d, xk, s, ti) (b + LROT((a + H(b, c, d) + xk + ti), s))
#define R4(a, b, c, d, xk, s, ti) (b + LROT((a + I(b, c, d) + xk + ti), s))
#define LROT(x, s) ((x << s) | (x >> (32 - s)))
#define F(X, Y, Z) ((X) & (Y) | (~X) & (Z))
#define G(X, Y, Z) (((X) & (Z)) | ((Y) & (~Z)))
#define H(X, Y, Z) ((X) ^ (Y) ^ (Z))
#define I(X, Y, Z) ((Y) ^ ((X) | (~Z)))
/* initial value for MD register */
#define A0 0x67452301
#define B0 0xefcdab89
#define C0 0x98badcfe
#define D0 0x10325476
#define BLOCK_SIZE 64
#define FINAL_BLOCK_SIZE (BLOCK_SIZE - 8)
static void md5_block(unsigned int register[], const unsigned int blk[]);
static unsigned int T[64] = {
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x2441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x4881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391
};
void md5(const unsigned char message[], int len, unsigned char result[])
{
int pos = 0;
int padded = 0;
int remain = 0;
unsigned int la[2];
const unsigned char pad = 1 << 7; /* first byte of padding */
unsigned int X[BLOCK_SIZE / sizeof(int)]; /* 512 bit block = 32 bit * 16 */
unsigned char buf[BLOCK_SIZE]; /* for final and final-1 block */
unsigned int r[4] = {A0, B0, C0, D0}; /* MD register */
memset(buf, 0, sizeof(buf));
/* Process Message in 16-word Blocks */
while (len - pos >= BLOCK_SIZE) {
memcpy(X, &message[pos], sizeof(X));
md5_block(r, X);
pos += BLOCK_SIZE;
}
remain = len - pos;
if (remain > 0) {
memcpy(buf, &message[pos], remain);
}
#if !defined(UDF_MD5_COMPAT) || ((UDF_MD5_COMPAT) == 0)
if (remain > FINAL_BLOCK_SIZE - 1) {
#else
if (remain > FINAL_BLOCK_SIZE) {
#endif
/* carry block: cannot put length field in final block */
buf[remain] = pad;
memcpy(X, buf, sizeof(buf));
md5_block(r, X);
padded = 1;
memset(buf, 0, sizeof(buf));
}
/* Step 1: Append Padding Bits */
if (!padded)
buf[remain] = pad;
/* Step 2: Append Length */
la[0] = len << 3; /* byte to bit */
la[1] = 0; /* assuming length < 4Gb */
/* run final block */
memcpy(buf + FINAL_BLOCK_SIZE, la, sizeof(la));
memcpy(X, buf, sizeof(buf));
md5_block(r, X);
memcpy(result, r, sizeof(int) * 4);
/* clear digester to maintain security */
memset(r, 0, sizeof(r));
}
static void md5_block(unsigned int r[], const unsigned int blk[])
{
unsigned int a = r[0];
unsigned int b = r[1];
unsigned int c = r[2];
unsigned int d = r[3];
#ifdef DEBUG
int i;
printf("md5_block <");
for (i = 0; i < 16; ++i) {
printf(" %x", blk[i]);
}
printf("\n");
printf("a, b, c, d = %x %x %x %x\n", a, b, c, d);
#endif
a = R1(a, b, c, d, blk[0], 7, T[0]);
d = R1(d, a, b, c, blk[1], 12, T[1]);
c = R1(c, d, a, b, blk[2], 17, T[2]);
b = R1(b, c, d, a, blk[3], 22, T[3]);
a = R1(a, b, c, d, blk[4], 7, T[4]);
d = R1(d, a, b, c, blk[5], 12, T[5]);
c = R1(c, d, a, b, blk[6], 17, T[6]);
b = R1(b, c, d, a, blk[7], 22, T[7]);
a = R1(a, b, c, d, blk[8], 7, T[8]);
d = R1(d, a, b, c, blk[9], 12, T[9]);
c = R1(c, d, a, b, blk[10], 17, T[10]);
b = R1(b, c, d, a, blk[11], 22, T[11]);
a = R1(a, b, c, d, blk[12], 7, T[12]);
d = R1(d, a, b, c, blk[13], 12, T[13]);
c = R1(c, d, a, b, blk[14], 17, T[14]);
b = R1(b, c, d, a, blk[15], 22, T[15]);
#ifdef DEBUG
printf("round 1: %x %x %x %x\n", a, b, c, d);
#endif
a = R2(a, b, c, d, blk[1], 5, T[16]);
d = R2(d, a, b, c, blk[6], 9, T[17]);
c = R2(c, d, a, b, blk[11], 14, T[18]);
b = R2(b, c, d, a, blk[0], 20, T[19]);
a = R2(a, b, c, d, blk[5], 5, T[20]);
d = R2(d, a, b, c, blk[10], 9, T[21]);
c = R2(c, d, a, b, blk[15], 14, T[22]);
b = R2(b, c, d, a, blk[4], 20, T[23]);
a = R2(a, b, c, d, blk[9], 5, T[24]);
d = R2(d, a, b, c, blk[14], 9, T[25]);
c = R2(c, d, a, b, blk[3], 14, T[26]);
b = R2(b, c, d, a, blk[8], 20, T[27]);
a = R2(a, b, c, d, blk[13], 5, T[28]);
d = R2(d, a, b, c, blk[2], 9, T[29]);
c = R2(c, d, a, b, blk[7], 14, T[30]);
b = R2(b, c, d, a, blk[12], 20, T[31]);
#ifdef DEBUG
printf("round 2: %x %x %x %x\n", a, b, c, d);
#endif
a = R3(a, b, c, d, blk[5], 4, T[32]);
d = R3(d, a, b, c, blk[8], 11, T[33]);
c = R3(c, d, a, b, blk[11], 16, T[34]);
b = R3(b, c, d, a, blk[14], 23, T[35]);
a = R3(a, b, c, d, blk[1], 4, T[36]);
d = R3(d, a, b, c, blk[4], 11, T[37]);
c = R3(c, d, a, b, blk[7], 16, T[38]);
b = R3(b, c, d, a, blk[10], 23, T[39]);
a = R3(a, b, c, d, blk[13], 4, T[40]);
d = R3(d, a, b, c, blk[0], 11, T[41]);
c = R3(c, d, a, b, blk[3], 16, T[42]);
b = R3(b, c, d, a, blk[6], 23, T[43]);
a = R3(a, b, c, d, blk[9], 4, T[44]);
d = R3(d, a, b, c, blk[12], 11, T[45]);
c = R3(c, d, a, b, blk[15], 16, T[46]);
b = R3(b, c, d, a, blk[2], 23, T[47]);
#ifdef DEBUG
printf("round 3: %x %x %x %x\n", a, b, c, d);
#endif
a = R4(a, b, c, d, blk[0], 6, T[48]);
d = R4(d, a, b, c, blk[7], 10, T[49]);
c = R4(c, d, a, b, blk[14], 15, T[50]);
b = R4(b, c, d, a, blk[5], 21, T[51]);
a = R4(a, b, c, d, blk[12], 6, T[52]);
d = R4(d, a, b, c, blk[3], 10, T[53]);
c = R4(c, d, a, b, blk[10], 15, T[54]);
b = R4(b, c, d, a, blk[1], 21, T[55]);
a = R4(a, b, c, d, blk[8], 6, T[56]);
d = R4(d, a, b, c, blk[15], 10, T[57]);
c = R4(c, d, a, b, blk[6], 15, T[58]);
b = R4(b, c, d, a, blk[13], 21, T[59]);
a = R4(a, b, c, d, blk[4], 6, T[60]);
d = R4(d, a, b, c, blk[11], 10, T[61]);
c = R4(c, d, a, b, blk[2], 15, T[62]);
b = R4(b, c, d, a, blk[9], 21, T[63]);
#ifdef DEBUG
printf("round 4: %x %x %x %x\n", a, b, c, d);
#endif
r[0] += a;
r[1] += b;
r[2] += c;
r[3] += d;
#ifdef DEBUG
printf("md5_block > : %x %x %x %x\n", digester->r[0], digester->r[1],
digester->r[2], digester->r[3]);
#endif
}
【md5.d】
ファイルの中身を表示
/* Copyright (c) 2008 by Teradata Corporation. All Rights Reserved. */
#ifndef MD5_H
#define MD5_H
/* generate MD5 result in upper case */
#define UDF_MD5_UPPERCASE 1
/* generate same result as previous releases
* not correct if the length of the input is 56 + 64*N (N>= 0) bytes
*/
#define UDF_MD5_COMPAT 0
void md5(const unsigned char message[], int len, unsigned char result[]);
#endif
【udf_md5_high4bytes_latin.c】
ファイルの中身を表示
/* Copyright (c) 2008 by Teradata Corporation. All Rights Reserved. */
/*
* The md5 function implements the MD5 message-digest algorithm.
* The algorithm takes as input a message of arbitrary length and produces
* as output a 128-bit "fingerprint" or "message digest" of the input. The
* MD5 algorithm is intended for digital signature applications, where a
* large file must be "compressed" in a secure manner before being
* encrypted with a private (secret) key under a public-key cryptosystem
* such as RSA.
*
*
*/
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#define SQL_TEXT Latin_Text
#include "sqltypes_td.h"
#include "md5.h"
#define UDF_OK "00000"
void md5_high4bytes_latin(VARCHAR_UNICODE *message,
INTEGER *len,
BIGINT *digest,
char sqlstate[])
{
int i;
unsigned char outbuf[16];
//CHARACTER_LATIN *ptr;
md5((unsigned char *) message, *len * 2, outbuf);
// high 4 byte
*digest = outbuf[0];
*digest = *digest << 8;
*digest += outbuf[1];
*digest = *digest << 8;
*digest += outbuf[2];
*digest = *digest << 8;
*digest += outbuf[3];
(void) sprintf(sqlstate, UDF_OK);
}
Snowflake 「UTF-16 Little Endian」形式変換関数作成
Snowflakeで提供されているMD5関数はバイナリデータに対して適用されるため、
テキストデータ(文字列)を直接処理することはできません。
そのため、MD5ハッシュを計算する前に、文字列をバイナリ形式に変換する必要があります。
つまり、結合した文字列をUTF-16 Little Endian形式に変換するための関数を作成する必要があります。
※関数を作成したいスキーマ上で下記のクエリを実行すると関数が作成されます。
作成した「関数作成」クエリ ↓
クエリを表示
create or replace function convert_to_utf16le( str VARCHAR )
returns binary
language javascript
AS
$$
var utf16BEString = STR;
const utf16BEBytes = new Uint8Array(utf16BEString.length * 2);
for (let i = 0; i < utf16BEString.length; i++) {
const charCode = utf16BEString.charCodeAt(i);
utf16BEBytes[i * 2] = charCode & 0xFF;
utf16BEBytes[i * 2 + 1] = charCode >>> 8;
}
return utf16BEBytes;
$$;
3-2. SQLクエリでのハッシュ関数の使用
章3-1で作成した関数をクエリに追加して、
使用することで対象テーブルのハッシュ値を取得することができます。
下記は実際に関数をクエリに追加したものの例になります。
【Teradata】
クエリを表示
-- DBTT.TABLE1
select sum(hash_md5_high4bytes(tmp.hashvalue,character_length(tmp.hashvalue))) sum_hashvalue
from (
select (trim(
trim(coalesce(rtrim("char_column") || '', '<NV>'))||
trim(coalesce("varchar_column" || '', '<NV>'))||
trim(coalesce("byteint_column" || '', '<NV>'))||
trim(coalesce("smallint_column" || '', '<NV>'))||
trim(coalesce("integer_column" || '', '<NV>'))||
trim(coalesce("bigint_column" || '', '<NV>'))||
trim(rtrim(coalesce("decimal_column" || '', '<NV>'), '.'))||
trim(coalesce(cast(("float_column" (format '-9.999999999999999E-999')) as varchar(23)), '<NV>'))||
trim(coalesce(cast(("date_column" (format 'YYYY-MM-DD')) as varchar(10)), '<NV>'))||
trim(coalesce(cast(("time_column" (format 'HH-MI-SS')) as varchar(8)), '<NV>'))||
trim(coalesce(cast(("timestamp_column" (format 'HH-MI-SSDS(F)')) as varchar(15)), '<NV>'))||
'')) as hashvalue
from DBTT.TABLE1
) tmp;
【Snowflake】
※Teradata側とビット数を合わせるために、bitshiftright()関数を使用して、
取得したハッシュ値64ビットの内、下位32ビットを切り捨てて上位32ビットのみを抽出しています。
クエリを表示
-- DBTT.TABLE1
select sum(bitshiftright(md5_number_upper64(convert_to_utf16le(tmp.hashvalue)), 32)) sum_hashvalue
from (
select(
trim(coalesce("CHAR_COLUMN" || '', '<NV>'))||
trim(coalesce("VARCHAR_COLUMN" || '', '<NV>'))||
regexp_replace(regexp_replace(coalesce("BYTEINT_COLUMN" || '', '<NV>'), '^0.', '.'), '^-0.', '-.')||
regexp_replace(regexp_replace(coalesce("SMALLINT_COLUMN" || '', '<NV>'), '^0.', '.'), '^-0.', '-.')||
regexp_replace(regexp_replace(coalesce("INTEGER_COLUMN" || '', '<NV>'), '^0.', '.'), '^-0.', '-.')||
regexp_replace(regexp_replace(coalesce("BIGINT_COLUMN" || '', '<NV>'), '^0.', '.'), '^-0.', '-.')||
regexp_replace(regexp_replace(coalesce("DECIMAL_COLUMN" || '', '<NV>'), '^0.', '.'), '^-0.', '-.')||
coalesce(regexp_replace(to_varchar("FLOAT_COLUMN"::float, 'FM9.000000000000000EEEEE'), '\\+', ' '), '<NV>')||
coalesce(to_varchar("DATE_COLUMN"::date, 'YYYY-MM-DD'), '<NV>')||
coalesce(to_varchar("TIME_COLUMN"::time, 'HH-MI-SS'), '<NV>')||
coalesce(to_varchar("TIMESTAMP_COLUMN"::timestamp, 'HH-MI-SS.FF6'), '<NV>')||
'') as hashvalue
from DBTT.TABLE1
) tmp;
4. ハッシュ値比較の注意点と課題
この章ではハッシュ関数の引数となる文字列(1レコードを連結したもの)の作成方法と
その際の注意点について説明いたします。(上記クエリの「hash_value」の部分です)
異なるデータベースのデータ形式違いとその対策
対象テーブルのレコード毎にデータを連結する基本的な方法は下記の通りになります。
select (
column1 || column2 || column3 || ・・・ || columnN
)
from SCHEMA_NAME.TABLE_NAME;
しかし、これだけでは異なるデータベースのデータ形式違いが考慮されていません。
TeradataとSnowflakeでは同じデータでもデータ形式が異なるため、
そのままハッシュ値を取得しても比較結果が一致することはありません。
そのため、データ型毎にどんな形式・仕様の違いがあるのか洗い出して、
TeradataとSnowflakeで同じデータ形式になるようにクエリで修正する必要があります。
(今回の記事の一番の肝となる部分です。)
洗い出した形式・仕様違い一覧は下記の通りになります。
【Teradata】

【Snowflake】

洗い出した形式・仕様違いと章3の内容を織り込み、
TeradataとSnowflakeデータ形式を合わせるクエリを作成しました。
【Teradata】
カラム情報:DBC.ColumnsV
order by:ColumnId
※データを絞り込みたい場合は、where句部分を修正してください。
クエリを表示
select '-- :DB_NAME.:TABLE_NAME' (TITLE'');
select 'select sum(hash_md5_high4bytes(tmp.hashvalue,character_length(tmp.hashvalue))) sum_hashvalue' (TITLE'');
select 'from (' (TITLE'');
select ' select (trim(' (TITLE'');
select
case when Nullable = 'Y' then
case ColumnType
when 'CF' then ' trim(coalesce(rtrim("' || trim(ColumnName) || '") || '''', ''<NV>''))||' -- CHAR
when 'CV' then ' trim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''))||' -- VARCHAR
when 'I1' then ' trim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''))||' -- BYTEINT
when 'I2' then ' trim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''))||' -- SMALLINT
when 'I' then ' trim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''))||' -- INTEGER
when 'I8' then ' trim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''))||' -- BIGINT
when 'D' then ' trim(rtrim(coalesce("' || trim(ColumnName) || '" || '''', ''<NV>''), ''.''))||' -- DECIMAL
when 'F' then ' trim(coalesce(cast(("' || trim(ColumnName) || '" (format ''-9.999999999999999E-999'')) as varchar(23)), ''<NV>''))||' -- FLOAT
when 'DA' then ' trim(coalesce(cast(("' || trim(ColumnName) || '" (format ''YYYY-MM-DD'')) as varchar(10)), ''<NV>''))||' -- DATE
when 'AT' then ' trim(coalesce(cast(("' || trim(ColumnName) || '" (format ''HH-MI-SS'')) as varchar(8)), ''<NV>''))||' -- TIME
when 'TS' then ' trim(coalesce(cast(("' || trim(ColumnName) || '" (format ''HH-MI-SSDS(F)'')) as varchar(15)), ''<NV>''))||' -- TIMESTAMP
else ' ''' || trim(ColumnName) || ':' || trim(ColumnType) || ' is not defined.' || '''||'
end
else
case ColumnType
when 'CF' then ' rtrim("' || trim(ColumnName) || '") || ''''||' -- CHAR
when 'CV' then ' "' || trim(ColumnName) || '" || ''''||' -- VARCHAR
when 'I1' then ' "' || trim(ColumnName) || '" || ''''||' -- BYTEINT
when 'I2' then ' "' || trim(ColumnName) || '" || ''''||' -- SMALLINT
when 'I' then ' "' || trim(ColumnName) || '" || ''''||' -- INTEGER
when 'I8' then ' "' || trim(ColumnName) || '" || ''''||' -- BIGINT
when 'D' then ' trim(rtrim("'|| trim(ColumnName) || '" || '''', ''.''))||' -- DECIMAL
when 'F' then ' cast(("' || trim(ColumnName) || '" (format ''-9.999999999999999E-999'')) as varchar(23))||' -- FLOAT
when 'DA' then ' cast(("' || trim(ColumnName) || '" (format ''YYYY-MM-DD'')) as varchar(10))||' -- DATE
when 'AT' then ' cast(("' || trim(ColumnName) || '" (format ''HH-MI-SS'')) as varchar(8))||' -- TIME
when 'TS' then ' cast(("' || trim(ColumnName) || '" (format ''HH-MI-SSDS(F)'')) as varchar(15))||' -- TIMESTAMP
else ' ''' || trim(ColumnName) || ':' || trim(ColumnType) || ' is not defined.' || '''||'
end
end (TITLE '')
from DBC.ColumnsV
where DatabaseName = ':DB_NAME'
and TableName = ':TABLE_NAME'
-- and ColumnType <> 'TS'
order by ColumnId;
select ' '''')) as hashvalue' (TITLE'');
select ' from :DB_NAME.:TABLE_NAME' (TITLE'');
--select ' where :COND' (TITLE'');
select ' ) tmp;' (TITLE'');
select '' (TITLE'');
【Snowflake】
カラム情報:information_schema.columns
order by:ORDINAL_POSITION
※データを絞り込みたい場合は、where句部分を修正してください。
クエリを表示
select '-- :DB_NAME.:TABLE_NAME';
select 'select sum(bitshiftright(md5_number_upper64(convert_to_utf16le(tmp.hashvalue)), 32)) sum_hashvalue';
select ' from (';
select ' select(';
select
case when IS_NULLABLE = 'YES' then
case DATA_TYPE
when 'TEXT' then ' trim(coalesce("' || trim(COLUMN_NAME) || '" || '''', ''<NV>''))||' -- CHAR
when 'VARCHAR' then ' trim(coalesce("' || trim(COLUMN_NAME) || '" || '''', ''<NV>''))||' -- VARCHAR
when 'NUMBER' then ' regexp_replace(regexp_replace(coalesce("'|| trim(COLUMN_NAME) || '" || '''', ''<NV>''), ''^0.'', ''.''), ''^-0.'', ''-.'')||' -- NUMBER,SMALLINT,INTEGER,BIGINT,DECIMAL
when 'FLOAT' then ' coalesce(regexp_replace(to_varchar("' || trim(COLUMN_NAME) || '"::float, ''FM9.000000000000000EEEEE''), ''\\\\+'', '' ''), ''<NV>'')||' -- FLOAT
when 'DATE' then ' coalesce(to_varchar("' || trim(COLUMN_NAME) || '"::date, ''YYYY-MM-DD''), ''<NV>'')||' -- DATE
when 'TIME' then ' coalesce(to_varchar("' || trim(COLUMN_NAME) || '"::time, ''HH-MI-SS''), ''<NV>'')||' -- TIME
when 'TIMESTAMP_NTZ' then ' coalesce(to_varchar("' || trim(COLUMN_NAME) || '"::timestamp, ''HH-MI-SS.FF6''), ''<NV>'')||' -- TIMESTAMP
else ' ''' || trim(COLUMN_NAME) || ':' || trim(DATA_TYPE) || ' is not defined.' || '''||'
end
else
case DATA_TYPE
when 'TEXT' then ' "' || trim(COLUMN_NAME) || '" || ''''||' -- CHAR
when 'VARCHAR' then ' "' || trim(COLUMN_NAME) || '" || ''''||' -- VARCHAR
when 'NUMBER' then ' regexp_replace(regexp_replace("'|| trim(COLUMN_NAME) || '", ''^0.'', ''.''), ''^-0.'', ''-.'')||' -- NUMBER,SMALLINT,INTEGER,BIGINT,DECIMAL
when 'FLOAT' then ' regexp_replace(to_varchar("' || trim(COLUMN_NAME) || '"::float, ''FM9.000000000000000EEEEE''), ''\\\\+'', '' '')||' -- FLOAT
when 'DATE' then ' to_varchar("' || trim(COLUMN_NAME) || '"::date, ''YYYY-MM-DD'')||' -- DATE
when 'TIME' then ' to_varchar("' || trim(COLUMN_NAME) || '"::time, ''HH-MI-SS'')||' -- TIME
when 'TIMESTAMP_NTZ' then ' to_varchar("' || trim(COLUMN_NAME) || '"::timestamp, ''HH-MI-SS.FF6'')||' -- TIMESTAMP
else ' ''' || trim(COLUMN_NAME) || ':' || trim(DATA_TYPE) || ' is not defined.' || '''||'
end
end
from information_schema.columns
where TABLE_SCHEMA = ':DB_NAME'
and TABLE_NAME = ':TABLE_NAME'
-- and ColumnType <> 'TS'
order by ORDINAL_POSITION
;
select ' '''') as hashvalue';
select ' from :DB_NAME.:TABLE_NAME';
--select ' where :COND';
select ' ) tmp;';
select '';
5. まとめ
今回はTeradataとSnowflakeのテーブル比較の効率的な方法ということで、
ハッシュ値を用いたデータ比較について紹介させて頂きました。
ポイントは、下記の通りになります。
・ハッシュ関数(UDF)を作成する必要がある
・TeradataとSnowflakeのデータ形式違いを一致させる必要がある
TeradataとSnowflakeの仕様等様々な要素が絡んでいたので、とても勉強になりました。
この記事が少しでも皆様のお役に立てれば幸いです。