はじめに
こんにちは。株式会社ジールの@Shin-Nakamura224です。
先日(2023/1/30)、AWS Glue Studio のビジュアルETLに5つの新しい変換が追加されることが
発表されたので、紹介していきたいと思います。
またFlattenについては使用例も紹介したいと思います。
概要
追加されたのは、下記5つのTransformになります。
Add identifier、Add UUID、Flatten、To timestamp、Format timestamp
・Add identifier
データセットの各行に対して、数値識別子(連番) を割り当てます。
・Add UUID
データセットの各行に対して、36文字の一意な文字列を割り当てます。
・Flatten
データ内の入れ子構造体のフィールドを平坦化し、トップレベルのフィールドに変換します。
新しいフィールドは、それに到達する構造体フィールドの名前を前に付けたフィールド名を使用して、
ドットで区切られた名前が付けられます。
{"items": { "item_id": 1, "item_name": "test"}}
→ {"items.item_id":1,"items.item_name": "items.test"}
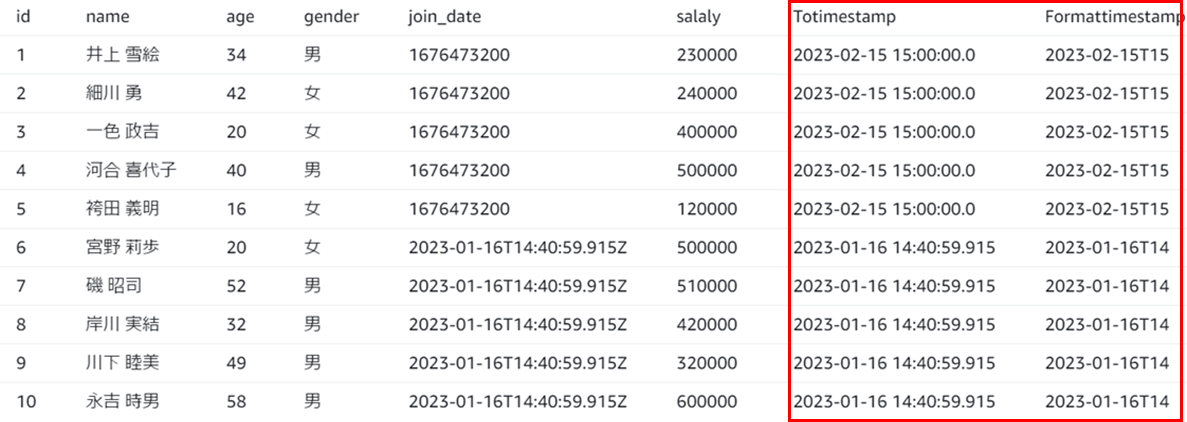
・To timestamp
数値または文字列列のデータ型をタイムスタンプ型に変更して、保存することができます。
(※タイムゾーンの指定はできません)
・Format timestamp
Timestamp型のデータを文字列に変更して、保存することができます。
文字列の形式は、Sparkの日付構文やPythonの日付コード(全てではない)を使用して、
定義することができます。
2023-02-15 15:00:00:00.0
→ 2023-02-15T15
↓ Sparkの日付構文、Pythonの日付コード
処理可能なデータソースの形式(Glue Stadio)
・JSON
・CSV
・Parquet
・Apache Hudi
・Delta Lake
実践
追加された各Transformを試していきます。
Add identifier
1.テストデータ(csv)をS3に準備します。
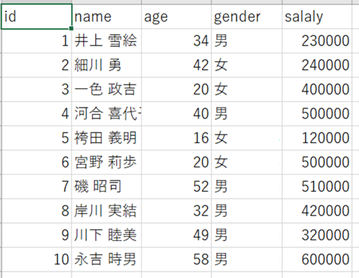
2.ジョブを作成して、Transformノードを追加します。
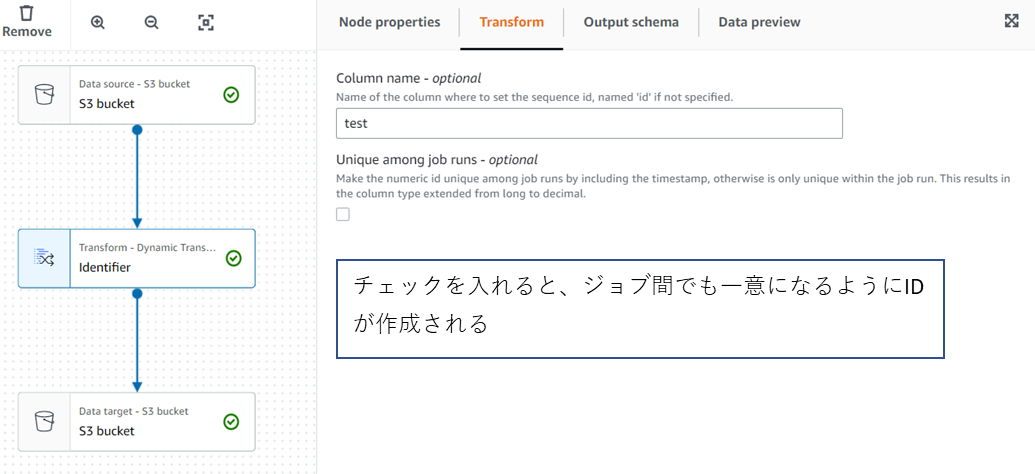
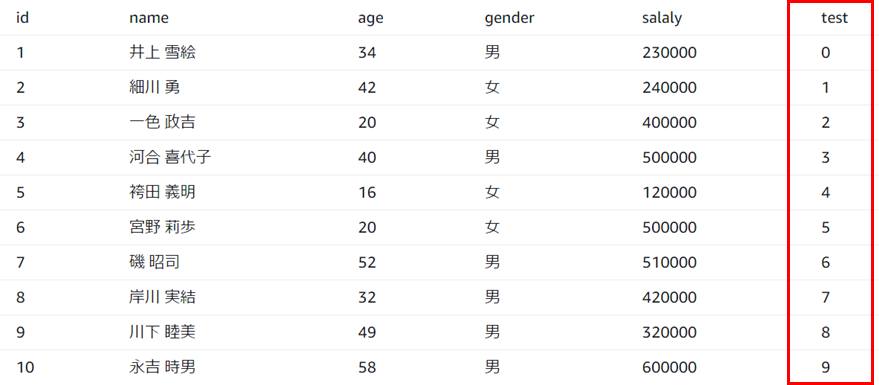
3.実行結果
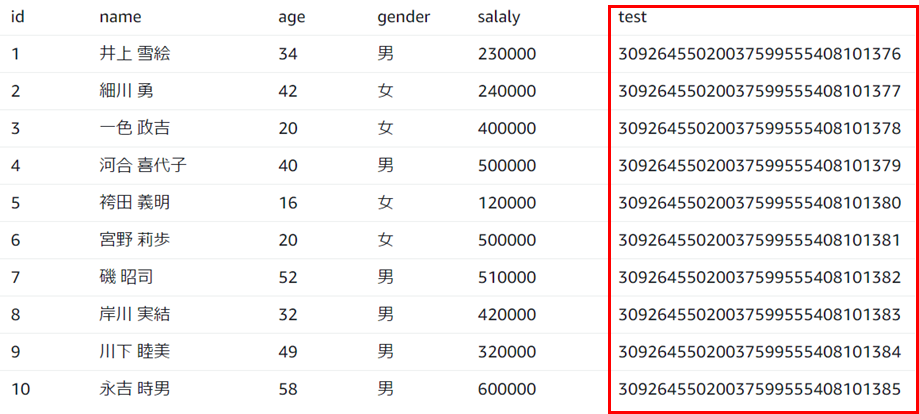
チェックを入れた場合
Add UUID
1.テストデータ(csv)をS3に準備します。
2.ジョブを作成して、Transformノードを追加します。
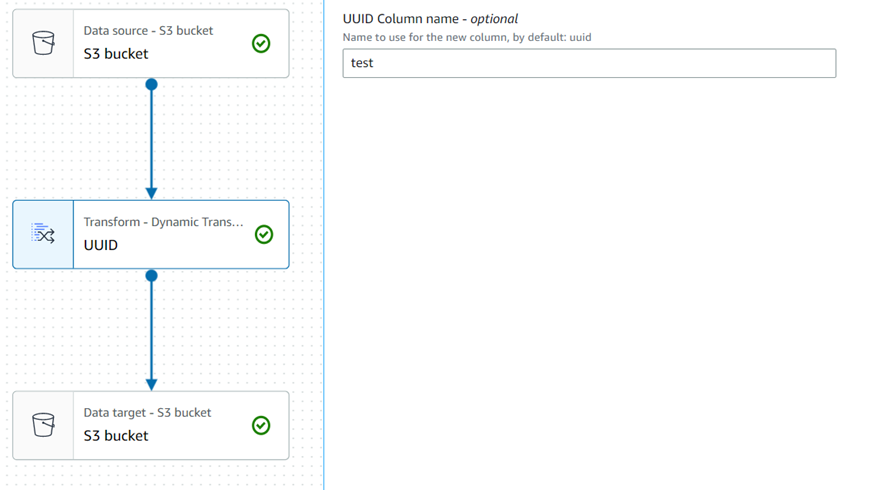
3.実行結果
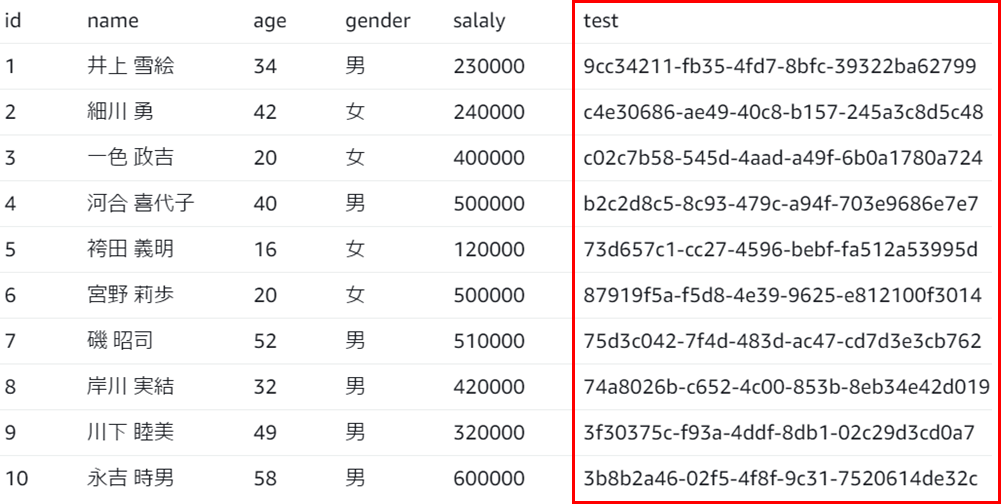
Flatten
1.テストデータ(json)をS3に準備します。

2.ジョブを作成して、Transformノードを追加します。
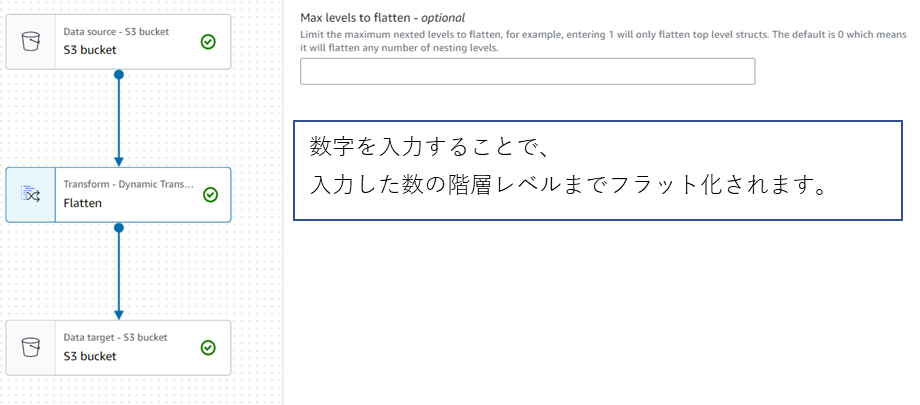
3.実行結果

上記設定で1を入力した場合

To timestamp,Format timestamp
1.テストデータ(csv)をS3に準備します。
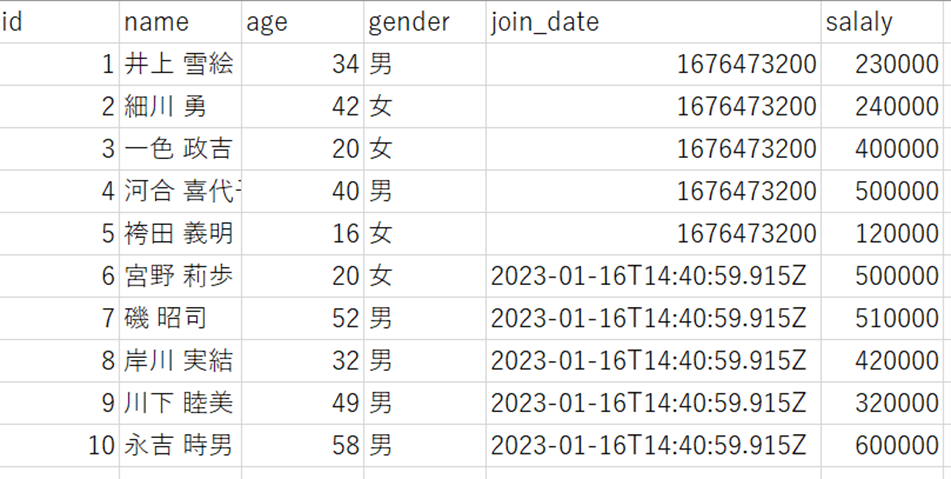
2.ジョブを作成して、Transformノードを追加します。
To timestamp

Format Timestamp
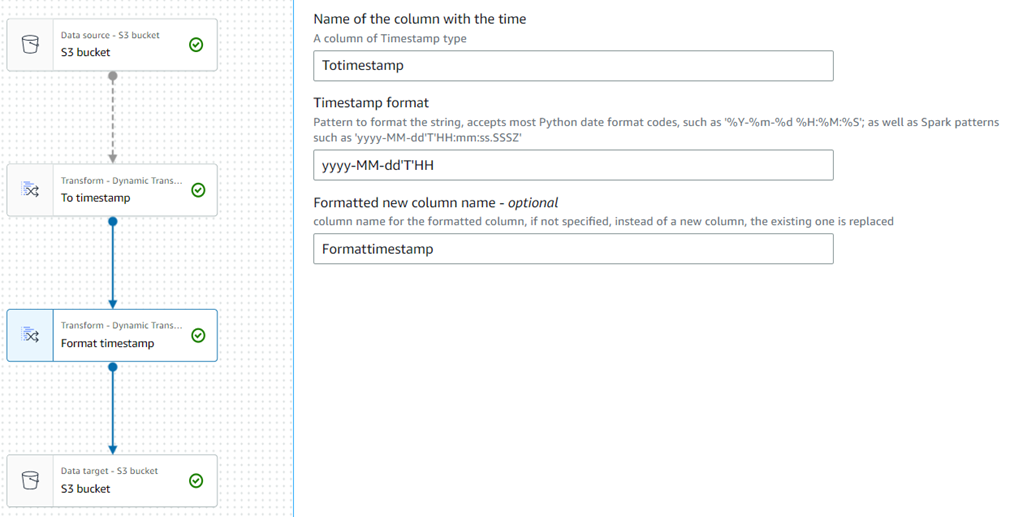
3.実行結果
flattenの使用例
簡単にflattenの使用例を紹介したいと思います。
使用例は、以下の内容になります。
・Glue Stadio上でネストされているソースデータ(半構造化データのJSONファイル)を
フラット化して、Redshiftの構造化データに挿入
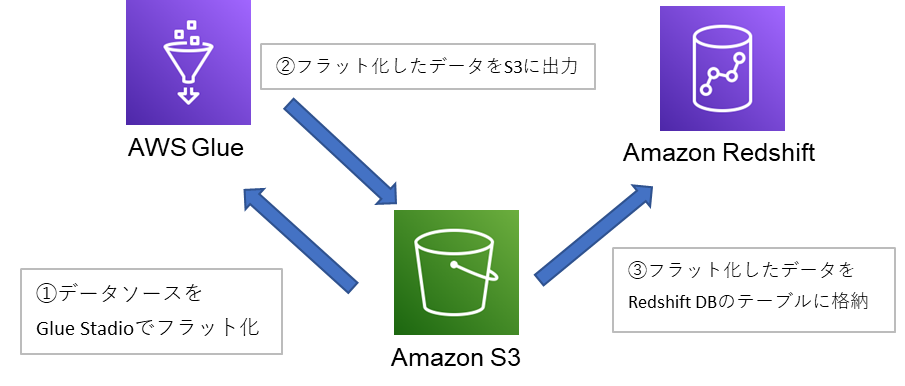
今回は非構造化データ(JSONファイル)をRedshift DBのテーブル(構造化データ)に挿入するために、
RedshiftのCOPYコマンド(RedshiftDBのテーブルに外部データをコピーする)を実行します。
実行するためには、元データとテーブルのカラム名を一致させる必要があるため、
データソース(ネストされているJSONファイル)にカラム名となるキーを準備する必要があるので、
Glue上でフラット化しました。
①②の手順については、
手順は上記のFlattenと同じなので、省略します。(ソースデータは上記のものと同じ)
元データ
フラット化されたデータ
③フラット化したデータをRedshift DBのテーブルに格納
(本記事の内容から逸脱するため、Redshift等の設定は省略させて頂きます。)
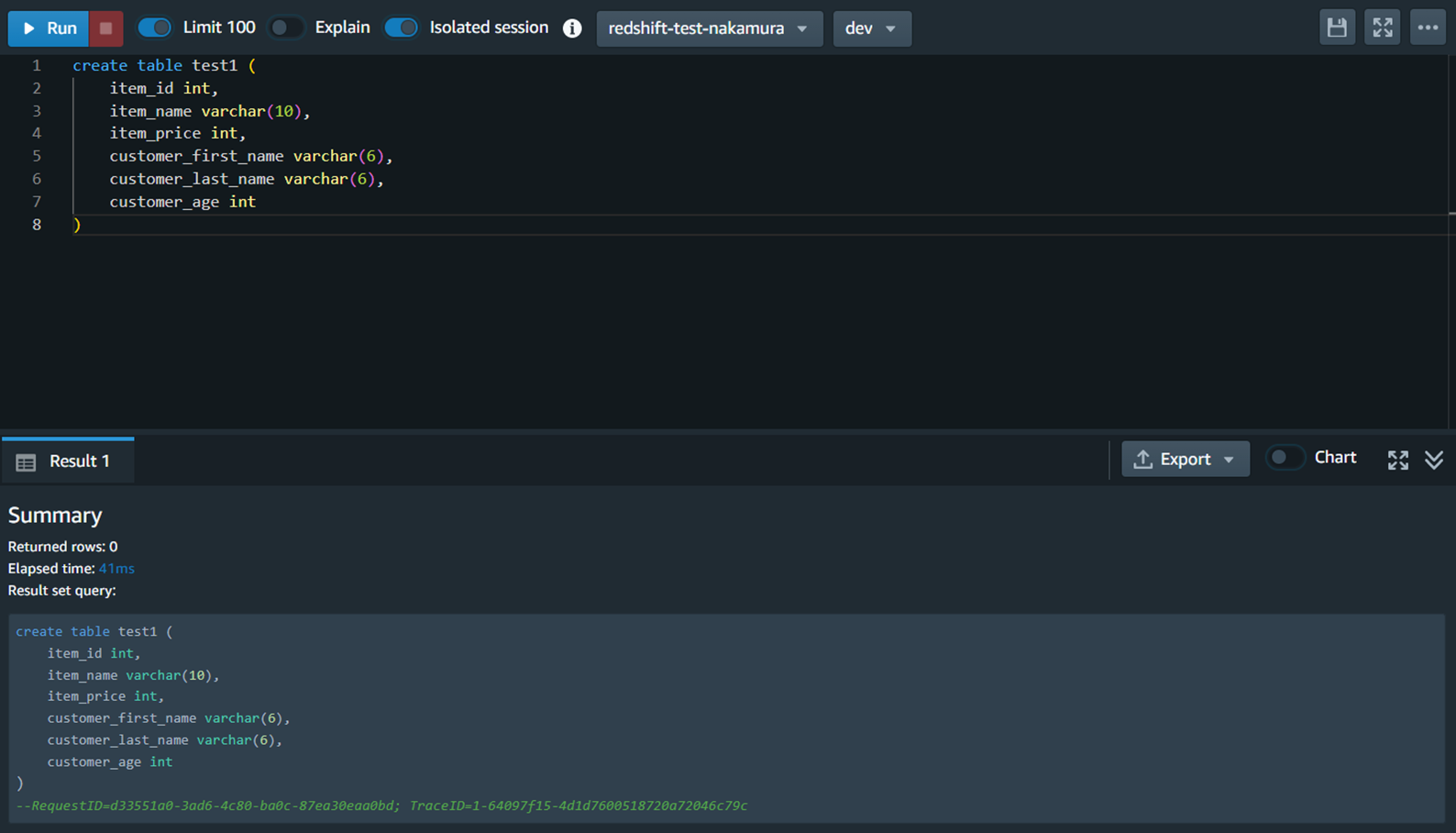
1.Redshiftクラスターのクエリエディタv2を使用して、テーブルを作成します。
(※コピー元データのカラム名と同じカラム名でないと、copyしてもnull値が挿入されます)
2.RedshiftのCOPYコマンドを使用して、S3のデータをRedshiftのテーブルへコピーします。

3.select文で確認

まとめ
今回追加されたTransformは以下の5つになります。
・Add identifier
・Add UUID
・Flatten
・To timestamp
・Format timestamp
Flattenについては、
上記の使用例(半構造化➡構造化)やログデータ等のフラット化に使えそうなので、
便利な機能だと感じました。
この記事が少しでも皆様のお役に立てれば幸いです。
参考サイト