概要
S3上に保存したファイルに対して発行されるクエリを作成します。細かい設定内容のベストプラクティスはまだ分かっていないところがあるので、とりあえず作成するまで。
| 項目 | 内容 |
|---|---|
| 取り扱う内容 | • S3に保存したCSVを参照する、Athenaクエリを定義する方法 • 対象CSVにヘッダ行がある場合の対応 |
| 想定読者 | • 他サービスからS3上のCSVをDBテーブルとして参照したい人(QuickSightなど) |
| ゴール | • S3上のCSVに対して、各列のデータ型を明示したDBテーブルを定義できる |
S3の整備
S3上で、Athenaから参照するデータの配置、およびAthenaがクエリ結果を保存するバケットの作成を行います。
Athenaから参照するデータの配置
対象のファイルをS3バケットに配置します。既に配置済の場合はスキップでOK。後ほどAthenaからの参照先を登録するために、対象ファイルのあるバケットのパスをメモっておきます。

今回は手順の整理だけなのでCSVファイルを配置しますが、圧縮効率と速度の両立を考えると、Parquetファイルを保存する運用にした方が良さそうですね。
Athenaがクエリ結果を保存するバケットの作成
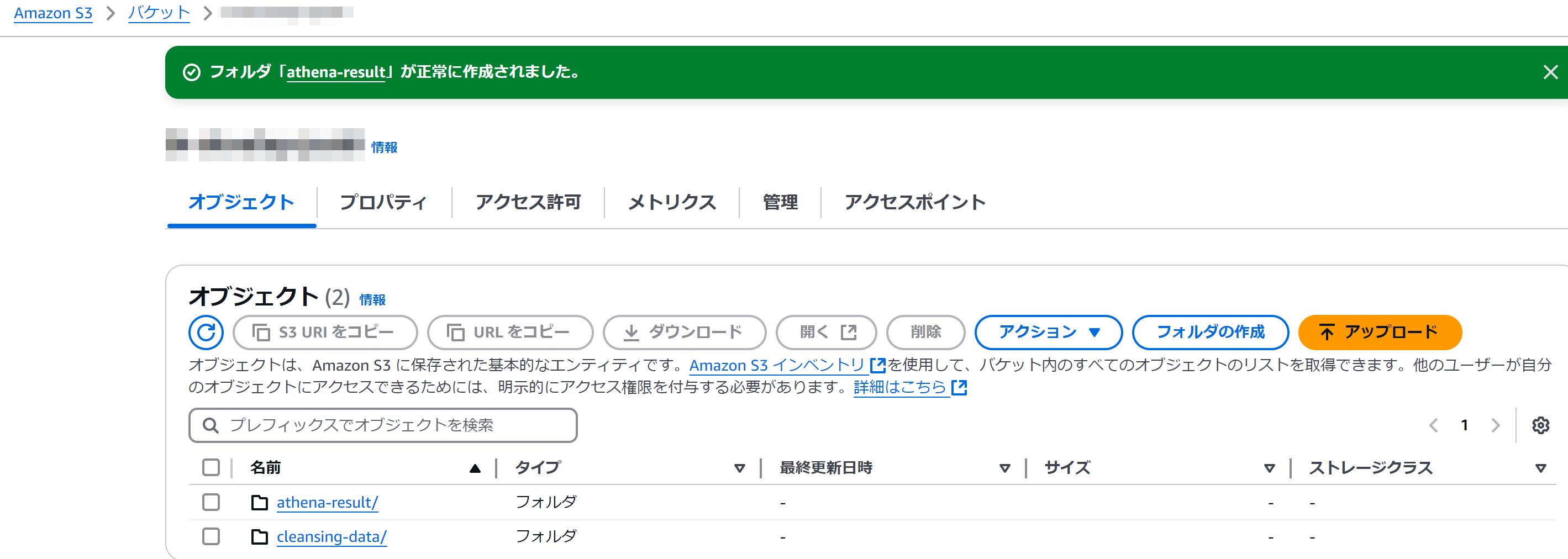
外部からAthenaにデータ取得のリクエストがある度に、Athenaは参照先データのあるS3バケットとは異なるバケットへ、クエリ結果を保存します。今回は参照先データを配置するフォルダと同じ階層にathena-resultとしてフォルダを作成しました。クエリ結果が保存されるバケットにライフサイクルルール(数時間で消えるなど)を設定する場合、バケット内のフォルダではなく、バケット自体を分ける必要がありそうですね(だよね?)
Athenaでテーブル定義を作成する
Athenaのクエリエディタ左部のサイドバーから、テーブルを作成する場所(データソース/データベース)を指定して、作成をクリックします。データベースの初期値はアルファベット順で先頭にあたるalblogdbが選択されていますが、ここにはALBのlog関連っぽい用途で既にテーブルがありました。したがって、ここではdefaultに変更します。

ドロップダウンより、データソースからテーブルを作成を選択します。S3のデータから一部の列だけ取り出したり、加工・集計しつつ取り出したい場合は、SQLを書いて作成することも可能です。

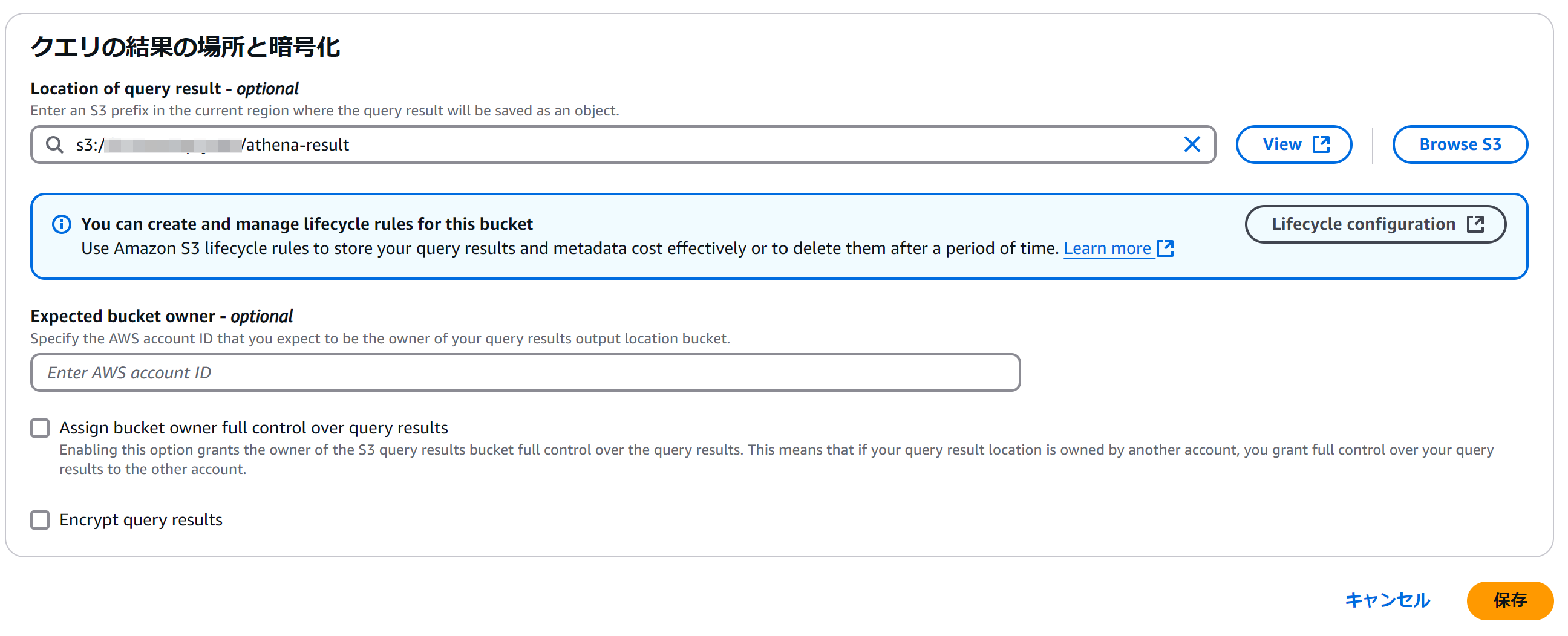
Athenaのクエリ結果を保存するバケットを登録する
Athenaがクエリ結果を保存するバケットの作成で作成したバケットを登録します。


登録した状態。保存をクリックします。
S3バケットデータからテーブルを作成する
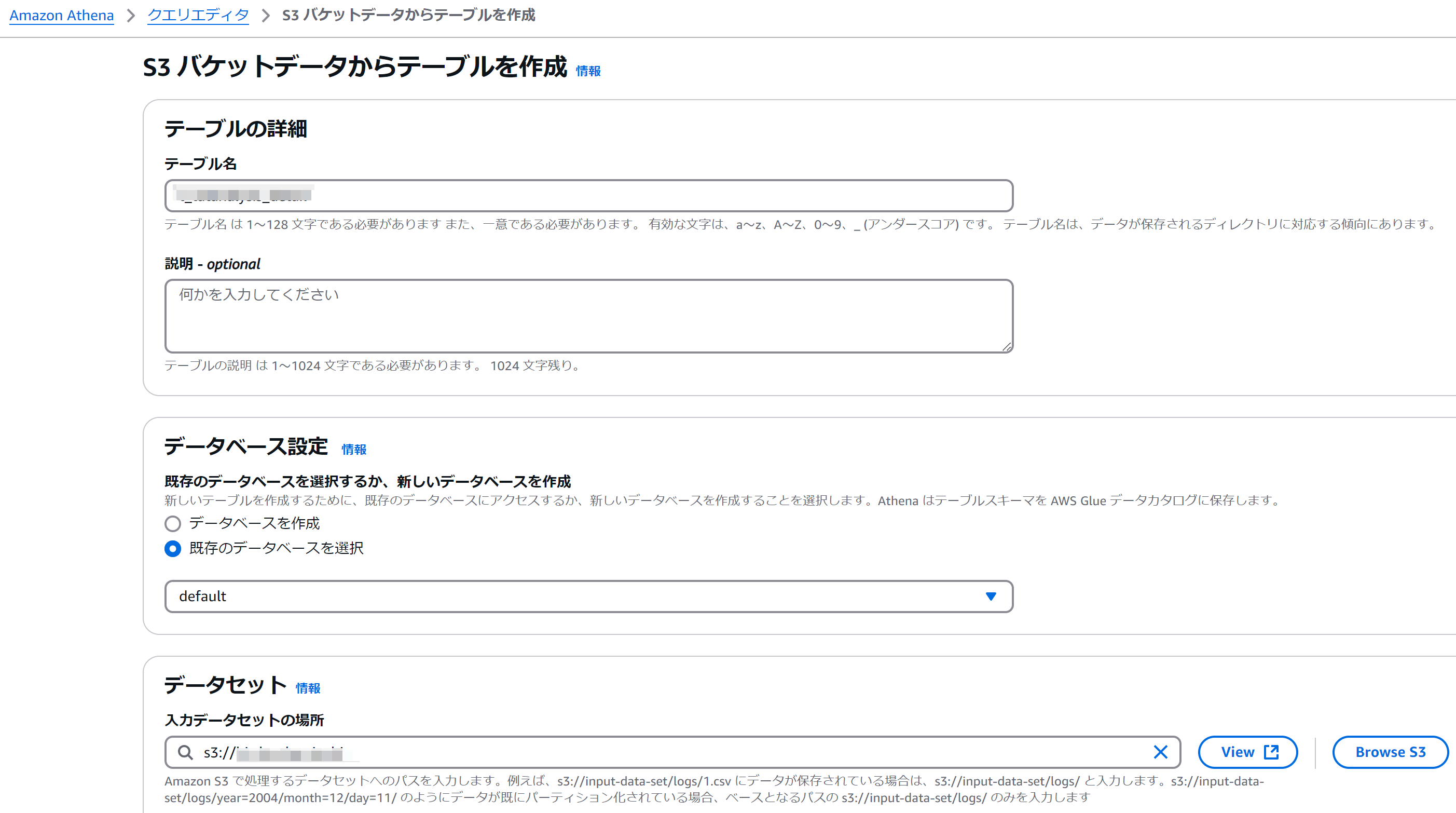
テーブルの属性情報を登録する
上から順にテーブル名、テーブル作成先のデータベース、元データとして参照するS3バケットを指定します。データベースはここで新規作成も可能です。S3の指定はファイルではなく、ファイルがあるバケットを指定すればよいです。
データ形式を設定する
テーブルタイプはデフォルトのApache Hiveままとしました(要件次第で精査は必要) ファイル形式は、S3に置いたファイルの形式に合わせます。

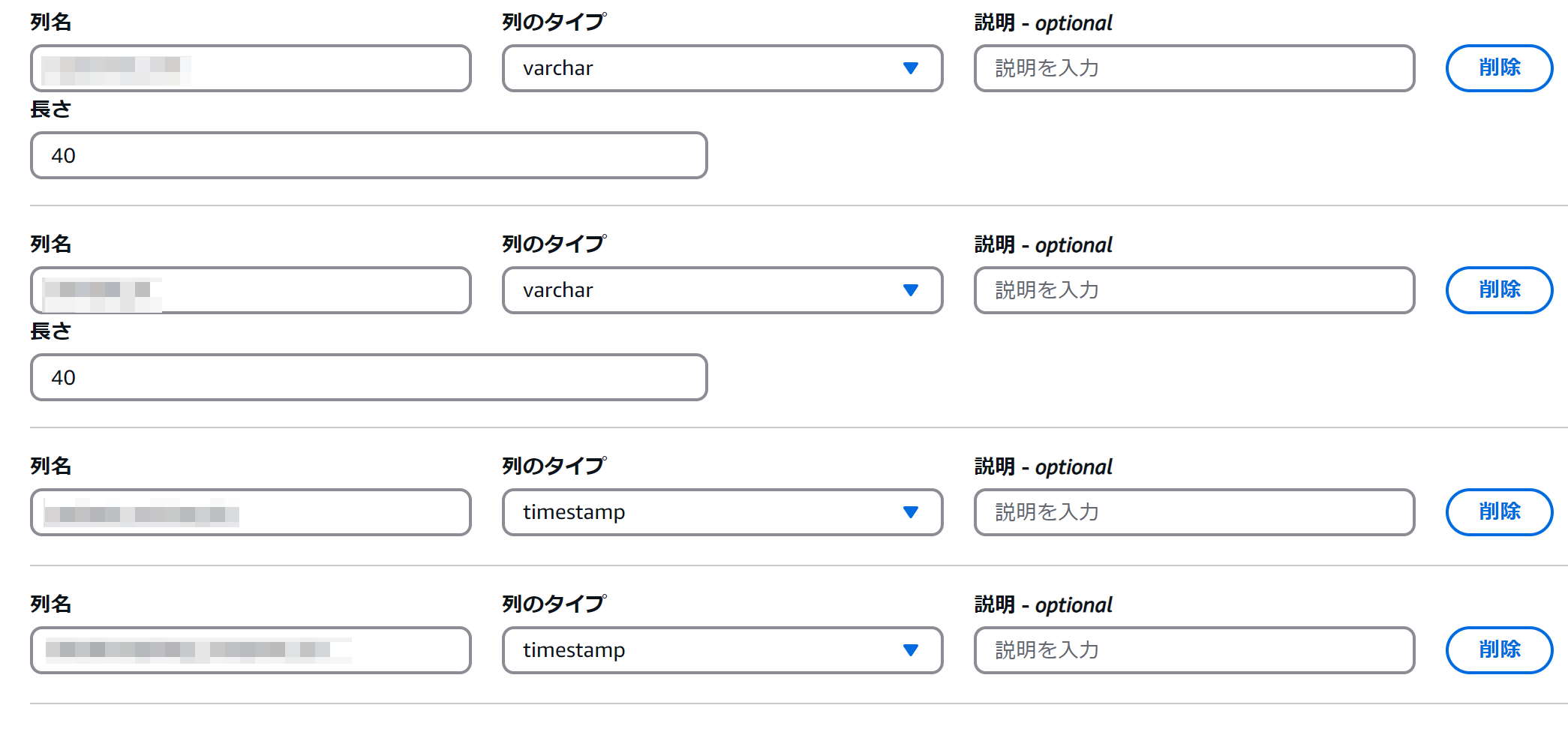
カラム定義を設定する
列の一括追加をクリックすると、列名 データ型の形式でカラム定義を一括で登録できるウィンドウが開きます。CREATE TABLE文の要領で、カンマ区切りで登録を行います。

注意点として、データ型の表記はAthenaが対応しているものでないと、登録時に列名だけが登録されてデータ型が空の状態になります。PostgreSQLのDDLからコピペを試みる場合は、データ型表記の置換を行ってから登録してください。
↓PostgreSQLとAthenaのデータ型対応づけ例(一部)↓
| PostgreSQL | Athena |
|---|---|
| text | varchar |
| timestamptz | timestamp |
| int4 | int |
登録後の状態。varcharは最大サイズを指定する欄があります。指定しないとエラーで先に進めないので、定義します。
テーブルのプロパティを指定する
書き込み圧縮の方式を選択します。今回はQuickSightからのダイレクトクエリなので、解凍速度を優先してLZ4を選択しました。

テーブルデータを分割する
今回は触っていませんが、同一データ中の特定の情報を使って、データのパーティショニング(分割)を行える模様。
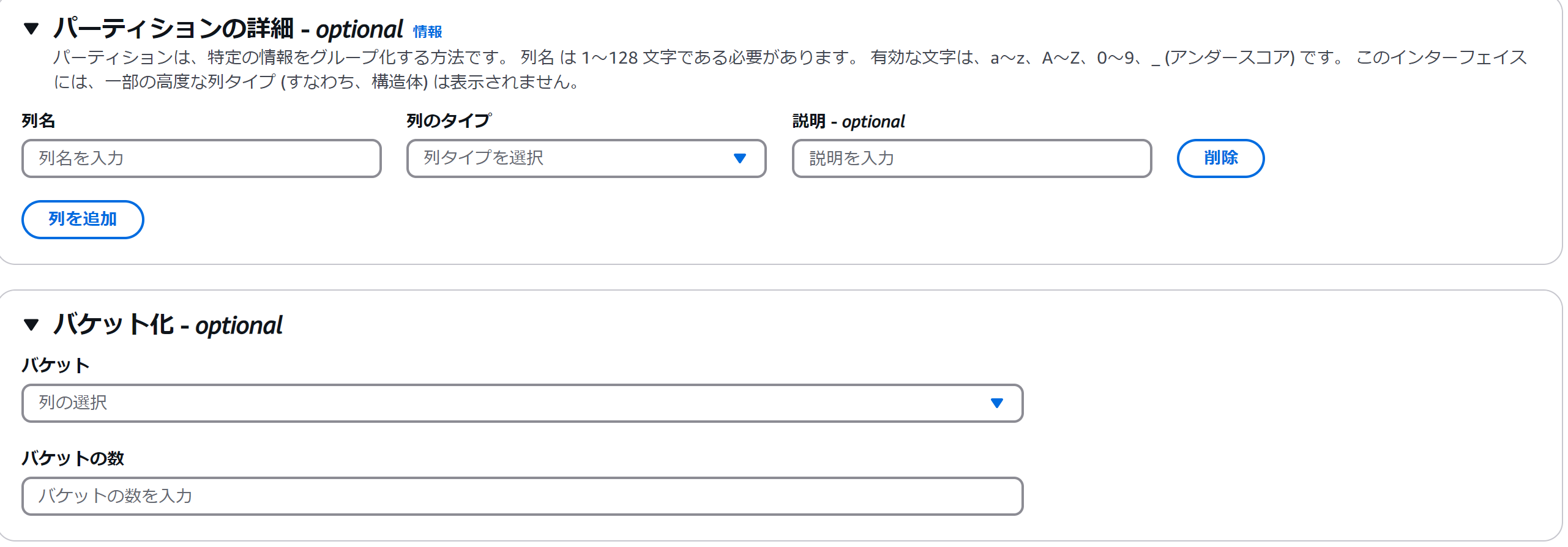
大規模なデータであれば、これを年月や施設IDといった、描画時に意識されるデータの単位で区切って分割することで、クエリの速度を高速化できますね。パーティションはテーブル中に子テーブルのようなものを保持して分割し、バケット化は指定したパーティションに応じてS3側のバケットを分割するように見受けられます。また使ったら書きます。
クエリの実行
すべての設定を終えたら、最下部のボタンからクエリを実行します。DDL文のプレビューが表示されているので、追加すべきプロパティが予め分かっている場合は、ここで追加・変更してからクエリを実行します。後述の【重要】必要に応じて、プロパティを追加・変更する項を参照してください。特に、S3上のCSVにヘッダ行が含まれる場合は、これをスキップするプロパティを追加する必要があります。
登録後の画面。サイドバーに今作成したテーブル名がリスト表示されていればOK。必要に応じて、直近のクエリ結果を再利用するラジオボタンをONにします。これにより、元データに更新・変更が無いユースケースであれば、クエリ実行コストの節約になります。
S3のクエリ結果保存先バケットにも、ファイルが生成されています。

【重要】必要に応じて、プロパティを追加・変更する
テーブル作成時に設定項目の無いプロパティを追加・変更します。既にテーブルを作成してしまったのであれば、【Athena】一度作ったテーブルの定義を変更するにしたがってテーブル定義の変更を行います。
CSVにヘッダ行がある場合、読み飛ばす設定
S3上のCSVにヘッダ行がある場合、スキップさせる設定を追加します。
TBLPROPERTIES (
'skip.header.line.count'='1', -- S3から読み込む際、ヘッダ行をスキップする
)
以下に該当するものを随時追記。
- デフォルトで追加されないプロパティ
- 設定画面に項目が無く、手動で追加する必要のあるプロパティ
以上で、S3ファイルを参照するAthenaテーブルの定義は完了です。
トラブルシューティング
テーブル作成実行時にエラー:No output location provided. An output location is required either through the Workgroup result configuration setting or as an API input.
Athenaがクエリ結果を保存するバケットの作成を正しく行っていないために起こっているエラーです。該当箇所の設定を見直し、適切なバケット登録がされているか確認します。
テーブル作成後、Athena内外からのクエリ実行時エラー:HIVE_BAD_DATA: Not valid Parquet file: s3://backetname/cleansing-data/sample.csv expected magic number: PAR1 got: 17
S3に配置したファイルがCSVであるにもかかわらず、テーブル作成時のファイル形式をParquetに指定していることで起こるエラーです。
テーブル作成クエリのSTORED AS INPUTFORMATを以下の通り編集します。
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'