はじめに
2024年8月頃からAWS上でBedrockを使って社内向け生成AIチャットボットを作っています。
初めて生成AIを使ってみたところで色々考える点があったので、メモとして残しておくことにしました。
生成AI技術が日々すごいスピードで進歩しているので既に古い技術になっていそうなのと、そもそも初心者が書いておりますで、あまり技術的な参考にはならないと思いますが、ポエム的な感じ?でお読みいただけたら幸いです。
考えたこと② AIプラットフォーム
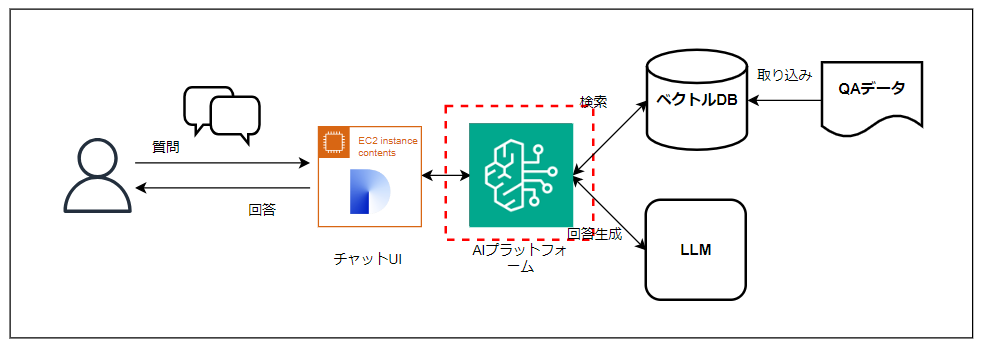
考えたこと②ものの、「AWSで作る」という時点であまり悩まず、今回はAmazon Bedrockの一択でした。(DifyでLLMを使うときにモデルプロバイダーをAWSにする場合はBedrockを指すことになる)
また、下記はAWSさんが生成AIサービスについて説明されるときによく使われてた資料ですが(日本語版でよく見てたのですが見つからず…)、
今回はシンプルなQAデータを読むチャットボットを作るという目的のため、SageMakerで独自モデルを作るほどのものではなく(難しくてできない)、提供されるモデルを使っていきたいという考えがありました。
Amazon Bedrockを使いたかった理由
色んな基盤モデルを利用できる
基盤モデルは種類があって次々と新しいバージョンが出てくるので、置き換えていくことで精度や性能を上げていきたいと考えました。
- 最新のモデルを使いたい
- 用途によって複数のモデルを使い分けたい
ナレッジベース
QAチャットボットの特性からファインチューニングではなくて、RAGを充実させたいと考えました。Dify上でもRAG(ナレッジ)は持てるのですが、以下の理由からBedrockのナレッジベースを使うことにしました。
- 将来的に多数のファイルを読み込みたい
- フォルダ単位で管理したい
- Teams版と共有したい
ガードレール
ガードレールというと不適切な言葉のフィルターするという目的が大きいかと思いますが、今回は社内版ということでそのあたりのガードではなくて、スコアを取得するために使いたいと考えました。
ガードレールにはGroundingとRelevanceという2つのスコアが取得できます。
簡単に書くとGroundingは根拠に基づいているかどうか、Relevanceは質問の意図を汲み取れているかどうかというスコアとのことです。
(こちらの記事を参考にさせていただきました。)
初期検討時はハルシネーション抑制ためにGroundingスコアを使いたいという目的があったのですが、ある程度チャットボットの形ができあがってきた現段階では、Relevanceスコアを使ってスコアの低い回答だった場合にQAデータとして追加させようかという改善活動に向けての使い方が大きくなってきた気がします。
フロー
シンプルなチャットボットと言えども、質問と回答の処理だけでは成り立たなくて、RAG検索したり、スコアを取得して制御したり、履歴をDBに格納したり、ちゃんとした回答得られなかったときに代替候補出したり等々、、、フローとして処理を組むことが必要になってくると思います。
こちらはDifyの特徴であるワークフローで実現できますが、Bedrockでもフロー機能があり、どちらを使うか考えました。
初期検討時はDifyでフロント側の制御、LLMやRAG的なバックエンドにBedrock側のフローを使おうかという案もありましたが、全体的な使い易さ(UI、複製が楽、デバッグ簡単…etc)の面でDify側のフローで対応することにしました。
#Bedrock側のフローはPreview版でPrompt Flowsと呼ばれていたときに比較したので、現在はPreview外れてAmazon Bedrock Flowsになったようなので当時よりは使い易くなっているんだろうと思います。
Amazon Bedrock 構築時に参考にしたサイト
DifyからBedrockにIAMロールでアクセスさせる
アクセスキーではなくEC2にIAMロールを割り当てて利用する方法として参考にしました。
APIの呼び出し
ナレッジベースやガードレールのAPI呼び出しは、Dify側でカスタムツールを作成して、API Gateway⇒Lambda⇒Bedrockという感じで呼び出す形としました。
考えた結果