#はじめに
本記事の対象読者は構文解析に興味はあるが、はじめの一歩がなかなか踏み出せない方です。
目標は他の記事を読む際の敷居を下げることです。
また、構文解析はコンパイラ作成や電卓作成に使える技術です。
ぜひここで少し理解した後に、他の記事で完全理解することを目指してください!
※本記事の説明に使うプログラム: https://github.com/ShebangDog/lets
※参考にした記事: https://www.sigbus.info/compilerbook
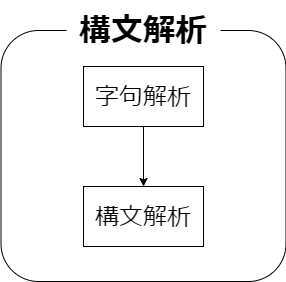
#構文解析
構文解析とは形式文法に沿って構文木を生成する行為です。
例えば以下の図が表す動作がそれに該当します。

上記では数式と同様の文法を利用して構文解析を行っています。
また構文解析は主に二つの処理で成り立っています。
一つが字句解析、もう一つは構文解析です。
##字句解析
字句解析とは文字列から意味のある単位(トークン*)の並びへ変換する行為です。
例えば以下の図が表す動作がそれに該当します。

まずこれの目的は構文解析を行う時に生の文字列を扱うことを避けることにあります。
これを行うことで次の処理である構文解析で構文の正しさのみに注目できます。
下記がプログラム例です。
Token *tokenize(char *string) {
Token *root = calloc(sizeof(Token), 1);
root->kind = T_ROOT;
Token *head = root;
for(;; string++) {
char value = string[0];
if (value == '\0') {
Token token = {.kind = T_END};
head = new_token(token, head);
return root;
}
if (is_space(value)) continue;
if (is_num(value)) {
Token token = {.value = value, .kind = T_NUM, .next_token = NULL
};
head = new_token(token, head);
}
if (is_operator(value)) {
Token token = {.value = value, .kind = T_OPE, .next_token = NULL};
head = new_token(token, head);
}
}
このプログラムは、生の文字列(string)を一文字ずつ見て該当するトークンへの変換を行います。
演算子であればOPERATORを数字であればNUMBERをトークンの種類として格納します。空白であれば読み飛ばします。
よって、字句解析を行うことで、構文解析の際に空白を気にする必要が無くなります。
またトークンの種類分けも行われるため、そのトークンが何であるかが容易に分かります。
※new_token(Token* token, Token* parent)は、parentの次のトークンとしてtokenをつなげる関数を想定しています。
##構文解析
構文解析とは字句解析で得られたトークン列を構文に沿った構文木に変換する行為です。
例えば以下の図が表す動作がそれに該当します。

下記がプログラム例です。
Node *parse(Token *token ,Node* node) {
if (!is_root_token(token)) exit(1);
Node *result = expression(token->next_token);
return result;
}
Node* number(Token *token) {
Node *node = new_node(NUMBER, token->value, NULL, NULL);
return node;
}
Node* expression(Token *token) {
Node *node = number(token);
token = token->next_token;
while (1) {
if (is_num_token(token)) exit(1);
if (is_end_token(token)) return node;
if (is_operator_token(token)) {
char symbol = token->value;
token = token->next_token;
Node *right_number = number(token);
node = new_node(OPERATOR, symbol, node, right_number);
token = token->next_token;
continue;
}
exit(1);
}
}
このプログラムは以下の処理を行います。
- トークン列が構文に沿っているか確認する
- トークンの種類と対応するノードを作る
- 作ったノードをつなげる
この短い記述で、どれだけ長い文字列が入力されたとしても構文が正しければ木にすることができます。
*new_node(Kind kind, char value, Node *left, Node *right)は節の種類、値としてkind、valueを受け取り左の要素としてleft右の要素としてrightを受け取り、その節を返す関数を想定しています。
#最後に
本記事では登場しませんでしたが、BNFや再帰関数といったものの考えかたや使い方は習得しておくと良いです。
名前から少し難しそうに思うかもしれませんが、両方とも書き方に関わるものですので軽い気持ちで挑戦してみてください。
また、これら二つを知るだけで読みやすくなる記事も増えるはずです。