前書き
記事の概要
今回は機械学習の中で最も基本的なモデルの1つである 線形回帰 について解説していきます。
この記事には
- 数式による線形回帰の解説
- プログラム実装例
が含まれています。それぞれ自分に必要な部分を参照してもらえればいいなと思っています。
対象読者
大学1年生で勉強する「線形代数学」および「統計学」の基礎事項は既知であるとして話を進めていきます。
キーワードは 最小二乗法 / 最尤推定 / ガウス分布 です。
もし記事中でわからない言葉が出てきた場合には、線形代数学の教科書を読んだり他のサイトを見たりして調べてみてください。
導入
データ集合 $D = \{ ({\bf x^{(n)}}, y^{(n)}) \}_{n=1}^N$ が与えられたとき、各 $({\bf x}, y)$ の因果関係 $y = f({\bf x})$ を推定する問題を考えます。すなわち、$({\bf x}, y)$ の関係を規定するモデル $y = f({\bf x})$ を構成することを考えます。 $y$ が連続値の場合には 回帰(問題) 、離散値の場合には 分類(問題) と呼ばれます。ここで「モデルを構成する」というのは「モデルの構造(関数 $f$ )を決める」ことを指してします。場合によっては「モデルに含まれるパラメータを決める」プロセスも含まれるかもしれません。
通常、機械学習では真の分布に関する情報が利用できないと仮定することが多いです。回帰/分類問題について言えば、 $({\bf x}, y)$ の背後にどのような関係があるか知ることができない状況を考えるということです。「モデルの構造(関数 $f$ )を決める」と言うのは「 $({\bf x}, y)$ が $y = f(x)$ という関係式に従っていると仮定すればうまく説明できるかもしれない」というイメージで捉えるのが良いと思います。
モデルの構造としてどのようなものを採用するのが良いでしょうか。これはケースバイケースと言わざるを得ません。機械学習を使うからには何かしらの意図や要求があると思いますが、それに応じて適切なモデルを選ぶことになると思います。
良いモデルの基準の1つに「簡潔さ」があります。その動機としては「簡単なモデルなら直感的に理解しやすい」「短時間で処理をしたい」といったものが挙げられるでしょう。回帰問題を解くモデルで最も基本的で簡単なものが (一般)線形回帰 です。
線形回帰モデルでは、構造としてパラメータ ${\bf w}$ の線形関数を採用する、すなわち目的変数 ${\bf y}$ が説明変数 ${\bf x}$ の係数 ${\bf w}$ の線形結合で表現できると仮定します。式で書けば
\begin{eqnarray*}
y = f({\bf x}) \equiv {\bf w}^T {\bf x}
\end{eqnarray*}
となります。1 以下で詳しく説明しますが、このパラメータ ${\bf w}$ は最小二乗法と呼ばれる方法で観測データに基づいて最適化します。
理論
基礎的な話
線形回帰の枠組みでは、観測データ集合 $D = { ({\bf x^{(n)}}, y^{(n)}) }_{n=1}^N$ が与えられたとき、それを表現するモデルとして
\begin{eqnarray*}
y = f({\bf x}) \equiv {\bf w}^T {\bf x}
\end{eqnarray*}
を採用します。以下ではこのモデルに含まれる重み係数パラメータ ${\bf w}$ として「最も尤もらしい」ものを推定することを考えましょう。
ここで 尤もらしい というのは「観測データをうまく説明できている」という意味です。
下図にはある1次元観測データを回帰分析する様子が描かれています。観測データ(true)は水色、それを回帰分析した結果の予測値(predict)は赤色で示されています。
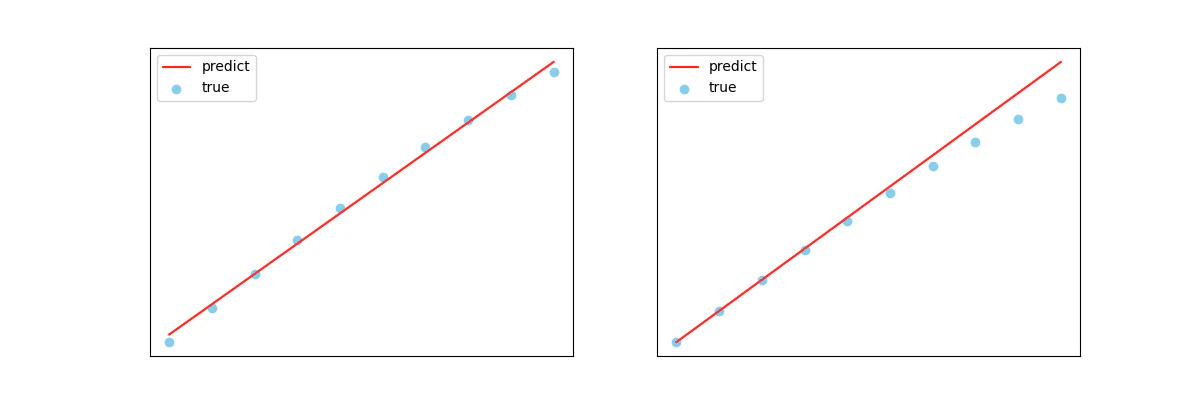
どちらも直線によってデータを説明しようとしていることから、線形回帰モデルを利用していることがわかると思います。ただ、同じモデルを採用していてもパラメータ(傾きと切片)が異なれば予測が異なり、その結果観測データに対するあてはまり具合も変わってきます。今回の例に関して言えば、(微妙な違いではありますが)左の回帰直線の方がデータをよく説明できており、より「尤もらしい」と考えます。2
もう1つの例をみてみましょう。下図ではさらに観測データが追加された状況を考えています。
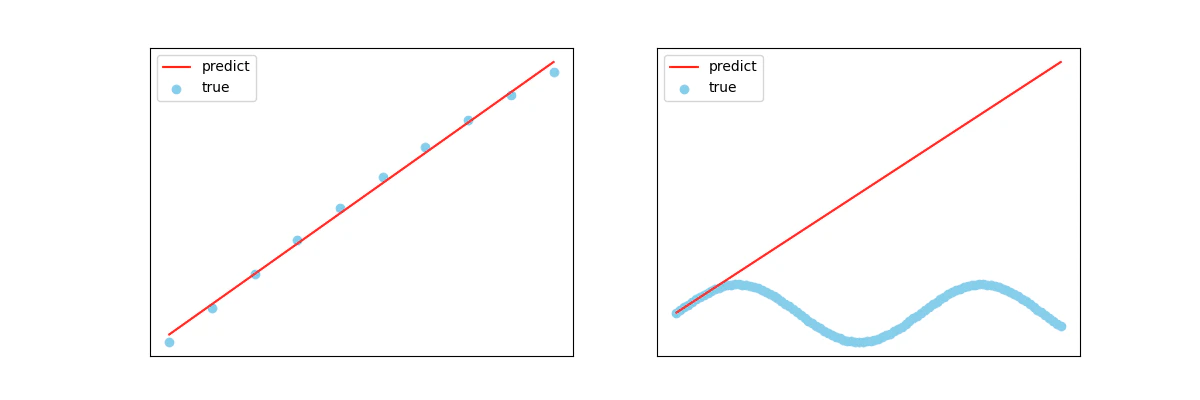
観測データの先頭を局所的に見れば線形回帰モデルでもうまく説明できていましたが、追加された観測データを含めて大局的に見るとそうでもないことがわかりました。それどころか、この観測データはもはや直線では表現できないことも明らかだと思います。このような場合には線形回帰モデルを使うことが不適切で、別のより「尤もらしい」モデルを選択するのが良い、ということになります。
以上2つの例では「尤もらしい」かどうかを直感的に判断しましたが、ここからはより形式的に「尤もらしさ」を取り扱うことを考えます。
観測データをうまく説明できているかどうかを測る指標として 二乗和誤差 があります。これは残差(= 真の値 - 予測値)の2乗和で
\begin{eqnarray*}
L = \sum_{n=1}^N \left( y_n - f({\bf x_n}) \right)^2
\end{eqnarray*}
という式で表されます。この値をより小さくするようなパラメータ ${\bf w}$ がより良いパラメータであると考えることができます。線形回帰では、二乗和誤差を最小化する点を探索することで最適なパラメータ ${\bf w}$ を求めます。これを 最小二乗法 と言います。
では実際に最小二乗法によって最適解 ${\bf w^{\ast}}$ を求めてみましょう。二乗和誤差 $L$ は
\begin{eqnarray*}
L({\bf w})
&=& \sum_{n=1}^N \left( y_n - f({\bf x_n}) \right)^2 \\
&=& \sum_{n=1}^N \left( y_n - {\bf x_n}^T {\bf w} \right)^2 \\
&=& \| {\bf y} - X {\bf w} \|^2
\end{eqnarray*}
と書き直すことができます。ここで
\begin{eqnarray*}
X \equiv
\left(
\begin{array}{c}
{\bf x_1} \\
\vdots \\
{\bf x_n}
\end{array}
\right)
,
{\bf y} \equiv
\left(
\begin{array}{c}
y_1 \\
\vdots \\
y_n
\end{array}
\right)
\end{eqnarray*}
と定義しています。 $L$ の( ${\bf w}$ による)勾配を計算すると
\begin{eqnarray*}
\frac{\partial}{\partial {\bf w}} L({\bf w})
&=& 2 X^T (X {\bf w} - {\bf y})
\end{eqnarray*}
となります。$L({\bf w})$ を最小にする点 ${\bf w^{\ast}}$ では勾配が ${\bf 0}$ になることから
\begin{eqnarray*}
\frac{\partial}{\partial {\bf w}} L({\bf w^{\ast}}) = {\bf 0}
&\Leftrightarrow& 2 X^T (X {\bf w^{\ast}} - {\bf y}) = {\bf 0} \\
&\Leftrightarrow& X^T X {\bf w^{\ast}} = X^T {\bf y}
\end{eqnarray*} \\
という式を得ることができます。これは 正規方程式 と呼ばれています。 $m$ 次正方行列 $X^T X$ が正則ならば
\begin{eqnarray*}
{\bf w^{\ast}} = (X^T X)^{-1} X^T {\bf y}
\end{eqnarray*}
と解析的に ${\bf w^{\ast}}$ を求めることができます。
解析的に計算できない場合
正規方程式が解析的に計算できるためには、 $m$ 次正方行列 $X^T X$ が正則である必要があります。では、 $X^T X$ が正則でない場合にはどうすれば良いでしょうか。
1つの解決策は 勾配法 を利用することです。
例えば最急降下法によって線形回帰モデルのパラメータ ${\bf w}$ を推定する場合には
\begin{eqnarray*}
{\bf w} := {\bf w} - \eta \frac{\partial}{\partial {\bf w}} {\mathcal L}({\bf w})
\end{eqnarray*}
という更新式によって ${\bf w}$ の推定値を改善していきます。一般にパラメータの最適解を閉形式で求めることができない場合には、勾配法のような反復法を利用します。
もう1つの解決策は 正則化 です。
そもそも問題だったのは「 $X^T X$ が正則行列になる保証がない」ことでした。この問題を解決するために、「 $X^T X$ に対角行列 $\lambda I_m$ を加えることで正則行列にする」ことを考えます。十分大きな $\lambda$ をとれば $X^T X + \lambda I_m$ は正則行列になります。以下では任意の行列がある対角行列を足すことで正則化できることを証明しています。興味があればクリックしてご覧ください。
任意の正方行列が正則化可能であることの証明
任意の $n$ 次正方行列 $A$ に対してある $\lambda$ が存在して $A + \lambda I_n$ が正則行列になることを示します。
この証明には 狭義優対角行列 という概念が必要になります。以下では簡単に狭義優対角行列に関する性質を見た後、それを利用して本題を示すことにします。
$n$ 次正方行列 $A$ が狭義優対角行列であるとは、すべての行 $i$ に関して
$$
| a_{ii} | > \sum_{j \ne i} | a_{ij} |
$$
が成立することを言います。
補題として、狭義優対角行列が正則であることを示しましょう。
狭義優対角行列 $A$ が正則でないと仮定します。このとき、連立方程式 $A {\bf x} = {\bf 0}$ には非自明解 ${\bf x} \ne {\bf 0}$ が存在するので、それを1つ固定します。
${\bf x}$ のうち、絶対値が最大である成分を $x_i$ と書くことにします。${\bf x} \ne {\bf 0}$ なので $x_i > 0$ であることに注意してください。連立方程式の第 $i$ 行に注目すると
$$
\sum_j a_{ij} x_j = 0 \
a_{ii} x_i = - \sum_{j \ne i} a_{ij} x_j \
| a_{ii} x_i | \le | \sum_{j \ne i} a_{ij} x_j |
$$
です。両辺の絶対値をとると
$$
| a_{ii} | | x_i |
\le \sum_{j \ne i} | a_{ij} | | x_j |
\le \sum_{j \ne i} | a_{ij} | | x_i |
$$
が成立します。両辺を $| x_i |$ で割ると
$$
| a_{ii} | \le \sum_{j \ne i} | a_{ij} |
$$
となりますが、これは $A$ が狭義優対角であることに矛盾します。よって $A$ は正則です。
これで狭義優対角行列が正則であることがわかったので、あとは $A$ に $\lambda I_n$ を加えることで狭義優対角行列にすれば良いです。これは十分大きな $\lambda$ をとることで実現できます。(具体的には $\epsilon$ を正の定数として $\lambda = \max_{i}{\sum_{j \ne i} | a_{ij} | } + \epsilon$ とすれば $A + \lambda I_n$ は必ず狭義優対角行列になります。)
以上より、任意の正方行列は正則化できることがわかります。
次項では正則化を施した場合の線形回帰モデルについて考察します。
L2正則化線形回帰(Ridge)
正規方程式が解析的に計算できない場合の解決策として正則化という概念を導入しました。ここでは「 $X^T X$ に対角行列を足すことで正則行列にする」という方面から考えていました。これが修正された誤差関数から自然に導出されることを見てみましょう。
正則化線形回帰では、二乗和誤差に正則化項 $\frac{1}{2} \lambda | {\bf w} |_2^2$ を加えたものを新しい誤差関数とします。すなわち
\begin{eqnarray*}
L({\bf w}) = \| {\bf y} - X {\bf w} \|^2 + \lambda \| {\bf w} \|_2^2
\end{eqnarray*}
とします。ここで $\lambda$ は正則化係数で、正則化の強さを調整するパラメータです。 $\lambda = 0$ のときを考えると、正則化なしの線形回帰モデルになっています。
では、新しい誤差関数 $L$ の勾配を求めます。追加された項の勾配は
\begin{eqnarray*}
\frac{\partial}{\partial {\bf w}} \| {\bf w} \|^2 = 2 {\bf w}
\end{eqnarray*}
なので、全体では
\begin{eqnarray*}
\frac{\partial}{\partial {\bf w}} L({\bf w})
= 2 X^T (X {\bf w} - {\bf y}) + 2 \lambda {\bf w}
= 2 \{ (X^T X + \lambda I_m) {\bf w} - 2 X^T {\bf y} \}
\end{eqnarray*}
となります。これを ${\bf 0}$ とおくことで最適パラメータ ${\bf w^{\ast}}$
\begin{eqnarray*}
{\bf w^{\ast}} = (X^T X + \lambda I_m)^{-1} (X^T {\bf y})
\end{eqnarray*}
を求めることができます。天下り的ではありましたが、誤差関数にペナルティをうまく加えることで正則化を実現することができました。
このように、L2ノルム(の定数倍)を正則化項とした線形回帰モデルを Ridge回帰 と言います。
L1正則化線形回帰(LASSO)
前項では ${\bf w}$ のL2ノルム(の定数倍)を正則化項としましたが、L2ノルム以外の関数を利用することもできます。
一般に広く利用されているのがL1ノルムです。L1ノルム(の定数倍)を正則化項とした線形回帰モデルを LASSO回帰 と言います。LASSOにおける誤差関数 $L({\bf w})$ は
\begin{eqnarray*}
L({\bf w}) = \| {\bf y} - X {\bf w} \|^2 + \lambda \| {\bf w} \|_1
\end{eqnarray*}
となります。パラメータ ${\bf w}$ がスパースになるため、重要な特徴量を抽出することができるというメリットがあります。LASSOはそれだけで1記事書けるほど奥が深いので、この記事ではこれ以上踏み込まないことにします。
発展的な話
一般線形回帰を確率モデルとして定式化してみましょう。
観測データ集合 $D = { ({\bf x_n}, y_n) }_{n=1}^N$ に対して、上の議論では
\begin{eqnarray*}
y = f({\bf x}) \equiv {\bf w}^T {\bf x}
\end{eqnarray*}
というモデルを仮定していました。これを確率的に取り扱うために、誤差項 $\epsilon$ を導入して
\begin{eqnarray*}
y = {\bf w}^T {\bf x} + \epsilon
\end{eqnarray*}
とします。 $\epsilon$ は平均0、分散 $\sigma^2 (\sigma > 0)$ の分布に従う確率変数です。 このとき $y$ も確率変数であって
\begin{eqnarray*}
{\bf E}[y] = {\bf w}^T {\bf x}
\end{eqnarray*}
です。これまでは確率的な線形回帰モデルの期待値について議論していたと考えることができるかもしれません。
もう少し強い仮定として、各データ $({\bf x_n}, y_n)$ に加えられている誤差項 $\epsilon_n$ が互いに独立にガウス分布に従うという場合を考えます。つまり
\begin{eqnarray*}
\epsilon \sim {\mathcal N}(0, \sigma^2)
\end{eqnarray*}
であるとします。このとき $y$ については
\begin{eqnarray*}
y \sim {\mathcal N}({\bf w}^T {\bf x}, \sigma^2)
\end{eqnarray*}
となります。ここまでで「説明変数 ${\bf x}$ とパラメータ ${\bf w}$ が入力として与えられると、平均 ${\bf w}^T {\bf x}$ 、分散 $\sigma^2$ のガウス分布に従って目的変数 $y$ が出力として得られる」というモデルを構築したことになります。
それでは 最尤推定 の枠組みを使って一般線形回帰モデルのパラメータ ${\bf w}$ を推定していきましょう。
最尤推定とは、字面の通り「最も尤もらしいパラメータを点推定する」枠組みです。
パラメータをある値に固定したとき、その条件下で与えられたデータが発生する確率をそのパラメータの 尤度 (尤もらしさ)と考えます。最尤推定では、尤度を最大化するようなパラメータを解析的に求めるということを行います。
上で定義した一般線形回帰モデルの尤度 $L({\bf w})$ は
\begin{eqnarray*}
L({\bf w})
&=& \prod_{n=1}^N p(y_n | {\bf x_n}, {\bf w}) \\
&=& \prod_{n=1}^N \frac{1}{\sqrt{2 \pi \sigma^2}} \exp \left( - \frac{1}{2 \sigma^2} (y_n - {\bf w}^T {\bf x_n})^2 \right) \\
&=& \left( \frac{1}{2 \pi \sigma^2} \right)^{\frac{N}{2}} \exp \left( - \frac{1}{2 \sigma^2} \sum_{n=1}^N (y_n - {\bf w}^T {\bf x_n})^2 \right)
\end{eqnarray*}
となります。これはパラメータ ${\bf w}$ を固定した条件下で説明変数 $\{ {\bf x_n} \}_{n=1}^N$ が与えられたときに $\{ y_n \}_{n=1}^N$ が発生する確率となっています。各データ組は独立なので、同時確率は各データ組が発生する確率の積となっています。
この尤度に対して勾配を求めて ${\bf 0}$ とおいて極小解を求めても良いですが、問題を簡単にするために対数をとることにします。この操作は、対数関数が単調増加関数で適用しても大小関係は変わらないことから正当化されます。すると
\begin{eqnarray*}
\log{L({\bf w})} = - \frac{1}{2 \sigma^2} \sum_{n=1}^N (y_n - {\bf w} {\bf x_n})^2 + const
\end{eqnarray*}
となります。 $const$ は ${\bf w}$ に依存しない定数項です。
さらに対数尤度に-1を乗じることで「負の対数尤度の最小化」を考えることもできます。負の対数尤度 ${\mathcal L}({\bf w})$ を計算すると
\begin{eqnarray*}
{\mathcal L}({\bf w}) \equiv - \log{L({\bf w})} = \frac{1}{2 \sigma^2} \sum_{n=1}^N (y_n - {\bf w}^T {\bf x_n})^2 + const
\end{eqnarray*}
となります。
ここで、いま導出した式を見直してみましょう。負の対数尤度 ${\mathcal L}$ の最小化は
\begin{eqnarray*}
\min_{\bf w} {\mathcal L}({\bf w}) = \min_{\bf w} \sum_{n=1}^N (y_n - {\bf w}^T {\bf x_n})^2
\end{eqnarray*}
と書くことができます。よって、負の対数尤度の最小化はデータ集合 $\{ ({\bf x_n}, y_n) \}_{n=1}^N$ に関して最小二乗法を実行することと完全に等価になっています。3
実装
線形回帰およびRidge回帰(L2正則化線形回帰)の実装はGitHubで公開しています。
線形回帰は LinearRegression クラスとして実装しました。(正則化パラメータ lam によって)L2正則化が扱えるようになっているため、Ridge回帰の実装 Ridge は単にエイリアスとなっています。
LinearRegression クラスには正規方程式を解析的に計算する方法と勾配法によって最適化する方法の2つを実装しました。 fit 関数の引数として max_iter というパラメータがありますが、これを0にすると正規方程式を解析的に計算し、正の値にすると勾配法を利用するようになっています。