TL;DR
-
Latent Dirichlet Allocation(LDA)で遊ぶだけの記事です
- Latent Dirichlet Allocationの理論について深堀しません
-
今回は前処理だけを記載した記事です
- さらっと利用方法をご紹介します
-
内容
自社のブログ記事の分析などに流用できないかLDA試した -
検証
「自社のTech blog(GCPの記事)」と「グルメサイトの口コミ(ラーメン)」の比較を実施
(かなり、差が出る検証) -
結果
出現の単語も全く違うので、分類成功! -
展望
Tech Blog内のトピックに差が少ない記事で検証したい
初めに
こんにちは、しゃんはいです。
Google Cloud Platformチームのアドベントカレンダー23日目の担当となります!
社内では機械学習などをやってる若手です。
弊社ではクラウドサービスの導入支援や案件の受託をしております。
この季節になるとAdvent Calendarで記事を読む機会が増ますよね。
Advent Calendarの記事をつらつら見ていると、ふと気になったことがありました。
「ブログの記事はみんな丁寧なことが多いけど、タグ付けは丁寧な人もおれば、テキトーな人もおるな」
これなんか支援でけへんかな??
みたいな感じで、まずはLatent Dirichlet Allocation(LDA)でブログ記事の分類をしてみることにしました。
Latent Dirichlet Allocation(LDA)
Latent Dirichlet Allocation(LDA)は、潜在ディレクレ分配モデルとも呼ばれる。トピック分布にディレクレ分布を事前分布と仮定して、ベイズ推定をしているモデルとなる。
(トピック:文章における話題のこと)
と言っても、わからんのでイメージは下の図です。
LDAに文章のデータを入力すると、文章における各トピックごとの単語の分布(潜在的なTopic)が計算される。この単語の分布を見てTopicの解釈を人間が行います。例えば、「GoogleやGCPなどの単語があるためグルメ記事だろう!」のような解釈です。二度言いますが、解釈するのはあくまで人間です。
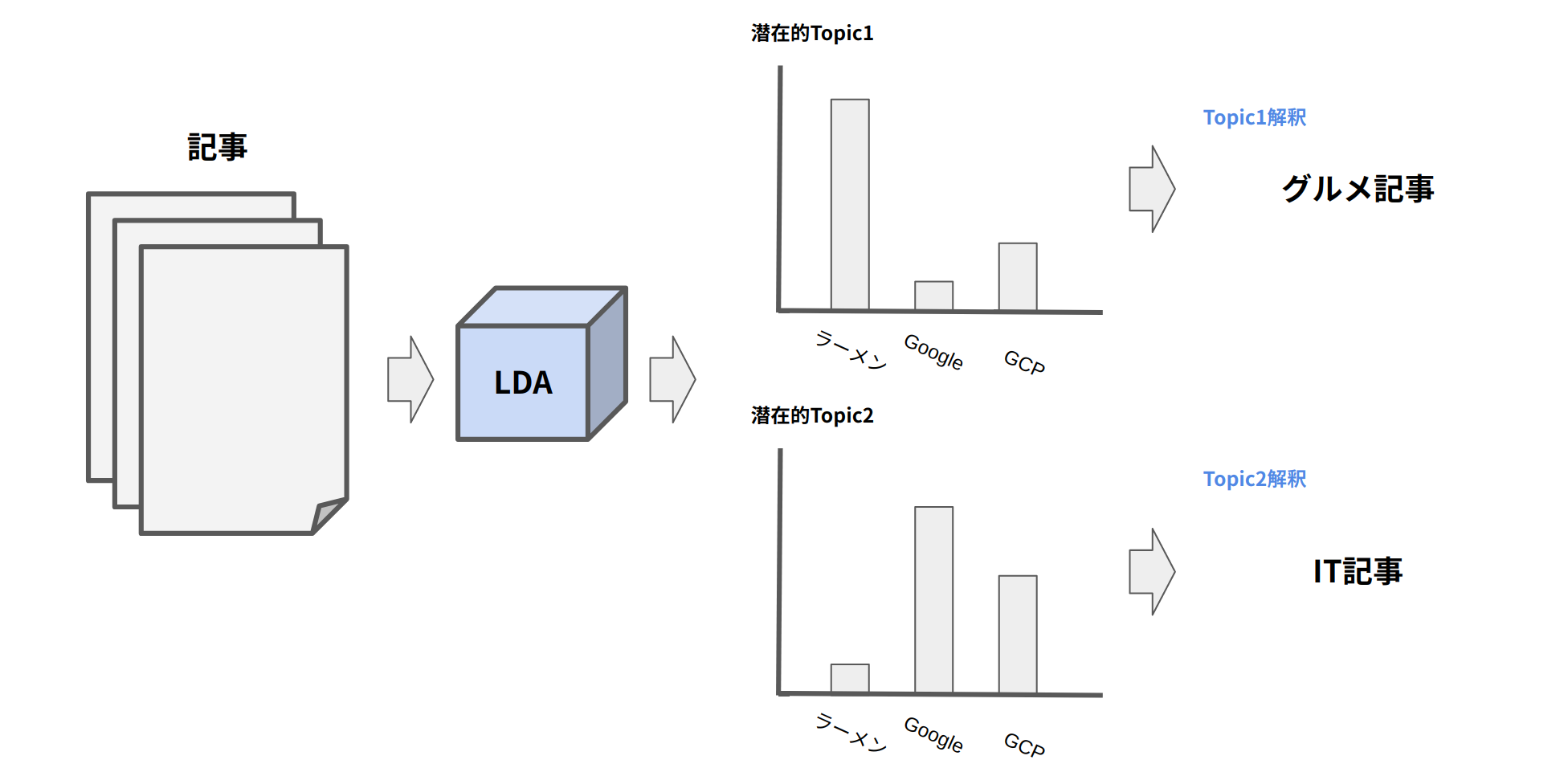
詳しく理解したい方は以下をご確認ください。
検証
「自社のTech blog(GCPの記事)100件」と「グルメサイトの口コミ(ラーメン)100件」のデータを取得し、LDAに入れるとどのような結果が得られるか確認する。
実行環境
- OS : Ubuntu 20.04.3 LTS
- プログラム : Python 3.10.4
- 主要ライブラリ :
- mecab-python3 = 1.0.6
- scikit-learn = 1.0.1
- nlplot = 1.6.0
- gensim = 4.1.2
データの処理
文章データには様々なノイズが存在します。そのため、文章データをモデルへ入力するためには様々な前処理が必要となります。今回は以下の前処理を行います。
- クリーニング
- 形態素解析
- Stop Wordの設定
例として以下の文章がどの様に処理されていくのかを見ていきましょう。
今日はとても外が寒かった〜!(>_<)/。道が凍ってたのでこけちゃった👎でも、イケメンが手を貸してくれたThank you!
クリーニング
口コミや記事を見ると、「記号」や「絵文字」などのトピックの分類に不必要な文字が含まれていることがあります。これらはトピックの分類に関する情報を持たず、モデルの精度を低下させることがあるため、除くことが推奨されます。
文章内の不要な文字は以下が挙げられます。
- 記号
- URL
- 数字
- 文字の表記ブレ
- 絵文字 etc...
今回は正規表現とemojiライブラリを用いてクリーニングを実施します。
コードは以下となります。
(全要件に対応できるわけではないので、処理は作成してください)
import re
import emoji
# クリーニング処理を実行する
def text_normalize(text):
replaced_text = text.lower() # 小文字へ変換
replaced_text = re.sub(r'https?:\/\/.*?[\r\n ]', '', replaced_text) # URLの除去
replaced_text = re.sub(r'[!#$%&*+,-./:>;?@^=_`{|}~"【】<>__~〜()()[]\[\]「」※〔〕→“”〈〉『』&*:、・$#.❯①②③├─└↑○×<■―…~@。,?!`+¥%]', '', replaced_text) # 不要な記号の削除
replaced_text = re.sub(r' ', '', replaced_text) # 全角空白の除去
replaced_text = re.sub(r'\d+', '', replaced_text) # 数字の除去
replaced_text = emoji.replace_emoji(replaced_text, "") # 絵文字の除去
replaced_text = replaced_text.replace('imagepng','') # 自社ブログのデータ取得上、画像部分がimagepngとなるため除去
return replaced_text
結果は以下となります。
不要な記号や絵文字が除かれていることがわかります。
# 処理前
今日はとても外が寒かった〜!(>_<)/。道が凍ってたのでこけちゃった👎でも、イケメンが手を貸してくれたThank you!
# 処理後
今日はとても外が寒かった道が凍ってたのでこけちゃったでもイケメンが手を貸してくれたthank you
クリーニングの参考になりそうなサイトを記載しておきます。
形態素解析
文章分類に不要な情報は「記号」や「絵文字」だけではありません。
例えば、「〜である」の助動詞「ある」です。今回の場合、記事のトピックを分けるための重要な情報ではないことがわかります。そのため、事前にデータから除くことが必要です。
そのためには形態素解析を行い、必要な情報のみを取得する必要があります。一般的に「名詞, 動詞, 形容詞」を取得することが多いです。今回はMeCabを用いて「名詞, 形容詞」を取得します。
コードは以下となります。
import MeCab
# 名詞、形容詞、動詞を抽出
def extract_keyword(text):
tagger = MeCab.Tagger() # ToDo: 辞書のPath記入
tagger.parse('')
node = tagger.parseToNode(text)
word_list = []
while node:
pos = node.feature.split(",")[0]
if pos in ["名詞","形容詞"]: # ToDo: 対象の品詞を入れる
word = node.surface
word_list.append(word)
node = node.next
return " ".join(word_list)
結果は以下となります。
名詞と形容詞が取得されていることがわかります。
# 処理前
今日はとても外が寒かった道が凍ってたのでこけちゃったでもイケメンが手を貸してくれたthank you
# 処理後
今日 外 寒かっ 道 イケメン 手 thank you
MeCabについてはこちらを参照してください。
Stop Wordの設定
意味を持たない情報を除くためにStop Wordを設定します。例えば、「You」や「彼女」などの単語は自然言語処理(NLP)では意味を持たないことが多いとされています。トピックの分けるための情報を持っていないため、これらの単語をStop Wordとしてデータから除きます。
今回はslothlib(日本語)とsklearnのnltkを用いてStop Wordを設定します。
import nltk
# slothlibのStop Word読み込み
# 事前にファイルをダウンロードしてください
file_path = "" # ToDo: slothlibの日本語ファイルPathのPath
with open(file_path) as f:
lines = f.readlines()
slothlib_stop_words = [line.rstrip('\n') for line in lines]
# nltkのStop Word読み込み
nltk.download('stopwords')
stop_words_nltk = nltk.corpus.stopwords.words('english')
# Stop Wordの除去
stop_words_nltk.extend(slothlib_stop_words)
def del_eng_stop_words(text):
words = [w for w in text.split(" ") if not w in stop_words_nltk]
words=' '.join(words)
words = words.split(' ')
return words
結果は以下となります。
Stop Wordに設定されている「今日」や「you」などの単語が省かれていることがわかります。
# 処理前
今日 外 寒かっ 道 イケメン 手 thank you
# 処理後
['今日', '寒かっ', 'イケメン', 'thank']
これにて、今回行う予定の前処理が完了しました!!
データの確認
せっかく、前処理したのでどんな結果になるのか「前処理あり」と「前処理なし」で比べてみましょう!
今回は、可視化ライブラリとして「nlplot」があるのでこちらを使用したします。使用方法は以下を参照してください。
単語の出現数(前処理あり)
実際にデータにおける単語の出現回数を確認してみましょう。
今回使用しているデータは「自社のTech blog(GCPの記事)」と「グルメサイトの口コミ(ラーメン)」となります。
以下の画像は、縦軸が出現単語、横軸が出現回数となります。
考察
- 口コミでは商品名に「麺」の文字が入っていることもあり、100件のデータに対して出現回数が多い
- 自社のTeck blogでは「GCP」と「Google Cloud Platform」などの表記ブレがあり、出現回数がバラけている
- 自社のTeck blogではアカウントや事前の設定などから説明しているため、「設定」や「作成」の出現回数が多い etc...
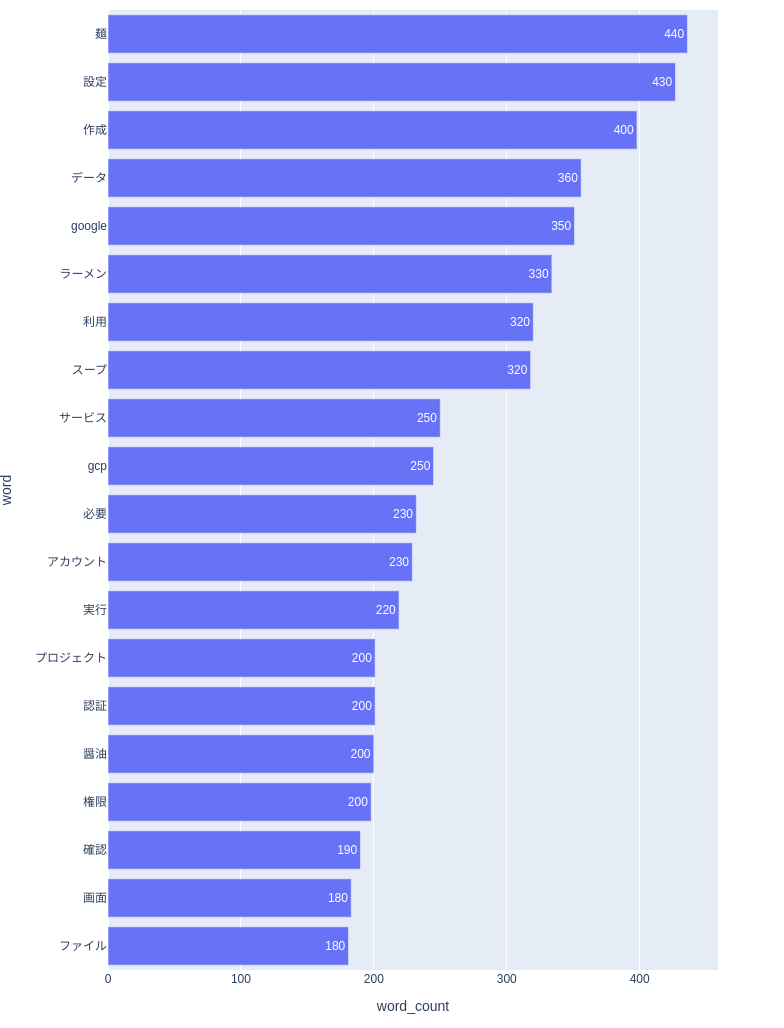
前処理をしたおかげで、記号や数字などの情報が除かれ、必要な情報が取得できています。
なんか、自社のTech blogと他社のTech blogのグラフも見てみたいな。なんて思ったり。
単語の出現数(前処理なし)
では、前処理を行わなかった場合はどうなるでしょうか。
トピックを見分けるための単語「麺」「Google」より、「ます」「た」「です」などのトピックに関連する情報を持たない単語が頻出となっています。
人間がグラフを見てもわかりにくいのでは無いでしょうか?これらの処理されていないデータをモデルに入力すると、不必要な情報から予測を計算することになり、精度が低下する場合があります。
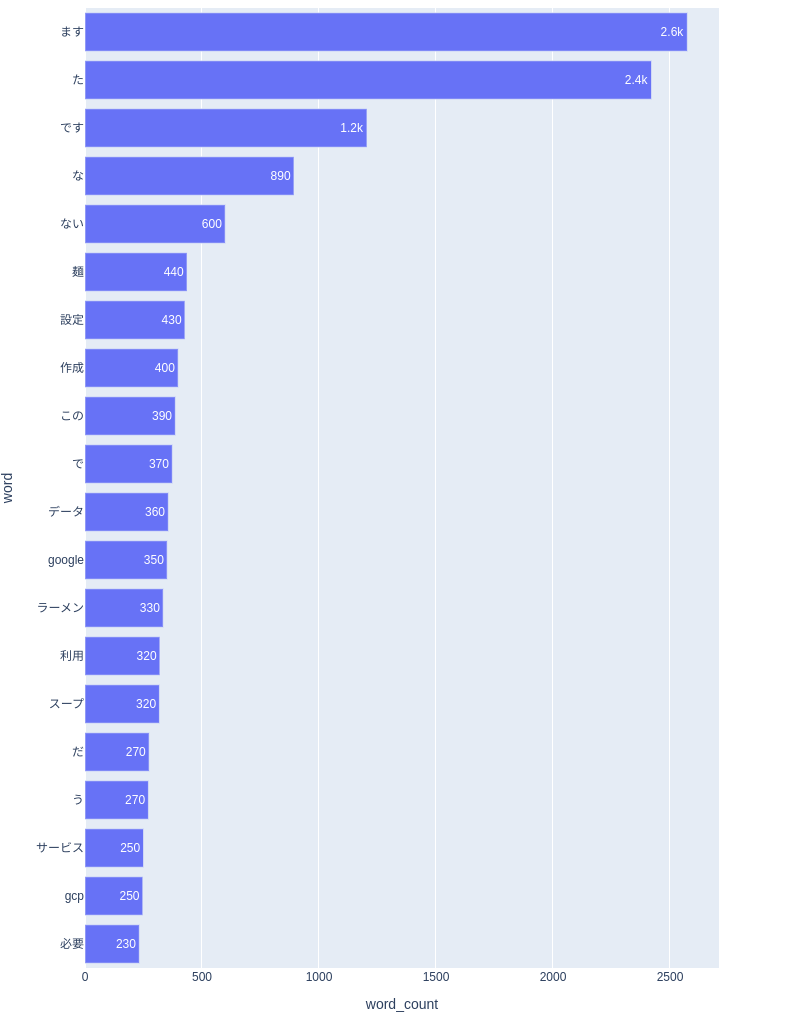
まとめ
今回はLDAを使うための前処理について、ご紹介しました。
Pythonでは様々なライブラリが備わっており、簡単に処理できます。
次回は実際にモデルを使った結果を記載します!
GCPに関係ない記事ですが、自社のBlogが少しでも良くなるようになにか関われないかなとも考えてます。
そういえば、検索バーもないな。改善点は色々ありそうです!!ではでは!良い年を!!