データベースの正規化
いろーんな書籍やサイトでこすられまくってるデータベースの正規化という話題。しかし意外にも良い具体例が上がっているサイトが見当たらないなぁって思いまして、ポートフォリオ作成とかで困っている人の一助になればと記事を書きました。
この記事の対象者
以下に当てはまる人にはちょうどよさそうな記事になってる気がします、
- ポートフォリオ作ろうと思ってるけど、システムで使用するデータの正規化に困ってる人
- なんとなくで正規化を行ってきた人
- 今までDBの正規化をやったことがない人
はい、要は初心者向けです![]() 慣れてる人は見てもつまらないと思います
慣れてる人は見てもつまらないと思います![]()
ついでに、厳密な用語の定義とかいいから、俺はとにかく正規化したいンだァ! って人にもおすすめかなって思います。
記事の流れ
この記事では「スーパーのレシートの正規化」を例に、1STEPずつ正規化を行っていきます。これは現状を起点に設計を行うボトムアップ アプローチな設計です。
よくある第1正規化~第3正規化までに加えて、トランザクション系・マスタ系テーブルの観点から見たインデックスの設定も行います。
いずれはやりたいことから設計を行うトップダウンな方法も記事にしたいと思ってます。
早速正規化を!
「第一正規化とは非正規系の表を~」とか...論文かよ!ってツッコみたくなる講釈は Wiki にでも垂れさせときましょ。技術者としてはとにかく使える技能・技術が欲しいんですよ。そっちの方が涎も垂れるってもんです ![]()
というわけで正規化やっていきます。
スーパーのレシートの正規化
まずは「スーパーのレシート」を正規化します。お手元にレシートをご準備ください。ではやっていきましょう。
第一正規化
この後の第二正規化とかより、ぶっちぎりで第一正規化が大事です。ここで正規化の成否が決まるレベルです。
やることその1 とにかく表を作る
最初にやることは「とにかく表を作る」ことです。わけわからんですよね。やってみたらわかるかもです。
「とにかく表を作る」段階では、正規化したいデータが集まった一つの集合を、ただ書き並べる作業を行います。
正規化したいデータが集まった一つの集合とは、ここでは「レシート1枚」を指します。レシート1枚に書かれた情報をとにかく横に列挙して、2枚目があるなら次の行に列挙して。3枚もあるならさらに次の行に列挙して。
ではやっていきます。レシートに目をやると、レシートナンバーなるものが書いてありますね。ではこれを書きます。記念すべき一つ目のデータです。(一つ目とか言ってるけど、順不同です。好きな順番で書いてください)
| レシートNo |
|---|
| 8945 |
さらにお店の名前が書いてあります。レシートを発行した店の名前ですね。二つ目のデータを列挙します。
| レシートNo | 店舗名 |
|---|---|
| 8945 | ヤオコー |
支店名とか、電話番号とか、事業所番号とか、購入日とか、買った商品とか、なんかめっちゃたくさんデータが見つかりますね。これもガンガン列挙していくのですが必ず意識したいのは
横1行に、レシート1枚が持っている情報量と同じだけの情報量を持たせる!!
ってことです。慣れるまではこれを常に意識しましょう。慣れてくれば「要件的に不要な情報」、「RDB的に不要な情報」が何かわかるようになります。
というわけで列挙した結果がこれです。

(それレシートのデータ足りないよ!っていう人もいるかもですが勘弁してください。泣く泣くちょっと省いてます。まぁワイの世界のレシートはこんなデータしかなかったんですよってことで納得してください。)
とんでもなく横に長くなりますか?じゃあこんな工夫もありですね。

この調子で2枚目、3枚目、4枚目...とレシートの内容を列挙していきます。

「とにかく表を作る」段階では横1行にレシート1枚分のデータを入れるので、4枚のレシートがサンプルとして手元にあるなら、横4行の表が出来上がります。
... ... いやいや、だまされてはいけません。出来上がりの上画像の表は1+4で5行になってます。表の一番上の行は一般に「見出し」とか「表頭」と呼ばれます。見出しにはその下に来るデータがなんであるかを完結に表現した文字列が入ります。
さりげなくやっていましたが、表見出しを付ける作業もここでやっておくべきです。見出しの文字列はだれが見ても伝わるように決めましょう。
ちょい発展的な内容含む雑談チックな折り畳み
【見出しの文字列の重要性】
DBの設計は大きく3段階に分かれます。
要件定義の段階 ... 概念設計:DBで管理すべきデータの決定
外部設計の段階 ... 論理設計:主キーの決定、テーブルの正規化
内部設計の段階 ... 物理設計:DBMS、物理名(テーブル名、列名)、型・制約の決定
現状を起点にDBの設計を行う(ボトムアップ・アプローチの)場合、概念設計が不要です(どんなデータを扱うか決まってるので)。なのでいきなり正規化をやってますが、正規化はDBの論理設計段階でやることであり、DBの論理設計は開発段階における外部設計で行います。
開発工程において、外部設計の段階はクライアントにもレビューしてもらうことが一般的です。クライアントはプログラマじゃないかもしれません。今作っている表の見出しは、後にテーブルのカラム名として使用します。プログラマじゃなくても、たとえだれが見てもすぐに「そういう意味ね!」ってわかるような名前を付けるのが、この段階ではもっともスマートなやり方です。
とにかく表を作ることができました。最初に作る表は「横1行にレシート1枚の情報」が格納されていればどんな形でも問題ありません。(セル結合してたら横1行って表現微妙かも...)
やることその2 横に伸びない表にする! + スカラ化!
とにかく表を作ることができましたが、これは非常に扱いづらいです。なんで扱いづらいのかを明確にしていきます。
- 横に項目を並べた表
この表の問題点は、新しいレシートのデータを追加したときに 縦にも横にも伸びる可能性がある という部分です。
例えば商品を100種類買った場合、横に 品物5, 品物6, ..., 品物99, 品物100 と伸びていきます。普通に使いづらい。削除するときも大変そう。
新しいデータを追加したとき、必ず縦にしか伸びない表である ようにすると、データの管理がしやすそうですね。
- 1つのセルに複数のデータが入った表
これはなんかもう見た目でダメそうって感じますね。人間が見たら、「150円以上の商品は?」って聞かれてもこの表から答えられそうですが、プログラムでやるには少々骨が折れそうです。データの追加も「ア!カンマの位置間違えちゃった!」みたいな事態に陥りそう...。
(加えて主キーの原則に違反するってのがあるんですが、現状はどうでもいいです)
1つのセルには1つのデータしか入れてはいけない とすると、これまたデータ管理しやすそうですね。
そして、どちらの表にも共通して言えるのが「計算で出せる項目が表にあるのは使いづらい」って部分です。暗算で打ち間違えたら困りものですからね。合計金額が欲しいなら合計金額を計算するプログラムを書けばよいのです。
今作った表は扱いづらい!というわけで、作成した表を3つのルールの元で変形します。
1. データが追加された場合、表は必ず縦にのみ伸びる(削除の際、表は縦にのみ縮む)
2. 1つのセルには1つのデータしか入れてはいけない(スカラ値の原則)
3. 計算によって導出可能な項目は、基本的に表に入れない
この3つのルールの元で表を変形させると、必ず次の形になります。(一番左に「レシート1」って書いてありますが、わかりやすくするための表示で表とは無関係です)

この調子でほかのレシートのデータも入れていきます。

これが第一正規化を実施してできた「第一正規形の表」です。ここらでいったん用語を整理します。
まず、元の表(「とにかく表をつくる」で作った表)の形を、非正規形 と言います。扱いづらいのが非正規形。
対して、3つのルールのもと作成した上の表の形を、第一正規形 と言います。
非正規形だろうが、第一正規形だろうが、 情報の損失がない というのが非常に重要です。
この後で第二正規形や第三正規形に表の形を変形していきますが、常に情報の損失を生まないようにするのが大事です。
ついでに、今後は下図のような名称で各箇所を呼称します。
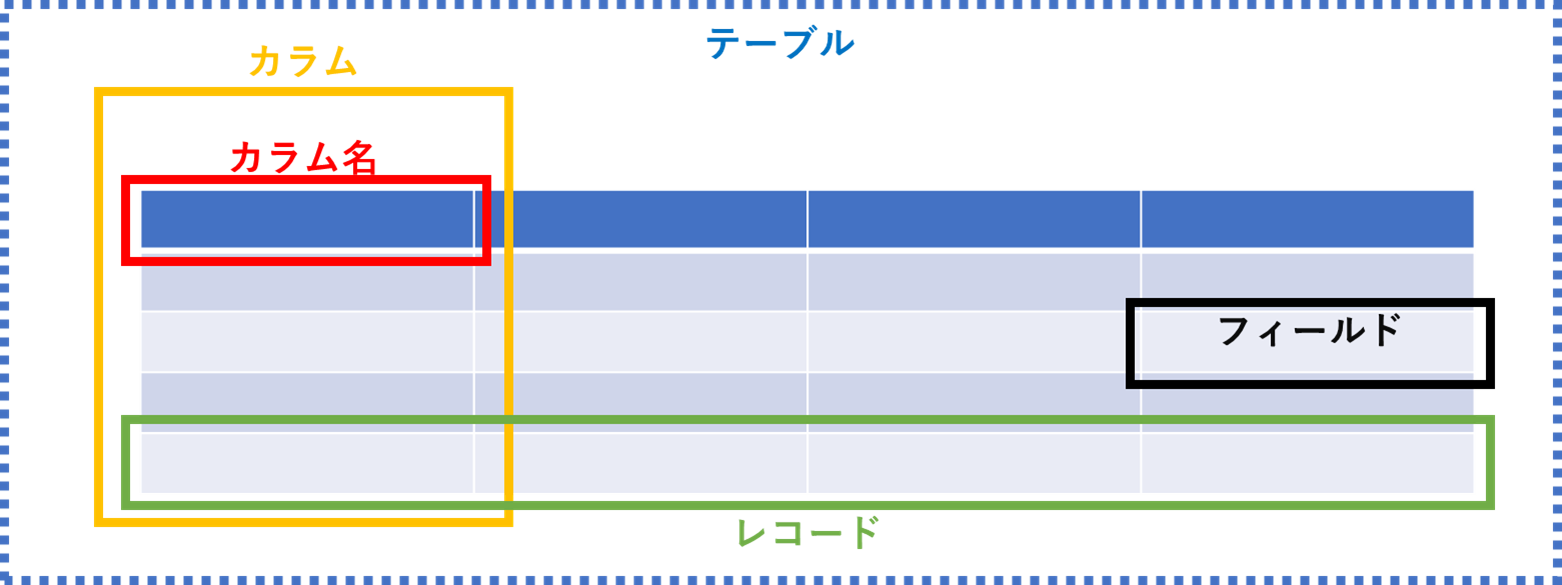
- 表 -> テーブル
- 横1行 -> レコード
- 縦1行 -> カラム
- 1つ分のセル -> フィールド
- 見出し名 -> カラム名
先ほど作ったテーブルをレシートテーブルと名付けます。
やることその3 1レコードを特定できるカラム名を列挙
1レコードを特定するのに必要なカラム名を 主キー(Primary Key) と言います。多くの場合、第一正規形のテーブルでは複数の主キーを指定する必要があります(主キーが複数ある場合、複合主キー と呼ばれます)。
主キーには、
- フィールドが空であってはならない(Not Null であること)
- 重複してはならない(UNIQUE であること)
という制約があります。カッコ内は覚えなくてもいいです。
今後主キーになるカラム名は黄色でハイライトします。ではこれから主キーを見つけていきます。用語の説明もかねて下記の手順で見つけていきましょう。
-
スーパーキーを(できるだけ)列挙する
スーパーキーとは、「1レコードを特定できるカラム名の集まり」のすべて のことです。主キーと似たような説明ですが、決定的に違うのは 1レコードを特定できるならなんでもいい! のがスーパーキーです。
今回のレシートテーブルを再度見てみます。
1レコードを特定できるカラム名の組はどれでしょうか?まず第一に思い浮かぶのが、「全カラム」ですね。全カラムを見れば、当然1レコード特定できます。もし全カラムを見ても特定できない場合、まったく同じレコードが複数あることになるので重複しているレコードは削除しましょう。
ほかにも、購入数 カラム以外の全てもスーパーキーです。ほかにも...ほかにも...
スーパーキーをすべて列挙するのは超大変です。結論から言えば、このテーブルには 4096 通りのスーパーキーがあるからです。
スーパーキーを探すときはなるべく少ないキーを指定しましょう。例えば今回の場合は、レシートNo と 品物 あたりが良さそうです。
指定したカラムの集合がスーパーキーとなりえるかどうかは、他にもサンプルデータをいくつか入れてみて、矛盾がないことを確かめる必要があります。
サンプルデータを追加して矛盾が見つかったら、指定したカラムの集合はスーパーキーとして不適当なのでさらにカラムを追加します。
実際にやってみましょう。テーブルを見てパッとみで「レシートNo と 品物 はスーパーキーだ!」と思ったとします。
ここで次のサンプルデータを考えます。

こちらのサンプルは 違う店舗であればレシートNoが被る可能性がある ことを示してくれています。このサンプルが表に入った場合、「レシートNo = 8945」「品物 = ナンプラー」で2つのレコードがヒットすることになり、1つのレコードを特定することができていません。
というわけでここで、「やっぱり レシートNo と 品物 と 事業所番号 がスーパーキーだ!」ってなるわけですね。
当然、 レシートNo と 品物 と 事業所番号 がスーパーキーなら、そこに 金額 カラムを追加したものも、購入時刻 を追加したものもスーパーキーです。(3つのカラムで1レコード特定できるなら、その3つのカラムを含む4つのカラムでももちろん1レコード特定できる)
-
候補キーを列挙する
候補キーとは、数あるスーパーキーのうち、既約なものを指します。
既約というのは「スーパーキーから一つでもカラムをのぞいたらスーパーキーではなくなるもの」を指します。
スーパーキーを探すときに、なるべく少ないキーから探していた場合はすぐに見つかると思います。今回の候補キーは-
レシートNo、品物、事業所番号 -
レシートNo、品物、電話番号
-
あたりかなって思います。
- 主キーを選ぶ
候補キーの中から主キーを選択します。一応今回は「レシートNo、品物、事業所番号」を主キーとして採用します。なんでこっちを主キーに採用したかですが、電話番号を持たない事業所もあるかもしれないからですね。主キーは Not Null でなければならない!
というわけで主キーに黄色ハイライトを入れた第一正規形の最終版がこちらです。

本当にこれでいいの...??? という疑問はごもっともです。主キーの選び方が一意じゃないことから不安に思う人もいると思います。
実際にこれでいいかどうかは テストデータを使って、テーブルにデータを追加・削除・更新が問題なくできるかどうか で判断します。
どこかからテスト用のレシートを持ってきて、データを追加してみましょう。また、主キーを指定して削除・更新してみましょう。それができればOKです。
第二正規化
第一正規化ができたら後は楽勝です。第二正規化を行います。第二正規化ではテーブルの分割が行われます。非常に機械的な作業になります。
やること 複合主キーの一部に依存する項目を探す
第一正規化が終わったテーブルを見て、まず複合主キーが(主キーが複数)あるかどうか調べます。もし第一正規化が終わったテーブルに主キーが一つなら、第二正規化を行う必要はありません。
主キーが複数ある場合、そのうちの一部で決まるものがないか探します。
今回の主キーは レシートNo、 品物、 事業所番号 の3つです。これの一部に依存しているカラムを洗い出します。一つずつ機械的に行いましょう。
-
レシートNoにのみ依存するカラム
レシートNoだけで特定できるカラムはありません。 -
品物にのみ依存するカラム
品物だけで特定できるカラムはありません。 -
事業所番号にのみ依存するカラム
事業所番号がわかれば、登録されている事業所名(購入店、支店名)と電話番号がわかります。これは事業所番号という主キーで購入店、支店名、電話番号があるレコードを特定できるということなので、次のテーブルを作成できます。これを事業所テーブルと名付けます。

-
レシートNo、品物に依存するカラム
レシートNo、品物だけで特定できるカラムはありません。 -
レシートNo、事業所番号に依存するカラム
レシートNo、事業所番号がわかれば、いつ(購入日、購入時刻)どのレジで(購入レジ)、だれがそのレジをたたいたか(担当者、役職)がわかります。これはレシートNo、事業所番号という主キーで、購入日、購入時刻、購入レジ、担当者、役職があるレコードを特定できるということなので次のテーブルを作成できます。これをレシート明細テーブルと名付けます。

-
品物、事業所番号に依存するカラム
品物、事業所番号がわかれば、その事業所で売られている品物の金額がわかります。同じ要領で次のテーブルを作成することができます。これを商品単価テーブルと名付けます。

ここまで出来たら、元のレシートテーブルから、事業所テーブル、レシート明細テーブル、商品単価テーブルで参照しているデータを抜き取ります。

以上で第二正規化は終了です。簡単ですね![]()
第三正規化
これで最後です。今度は非キー列(主キーじゃないカラム)に着目します。
やること 非キー列を見て、実は主キーに依存してないやつを探す
これまでに作成したテーブルを、主キー列をグレーアウトして下に表示します。

ここからやりたいのは、非キー列に依存した非キー列の洗い出しです。具体的に非キー列を一つずつ見ていきます。
- レシートテーブル
購入数は、どのお店でどんな商品をどのレシートに記載されたものかわからないといけないので、主キー(レシートNo、品物、事業所番号)で決定されます。 - 商品単価テーブル
金額はどのお店のどんな商品についての金額なのかわからないといけないので、主キー(事業所番号、品物)で決定されます。 - 事業所テーブル
購入店、支店名、電話番号は主キー(事業所番号)で決定されます。 - レシート明細テーブル
購入日、購入時刻、購入レジ、担当者はどのお店のどのレシートに記載されたものかわからないといけないので主キー(レシートNo、事業所番号)で決定されます。
役職はお店とそこで働く人がわかれば決定されます(事業所番号、担当者で決定される)。
これをテーブルにすると次のようになります。従業員テーブルと名付けます。

レシート明細テーブルからは 役職 カラムを除いておきます。これで第三正規化は終了です。

マスタ系・トランザクション系
テーブルは、頻繁にデータの更新作業(追加・削除・更新)を行うものと、辞書のような使い方をして検索がメインで行われるものの2種類に大別できます。
-
マスタ系テーブル
検索(SELECT文)がメインで行われるテーブル。辞書みたいに使われる。 -
トランザクション系テーブル
データの更新作業(INSERT、DELETE、UPDATE)がメインで行われるテーブル。
やること マスタ系・トランザクション系にテーブルを分類する
マスタ系テーブルとトランザクション系テーブルの見分け方ですが、これは実際の運用を考えるとわかりやすいです。
今はレシートの情報を管理するテーブルを作成しています。どんなシステムに利用されるかわかりませんが、まず間違いなく、運用の際には ガンガンレシートが追加されていくことでしょう。
本来は実際にサンプルデータを挿入してみるとわかりやすいですが、ちょっと疲れてるのでここはイメージでいきます。
またお買い物してレシートが発行されました!さて、レシートテーブルとレシート明細テーブルにはガツンとデータが追加されます。ほかのテーブルは今まで行ったことないお店の時や、今まで担当されたことのない店員さんの時だけデータを追加しますね。商品単価はものによりますが、それでもレシートデータの追加よりは値段の更新が少ないと思います。
それこそ、20年も運用したら事業所テーブルとかほぼ変わらなくなりそうですね。
というわけで、下記のように分類されると考えてよいでしょう。
- マスタ系 ... 事業所テーブル、従業員テーブル、商品単価テーブル
- トランザクション系 ... レシートテーブル、レシート明細テーブル
なぜこんな分類を行うかというと、インデックス の設定を行うためです。
インデックスとは辞書についてる索引みたいなもので、マスタ系テーブルの主キーになります。「事業所テーブルとかすでに主キーあるよ!」って声も聞こえそうですが、主キーが文字列だと以下の問題が発生します。
- 問題その1 ヒューマンエラー
トランザクション系テーブルは、マスタ系テーブルの主キーを参照して、追加・削除・更新を頻繁に行います。主キーが文字列だと打ち間違いのリスクにさらされます。
例えば実際に発行するSQL文で
INSERT INTO レシートテーブル VALUES ('8945', 'T4030001055XXX', 'レタス', 3);
みたいな感じになります。これはヒューマンエラー発生不可避![]()
- 問題その2 検索速度
これは問題点というよりインデックスをつけるメリットという見方の方が正しいのですが、インデックスが付与されたテーブルの検索を行う場合、検索速度の向上が見込まれます。
(特に WHERE 句、ORDER BY 句、JOIN の結合条件あたりで効果を発揮します。)
非常に優秀なインデックスという概念ですが、デメリットも存在します。
(主に、インデックスという新しいカラムを定義するのでディスク容量を消費してしまうのと、追加・削除・更新を行うと面倒なことになるという2点です)
インデックスをつける場合は必ず マスタ系テーブルにのみつける ように注意しましょう。
では実際にインデックスを付与していきます。基本的には主キーの数が少ないマスタ系テーブルからやっていくといいかなって思います。
まず事業所テーブルから。

インデックスはテーブルの新たな主キーとなります。これは人工的に作るキーなので人工キーとも呼ばれます。もともとの主キーはナチュラルな主キーで自然キーとか言われます。
残る従業員テーブル、商品単価テーブルでも同じくインデックスを付与していきます。このとき、事業所番号 カラムは 事業所ID カラムに置き換えます。
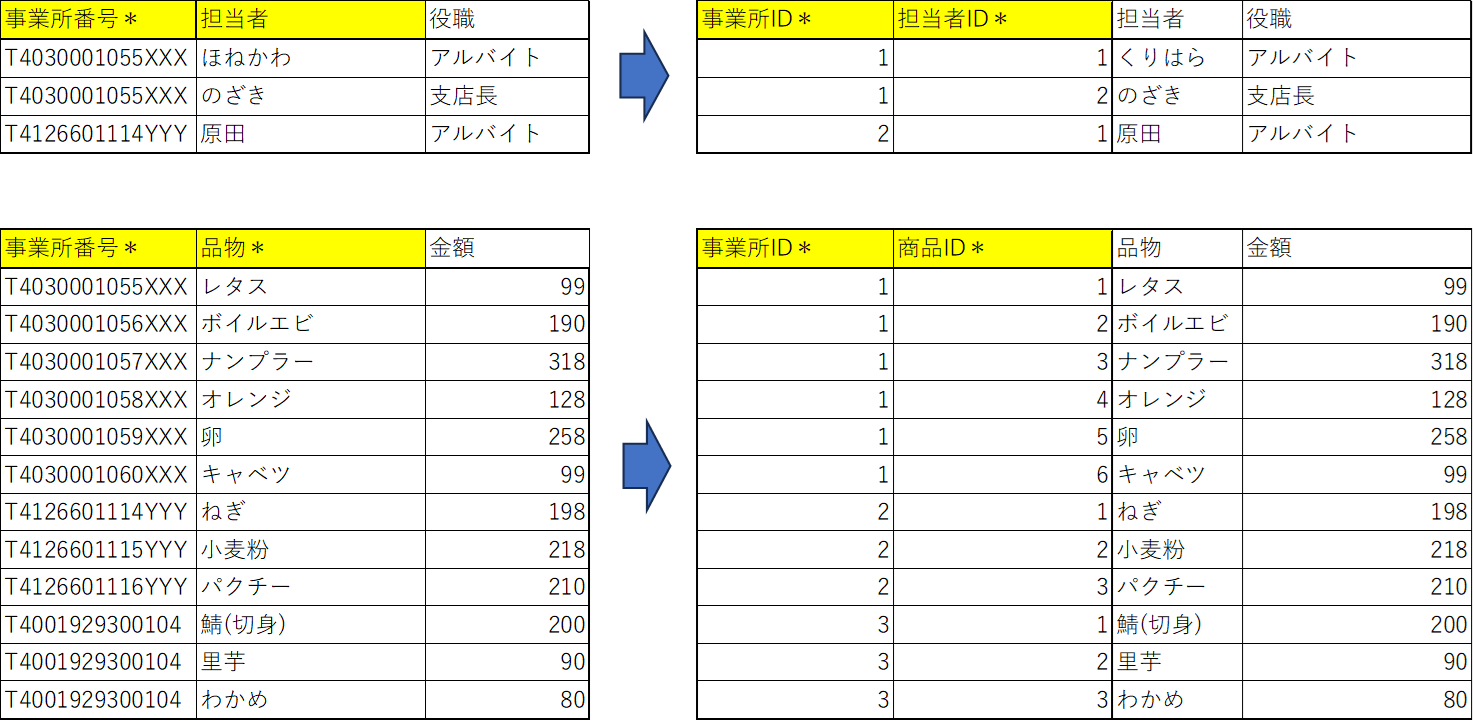
マスタ系テーブルは上記の3つですべてなので、これでインデックスの付与が完了です。インデックスの付与によって主キーが変更されたので、それに合わせてレシートテーブル、レシート明細テーブルのカラムも変更します。
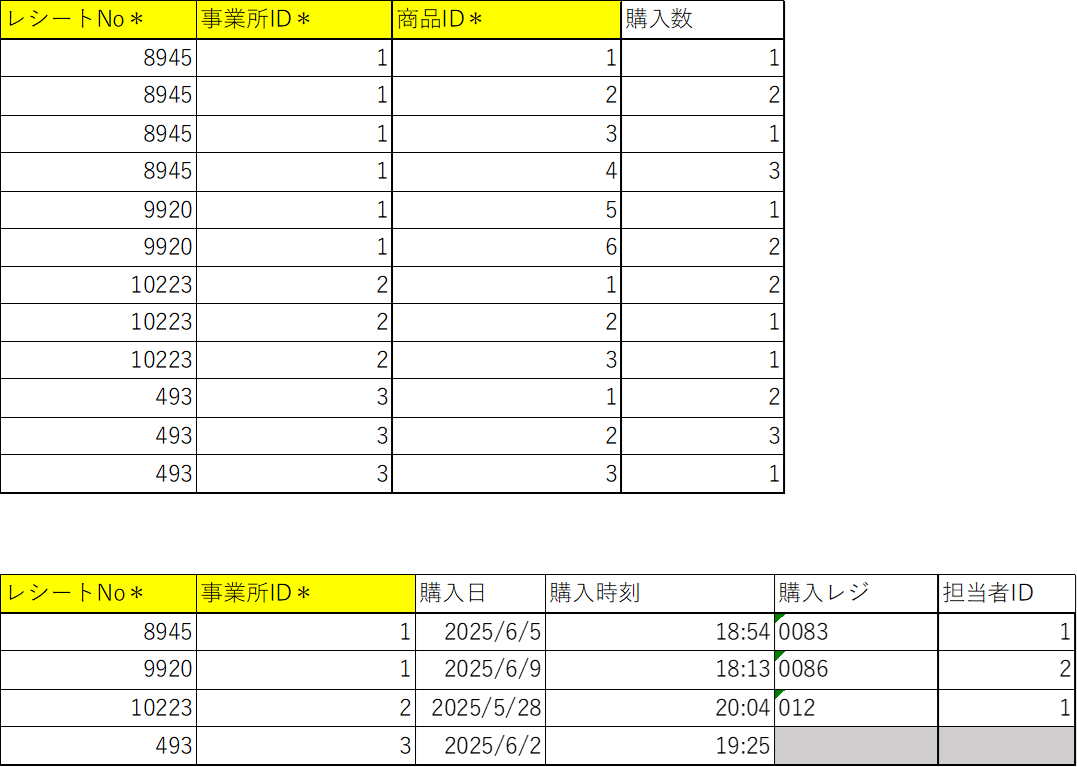
おわりぃ!!![]()