この記事は情報検索・検索技術 Advent Calendar 2024の9日目の記事です。
はじめに
LLMやRAGが最近注目され、情報検索に埋め込み表現を用いたベクトル検索や全文検索とベクトル検索を組み合わせたハイブリッド検索を活用する事例が多く見られるようになりました。
特に、Azure AI SearchとAzure OpenAIを使うことで、簡単にハイブリッド検索を活用できるようになっています。
Azure Cognitive Search のベクトル検索とハイブリッド検索をデモ UI に追加
ハイブリッド検索の概要

この記事では、あえてOpenAIやGemini、LangChainなどを使わずに、HuggingFace Hubにあるモデルや近似最近傍探索ライブラリなどを使ってスクラッチでハイブリッド検索を簡単に実装してみます。
今回実装したものは、こちらのリポジトリにアップしています。
Shakshi3104/cobalt-hybird-search
また、Gradioを用いて作成したデモアプリをHugging Face Spaceにアップしています。
Shakshi3104/Cobalt
使用するモデルやライブラリ
今回は以下のモデルやライブラリを使用してハイブリッド検索を実装します。
Ruri: Japanese General Text Embeddings
Ruriは、日本語に特化した埋め込みモデルで、2024年9月に発表されたモデルです。埋め込みモデルとリランクモデルがHuggingFace Hubで公開されています。
今回は、パラメータ数が337Mのruri-largeを使用します。
Ruriについては、こちらの記事を参考にしました。
日本語の高性能な文埋め込みモデルを試す
また、情報検索・検索技術 Advent Calendar 2024の6日目でもRuriの解説が詳しくされていたので、こちらも読んでみてください。
Ruri: 日本語に特化した汎用テキスト埋め込みモデル
Voyager
VoyagerはSpotifyが開発した近似最近傍探索ライブラリです。同じくSpotifyが開発したAnnoyと比べて10倍速く、4倍メモリ消費量が少ないらしいです。
Voyagerについては、こちらの記事を参考にしました。
近似最近傍探索ライブラリVoyagerで類似単語検索を試す
BM25
BM25は情報検索における順位付けの手法です。単語の出現頻度に基づいて、文章の順位付けを行うアルゴリズムで、tf-idfの進化系と言われています。
今回は、rank_bm25を使っています。
ハイブリッド検索を実装する
全文検索
Elasticsearchなどの検索エンジンと同様にBM25を使用した検索を実装します。
rank_bm25を使って実装する場合は、以下のようにベースのクラスを継承したクラスを作成します。
class BM25Wrapper(BM25Okapi):
def __init__(self, dataset: pd.DataFrame, target, tokenizer=None, k1=1.5, b=0.75, epsilon=0.25):
self.k1 = k1
self.b = b
self.epsilon = epsilon
self.dataset = dataset
corpus = dataset[target].values.tolist()
super().__init__(corpus, tokenizer)
def get_top_n(self, query, documents, n=5):
assert self.corpus_size == len(documents), "The documents given don't match the index corpus!"
scores = self.get_scores(query)
top_n = np.argsort(scores)[::-1][:n]
result = deepcopy(self.dataset.iloc[top_n])
result["score"] = scores[top_n]
return result
全文検索は、単語の頻出度合いで類似度を検索するため、検索クエリや検索対象のドキュメントに対してわかち書きをする必要があります。今回は、MeCabを使用しました。
# 検索対象のドキュメント
df = pd.read_csv("corpus.csv")
# contentが検索対象のカラム
search_field = df["content"].values.tolist()
# MeCab
parser = MeCab.Tagger("-Owakati")
# わかち書きをする
tokenized = []
for t in search_field:
tokenized.append(parser.parse(t).split())
df["tokenized"] = tokenized
わかち書きした文章をもとに、先ほど実装したクラスを初期化します。
# tokenizedがわかち書きした検索対象の文章
bm25 = BM25Wrapper(df, "tokenized")
実際に検索をする場合は以下のようなコードで実行できます。
# 検索文
query = "日本の首都"
# 検索文のわかち書き
query_tokenized = parser.parse(t).split()
# 検索: 上位10件を検索する
result = bm25.get_top_n(query_tokenized, df, 10)
詳細な実装はsurface.pyを読んでみてください。
ベクトル検索
ベクトル検索は、埋め込みモデルを使ったベクトル化とベクトル同士の類似度算出の2つの要素から成り立ちます。
Ruriによるベクトル化をする場合は、シンプルには以下のように書きます。
埋め込みモデルとしてRuriを使用する場合、テキストに対して検索クエリの場合は「クエリ: 」、文書の場合は「文書: 」と頭につける必要があるそうです。
model = st.SentenceTransformer("cl-nagoya/ruri-large")
# 検索クエリの場合
text = "日本の首都"
embedding = model.encode(f"クエリ: {text}")
検索文書はベクトル化をした後にVoyagerのIndexを作成する必要があります。
# 検索文書には「文書: 」と頭につける
search_fields = [f"文書: {text}" for text in df["content"].values.tolist()]
# ベクトル化
embeddings = model.encode(search_fields)
# 埋め込みベクトルの次元
num_dim = embeddings.shape[1]
# Voyagerのインデックスを初期化
# 類似度指標はコサイン類似度
index = voyager.Index(voyager.Space.Cosine, num_dimensions=num_dim)
# indexにベクトルを追加
_ = index.add_items(embeddings)
これで準備ができました。検索をする場合は、以下のようなコードを実行します。
# 検索クエリには「クエリ: 」と頭につける
text = "日本の首都"
embedding = model.encode(f"クエリ: {text}")
# Voyagerのインデックスを探索
# Voyagerは類似度が高い順にインデックスを返す
neighbors_indices, distances = index.query(embeddings_query, k=10)
result = df.iloc[neighbors_indices]
詳細な実装はvector.pyを読んでみてください。
RRF
ハイブリッド検索は、ベクトル検索と全文検索の結果を融合する必要があります。そのとき使用されるのがRRF (Reciprocal Rank Fusion)というアルゴリズムです。これは、Azure AI Searchでも使用されています。
これは、単純にそれぞれの検索結果の順位をもとにスコアを計算するようなアルゴリズムです。RRFは以下のような定義です。
RRF(d)=\sum_{i=1}^n \frac{1}{k+r_i(d)}
ここで、
- $d$: 検索結果のドキュメント
- $n$: 融合する検索結果の数 (= 検索アルゴリズムの数)
- $r_i(d)$: $i$番目の検索結果における$d$の順位
- k: RRFのパラメータ
です。全文検索とベクトル検索の2つを融合する場合は、$n=2$ となります。
今回は、以下のような関数を実装し、RRFスコアを計算するようにしました。
def reciprocal_rank_fusion(sparse: pd.DataFrame, dense: pd.DataFrame, k=60) -> pd.DataFrame:
"""
Reciprocal Rank Fusionを計算する
Parameters
----------
sparse:
pd.DataFrame, 表層検索の検索結果
dense:
pd.DataFrame, ベクトル検索の結果
k:
int,
Returns
-------
rank_results:
pd.DataFrame, RRFによるリランク結果
"""
# カラム名を変更
sparse = sparse.rename(columns={"rank": "rank_sparse"})
dense = dense.rename(columns={"rank": "rank_dense"})
# denseはランク以外を落として結合する
dense_ = dense["rank_dense"]
# 順位を1からスタートするようにする
sparse["rank_sparse"] += 1
dense_ += 1
# 文書のインデックスをキーに結合する
rank_results = pd.merge(sparse, dense_, how="left", left_index=True, right_index=True)
# RRFスコアの計算
rank_results["rrf_score"] = 1 / (rank_results["rank_dense"] + k) + 1 / (rank_results["rank_sparse"] + k)
# RRFスコアのスコアが大きい順にソート
rank_results = rank_results.sort_values(["rrf_score"], ascending=False)
rank_results["rank"] = deepcopy(rank_results.reset_index()).index
return rank_results
全文検索とベクトル検索の結果に対して、上記の関数でRRFスコアを算出し最終的な検索結果としています。
詳細な実装は、hybird.pyを読んでみてください。
GradioでUIをつけてみた
前のセクションでいわゆるバックエンドを実装したので、見た目でわかりやすくするためにUIをつけてみました。
今回使用したのはGradioです。Gradioは、Pythonで簡単にWebアプリが作れるライブラリです。似たようなライブラリにStreamlitがあり、そちらは使用したことがありましたが、Gradioは今回初めて触りました。こちらの記事を参考に実装しています。
AIモデルの予測結果の可視化を楽にしたい? Gradioを使ってみよう!
今回は、簡単に検索クエリを入力するテキストボックスと、検索結果を表示するテーブルがあるようなUIになっています。HuggingFace Spaceにアップしたものはこちら: Shakshi3104/Cobalt
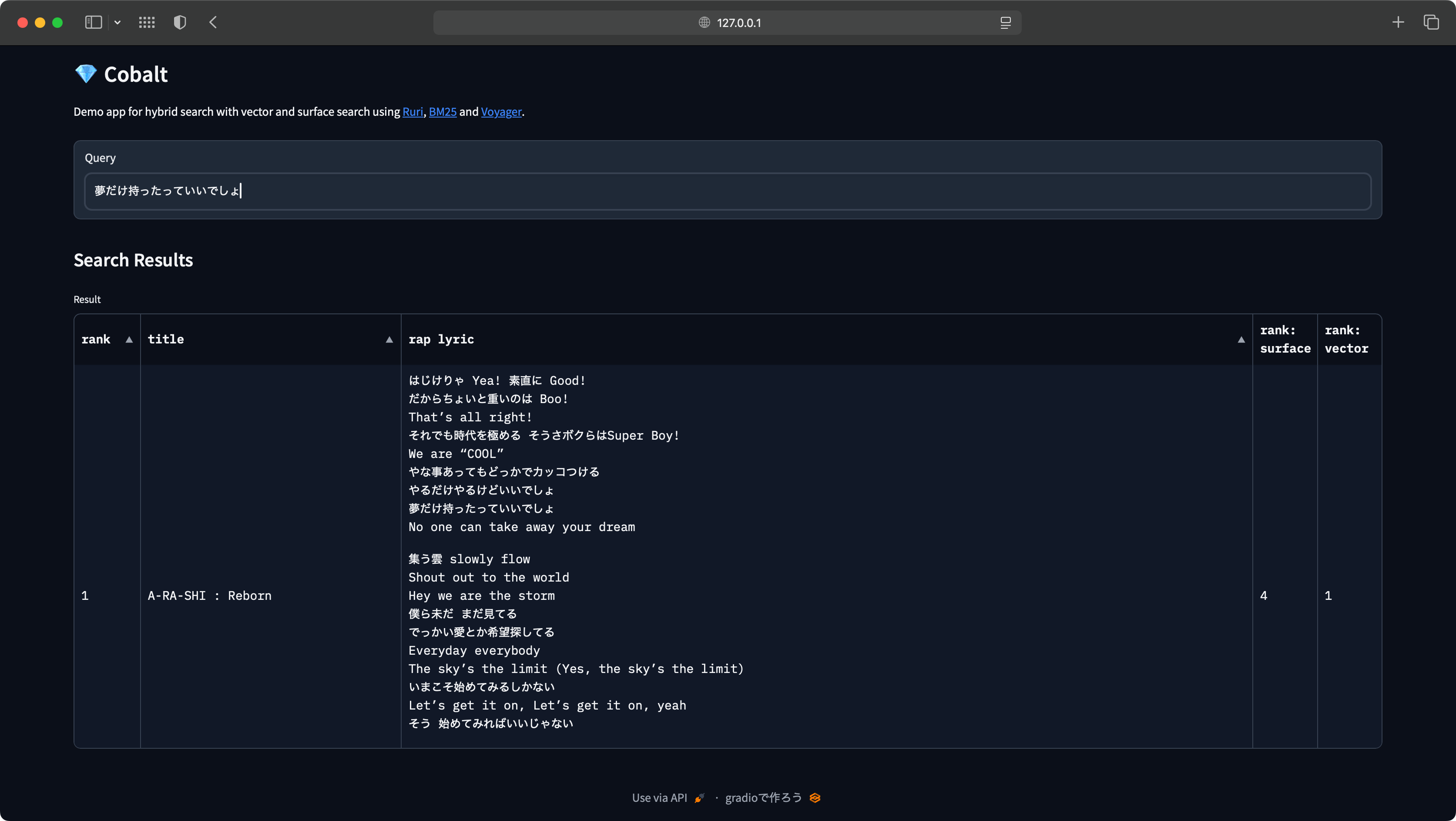
このUIは以下のようなコードで実装できます。
import gradio as gr
with gr.Blocks() as search_interface:
gr.Markdown("""
# 💎 Cobalt
""")
# Input query
search_query = gr.Textbox(label="Query", submit_btn=True)
gr.Markdown("""
## Search Results
""")
# Search result
result_table = gr.DataFrame(label="Result")
# Event handler
search_query.submit(fn=search(), inputs=search_query, outputs=result_table)
# App launch
search_interface.queue()
search_interface.launch(server_name="0.0.0.0")
Streamlitと同じようにUIが簡単に作れて便利だと思います。UIのコンポーネントとそのコンポーネントに入るデータが分かれたところに宣言するところがちょっと不思議な感じでした。
なんとなくですが、Streamlitは宣言的に書くような感じで、Gradioは命令的に書くような印象があります。
同じようなものをStreamlitで作る場合は、以下のような感じになると思います。
import streamlit as st
st.markdown("""
# 💎 Cobalt
""")
# Input query
query = st.text_input("Query")
# Search
result = search()
st.markdown("""
## Search Results
""")
# Result
st.dataframe(result)
まとめ
今回は、RuriとVoyager、BM25を用いてハイブリッド検索を実装してみました。スクラッチで作ることで、Azure AI Searchなどで使われているアルゴリズムを理解するきっかけになったと思います。
また、GradioでUIも作ってみました。実際にGradioでWebアプリを作ってみて、GradioとStreamlitの違いをちょっと知れて面白かったです。