Introduction
きっかけ
最近はWebアプリ開発にかまけて、楽しい楽しい言語処理を疎かにしていたので、久々にさわってみたくなりました。言語処理といえば、、、MeCabですね。
ただ現在はMac使いのボク(キリッ)ですが、米津玄師+WordCloudの記事当時は、WindowsによるMeCabの環境設定に大いに苦労しました。
もうあんな思いはしたくないですし、時代はクラウドなので、クラウドでの環境設定に興味を持っていました1。
言語処理といっても、仰々しいことをやるのはしんどいので、簡単2にWordCloudでの可視化と組み合わせてみました。
実際の作業は、思い立って画像をダウンロードするまで、3時間かかってないです3。 簡単楽ちん♪
結論
こんな感じのpngファイルが完成します。

上記の画像はQiitaへ投稿するために、作った画像です。
本日のお品書き
・Google Colaboratoryの簡単な使い方の紹介。
・MeCabとWordCloudを用いて、実際に言語処理を体感してみよう。
・やってて困ったことやつまづいたこと。
対象者
・自然言語処理の初心者の方
・1を聞いて10を理解できるエンジニア
・とりあえず難しいことは知りたくない人
・Macユーザーの人
・データの前処理に苦しむ方
非対象者
・自然言語処理が超得意な人
・説明下手な筆者を攻撃しようとするエンジニア
・きちんと体系的にしっかりと学びたい人
・Windowsユーザーの人
・データの前処理エキスパートの方
自己紹介

自己紹介ページ
環境情報
macOS Big Sur ver:11.6
# 以下の情報は、全てGoogle Colaboratoryの環境
ipython==5.5.0
mecab-python3==1.0.4
notebook==5.3.1
Python 3.7.12
Cf.) Python2系とかPython3系の意味が分からない人へ!
Pythonには2系と3系があって、最近始めた人ならほとんどPython3系だと思います。詳細はWebで検索してください。
Let's Start
Google Colaboratory(以下Colab)上での実装となります。
使い方は、Jupyter LabやJupyter Notebookと似たような使い方ができます。
Google Colaboratoryとは?
Google Colaboratoryの詳細に関しては、Google先生に聞いてください。そして僕に教えてください。コメントお待ちしております。
起動方法
Google アカウントを作成する。
Googleを開いて、[Google Colaboratory]を検索窓に入力する。
開いて、New NotebookでOKです。
Pythonのインストール
さてPythonは入っているのでしょうか?
Google Colaboratoryのnotebook内で、下記のコマンドを入力してみましょう。
%%bash
python --version

ColabにはすでにPythonやその他のパッケージが入っているので、何もインストールしなくてもPythonのバージョン情報が表示されます。
環境設定に困っていた過去の自分に教えてあげたいものです。
「Google先生がPythonの環境を作ってくれたよ。もうAnacondaとかPythonとかminicondaとか悩まなくてええんやで。あのPathの設定に戸惑って枕を濡らした夜を過ごさなくてええのよ。ありがとうGoogle。ありがとうラリー・ペイジ。ありがとう、ありがとう、ありがとう」
って感じですね。
なんて簡単!!
MeCabのインストール
MeCabのインストールはこちらのコマンドでいけます。
Colabのセル内で下記のコマンドを実行するだけでMeCabがインストールされます。
自分はコマンド実行からインストール完了まで30秒以上かかりました。
%%bash
# mecabのインストール
apt-get install mecab swig libmecab-dev mecab-ipadic-utf8 >/dev/null
# mecab-pythonのインストール
pip -q install mecab-python3
引用元:
インストールされたかどうかは、下記の方法で確認できます。
%%bash
mecab -v
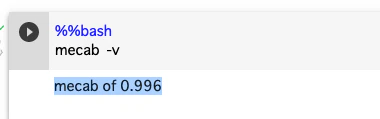
0.996というバージョンがインストールされているようです。
日本語フォントのインストール(WordCloud用)
先ほども紹介したこちらの記事でもある通り、WordCloudは日本語に対応していません。いわゆる豆腐になってしまうので、事前に日本語フォントをインストールしておきます。
下記のコマンドをセルの中に入れて実行してください。
%%bash
sudo apt update
sudo apt install fonts-ipaexfont

これで最低限のインストール作業は完了です。
いよいよ言語処理をやっていきましょう。
MeCabとの戯れ。
今回処理する文章は、以前noteに書いた記事を利用しました。
こちらの記事の中の「書籍を読んで」という部分を使って、言語処理してみました。
import MeCab
str ='''
書籍を読んで。
イーロンマスクとの共通点
次郎のプリンシパルだけを意識した言動は、今をときめくイノベーターであるイーロンマスクを想起しました。日本国民や世界人類のために自分ができることを考える姿や手段から考えることなく、ビジョンを元に行動する姿には共通するところがあります。
また次郎を軸とした本書を読むうちに、今までに読んだ他の書籍(最下部に参考情報としてまとめておきます)と合わせて日本の昭和時代に思いを馳せました。やはり歴史は一本の川のようにはなっておらず、複数の選択肢からその時のベストの選択を取り続けた結果の積み重ねでしかないのかもしれません。後から悔やまないように、その都度その都度自分の頭で考えて決定していかないと、だめなんですね。
未来がわかっているなら、最高の選択を選ぶことができますが、人生においてはその時々で、持てる全ての情報を総動員して判断していくしかないんですね。
だから次郎のようにプリンシパルを持つ必要があると感じました。自分のプリンシパルを持って、そこから外れないからこそ、文脈や前例に縛られずに生きていくことができます。
まぁなかなかそんなカッコよく生きられないですけどね。
先述したとおり、次郎は日本が戦争に負けたからといって、日本国民全てが奴隷となったわけでないと考えていました。この考え方は今の時代でも使えると思います。国家の立ち位置と自分自身の根性は別物と考えることです。
例え日本国家が衰退したとしても、日本国民という理由だけで自分の未来を狭める必要はありませんし、自分を腐敗させる必要はありません。
つまり現在の日本の凋落や中国をはじめとしたアジア諸国の台頭に引け目を感じるニュースの多い日本に住んでいても、日本国民の自分が何かマイナスなものを感じる必要はないことを白洲次郎から学ぶことができます。
愛国心や日本国民としてのプライドを持っていたとしても、国家を自分の人生に投影する必要は全くありません。国家に限らず会社や学校でも同様のことが言えると思います。従業員の立場であるなら、自分の人生と会社の業績を投影することなく、一人の個として生きていくことが大切だと感じました。
プリンシパルをきちんと持っておけば、このような自立したマインドを持っておくことができるかもしれないですね。'''
#Chasenを使う。
mecab = MeCab.Tagger('-r/etc/mecabrc -Ochasen')
node = mecab.parseToNode(str)
output = []
#意味をなさないような単語を除外する。
stoplist =['(',')','わけ','し','い','教わっ','こと','ため','もの','ある','しれ','られ','あり','する','ない','いく','感じる']
# 品詞に分解して、助詞や接続詞などは除外している。
while node:
word_type = node.feature.split(",")[0]
if word_type in ["名詞","形容詞","動詞"]:
if not node.surface in stoplist and not node.surface.isdigit():
output.append(node.surface.upper())
node = node.next
print(output)
print(len(output))
やっていることを大雑把に説明すると、下記の3Stepとなります。
- 元の文章を単語に分割
- 事前に意味が判別しにくい単語を除去する。
- 意味が判別しやすい単語のみ(名詞や動詞や形容詞)をリストに入れる。
なんとなく、わかりますか?
実際は単語ではなく、形態素と呼ばれる単位に分割しています。
形態素解析というものは、文章を切り分ける技術です。
ちなみに形態素というのは文章から、意味を持つように切り分けたときの最小単位です。
英語なら文章に空白が入っているので、形態素に切り分けやすいです。
I am SempleならIとamとSempleに分けることができます。
しかし日本語は英語と異なり、形態素には切り分けられません。
わたしはSempleですの場合はわたしとはとSempleとですに切り分ける必要があります。
三回目の紹介ともなりますが、こちらの前回の記事より抜粋。
今回取り上げた言語処理のなんとなくイメージを掴んでもらえたら大丈夫です、それではソースコードを詳細に見ていきます。興味ない方は、次へお進みください。
まずは、MeCabをimportしています。
import MeCab
次に言語処理するテキスト部分をコピペで持ってきています。
前回のようにスクレイピングしたり、txt形式で読み込んでもいいのですが、もっとサクッと試したかったので、コピペで対応しています。
気が向いたら、もっと様々な方法でも実験してみようと思います。4

ここでは、mecabに含まれるChasenという方法で単語に分けています。
-r/etc/mecabrcのようにPathを追加した状態でないとエラーが発生してします。エラーの詳細と対処法に関しては、下記にまとめておきましたので、そちらをご参照ください。
mecab = MeCab.Tagger('-r/etc/mecabrc -Ochasen')
node = mecab.parseToNode(str)
ここでは、形態素解析した元のテキストから、名詞と形容詞と動詞のみ抽出しています。不要語の選定(stoplist)やチューニング等に関しては、下記にまとめてありますので、そちらを参照ください。
while node:
word_type = node.feature.split(",")[0]
if word_type in ["名詞","形容詞","動詞"]:
if not node.surface in stoplist and not node.surface.isdigit():
output.append(node.surface.upper())
node = node.next
形態素解析で分割された単語がどんな単語になったのかを確認するために、outputをprintしています。len(output) してるのは、不要語の設定や細かなパラメータを調整していたからです。詳細はこちら。
print(output)
print(len(output))
単語を集めて、まとめてWordCloudにポイ。
研究に使うとかChatbotを開発するとかでもない限り、言語処理したものを眺めていても楽しくないですよね。MeCabを通じて言語処理した単語を、WordCloudというサービスを利用して可視化してみましょう!
実際にできた画面がこちら。

トップでも一度紹介しました画像ですが、こちらのサービスは単語の出現頻度に応じて文字の大きさが変わります。つまりたくさん出現すると文字が大きくなり、出現頻度が少ないと文字のサイズも小さくなります。
それでは早速ソースコードです。
from wordcloud import WordCloud
#形態素解析された単語のリストをWordCloud用に処理している。
text = ' '.join(output)
#日本語はダウンロードしたの日本語フォントのパスを貼り付ける
fpath = "/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf"
wordcloud = WordCloud(background_color="white", font_path=fpath, width=800,height=600).generate(text)
#WordCloudの画像は下記のディレクトリ内に保存されます。
wordcloud.to_file("/content/sample_data/sample_shirasujiro.png")
やってることは単純で、MeCabでリストにした単語をWordCloudへ入れています。リストのままだと、受け付けてくれないので、形態素ごとに空白を入れた文字列へ変換して、WordCloudに読み込ませています。
作成した画像の保存場所は、Colab内の /content/sample_data内にあると思います。書籍の人物が白洲次郎なので、sample_shirasujiro.pngというファイル名で保存しています。

こちらの画像ファイルsample_shirasujiro.pngをダウンロードすることで、言語処理が可視化された画像が手に入ります。

お疲れ様でした。ここまでで大体3時間程度で出来たと思います。
もしかしたら、もっと早いかもしれないですね。今回は、白洲次郎を読んだ感想を言語処理しましたが、他の文章でも同様に可視化することができますので、ぜひ試してみてください。
To be Continued
再会のゆびきり
今後もQiitaやZennで、技術情報を発信しています。
noteには、備忘録を記録しています。
新着情報はX(旧: Twitter)で配信いたします。
フォローをお願いいたします。
Sempleの自由帳
Sempleのアイデア帳
Sempleのドキュメント
Sempleのツイッター
やってて困ったことやつまづいたこと。
mecabのChasenが実行できないエラー
本文でも軽くふれましたが、前回の記事のようにChasenを使用しようとした際にColab上ではエラーが出ました。
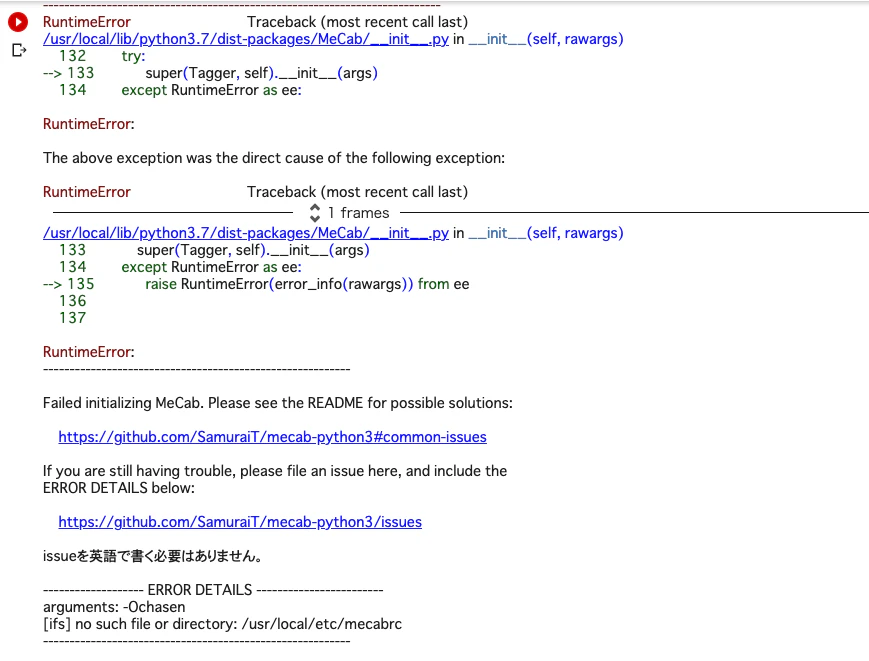
runtime Error周りを探していたんですが、公式からCommon Issueが立っています。
Local環境ではMeCabをインストールしたディレクトリを探してくれるようですが、Colab上では少し挙動が異なるそうです。macabrcがなんか色々あるみたいです。
結論としては、本文で紹介した通りの対策を行いました。実際にはPathを通すために何度も試行錯誤して時間を食ってしまいました。
以前の言語処理でMeCabをいじっていた時もこの辺が時間を費やしたような気がしますね。
表出化される単語のチューニング作業。
トップの画像を見ていただければわかりますが、日本国民と日本が表出されていたり、意味のわからない単語が出てきています。
この辺は、WordCloudで表出化された文字を見ながら、意味を含まない単語は、形態素解析する際にStopwordに設定して取り除きます。今回の記事では、細かな部分をどうこうするってわけではなく、環境設定する必要もなく、簡単にできることをメインテーマとしていますので、汚い出力結果となっています。正直なことを言うと、この辺は経験によるものが大きいです。自分も前回の経験をもとにStopwordを決めています。(流用とも言います。)
この辺りは量を重ねることで、慣れていくような職人芸だと思っています。辞書を直したりパラメータを調整したりと面白い分野ではあるんですが、なにぶん作業時間が膨大にかかるので、興味がある方はコメントください。一緒に勉強していきましょう!
豆腐はあなたの味方です。
豆腐がよくわからない方や、豆腐が見たい方はこちら
豆腐になる原因を簡単に説明するとWordCloudに日本語フォントが入っていないからです。
WordCloudに限らず、Pythonで言語処理をやっていると、よく出会います。matplotlibなどをいじっていても出逢います。もはや懐かしの旧友並みに親しみを覚えるので、ぜひ豆腐と仲良くしてあげてください5。
豆腐を修正する際に、matplotlibでの修正方法は多く見つかりましたが、wordcloudでの文字化け修正がなかなか見つからず苦労しました。
Local環境ではないためディレクトリ構造も異なりますので、Colabのディレクトリ構造の把握に時間がかかりました。
本文の中でも紹介しましたが、下記のコマンドでIPAのフォントをダウンロードしています。
%%bash
sudo apt install fonts-ipaexfont
インストール成功の可否は以下のコマンドで確認できます。
%%bash
fc-list | grep 'IPA'

引用元の記事はこちらです。
IPAという単語がつくものだけ出力して、って命令だと思います。
Linux?は詳しくないので、違っていたら教えてください。
ちなみに全然関係ないですけど、matplotlibの手法はいくつもあるみたいです。
参考記事