はじめに
えっ(思考停止) この衝撃的な知らせを受けて僕はもう約1週間、胃の痛みと睡眠不足に陥っています。 とにかく胃が痛くて仕方がありません。 現実を受け入れられない僕は、精神の安定とこのような悲劇が二度と起こらないためにも、データ収集と考察を行うことにしました。 当記事では、python3+requests+BeautifulSoup4+matplotlibでデータを収集、グラフ化し、まんがタイムきららmaxにおける掲載順の考察(特にどうびじゅ)を行いたいと思います。 # 環境【おしらせ】本日2月19日発売のまんがタイムきららMAXに「どうして私が美術科に!?」38話目載せてもらっています。
— 相崎うたう🎨どうびじゅ発売中 (@py_py_ai) 2019年2月19日
そして次号、最終話です。 pic.twitter.com/Ars5radT6o
# uname -a
Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux
# python --version
Python 3.7.2+
# pip3 show requests
Name: requests
Version: 2.18.4
# pip3 show beautifulsoup4
Name: beautifulsoup4
Version: 4.6.3
# pip3 show matplotlib
Name: matplotlib
Version: 2.2.2
# pip3 show numpy
Name: numpy
Version: 1.14.5
# pip3 show chardet
Name: chardet
Version: 3.0.4
データ収集
今回はまんがタイムきららWebのmaxのバックナンバーのページの情報から掲載順を取得したいと思います。
注意
今回行うスクレイピングは、場合によって大量のリクエストをサーバに送ることになり、結果としてサーバに負荷がかかる(=攻撃する)ことにつながる危険性があります。
攻撃する意図がなくても、実際に被害が出てしまったら犯罪になってしまいます。
法律面には十分に配慮し、連続して複数回リクエストを送る場合は必ず、1秒以上間隔を開けるようにしましょう。
とりあえず一ヶ月分
いきなり全部取得しようとするのは無理なので段階を踏んでいきたいと思います。
まず、取得すべきデータがどのタグの中に収まっているか確認しましょう。
以下は、http://www.dokidokivisual.com/magazine/max/book/index.php?mid=485
のソースの一部です。
<!-- /Title -->
<!-- Logo area -->
<div id="logo-area" class="clearfix">
<div class="logo">
<div><img src="../img/top/max_logo.gif" width="208" height="76" alt="ロゴ:まんがタイムきららMAX" /></div>
<p>ドキドキ★ビジュアル全開マガジン!!</p>
</div>
<div class="info">
<dl>
<dt>『まんがタイムきららMAX』</dt>
<dd>毎月19日発売</dd>
<dd>定価:本体333円+税</dd>
</dl>
<p class="link"><a href="../backnumber/index.php">バックナンバー</a></p>
</div>
</div>
<!-- /Logo area -->
<!-- Latest title -->
<div id="latest-title" class="clearfix">
<h2 class="date-title">ドキドキ★ビジュアル全開マガジン!!</h2>
<div class="photo">
<!-- Photo -->
<div><img src="/magazine/img_magazine/max_photo_t1603.jpg" width="208" height="295" alt="『まんがタイムきららMAX』" /></div>
<!-- /Photo -->
<!-- Lineup -->
<h3><img src="../../img/lineup_title.gif" width="208" height="27" alt="ラインナップ" /></h3>
<ul class="lineup">
くろば・U<FONT COLOR="#8000FF">『ステラのまほう』</FONT><BR>
原悠衣<FONT COLOR="#8000FF">『きんいろモザイク』</FONT><BR>
はんざわかおり<FONT COLOR="#8000FF">『こみっくがーるず』</FONT><BR>
火曜<FONT COLOR="#8000FF">『彼氏ってどこに行ったら買えますの!?』</FONT><BR>
荒井チェリー<FONT COLOR="#8000FF">『いちごの入ったソーダ水』</FONT><BR>
はまじあき<FONT COLOR="#8000FF">『きらりブックス迷走中!』</FONT><BR>
kashmir<FONT COLOR="#8000FF">『ななかさんの印税生活入門』</FONT><BR>
佐古新佑<FONT COLOR="#8000FF">『ペンにまします神サマの』</FONT><BR>
Koi<FONT COLOR="#8000FF">『ご注文はうさぎですか?』</FONT><BR>
有馬<FONT COLOR="#8000FF">『はんどすたんど!』</FONT><BR>
晴瀬ひろき<FONT COLOR="#8000FF">『魔法少女のカレイなる余生』</FONT><BR>
鍵空とみやき<FONT COLOR="#8000FF">『はるのさんは今日も見る!』</FONT><BR>
相崎うたう<FONT COLOR="#8000FF">『どうして私が美術科に!?』</FONT><BR>
水鏡ひより&氷坂透<FONT COLOR="#8000FF">『裏庭には…!』</FONT><BR>
へちま<FONT COLOR="#8000FF">『ぱぺっとコール!』</FONT><BR>
右左もりもり<FONT COLOR="#8000FF">『ふるスクらっち!』</FONT><BR>
らぐほのえりか<FONT COLOR="#8000FF">『すくりぞ!』</FONT><BR>
未影<FONT COLOR="#8000FF">『神様生徒会部!』</FONT><BR>
ぷらぱ<FONT COLOR="#8000FF">『アイドル声優☆上村とまり17歳』</FONT><BR>
沙籐しお<FONT COLOR="#8000FF">『シンデレラはまだ子供』</FONT><BR>
永山ゆうのん<FONT COLOR="#8000FF">『みゅ~こん!』</FONT><BR>
うみのとも<FONT COLOR="#8000FF">『そよ風テイクオフ』</FONT><BR>
アカコッコ<FONT COLOR="#8000FF">『ハナイロ』</FONT><BR>
もみのさと<FONT COLOR="#8000FF">『アルエない大発迷』</FONT><BR>
吉野貝<FONT COLOR="#8000FF">『軍師姫』</FONT><BR>
はんざわかおり<FONT COLOR="#8000FF">『かおす先生のアトリエ探訪』</FONT><BR>
<!-- /Lineup -->
相崎うたう<FONT COLOR="#8000FF">『どうして私が美術科に!?』</FONT><BR>
掲載されている作品の題名は、<FONT COLOR="#8000FF">と</FONT>にはさまれています。
URLとデータが入ったタグ名が分かれば十分です。
データを取得してみましょう。
# -*-coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
i=0
rank=0
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid=485'
html=requests.get(url)
source=BeautifulSoup(html.text,"html.parser")
span=source.find_all("font")
for tag in span:
try:
i+=1
name=tag.string
print(i,name)
if "どうして私が美術科に!?" in name:
rank=i
except:
pass
print("どうして私が美術科に!?>>>",rank)
1 wXe ÌÜÙ¤x
2 w«ñ¢ëUCNx
3 w±ÝÁª[sÁ½ç¦Ü·Ì!?x
5 w¢¿²ÌüÁ½[_
6 w«çèubNXÀIx
7 wÈÈ©³ñÌóüåx
8 wy¶Í¤³¬Å·©Hx
/*中略*/
24 wAGÈ¢åÀx
25 wRtPx
26 w©¨·ÌAgGTKx
どうして私が美術科に!?>>> 0
文字化けしてます。これでは読めないし、データの判別が面倒です。
困っていると救世主が。(かなりの時間を浪費したので助かりました。)
https://orangain.hatenablog.com/entry/encoding-in-requests-and-beautiful-soup
の通りに、Chardetをインストールし、
source=BeautifulSoup(html.text,"html.parser")
を書き換えると、
# -*-coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
i=0
rank=0
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid=485'
html=requests.get(url)
# ここを書き換える
source=BeautifulSoup(html.content,"html.parser")
font=source.find_all("font",color="#8000FF")
for tag in font:
try:
i+=1
#fontタグの中にある文字列を抜き出してnameに入れる
name=tag.string
print(i,name)
#もし、どうびじゅだったら、順位を記録する
if "どうして私が美術科に" in name:
rank=i
except:
pass
print("どうして私が美術科に!?>>>",rank)
1 『ステラのまほう』
2 『きんいろモザイク』
3 『こみっくがーるず』
4 『彼氏ってどこに行ったら買えますの!?』
5 『いちごの入ったソーダ水』
6 『きらりブックス迷走中!』
7 『ななかさんの印税生活入門』
8 『ペンにまします神サマの』
9 『ご注文はうさぎですか?』
10 『はんどすたんど!』
11 『魔法少女のカレイなる余生』
12 『はるのさんは今日も見る!』
13 『どうして私が美術科に!?』
14 『裏庭には…!』
15 『ぱぺっとコール!』
16 『ふるスクらっち!』
17 『すくりぞ!』
18 『神様生徒会部!』
19 『アイドル声優☆上村とまり17歳』
20 『シンデレラはまだ子供』
21 『みゅ〜こん!』
22 『そよ風テイクオフ』
23 『ハナイロ』
24 『アルエない大発迷』
25 『軍師姫』
26 『かおす先生のアトリエ探訪』
どうして私が美術科に!?>>> 13
動きました。とりあえず一安心。
初掲載だった2016年3月号の掲載順は13番手だったみたいです。
複数号分取得しよう
考察を行うためには複数のデータが必要です。
初掲載だった2016年3月号から最新号の2018年4月号までのデータを取得しましょう。
また、サイトの仕様を確認します。
http://www.dokidokivisual.com/magazine/max/book/index.php?mid=485
どうやら、URLのmidの値が5つおきにmaxのページになっているようです。
しかし、2017年12月号からその法則が変わります。ミラクの休刊があったためです。
このときからmidの値は4つおきになります。
注意:この方法はスクレイピングを行う上でとても便利な方法ですが、相対パスなどの通常では使わない方法をとると、意図せずディレクトリトラバーサルのような攻撃になってしまう場合があります。注意してください。
法則が分かったところで早速書いてみましょう。
最初にも書いたとおり、一回リクエストを送る度に一秒以上間隔を開けることをお忘れなく。
# -*-coding:utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
from time import sleep
mid=485
year=2016
month=3
# 順位はこの配列に格納します
rank_list=[]
while mid<=654:
print ("\n{}年{}月号".format(year,month))
#midが515のときだけずれていたので修正
if mid==515:
mid=514
#midをURLに埋め込む
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid={0}'.format(mid)
html=requests.get(url)
if mid==514:
mid=515
source=BeautifulSoup(html.content,"html.parser")
span=source.find_all("font",color="#8000FF")
i=0
for tag in span:
try:
i+=1
name=tag.string
print(i,name)
if "どうして私が美術科に" in name:
rank_list.append(i)
except:
pass
#年,月を更新
if month==12:
year+=1
month=1
else:
month+=1
#法則に従いmidを更新
if mid<=585:
mid+=5
else:
mid+=4
#1秒間隔を開ける(忘れずにかく)
sleep(1)
# 結果が入った配列を表示
print("どうして私が美術科に!?>>>",rank_list)
2016年3月号
1 『ステラのまほう』
2 『きんいろモザイク』
3 『こみっくがーるず』
4 『彼氏ってどこに行ったら買えますの!?』
5 『いちごの入ったソーダ水』
/*中略*/
2019年4月号
1 『ぼっち・ざ・ろっく!』
2 『きんいろモザイク』
3 『こみっくがーるず』
4 『ステラのまほう』
5 『初恋*れ〜るとりっぷ』
6 『旅する海とアトリエ』
7 『タベモノガタリ』
8 『たつのお年頃』
9 『ご注文はうさぎですか?』
10 『みわくの魔かぞく』
11 『魔王城ツアーへようこそ!』
12 『しょうこセンセイ!』
13 『ななどなどなど』
14 『私を球場に連れてって!』
15 『サジちゃんの病み日記』
16 『魔王と勇者が百合結婚するお話。』
17 『委員長のノゾミ』
18 『ももいろジャンキー』
19 『社畜さんと家出少女』
20 『合体アイドル!スノウちゃん』
21 『どうして私が美術科に!?』
22 『彼女がお兄ちゃんになったらしたい10のこと』
23 『ななかさんの印税生活入門』
どうして私が美術科に!?>>> [13, 7, 7, 17, 12, 15, 5, 21, 5, 7, 6, 13, 6, 7, 13, 5, 4, 5, 6, 17, 12, 10, 6, 6, 21, 10, 7, 17, 10, 12, 15, 12, 15, 18, 15, 17, 19, 21]
初掲載から最新号までのmaxの掲載順の一覧とどうびじゅの掲載順が入った配列を手に入れました。
グラフ化
一応データを入手することに成功しましたが、これでは考察が面倒です。
せっかく配列でデータを入手しているのでグラフに表しましょう。
# -*-coding:utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
bottom=24
mid=485
index=0
year=2016
month=3
rank_list=[]
# データ取得部分 ここから
while mid<=654:
print ("\n{}年{}月号".format(year,month))
if mid==515:
mid=514
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid={0}'.format(mid)
html=requests.get(url)
if mid==514:
mid=515
source=BeautifulSoup(html.content,"html.parser")
span=source.find_all("font",color="#8000FF")
i=0
for tag in span:
try:
i+=1
name=tag.string
print(i,name)
if "どうして私が美術科に" in name:
rank_list.append(i)
except:
pass
index+=1
if month==12:
year+=1
month=1
else:
month+=1
if mid<=585:
mid+=5
else:
mid+=4
sleep(1)
# ここまで
print(rank_list)
# このように上で表示したデータをコメントアウトでメモしておくと上の処理をしなくて済むので時間を節約できて、サーバにも負荷がかかりません
# rank_list=[13, 7, 7, 17, 12, 15, 5, 21, 5, 7, 6, 13, 6, 7, 13, 5, 4, 5, 6, 17, 12, 10, 6, 6, 21, 10, 7, 17, 10, 12, 15, 12, 15, 18, 15, 17, 19, 21]
# X軸のデータ
left = np.array(range(len(rank_list)))
# X軸とY軸のラベル
plt.xlabel('Publication issue')
plt.ylabel('Publication order')
# タイトル
plt.title('Changes in the order of publication')
# プロット
plt.plot(left+1, rank_list, label='doubiju')
# これを忘れると表示されません 注意
plt.show()
結果
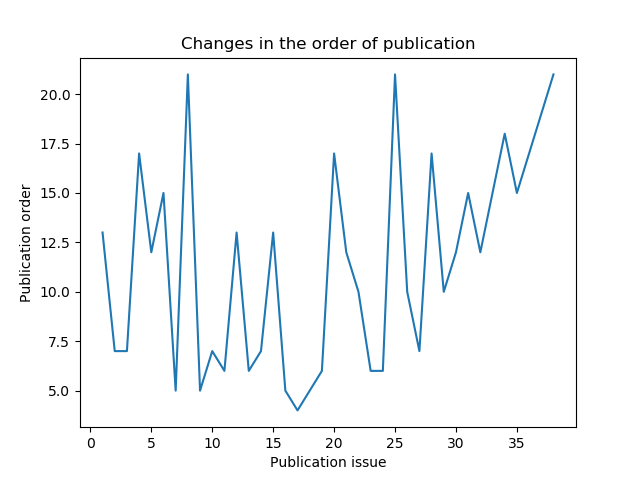
掲載順が良いほうが下になっているので違和感があります。
目盛りも小数点が出てきてなんだか見づらいです。修正しましょう。
# -*-coding:utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
bottom=24
mid=485
index=0
year=2016
month=3
rank_list=[]
# ----------------------------------
# 同じなので省略 データ取得部分をここに書く
# ----------------------------------
print(rank_list)
# このように上で取得したデータをコメントアウトでメモしておくと再利用できるので時間を節約できて、サーバにも負荷がかかりません
# rank_list=[13, 7, 7, 17, 12, 15, 5, 21, 5, 7, 6, 13, 6, 7, 13, 5, 4, 5, 6, 17, 12, 10, 6, 6, 21, 10, 7, 17, 10, 12, 15, 12, 15, 18, 15, 17, 19, 21]
# X軸のデータ
left = np.array(range(len(rank_list)))
# X軸とY軸のラベル
plt.xlabel('Publication issue')
plt.ylabel('Publication order')
# タイトル
plt.title('Changes in the order of publication')
# プロット
plt.plot(left+1, rank_list, label='doubiju')
# Y軸の値の上下を反転
plt.gca().invert_yaxis()
# 見やすいようにグリッドをつける
plt.grid(color='gray')
# Y軸の目盛りを全部対象にする
plt.yticks(range(1,bottom))
# これを忘れると表示されません 注意
plt.show()
結果
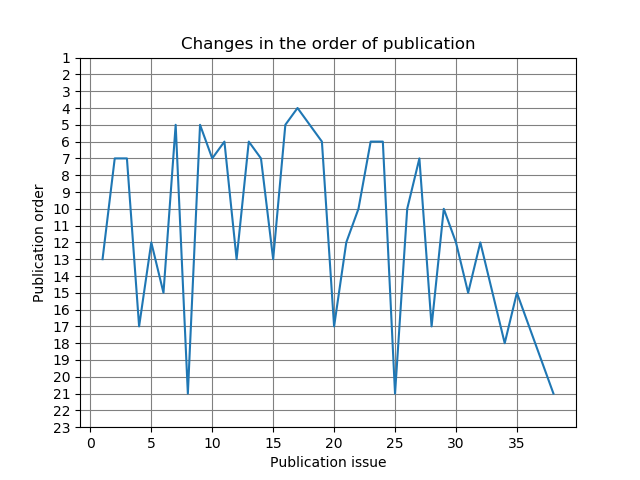
いい感じになりました。
考察
技術的な話題を離れて、得られたデータの考察をしたいと思います。
気になるのは、グラフの形状が激しいギザギザの形をしていることです。
しかし、値が落ちているところにも共通点があります。
(1). 大きく落ちているところでは必ず回復傾向にある
(2). (1)の傾向に当てはまる掲載順は13,17,21番目である
そこでサイトをもう一度よく調べてみると、1,9,13,17,21番目にはセンターカラーの作品がくることが分かりました。
つまり、センターカラーのページは決まっているので人気とは関係なく掲載順が落ちてるように見える現象が起きるのです。
しかし、例外がありました。最新号です。最新号のセンターカラーの掲載順は1,9,12,16,19番目になっています。サイトの情報と照合したところ、2019年2月号からこの傾向がみられるようになったようです。
更なる考察
こうなるともっとデータが欲しいところです。
他の漫画の掲載順も入れてみましょう。
"どうして私が美術科に!?"の!?が2017年8月号だけ!?になっていたので判定に注意が必要です。(一敗)
# -*-coding:utf-8 -*-
import sys
import requests
from bs4 import BeautifulSoup
from time import sleep
import numpy as np
import matplotlib.pyplot as plt
bottom=24
mid=485
index=0
year=2016
month=3
rank_list=[]
kanojo_list=[]
gochiusa_list=[]
kinmoza_list=[]
date_list=[]
date_place=[]
while mid<=654:
print ("\n{}年{}月号".format(year,month))
#X軸に入れる年と月を設定し、配列に格納する
if month==4:
date_list.append(str(year)+"\n"+"Apr.")
date_place.append(index+1)
if month==8:
date_list.append(str(year)+"\n"+"Aug.")
date_place.append(index+1)
if month==12:
date_list.append(str(year)+"\n"+"Dec.")
date_place.append(index+1)
if mid==515:
mid=514
url='http://www.dokidokivisual.com/magazine/max/book/index.php?mid={0}'.format(mid)
html=requests.get(url)
if mid==514:
mid=515
source=BeautifulSoup(html.content,"html.parser")
span=source.find_all("font",color="#8000FF")
i=0
for tag in span:
try:
i+=1
name=tag.string
print(i,name)
#表記揺れがあったので"!?"は書かない
if "どうして私が美術科に" in name:
rank_list.append(i)
if "彼女がお兄ちゃんになったらしたい10のこと" in name:
kanojo_list.append(i)
if "きんいろモザイク" in name:
kinmoza_list.append(i)
if "ご注文はうさぎですか?" in name:
gochiusa_list.append(i)
except:
pass
#連載されていなかったり、休載していてデータがないとき空データを格納
if len(kanojo_list)==index:
kanojo_list.append(None)
index+=1
if month==12:
year+=1
month=1
else:
month+=1
if mid<=585:
mid+=5
else:
mid+=4
sleep(1)
left = np.array(range(len(rank_list)))
plt.xlabel('Publication issue')
plt.ylabel('Publication order')
plt.title('Changes in the order of publication')
# データを増やすときはplt.plotを増やすだけ
plt.plot(left+1, rank_list, label='doubiju')
plt.plot(left+1, kanojo_list, label='kanojoga')
plt.plot(left+1, kinmoza_list, label='kinmoza')
plt.plot(left+1, gochiusa_list, label='gochiusa')
plt.gca().invert_yaxis()
plt.grid(color='gray')
# 凡例をつける
plt.legend(bbox_to_anchor=(1.02,1),loc='upper left',borderaxespad=0)
# 凡例がはみ出さないよう右側に余白を作る
plt.subplots_adjust(right=0.7)
# 目盛りの間隔を調整し、年と月のデータをX軸に入れる
plt.xticks(date_place,date_list)
plt.yticks(range(1,bottom))
plt.show()
結果
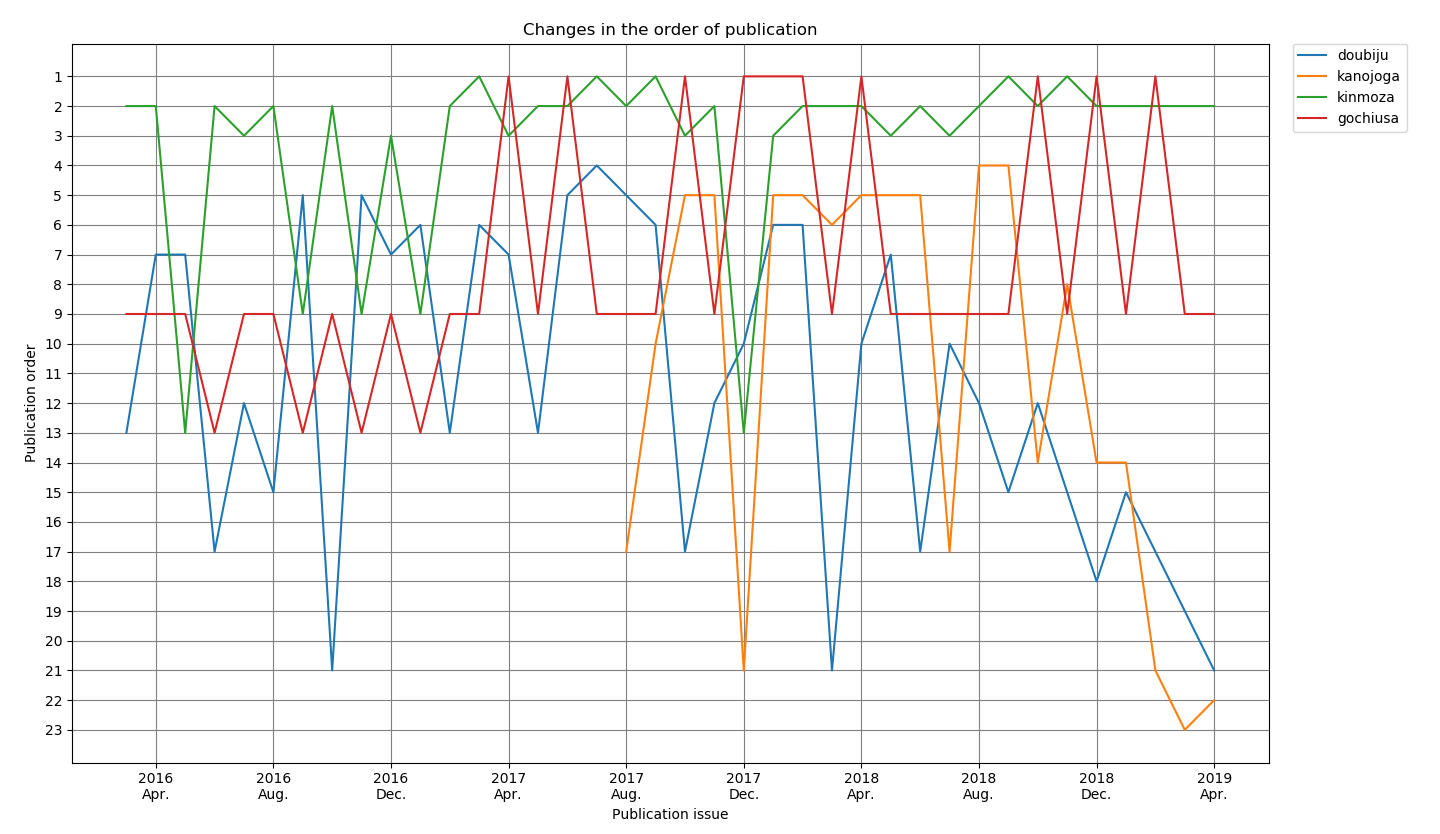
青:どうして私が美術科に!?
黄:彼女がお兄ちゃんになったらしたい10のこと
緑:きんいろモザイク
赤:ご注文はうさぎですか?
こう見るとごちうさのセンターカラー率は凄まじいですね...
もしかしたら100%かも知れません。
彼女がお兄ちゃんになったらしたい10のことを入れたのは、きらら展でサインが隣だったことと、傾向がよく似ていて心配だからです。胃が痛い。
センターカラーで見かけの掲載順が下がったあと、大きく戻らないとそのまま掲載順が下がってしまう傾向にあることがわかりました。
主張
まんがタイムきららmaxでは、ゲストの数が非常に多い傾向にありますが、もう少し既存の連載している作品を気にかけるべきではないでしょうか。
確かに若手を育てることは大切ですが、それによって3巻の壁を越えられるような作家を潰してしまうのは非常にもったいないように思います。学生の自分にはわからないような大人の事情が多々あるのでしょうが、もう少しどうにかならなかったのかなと思いました。
感想
この記事を読んだ方の9割7分は、「長い」、「何故Qiitaに書いたんだ」とお思いでしょうが僕もそう思います。
スクレイピングを取り扱う記事はQiitaには沢山ありますが、こういった趣味に近い楽しい使い方があっても良いなと思いました。今回はまんがタイムきららmaxでしたが、ジャンプやマガジンでもできると思います。また、掲載順だけじゃなくて売上とかでやって考察しても楽しいと思います。
ぜひ試してみてください。
初めて記事を書きましたが、楽しかったです。
教訓
どんなにデータ収集や考察をしたところで悪夢は覚めないし、現実は直視できない。
推しは推せるときに全力で推すべし。
やっぱり胃が痛い。