チームでのWeb API開発において、進行を妨げる要因は様々な形で噴出します。
「フロントはバックエンドのAPI実装待ちなので動けません...」「ドキュメンテーションのコストが重い...」「ドキュメントと実装が全然違うので参考にならない...」
また、APIスキーマ設定が不十分だと、ビジネスドメインの最低原則やクライアント側のニーズを理解せずに、バックエンド都合のAPIがそのまま実装される危険性もあります。
そうした問題を解決すべくSchema Driven Developmentと呼ばれる開発手法が生まれました。
AI駆動文脈で出てきたSpec-driven developmentとは違います。SDDの略称はこちらの方が多数派になりそうかも...?
https://github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai-get-started-with-a-new-open-source-toolkit/
Schema Driven Developmentとは?
Schema Driven Development(以下SDD)とはチームにおけるWeb API開発フローを改善する開発手法の一つです。スキーマ駆動開発やSchema First Developmentとも呼ばれていますね。
ざっくり述べると、先にAPIスキーマ定義をYAMLなどで固め、それを軸としてシステマチックにドキュメント生成&モック生成、リクエスト&レスポンスチェック等をほぼ自動生成として同期させることで効率化を目指すものです。適応効果が高いのはInternalなAPI、つまりモバイルアプリやSPA、マイクロサービスなどバックエンド側とクライアント側が密にコラボレーションすべき開発となります。
SDDという概念が現れ始めたのは少なくとも2015年7月に掲載された論文「Schema-Driven Development of Semantic MediaWikis」からです。そして日本ではRuby kaigi2017でonk氏が発表され、2019年1月に発行されたWEB+DB PRESS Vol.108にて詳しく解説されることとなりました。DeNAやFreeeなどが採用しているようです。
従来の開発フロー
SDDがなぜ効果的なのかを理解するために、従来の開発フローから問題点を洗い出すことにしましょう。
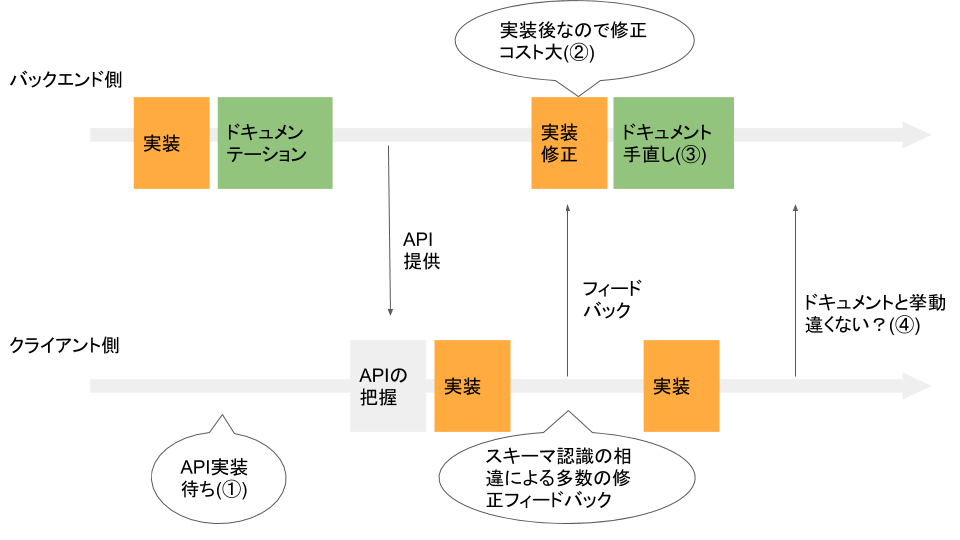
上図の開発フローには次のような問題点があります。
① クライアント側はバックエンド側のAPI実装待ちがある。1
② スキーマに対する双方の合意が確立されないまま実装されるので手戻りのリスクが高く、クライアント側からのフィードバックが得られるのは実装後のため修正コストも大きい。
③ 実装に変更がある都度ドキュメントを手直ししなければならない。
④ 実装とスキーマが完全に一致しているという保証がない。
その結果、余計なコミュニケーションコストが増大し、イテレーションサイクルも減少。品質は悪く、コストは大きく、完成の遅いプロダクトとなるリスクが非常に高くなります。
SDDを実現した開発フロー
SDDを実現すると、開発フローは以下のようになります。
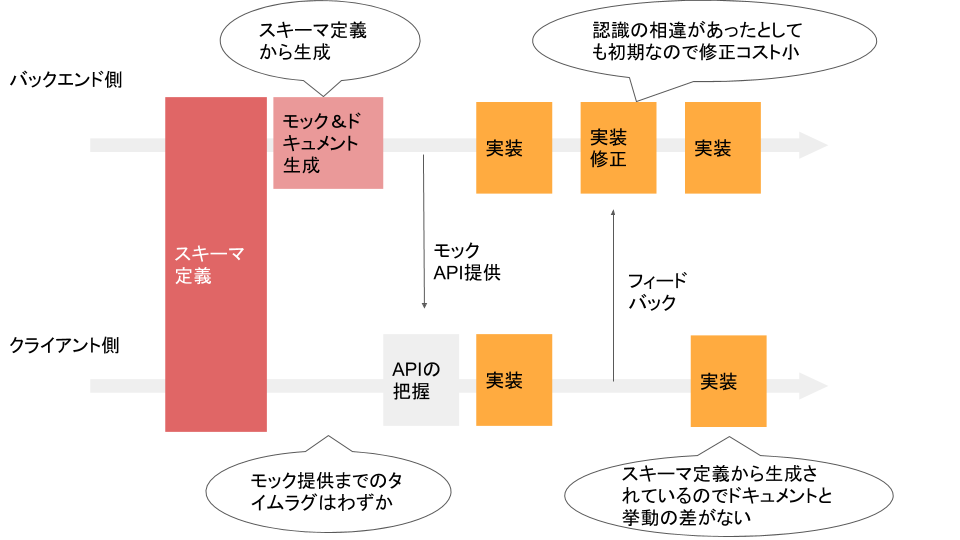
先に述べた問題点をほぼ解決しているのが見てとれると思います。では、どのように実現すればよいのでしょうか?
SDDを実現するための要素
SDDの実現のためには以下の要素が必要となります。
- 合意によるスキーマ定義
- 合意されたスキーマを「信頼できる唯一のソース」2として参照した開発成果物の生成
- モック&ドキュメント自動生成
- Request Validation
- Response Test
合意によるスキーマ定義
Web API開発のスタートはサーバー側とクライアント側共同によるスキーマ定義の合意から始まります。合意の成果物としてAPI仕様言語によるスキーマ定義が作成されるようにします。API仕様言語としては、OpenAPI、API Blueprint、およびRAMLなど、REST APIの言語に依存しない標準的な表現を定義します。もしくはSDDと親和性が高いとされているGraphQL Schemaを採用するという手もあります。
合意されたスキーマを「信頼できる唯一のソース」として参照した開発成果物の生成
実装も含め開発成果物は合意されたスキーマを完全に参照して生成されます。コードベースで言うと、例えばYAMLファイルに記述されたスキーマ定義ファイルを各所で参照したコーディング行うという形をとったりします。その結果合意されたスキーマと成果物が100%同期することが保証され、同期のために支払っていた様々なコストが解消されます。
・モック&ドキュメント自動生成
合意されたスキーマを参照して、APIモックやドキュメントを自動生成します。これによりクライアント側との迅速かつ安定的な連携を可能にします。OpenAPI形式を使っているならばモックはSwagger Codegenで生成、ドキュメントはSwagger UIにて表現といった、OpenAPIエコシステムによる恩恵を得た形にすることができます。
・Request Validation
合意されたスキーマを参照して、API requestが受け取れるパラメータをバリデーションします。これによりスキーマのリクエスト部を保証します。Railsだとcommitteeが次のResponse Testもできるので有名ですね。
・Response Test
合意されたスキーマを参照して、API Responseが返却するエンティティをテストします。これによりスキーマのレスポンス部を保証します。Railsだとjson_matchersによるjsonマッチテストが可能ですね。
SDDにより期待される効果
上記の要素を満たすことで、以下のような効果が実現されることとなります。
開発スピードの高速化
迅速なモック&ドキュメント提供により、クライアント側はバックエンド側がどのような実装をするのかに頓着せずに開発をスタートすることができます。また、バックエンド側もフィードバックが送られるタイミングが早まるため早期の修正を図ることができます。
契約による信頼
スキーマ定義による契約が課されるので、実装とスキーマは100%同期することになります。契約があると双方のエンジニアは迷いなく実装に集中することができるので、開発体験は向上します。また、コストの多かった工程が自動生成と代わるため反復によるイテレーションコストは大幅に下がり、品質の高いプロダクトを生み出すことができます。
クリーンな実装
スキーマの制約があることで不要なエンドポイントなどを用意せずにクリーンなコードベースでの開発をすることができます
スキーマ中心のコミュニケーション
開発の中心がスキーマとなるので、コミュニケーションの軸が生まれ、スキーマ設計のより良い理解が双方に蓄積されることとなります。ひいてはビジネスドメインを理解し、よりニーズに沿った開発が進むことになります。
開発フロー
では、実際に開発フローを追いながらSDDがどのように実現されるのか見てみましょう。SPAの記事閲覧サービスを想定して、「記事登録API」が必要という仕様があるとします。開発言語としてはRailsでOpenAPIベースのGrapeエコシステムを活用した手法をとりました3。言語仕様についての理解は主題ではないので簡単に触れますと、Grapeエコシステムを活用すると「実装のためのコードがそのままスキーマ定義やモックやドキュメントになる」という特性を持ち、SDDを実現するために非常に役に立つものです。
当実装例はこちらのGitHubリポジトリにあげましたのでご参考ください。
- スキーマ定義
- モック&ドキュメント提供
- フィードバック
- 内部実装
1.スキーマ定義
まずはスキーマ定義を行いましょう。チャットなどのコミュニケーションツールを活用しスキーマ定義について合意します。
最初の段階では完全なスキーマではなくとも構いません。その後のフィードバックを迅速に対応できるからです。とはいえ、スキーマという共通言語をベースにコミュニケーションするので、かなりの割合で双方のニーズに則ったスキーマが出来上がります。
エンドポイント、リクエストプロパティ作成
合意したスキーマをもとに定義を記述していきます4。
記述のコードは言語仕様特有のものなので雰囲気だけ把握できればOKです。
class Articles < Grape::API
resources :articles do
desc '記事を新規登録します' do
detail '記事の新規登録'
success Entities::ArticleEntity
end
params do
requires :title, type: String, documentation: {param_type: 'body'}, desc: '新規記事タイトル', default: '新規記事タイトル例'
requires :content, type: String, documentation: {param_type: 'body'}, desc: '新規記事本文', default: '新規記事本文例'
end
post do
end
end
end
レスポンスエンティティ作成
module Entities
class ArticleEntity < Grape::Entity
expose :id, documentation: {type: Integer, desc: '記事ID', example: 1}
expose :title, documentation: {type: String, desc: '記事タイトル', example: '記事タイトル例'}
expose :content, documentation: {type: String, desc: '記事本文', example: '記事本文例'}
end
end
スキーマ定義が作成されました。これを軸に開発を進めていきます。
2. モック&ドキュメント提供
フロント側に提供するためのモックとドキュメントを生成します。また、このタイミングでRequest Validationも用意しておきます。ちなみに今回使用したGrapeエコシステムだとスキーマ定義で記述したものがそのままドキュメント、Request Validationになります。
自動生成されたドキュメント
現状で自動生成されたドキュメントを見てみましょう。ドキュメントはSwagger UIで閲覧できるようしました。実物はこちらのHeroku appにデプロイしてありますので実際に触ってみてください。
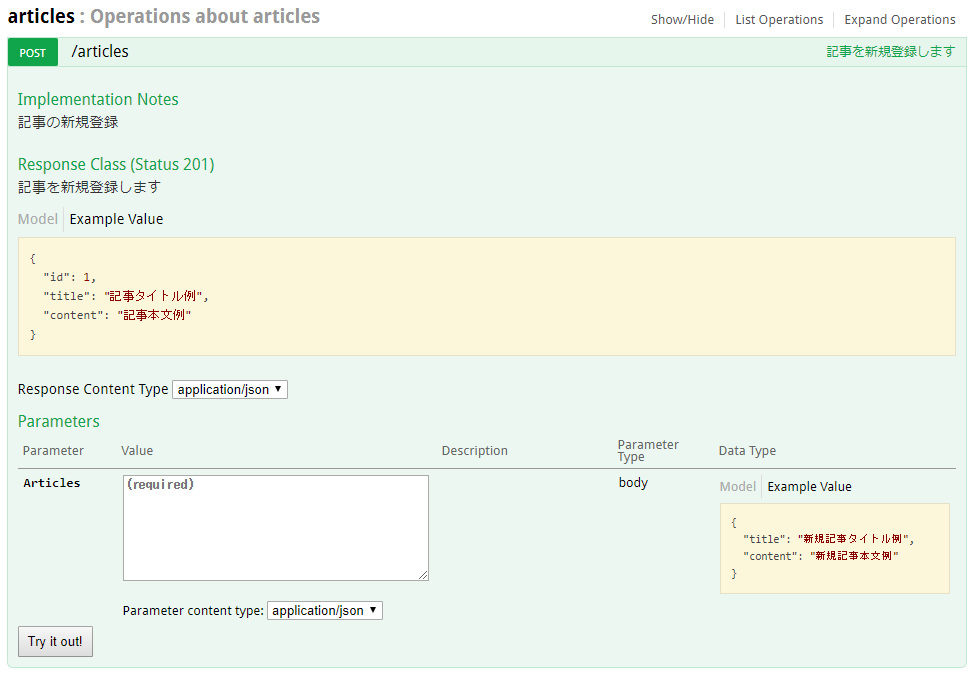
第1段階で用意したスキーマ定義がそのまま反映されていますね。modelタブを押すことで各フィールドの詳細を見ることもできます。フィールドごとのTypeやDescriptionを把握するときに重宝します。
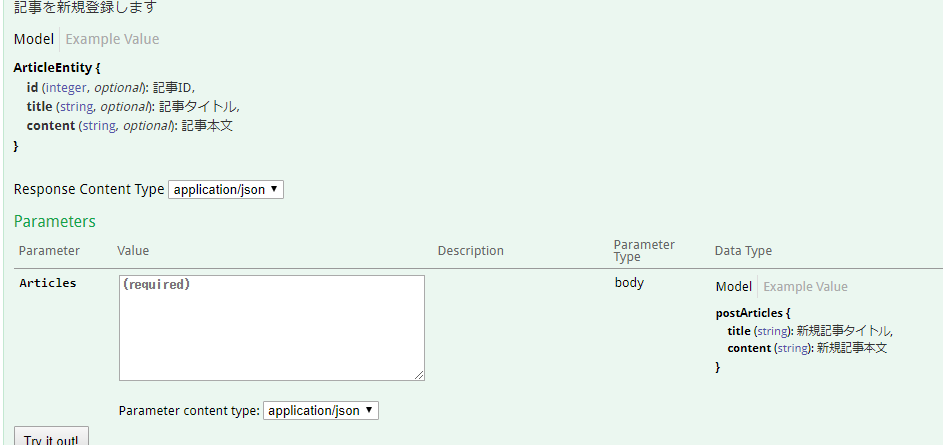
モック作成
上記のSwagger UIの「Example Value」にある理想のレスポンスJSONをコピーして、モック用のレスポンスとしてそのまま利用しましょう。
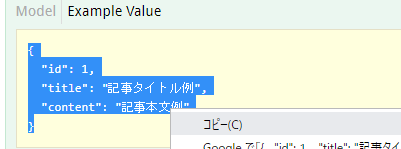
コピーして・・・
...
post do
response = {
"id": 1,
"title": "記事タイトル例",
"content": "記事内容例"
}
present response, with: Entities::ArticleEntity
end
...
レスポンスとして貼り付けます。これでモックとして動作するようになります。
自動生成されたモックとRequest Validation
Swagger UIの「Try it out!」で用意されたモックを見ることができます。
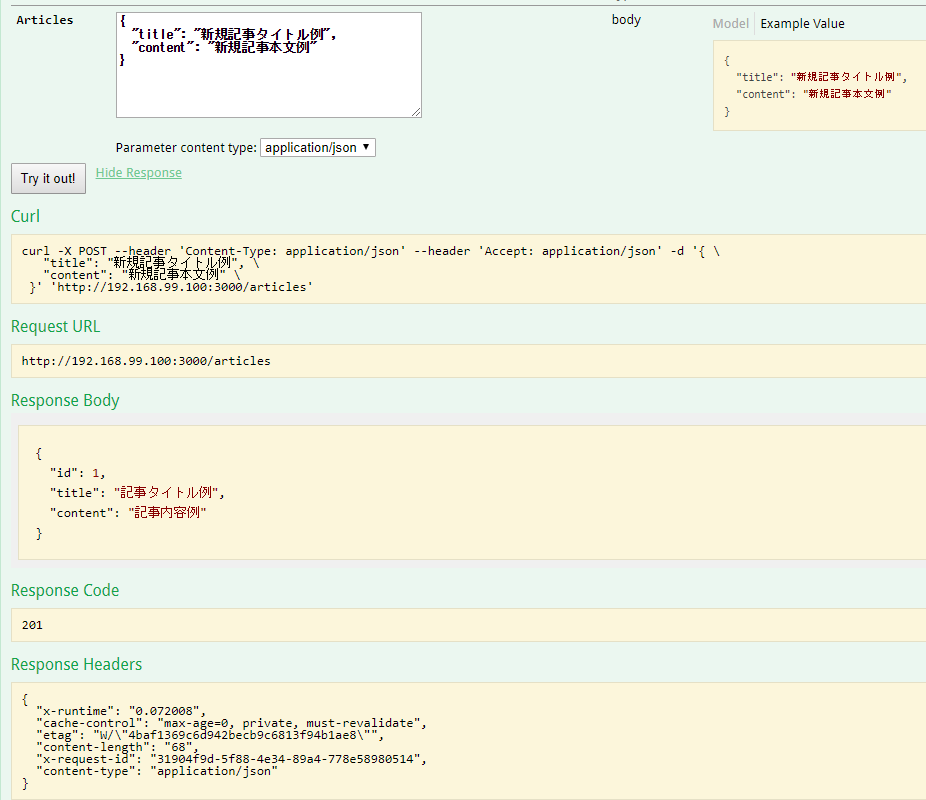
レスポンスコード201(リソース作成成功)とともにモックで用意したレスポンスボディが返却されていますね。
次にRequest Validationが動作しているか確認してみましょう。
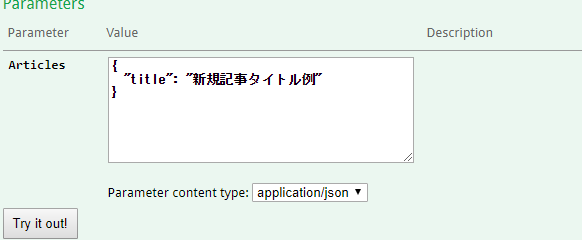
reqireパラムを一つ減らしてTry it out!
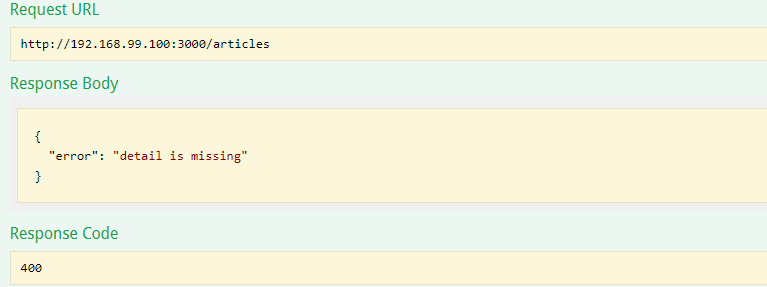
エラーコードとともにどのリクエストパラムが足りなかったかが取得されますね。動作しています。
これを開発用サーバーなどで見れる形にデプロイしてフロントに提供します。
3.フィードバック
モックを触ってもらうと、フロントのニーズに合わなかったスキーマが判明することがあります。ですので修正を反映しましょう。修正によるドキュメント改定などは自動生成で対応できますのでとても楽ですね。
追加でuser_idが欲しいというフィードバックがあった場合
各種スキーマ定義に追加するだけで・・・
class Articles < Grape::API
desc '記事を新規登録します' do
detail '記事の新規登録'
success Entities::ArticleEntity
end
params do
requires :title, type: String, documentation: {param_type: 'body'}, desc: '新規記事タイトル', default: '新規記事タイトル例'
requires :content, type: String, documentation: {param_type: 'body'}, desc: '新規記事本文', default: '新規記事本文例'
requires :user_id, type: Integer, documentation: {param_type: 'body'}, desc: '著者ユーザーID', default: 1
end
post do
response = {
"id": 1,
"title": "記事タイトル例",
"content": "記事内容例",
"user_id": 1
}
present response, with: Entities::ArticleEntity
end
end
end
module Entities
class ArticleEntity < Grape::Entity
expose :id, documentation: {type: Integer, desc: '記事ID', example: 1}
expose :title, documentation: {type: String, desc: '記事タイトル', example: '記事タイトル例'}
expose :content, documentation: {type: String, desc: '記事本文', example: '記事本文例'}
expose :user_id, documentation: {type: Integer, desc: '執筆者のユーザーID', example: 1}
end
end
生成されました。
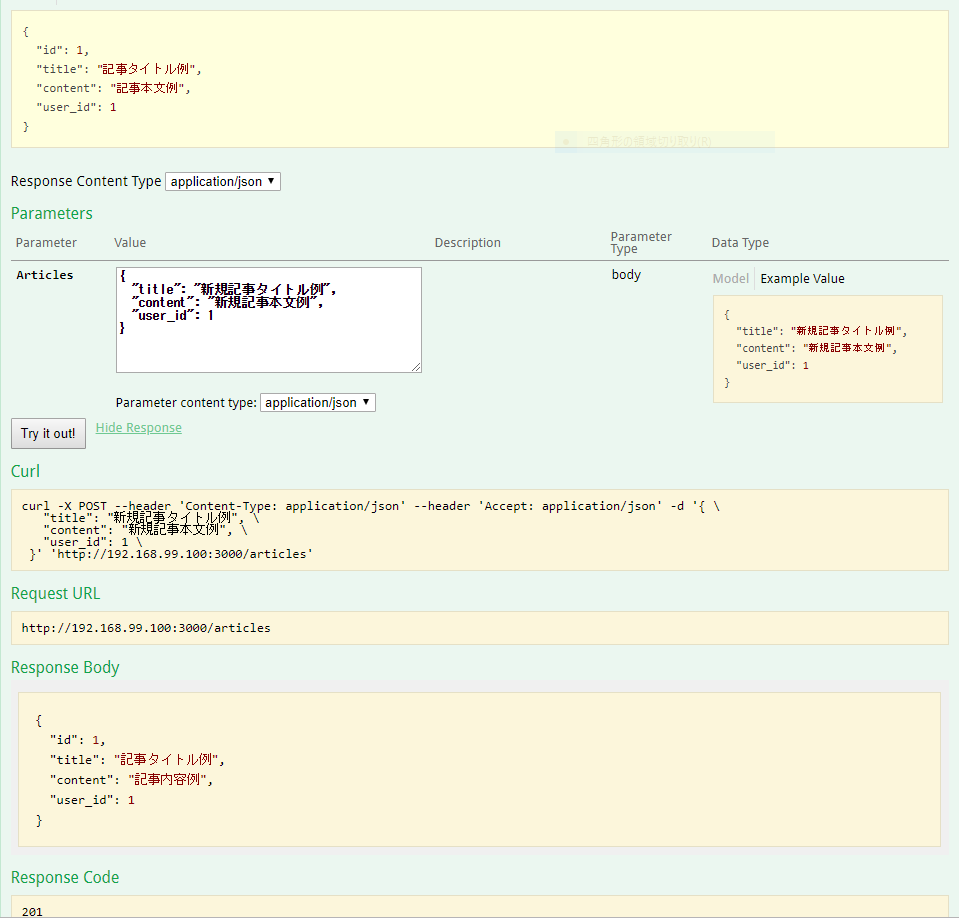
スキーマ定義に手を加えるだけでほぼ自動でドキュメントとモック共に反映されますね。SDDの開発サイクルが早い一因です。
4.内部実装
いよいよ具体的な内部の実装に取り掛かりましょう。このタイミングでモックだった部分を本実装し、Response Testとしてスキーマ定義とレスポンスエンティティが同型になるかをチェックするテストを用意します5、この際合意したスキーマ以上のことはしないようにしましょう(後で使うかもと入れた不要なエンドポイントなど)。100%信頼できるスキーマを守り、Response Testなどの契約を駆使して、合意したスキーマを再現できるようにしましょう。
その後
その後数度のイテレーションを通してクオリティを担保できるようになれば完成です。
まとめ
Schema-Driven-Developmentとは何か、そしてSDDを実現するための具体的なフローについて解説しました。
SDDが導入できると開発効率Upという恩恵だけでなく、開発体験の向上など様々な面でチームに良い影響をもたらすことが分かっています。
導入のためには多少の学習コストが必要かもしれませんが、道路整備さえ終えればすぐに効果を実感できるようになるはずです。積極的に開発フローの改善をする助けになれば幸いです。
参考文献
https://www.researchgate.net/publication/280105467_Schema-Driven_Development_of_Semantic_MediaWikis
https://nordicapis.com/using-a-schema-first-design-as-your-single-source-of-truth/
https://yos.io/2018/02/11/schema-first-api-design/
https://medium.com/@hintology/sdd-schema-driven-development-f1d232d73ea6
https://blog.onk.ninja/2017/09/21/schema_first_development
https://speakerdeck.com/spring_mt/api-spec-driven-development-with-swagger
https://speakerdeck.com/aeroastro/rails-meets-protocol-buffers-for-schema-first-development
https://www.prisma.io/blog/the-problems-of-schema-first-graphql-development-x1mn4cb0tyl3
https://developer.kaizenplatform.com/entry/laco/2018-06-08
-
実際のところ、「実装待ち」とはいってもそのタスクの優先順位を落として他の作業で手を埋めるでしょうが、そうしたタスク競争の状態が累積するとプロジェクトの成功率は下がります。 ↩
-
Single Source of Truth(SSOT)と呼ばれる情報デザイン原則でもあります。 ↩
-
Grapeエコシステム自体については後日解説記事をあげようと思っています。Rails特有の仕様にはなるので今回の概念的な説明には不要と判断しました。 ↩
-
記事では省略しましたがリポジトリに載せている例では先にテストを書いて落としてからスキーマ定義等の工程に移っています。 ↩
-
ちなみにGrapeエコシステムの場合スキーマ定義自体がシリアライザとして働くので実質的にResponse Testの役割は完了していると考えられます ↩