前置き
これまでPythonでJavaScriptが絡むウェブスクレイピングといえば、
BeautifulSoup+Selenium+PhantomJSが鉄板でした。
しかし、PhantomJSが開発終了したことでブラウザをChronium等に移行する傾向にあります。
そこで今回はPython 3.7とChroniumを使ったウェブスクレイピングについて記事にします。
必要なもの
Python関連
Python 3.7 (or 3.x)
bs4 (BeautifulSoup)
selenium
lxml
Chromedriver
ここから落としたあとに実行可能なパスに配置してください。
本稿で作るもの
Hyper Collocationという便利なサイトがあります。
Hyper Collocation とは?
arXivに収録されている 811,761報の 英語論文から,例文を検索するための検索エンジンです.前後の語の頻度でソートして結果を返すので典型的な用法の例文を得ることができ,コロケーション辞書のように利用できます.
(公式サイトより引用)
このサイトでキーワード検索することで、
例えば「"calculated"の前置詞はなにが一般的なんだろう?」といった疑問を解消してくれます。
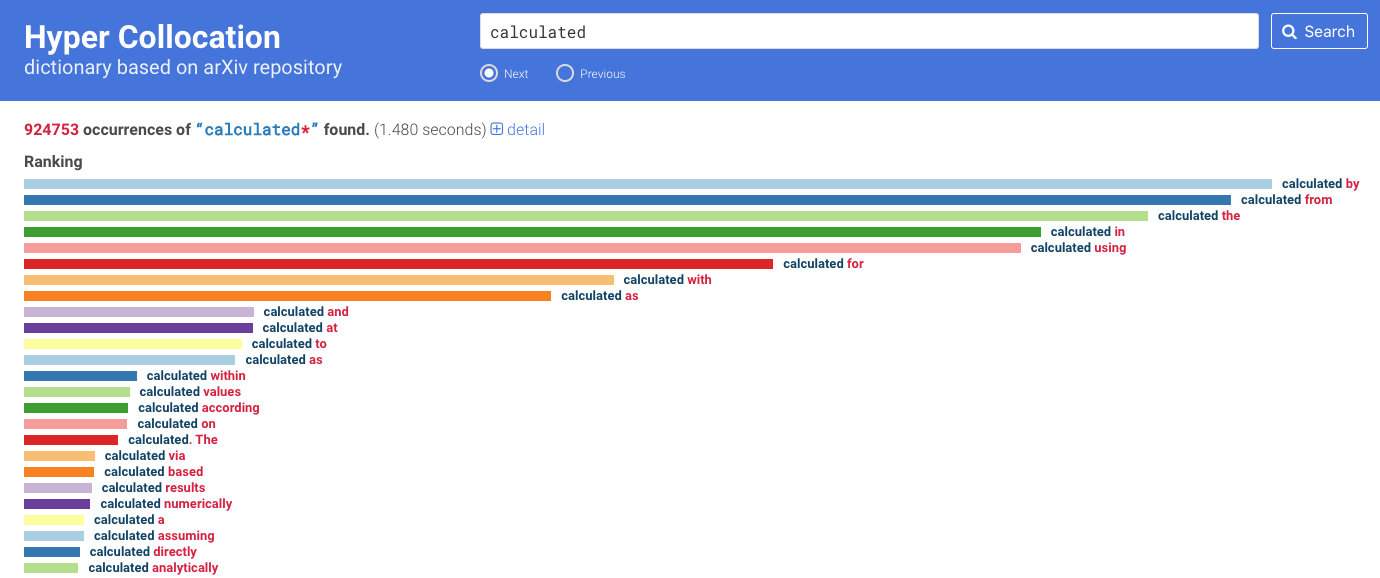
例文とキーワードが使用されているarXivのリンクまで載せてくれます。

今回はターミナルからこの検索結果を持ってくるものを作ります (完成品はこちら)。
静的なサイトからスクレイピングしたい場合はここまでスキップ。
実践
以後の説明ではファイル名を簡単のためmain.pyとします。
モジュールをインポート
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.keys import Keys
driverをセットアップする
options = ChromeOptions()
options.add_argument('--headless')
driver = Chrome(options=options)
2行目で--headlessを引数に追加することでウィンドウが開かなくしています。
デバッグ中はコメントアウトしても良いかもしれません。
試しに2行目をコメントアウトした状態で走らせてみましょう。
python main.py
後に続く処理がないのですぐ閉じてしまうと思いますがブラウザが立ち上がります。
以後、--headlessを追加しないままいくつか説明をします。
サイトにアクセス
Hyper Collocationに立ち上げたブラウザからアクセスします。
また、ブラウザがすぐ閉じないようにsleep()を使って処理を一時停止します。
from time import sleep
url = "https://hypcol.marutank.net/ja/"
driver.get(url)
sleep(200000)
python main.py
検索
実際にサイトを利用するとき、キーワードで検索するには
(a)検索ボックス選択、(b)キーワード入力、(c)決定の3つの手順が必要です。
これは今回のようにウェブスクレイピングをしている場合でも同じです。
まず、Chromeのデベロッパー(開発者)ツールで検索ボックスを指すElementを探します。
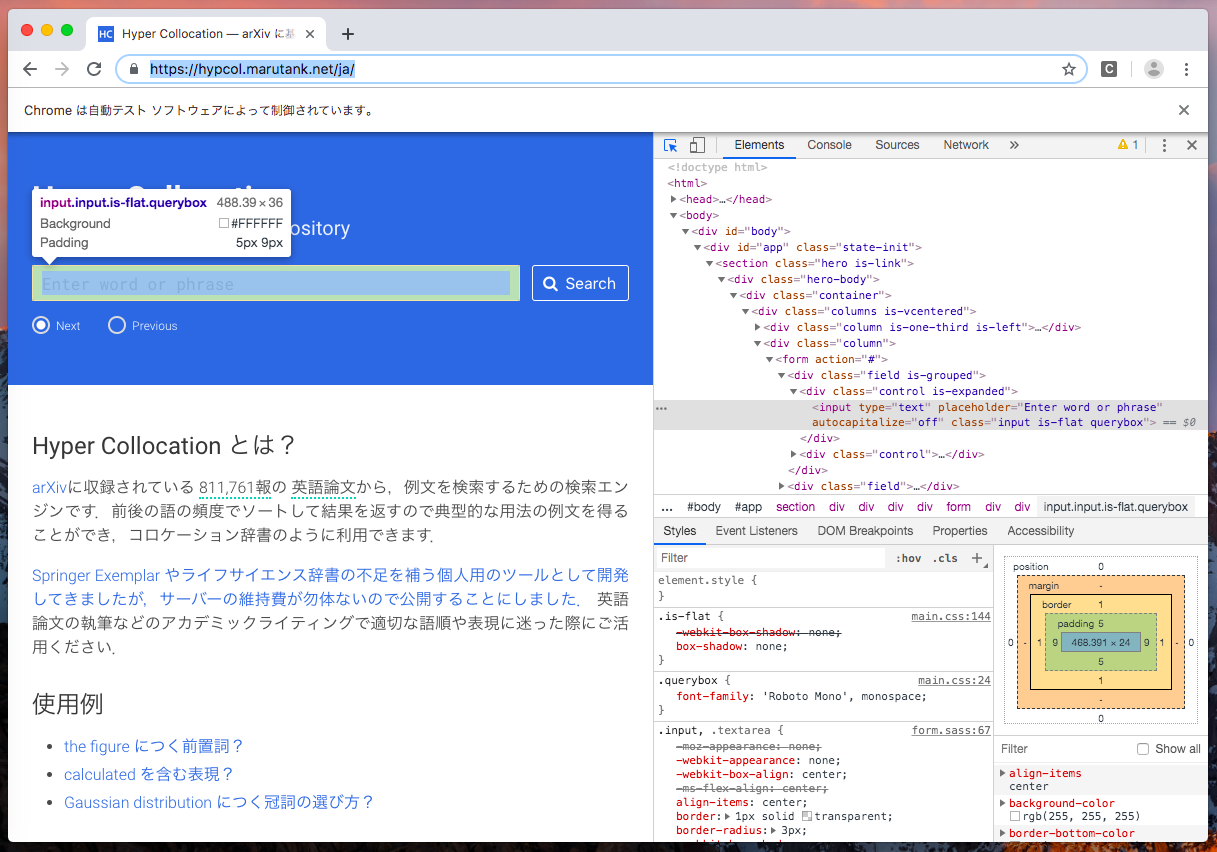
あとは手順(a), (b), (c)を順に行います。
今回はElementの指定にfind_element_by_class_name()というメソッドを使います。
名前の通りclass名で検索するものですが、他にもidやdivなどでも検索できます(詳しくはこちら)。
keyword = "calculated"
# (a) 検索ボックスを選択
input_element = driver.find_element_by_class_name("input")
# (b) キーワード入力
input_element.send_keys(keyword)
# (c) エンターキー押下
input_element.send_keys(Keys.RETURN)
python main.py
実行すると指定したキーワード(今回の例ではcalculated)で検索してくれるはずです。
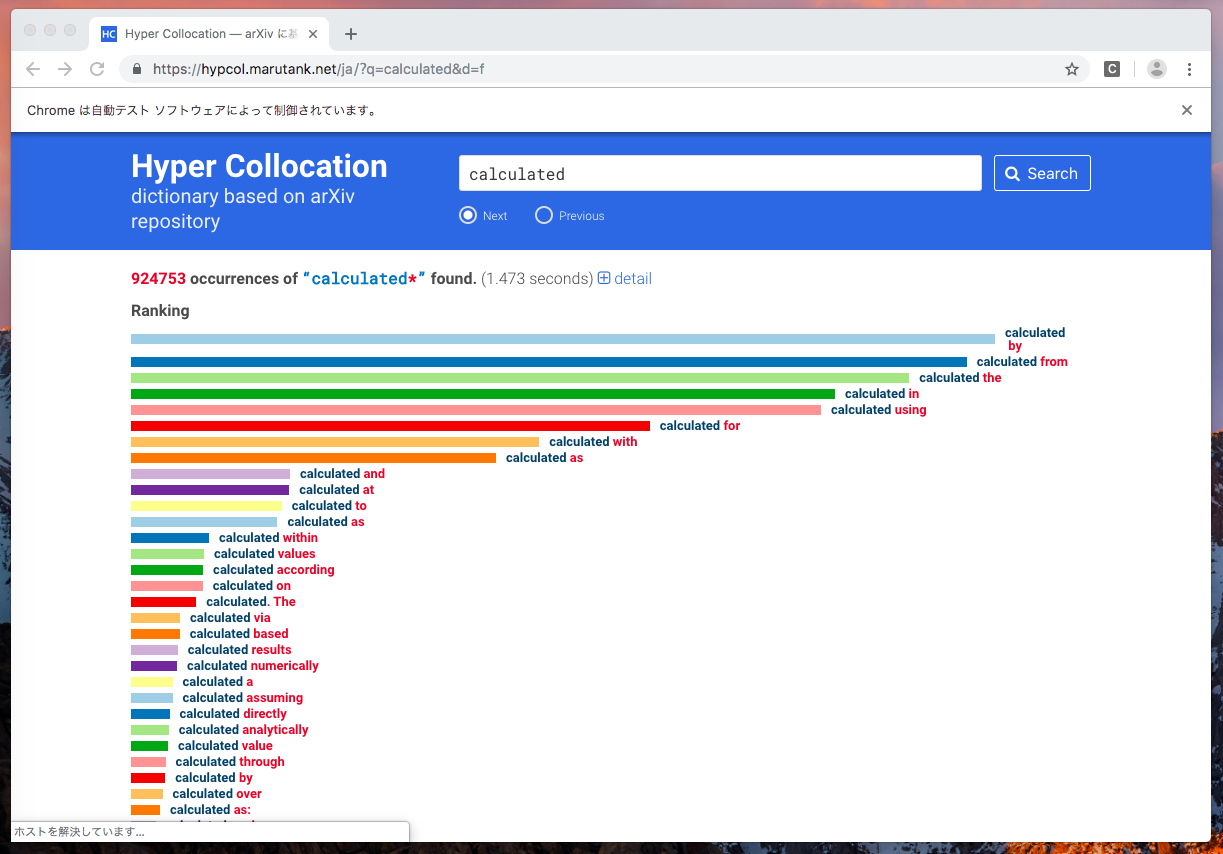
ここまでのスクリプトは以下のようになります。
# モジュールのインポート
from bs4 import BeautifulSoup
import lxml
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.keys import Keys
from time import sleep
# ドライバのセットアップ
options = ChromeOptions()
# options.add_argument('--headless')
driver = Chrome(options=options)
# サイトにアクセス
url = "https://hypcol.marutank.net/ja/"
driver.get(url)
# 検索
keyword = "calculated"
input_element = driver.find_element_by_class_name("input")
input_element.send_keys(keyword)
input_element.send_keys(Keys.RETURN)
# 処理を一時停止
sleep(20000)
BeautifulSoupでスクレイピング
まずdriverからソースのhtmlをもってきて、BeautifulSoup()でbs4.BeautifulSoupに変換します。
ここで、パーサにはlxmlを利用します。
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "lxml")
静的なサイト
また、JavaScriptで検索などをしない静的なサイトであれば
bs4.BeautifulSoupを得るためには以下のコードで足ります。
import requests
from bs4 import BeautifulSoup
# url指定
url = "https://www.google.com/"
# requestsでページをもってくる
r = requests.get(url)
# bs4.BeautifulSoupに変換
soup = BeautifulSoup(r.text, 'lxml')
つぎに、Chromeのデベロッパー(開発者)ツールを開いて検索結果のElementを探します。
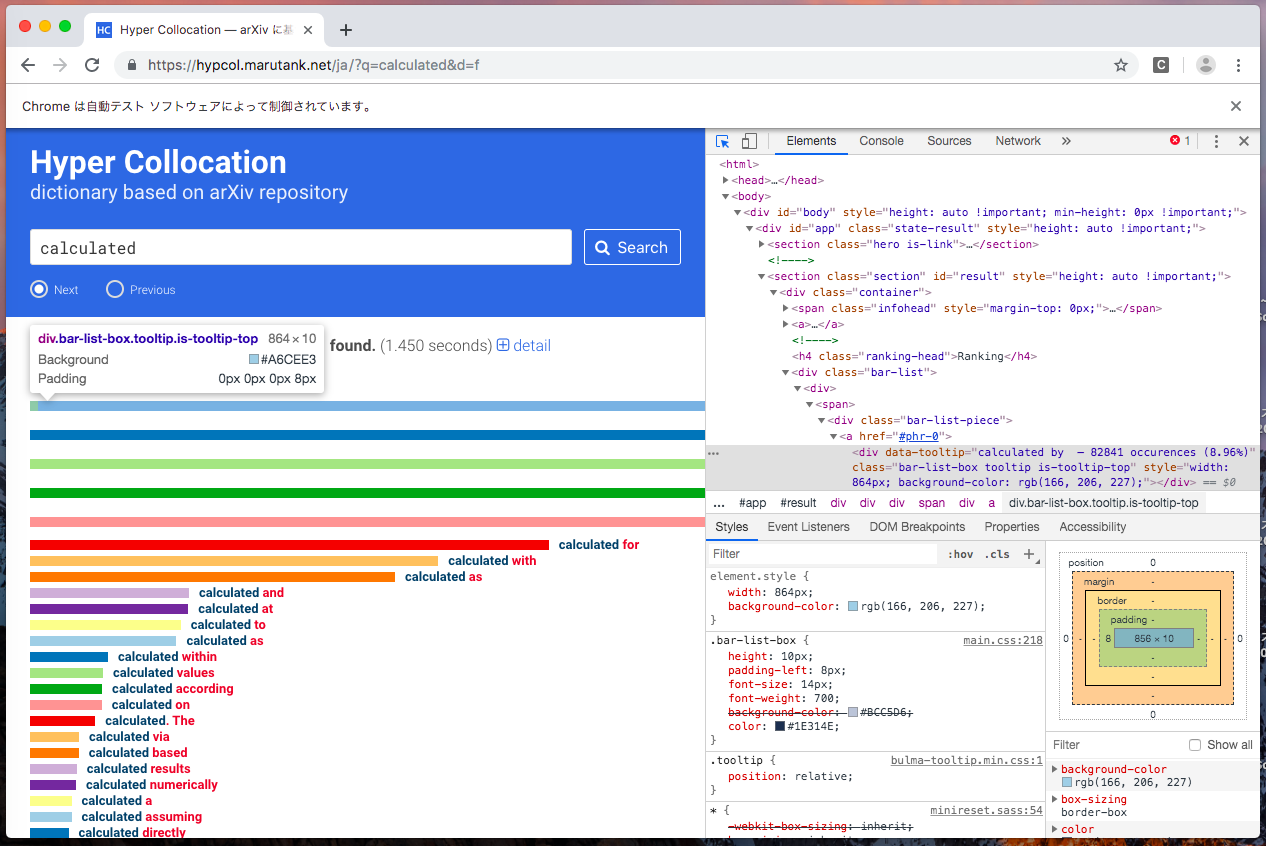
どうやらdivでclassが"bar-list-box tooltip is-tooltip-top"であるものを探せば良さそうです。
slist = soup.find_all("div", class_="bar-list-box tooltip is-tooltip-top")
これで、slistの中身は以下のようになるはずです。
[<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated by — 82841 occurences (8.96%)" style="width: 656px; background-color: rgb(166, 206, 227);"></div>,
<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated from — 80121 occurences (8.66%)" style="width: 634.461px; background-color: rgb(31, 120, 180);"></div>,
<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated the — 74610 occurences (8.07%)" style="width: 590.82px; background-color: rgb(178, 223, 138);"></div>,
<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated in — 67493 occurences (7.30%)" style="width: 534.463px; background-color: rgb(51, 160, 44);"></div>,
<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated using — 66158 occurences (7.15%)" style="width: 523.891px; background-color: rgb(251, 154, 153);"></div>,
<div class="bar-list-box tooltip is-tooltip-top" data-tooltip="calculated for — 49738 occurences (5.38%)" style="width: 393.864px; background-color: rgb(227, 26, 28);"></div>,
(以下省略)
ただ、実際にサイトを利用して分かる通り、検索結果を表示するまでには少し時間がかかります。
このサイトの場合、検索がおわるとclass="infohead"のElementが出現することがわかっています。
そこで必要な情報が得られるまで繰り返しスクレイピングする文を書きます。
infohead = []
while not len(infohead):
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "lxml")
slist = soup.find_all("div", class_="bar-list-box tooltip is-tooltip-top")
infohead = soup.find_all('span', class_="infohead")
また、回線速度などの理由でいつまでたっても検索が終了しない場合を考えて、ループに上限を設けます。
import sys
infohead = []
i = 0
while not len(infohead):
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "lxml")
slist = soup.find_all("div", class_="bar-list-box tooltip is-tooltip-top")
infohead = soup.find_all('span', class_="infohead")
i += 1
if(i > 1000):
print("TIME OUT")
sys.exit(1)
また、検索してもなにもヒットしなかった場合を想定した処理を加えます。
.textはhtmlのタグの部分を除去してくれる便利な機能です。
infohead = '\n' + infohead[0].text + '\n'
if not len(slist):
print(infohead)
sys.exit(1)
あとはデータを整形したり、それを出力するための処理を追加します。
これについては本稿の主旨からは逸れるので割愛します。
まとめ
- 引数でキーワードを指定可能にした
- 処理を関数に分割した
- 検索結果の表示件数を10件までとした
- データの整形・出力
以上を含めた実装がこちらになります。
スクレイピングのしやすさなどはサイトによりけりですが、
手順としては本稿で説明したものとほぼ差はないと思われます。
結局のところ、スクレイピングで大変なのはブラウザのセットアップやタグの検索ではなく
データの整形・出力方法を考えるところだと思います。