はじめに
毎日の日本株の株価データを公開している無尽蔵というサイトがあります。
ここから毎日自動で株価データを取得する方法について以前本サイトに投稿しました。
本投稿は、その続きであり、無尽蔵サイトから取得した毎日の株価データから、銘柄毎の株価日足時系列データを生成し、チャート表示させてみます。
無尽蔵サイトの株価データ
以下のようなcsv形式
2020/11/20,1001,11,1001 日経225,25486,25555,25425,25527,1088960000,東証1部
2020/11/20,1002,11,1002 TOPIX,1721,1727,1717,1727,1088960000,東証1部
2020/11/20,1301,11,1301 極洋,2848,2848,2820,2832,10200,東証1部
2020/11/20,1305,11,1305 ダイワTPX,1807,1815,1804,1813,403730,東証1部
2020/11/20,1306,11,1306 TOPIX投,1785,1794,1782,1792,944230,東証1部
...
2020/11/20,1712,31,1712 ダイセキ環境,0,0,0,0,0,名古1部
2020/11/20,1712,11,1712 ダイセキ環境,698,700,693,700,24100,東証1部
...
2020/11/20,9996,91,9996 サトー商会,1472,1490,1439,1490,1100,JAQ
2020/11/20,9997,11,9997 ベルーナ,924,928,907,916,199600,東証1部
特徴としては、次のようなかんじ。
- 4本値+出来高
- 「日経225」と「TOPIX」には独自の証券コードが割り振られている。
- 名証と東証に重複上場している銘柄は、両方の行がある。
- 出来なかった銘柄の株価は0
- 株式分割した際の調整株価のデータがない
- ときどきファイルに文字化けが発生している。
- 1996年以降のデータが置かれている。
株価データのurlの例
2019年以降
http://mujinzou.com/k_data/2020/20_01/T200106.zip
http://mujinzou.com/k_data/2019/19_01/T190107.zip
2015年~2018年
http://souba-data.com/k_data/2018/18_01/T180104.zip
1996年~2014年
http://souba-data.com/k_data/1996/96_01/T960104.lzh
2015年以降はzipで、それ以前はlzhで圧縮されています。lzhとは懐かしい。
とりあえず、数年分取得してみる。
必要に応じ、正しいbase_urlを選び、main()の取得期間を書き換える。
単なる力づくの実装例ということで。
# -*- coding: utf-8 -*-
"""
[無尽蔵]から過去のTyymmdd.zipを取得する
"""
import urllib.request
import zipfile
import datetime
import os
import logging
import sys
def download_csv_zip(output_dir, year, month, day):
base_url = 'http://mujinzou.com/k_data/'+str(year)+'/'
#base_url = 'http://souba-data.com/k_data/'+str(year)+'/'
subdir = '{0:02d}_{1:02d}/'.format(year-2000, month)
filename = 'T{0:02d}{1:02d}{2:02d}.zip'.format(year-2000, month, day)
url = base_url + subdir + filename
now = datetime.datetime.now()
try:
urllib.request.urlretrieve(url, filename)
with zipfile.ZipFile(filename, 'r')as zf:
zf.extractall(output_dir)
os.remove(filename)
logging.info(str(now)+' success to get file: '+filename)
except urllib.error.HTTPError:
logging.error(str(now)+' error')
def main():
args = sys.argv
if len(args)==2:
output_dir = args[1]
if output_dir[-1]!='/':
output_dir = output_dir + '/'
else:
output_dir = './'
logging.basicConfig(level=logging.INFO)
for yy in range(2019, 2021):
for mm in range(1, 13):
for dd in range(1, 32):
download_csv_zip(output_dir, yy, mm, dd)
if __name__ == '__main__':
main()
銘柄毎の株価日足時系列データの生成
必要な期間の株価データTyymmdd.csvを取得したら、それらから銘柄毎の株価日足時系列データを生成します。
株価日足時系列データのcsvファイルの例は以下。
2015/01/05,275,277,274,275,239000000
2015/01/06,274,275,270,272,480000000
2015/01/07,270,273,270,271,217000000
...
2020/11/25,2839,2846,2795,2831,27800000
2020/11/26,2820,2826,2801,2809,8700000
2020/11/27,2807,2825,2803,2819,22000000
以下のディレクトリ構成を前提としています。
working_root/
daily_data/
2015/
T150105.csv
...
...
2020/
T200106.csv
T200107.csv
...
T201120.csv
data/
1000/
1001.csv
1002.csv
...
2000/
...
9000/
9001.csv
...
これも、単なる力づくの実装例ということで。
# -*- coding: utf-8 -*-
"""
[無尽蔵]の過去の日足株価データから銘柄毎の株価日足時系列データを生成
"""
import glob
import os
def add_data(code, date_str, cv1, cv2, cv3, cv4, cvc):
code_dir = int(code/1000)*1000
out_path = "./Data/" + str(code_dir) + "/" + str(code) + ".csv"
line = date_str+','+cv1+','+cv2+','+cv3+','+cv4+','+str(int(float(cvc)*1000))+'\n'
with open(out_path,'a') as f:
f.write(line)
def import_daily_data(import_year):
daily_files = glob.glob('./daily_data/{}/*.csv'.format(import_year))
for daily_file in daily_files:
filename = os.path.basename(daily_file)
yy = 2000 + int(filename[1:3])
mm = int(filename[3:5])
dd = int(filename[5:7])
date_str = '{0:4d}/{1:02d}/{2:02d}'.format(yy, mm, dd)
with open(daily_file, mode='rb') as fd:
lines = fd.readlines()
for i, line in enumerate(lines):
try:
line = line.decode('cp932')
except:
print('error file {}: line {}'.format(daily_file, i))
# utf-8でないバイト列が含まれる行はスキップする
continue
line = line.rstrip()
line_list = line.split(',')
if len(line_list)==10:
if len(line_list[1])==4:
code = int(line_list[1])
market = line_list[9]
if '名古' in market:
next_line = lines[i+1]
next_line = next_line.decode('cp932')
next_line_list = next_line.split(',')
next_code = int(next_line_list[1])
if next_code!=code:
add_data(code, date_str, line_list[4], line_list[5], line_list[6], line_list[7], line_list[8])
else:
add_data(code, date_str, line_list[4], line_list[5], line_list[6], line_list[7], line_list[8])
else:
print('error file {}: line {} : {}'.format(daily_file, i, line))
def main():
for year in range(2015, 2021):
import_daily_data(year)
if __name__ == '__main__':
main()
- 名証と東証に重複上場している銘柄は、元データには両方の行が入ってますが、ここでは、東証だけを抽出しています。
- 東証とJASDAQの重複上場も過去にあったっぽいけど、未対応。
- 株式分割した際は未調整のまま。
- ファイルの文字化けは、デバッグの過程で見つかったものは対応しましたが、文字化けがあった銘柄の株価は欠落となります。
株価チャート表示
こうして得られた銘柄毎の株価日足時系列データのcsvファイルからmplfinanceを使ってローソク足チャートを表示してみます。
import pandas as pd
import mplfinance as mpf
def load_stock_price_csv(path):
df = pd.read_csv(path, header=None, names=['Date','Open','High','Low','Close','Volume'], encoding='UTF-8')
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index("Date")
return df
def main():
df = load_stock_price_csv('./data/1000/1001.csv')
mpf.plot(df, type='candle', volume=True)
if __name__ == '__main__':
main()
結果はこれ。
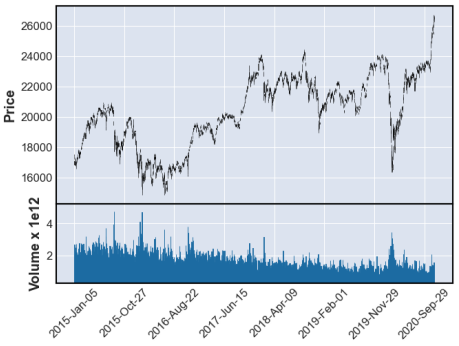
株式分割後株価の調整
この銘柄毎の株価日足時系列データは、株式分割後株価の調整がなされていません。
例えば、日本版コストコとの呼び名もある「業務スーパー」でお馴染みの「3038 神戸物産」のチャートを見てみると、このようになります。
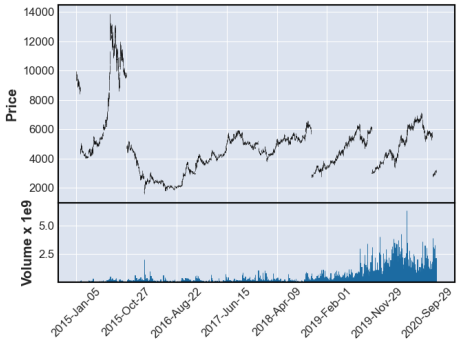
2015年以降、なんと5回も分割してるんですね。恐るべし。
こんなチャートでは使い物にならないので、株価調整は必要ですね。証券会社のサイトには、株式分割の履歴がまとめられていますから、これを取り込んで調整するべきなんでしょうが、なるべくお手軽にやりたいんで、自動調整を試みます。
- 値幅制限以上の変動があったら、株式分割があったものとみなし、自動調整する。
という方針でやってみます。分割比率が1:2とかだったらこれでいいんですが、分割比率が1:1.1とか1.1.2とかもある訳で、そのような場合は分割を見逃してしまいます。自動調整の限界ですかね。
値幅制限以上の変動を調べるコードを力づくで書きました。
from collections import namedtuple
PriceLimit = namedtuple("PriceLimit", "l h w")
price_limit_table1 = [
PriceLimit(0, 100, 30),
PriceLimit(100, 200, 50),
PriceLimit(200, 500, 80),
PriceLimit(500, 700, 100),
PriceLimit(700, 1000, 150),
]
price_limit_table2 = [
PriceLimit(1000, 1500, 300),
PriceLimit(1500, 2000, 400),
PriceLimit(2000, 3000, 500),
PriceLimit(3000, 5000, 700),
PriceLimit(5000, 7000, 1000),
PriceLimit(7000, 10000, 1500),
]
def normal_price(v0, v):
if v==0 or v0==0:
return True
for price_limit in price_limit_table1:
if price_limit.l<=v0 and v0<price_limit.h:
if abs(v-v0)<=price_limit.w:
return True
else:
return False
for i in range(0, 5):
a = pow(10, i)
for price_limit in price_limit_table2:
if price_limit.l*a<=v0 and v0<price_limit.h*a:
if abs(v-v0)<=price_limit.w*a:
return True
else:
return False
if abs(v-v0)<=10000000:
return True
else:
return False
normal_price()に前日と当日の終値を与えると、値幅制限以内ならTrueを返します。
実はこれは正確ではなく、以下のルールが未実装です。
- 連続してストップ高やストップ安が続いた場合、値幅制限が拡大する場合がある
- 値幅制限いっぱいになったとき、呼値以下の桁をまるめる
株価調整の力づくの実装例は以下です。pandasで読み込んだ表を渡します。
pandasの表を更新するところは、突っ込みどころ満載でしょうがお目こぼしを。
import pandas as pd
from decimal import Decimal, ROUND_HALF_EVEN
def adjust_price_value(df):
n = len(df)
adjust_rate = 1.0
v0 = df['Close'][n-1]
for i in reversed(range(0, n-2)):
v = df['Close'][i]
if not normal_price(v0, v):
next_adjust_rate = v0 / v
if next_adjust_rate>=1.0:
next_adjust_rate = int(Decimal(str(next_adjust_rate)).quantize(Decimal('0'), rounding=ROUND_HALF_EVEN))
else:
rev_next_adjust_rate = v / v0
rev_next_adjust_rate = int(Decimal(str(rev_next_adjust_rate)).quantize(Decimal('0'), rounding=ROUND_HALF_EVEN))
next_adjust_rate = 1.0/rev_next_adjust_rate
adjust_rate = adjust_rate * next_adjust_rate
print('i={}, v0={}, v={} radjust={}'.format(i, v0, v, adjust_rate))
v0 = v
if adjust_rate!=1.0:
df.iloc[i, 0] = int(df.Open[i]*adjust_rate)
df.iloc[i, 1] = int(df.High[i]*adjust_rate)
df.iloc[i, 2] = int(df.Low[i]*adjust_rate)
df.iloc[i, 3] = int(df.Close[i]*adjust_rate)
df.iloc[i, 4] = int(df.Volume[i]/adjust_rate)
このコードを使って調整したチャートをプロットします。
def load_stock_price_csv(path):
df = pd.read_csv(path, header=None, names=['Date','Open','High','Low','Close','Volume'], encoding='UTF-8')
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index("Date")
adjust_price_value(df)
return df
def main():
df = load_stock_price_csv('./data/3000/3038.csv')
mpf.plot(df, type='candle', volume=True)
で、結果はこれ。
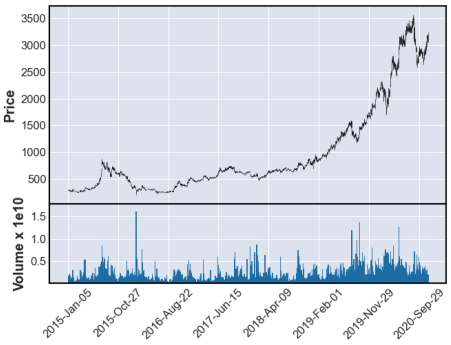
業務スーパー恐るべし。