はじめに
Pandas-datareaderは、株価データを取得するのに重宝するのですが、残念なことにデータの欠落がある場合があります。例えば、Stooqで、「1357NF日経ダブルインバース」を取得すると、
import pandas_datareader.stooq as web
from datetime import datetime
start_date = datetime(2016,6,10)
end_date = datetime(2016,6,17)
dr = web.StooqDailyReader('1357.JP', start=start_date, end=end_date)
df = dr.read()
df.to_csv('1357.csv')
以下のようなcsvファイルが得られます。
1357.csv
Date,Open,High,Low,Close,Volume
2016-06-17,3330,3380,3290,3370,8019724
2016-06-16,3270,3465,3250,3450,10403857
2016-06-14,3220,3315,3185,3270,9910736
2016-06-13,3105,3205,3100,3200,8193928
2016-06-10,2981,3040,2977,3000,4247241
2016-06-15のデータが欠落しています。ひょっとしたら、この日はシステムトラブルか何かで出来なかったのでは?と思い、Yahoo!Finance.の時系列データを確認すると、
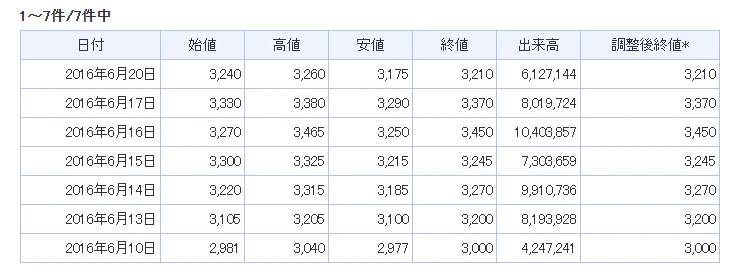
Yahoo!Finance.では、その日のデータは存在していました。
nikkei225インデックスを取得してみると、
import pandas_datareader.stooq as web
from datetime import datetime
start_date = datetime(2016,6,10)
end_date = datetime(2016,6,17)
dr = web.StooqDailyReader('^NKX', start=start_date, end=end_date)
df = dr.read()
df.to_csv('NIKKEI225.csv')
欠落はありませんでした。
NIKKEI225.csv
Date,Open,High,Low,Close,Volume
2016-06-17,15631.79,15774.87,15582.94,15599.66,1671723008
2016-06-16,15871.22,15913.08,15395.98,15434.14,1542472064
2016-06-15,15799.07,15997.3,15752.01,15919.58,1367727744
2016-06-14,16001.19,16082.5,15762.09,15859.0,1316932864
2016-06-13,16319.11,16335.38,16019.18,16019.18,1261788416
2016-06-10,16637.51,16643.36,16496.11,16601.36,1549976064
欠落は銘柄によるようです。
データ欠落の対策
銘柄によって欠落があったりなかったり。このままでは、株価を比較したりする局面で重大な誤りを生じる恐れがあるので、欠落行を除くなり補間するなりが必要です。
pandasを使用して、2つの表をマージすることにより、欠落行を除くなり補うなりすることができます。
import pandas as pd
nikkei225 = pd.read_csv('NIKKEI225.csv').set_index('Date').sort_index()
n1357 = pd.read_csv('1357.csv').set_index('Date').sort_index()
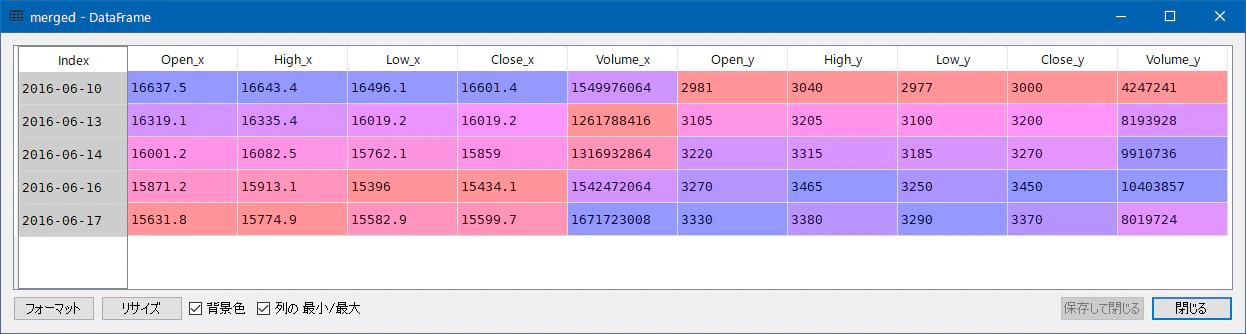
merged = pd.DataFrame.merge(nikkei225, n1357, on='Date', how='inner')
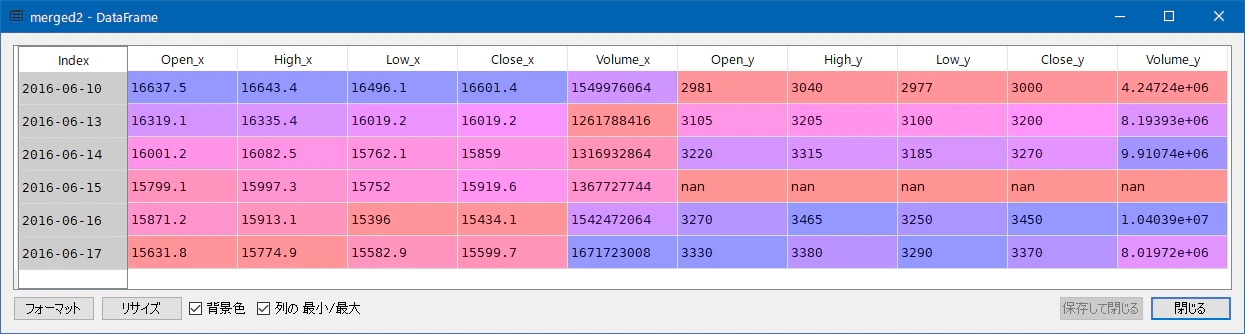
merged2 = pd.DataFrame.merge(nikkei225, n1357, on='Date', how='outer')
mergedは、欠落行が取り除かれた結果を得ます。
merged2では、欠落行がNaNで埋められます。
欠落行を補間するには、一旦NaNで埋めてから、必要な値に補間したらよいでしょう。
欠落を補う方法は、以下の記事で解説されています。
https://qiita.com/kazama0119/items/c838114f8687518ba58e
データ分析で株価予測をしてみた