はじめに
PyTorchで画像分類していきまーす!
開発環境
- Windows 11 PC
- Python 3.10
- PyTorch
PyTorchのインストールはここから
https://pytorch.org/get-started/locally/

anacondaで仮想環境作って、pipのみでインストールする派です(混ぜると危険)
導入
1.KaggleのDogs vs. Catsからデータセットをダウンロードします
https://www.kaggle.com/competitions/dogs-vs-cats/data
2.trainデータをcatフォルダとdogフォルダに分けます
dataset.py
import os
import shutil
# トレーニングデータセットのパスと移動先フォルダのパスを指定
dataset_path = "dogs-vs-cats/train"
cat_folder_path = "dogs-vs-cats/train/cat"
dog_folder_path = "dogs-vs-cats/train/dog"
# 移動先フォルダが存在しない場合は作成
os.makedirs(cat_folder_path, exist_ok=True)
os.makedirs(dog_folder_path, exist_ok=True)
# 画像ファイルの移動
for filename in os.listdir(dataset_path):
if filename.startswith("cat."):
src_path = os.path.join(dataset_path, filename)
dst_path = os.path.join(cat_folder_path, filename)
shutil.move(src_path, dst_path)
elif filename.startswith("dog."):
src_path = os.path.join(dataset_path, filename)
dst_path = os.path.join(dog_folder_path, filename)
shutil.move(src_path, dst_path)
print("画像ファイルの移動が完了しました。")
3.testデータにはラベルがついていないので、今回はtrainデータから20%をtestデータとします
dataset_split.py
import os
import random
import shutil
# トレーニングデータセットとテストデータセットのパスを指定
train_dataset_path = "dogs-vs-cats/train"
test_dataset_path = "dogs-vs-cats/test"
# テストデータセットのフォルダを作成
os.makedirs(os.path.join(test_dataset_path, "cat"), exist_ok=True)
os.makedirs(os.path.join(test_dataset_path, "dog"), exist_ok=True)
# トレーニングデータセットのcatフォルダからファイルリストを取得
cat_files = os.listdir(os.path.join(train_dataset_path, "cat"))
random.shuffle(cat_files)
# トレーニングデータセットのdogフォルダからファイルリストを取得
dog_files = os.listdir(os.path.join(train_dataset_path, "dog"))
random.shuffle(dog_files)
# テストデータセットに移動するファイル数の計算
num_cat_files = int(0.2 * len(cat_files))
num_dog_files = int(0.2 * len(dog_files))
# テストデータセットへのcatファイルの移動
for filename in cat_files[:num_cat_files]:
src_path = os.path.join(train_dataset_path, "cat", filename)
dst_path = os.path.join(test_dataset_path, "cat", filename)
shutil.move(src_path, dst_path)
# テストデータセットへのdogファイルの移動
for filename in dog_files[:num_dog_files]:
src_path = os.path.join(train_dataset_path, "dog", filename)
dst_path = os.path.join(test_dataset_path, "dog", filename)
shutil.move(src_path, dst_path)
print("テストデータの作成が完了しました。")
4.学習していきます
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
from torchvision import models
from tqdm import tqdm # pip install tqdm
# ハイパーパラメータの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 32
learning_rate = 0.001
# データの前処理
transform = transforms.Compose(
[
transforms.Resize((224, 224)), # 画像サイズのリサイズ
transforms.ToTensor(), # テンソルへの変換
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
), # データの正規化
]
)
# データセットの読み込み
train_dataset = ImageFolder(root="dogs-vs-cats/train", transform=transform)
test_dataset = ImageFolder(root="dogs-vs-cats/test", transform=transform)
# データローダの作成
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# モデルの定義
model = models.resnet18(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 2) # クラス数に応じて最終層の出力ユニット数を変更
model = model.to(device)
# 損失関数と最適化アルゴリズムの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# エポックループ
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
# バッチループ
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}"):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_accuracy = correct_predictions / len(train_dataset)
train_loss = running_loss / len(train_loader)
# テストデータでの評価
model.eval()
with torch.no_grad():
correct_predictions = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
test_accuracy = correct_predictions / len(test_dataset)
print(
f"Epoch {epoch+1}/{num_epochs} - Loss: {train_loss:.4f} - Train Accuracy: {train_accuracy:.4f} - Test Accuracy: {test_accuracy:.4f}"
)
# 最終モデルの保存
torch.save(model.state_dict(), "model.pt")
Epoch 1/10: 100%|████████████████████████| 625/625 [01:30<00:00, 6.94it/s]
Epoch 1/10 - Loss: 0.1728 - Train Accuracy: 0.9297 - Test Accuracy: 0.9490
Epoch 2/10: 100%|████████████████████████| 625/625 [01:28<00:00, 7.07it/s]
Epoch 2/10 - Loss: 0.7002 - Train Accuracy: 0.5187 - Test Accuracy: 0.5454
Epoch 3/10: 100%|████████████████████████| 625/625 [01:27<00:00, 7.15it/s]
Epoch 3/10 - Loss: 0.6525 - Train Accuracy: 0.6085 - Test Accuracy: 0.6446
Epoch 4/10: 100%|████████████████████████| 625/625 [01:28<00:00, 7.02it/s]
Epoch 4/10 - Loss: 0.5684 - Train Accuracy: 0.6975 - Test Accuracy: 0.7608
Epoch 5/10: 100%|████████████████████████| 625/625 [01:26<00:00, 7.18it/s]
Epoch 5/10 - Loss: 0.4284 - Train Accuracy: 0.7994 - Test Accuracy: 0.8442
Epoch 6/10: 100%|████████████████████████| 625/625 [01:44<00:00, 5.96it/s]
Epoch 6/10 - Loss: 0.3357 - Train Accuracy: 0.8502 - Test Accuracy: 0.8776
Epoch 7/10: 100%|████████████████████████| 625/625 [01:26<00:00, 7.22it/s]
Epoch 7/10 - Loss: 0.2680 - Train Accuracy: 0.8836 - Test Accuracy: 0.8998
Epoch 8/10: 100%|████████████████████████| 625/625 [01:27<00:00, 7.14it/s]
Epoch 8/10 - Loss: 0.2206 - Train Accuracy: 0.9064 - Test Accuracy: 0.9090
Epoch 9/10: 100%|████████████████████████| 625/625 [01:26<00:00, 7.19it/s]
Epoch 9/10 - Loss: 0.1787 - Train Accuracy: 0.9261 - Test Accuracy: 0.9270
Epoch 10/10: 100%|███████████████████████| 625/625 [02:05<00:00, 4.96it/s]
Epoch 10/10 - Loss: 0.1496 - Train Accuracy: 0.9364 - Test Accuracy: 0.9264
5.推論します
predict.py
import torch
from torchvision.transforms import transforms
import torchvision.models as models
from PIL import Image
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデルの定義と最終層の修正
model = models.resnet18(pretrained=True)
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, 2) # クラス数に応じて最終層の出力ユニット数を修正
# 学習済みモデルの重みを読み込む
model.load_state_dict(torch.load("model.pt"))
model.to(device)
model.eval()
# 画像の前処理
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# 推論用の画像を読み込む
image_path = "dogs-vs-cats/test1/1.jpg"
image = Image.open(image_path)
image = transform(image).unsqueeze(0).to(device)
# 推論の実行
with torch.no_grad():
output = model(image)
# 推論結果の解析
_, predicted = torch.max(output.data, 1)
class_index = predicted.item()
print(class_index)
| 入力画像 | 推論結果 |
|---|---|
 |
1 |
 |
0 |
train_dataset.classesからクラスを確認できます
['cat', 'dog']
0が猫、1が犬です
いい感じですね!お疲れ様でした。
追記
モデル一覧
ResNet152
train_resnet.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
# from torchvision.models import vision_transformer
from torchvision import models
from tqdm import tqdm # pip install tqdm
import timm # pip install timm
# ハイパーパラメータの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 16 # 32
learning_rate = 0.0001
# データの前処理
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# データセットの読み込み
train_dataset = ImageFolder(root="dogs-vs-cats/train", transform=transform)
test_dataset = ImageFolder(root="dogs-vs-cats/test", transform=transform)
# データローダの作成
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# モデルの定義
# model = models.resnet18(pretrained=True)
model = models.resnet152(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 2) # クラス数に応じて最終層の出力ユニット数を変更
model = model.to(device)
# EfficientNetモデルの定義
# model = models.efficientnet_b2(pretrained=True)
# model = models.efficientnet_v2_s(pretrained=True)
# model = model.to(device)
# ViTモデルの定義
# model = timm.create_model("vit_base_patch16_224", pretrained=False, num_classes=2)
# model = model.to(device)
# 損失関数と最適化アルゴリズムの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
best_accuracy = 0.0
best_model_path = "best_model.pt"
# エポックループ
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
# バッチループ
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}"):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_accuracy = correct_predictions / len(train_dataset)
train_loss = running_loss / len(train_loader)
# テストデータでの評価
model.eval()
with torch.no_grad():
correct_predictions = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
test_accuracy = correct_predictions / len(test_dataset)
# Check if current model has the best accuracy
if test_accuracy > best_accuracy:
best_accuracy = test_accuracy
torch.save(model.state_dict(), best_model_path)
print(
f"Epoch {epoch+1}/{num_epochs} - Loss: {train_loss:.4f} - Train Accuracy: {train_accuracy:.4f} - Test Accuracy: {test_accuracy:.4f}"
)
# 最終モデルの保存
# torch.save(model.state_dict(), "model.pt")
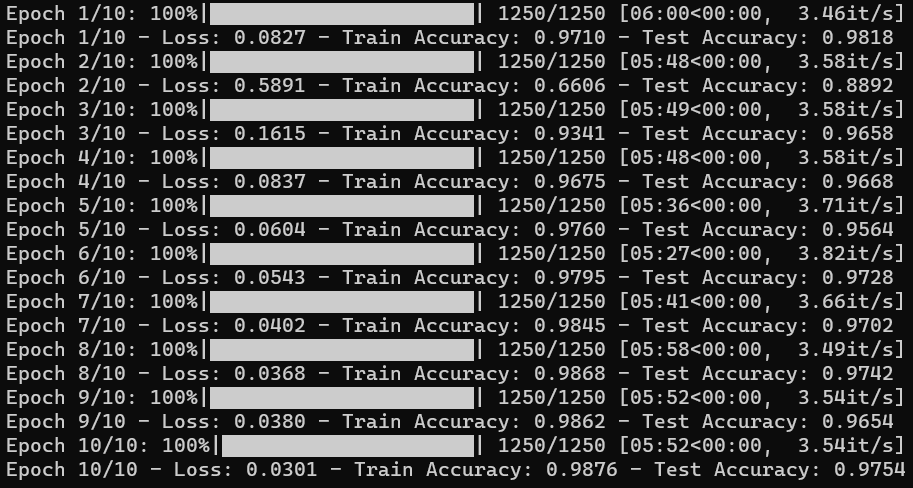
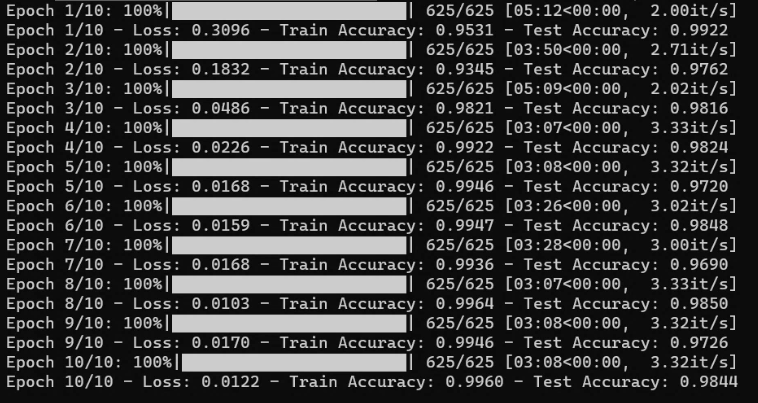
EfficientNet
train_efficientnet.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
# from torchvision.models import vision_transformer
from torchvision import models
from tqdm import tqdm
# ハイパーパラメータの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 32 # 32
learning_rate = 0.0001
# データの前処理
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# データセットの読み込み
train_dataset = ImageFolder(root="dogs-vs-cats/train", transform=transform)
test_dataset = ImageFolder(root="dogs-vs-cats/test", transform=transform)
# データローダの作成
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# モデルの定義
model = models.efficientnet_b2(pretrained=True)
model = model.to(device)
# 損失関数と最適化アルゴリズムの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# エポックループ
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
# バッチループ
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}"):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_accuracy = correct_predictions / len(train_dataset)
train_loss = running_loss / len(train_loader)
# テストデータでの評価
model.eval()
with torch.no_grad():
correct_predictions = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
test_accuracy = correct_predictions / len(test_dataset)
print(
f"Epoch {epoch+1}/{num_epochs} - Loss: {train_loss:.4f} - Train Accuracy: {train_accuracy:.4f} - Test Accuracy: {test_accuracy:.4f}"
)
# 最終モデルの保存
torch.save(model.state_dict(), "model.pt")

めっちゃ精度いいw
EfficientNetV2
モデルのところ変えるだけです
model = models.efficientnet_v2_s(pretrained=True)
ViT
train_vit.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
# from torchvision.models import vision_transformer
from torchvision import models
from tqdm import tqdm # pip install tqdm
import timm # pip install timm
# ハイパーパラメータの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 32 # 32
learning_rate = 0.0001
# データの前処理
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# データセットの読み込み
train_dataset = ImageFolder(root="dogs-vs-cats/train", transform=transform)
test_dataset = ImageFolder(root="dogs-vs-cats/test", transform=transform)
# データローダの作成
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ViTモデルの定義
model = timm.create_model("vit_base_patch16_224", pretrained=False, num_classes=2)
model = model.to(device)
model = model.to(device)
# 損失関数と最適化アルゴリズムの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# エポックループ
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
# バッチループ
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}"):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_accuracy = correct_predictions / len(train_dataset)
train_loss = running_loss / len(train_loader)
# テストデータでの評価
model.eval()
with torch.no_grad():
correct_predictions = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
correct_predictions += (predicted == labels).sum().item()
test_accuracy = correct_predictions / len(test_dataset)
print(
f"Epoch {epoch+1}/{num_epochs} - Loss: {train_loss:.4f} - Train Accuracy: {train_accuracy:.4f} - Test Accuracy: {test_accuracy:.4f}"
)
# 最終モデルの保存
torch.save(model.state_dict(), "model.pt")
Epoch 1/10: 100%|████████████████████████| 625/625 [08:44<00:00, 1.19it/s]
Epoch 1/10 - Loss: 0.6911 - Train Accuracy: 0.5598 - Test Accuracy: 0.6080
Epoch 2/10: 100%|████████████████████████| 625/625 [07:38<00:00, 1.36it/s]
Epoch 2/10 - Loss: 0.6457 - Train Accuracy: 0.6146 - Test Accuracy: 0.5880
Epoch 3/10: 100%|████████████████████████| 625/625 [07:40<00:00, 1.36it/s]
Epoch 3/10 - Loss: 0.6234 - Train Accuracy: 0.6429 - Test Accuracy: 0.6736
Epoch 4/10: 100%|████████████████████████| 625/625 [07:42<00:00, 1.35it/s]
Epoch 4/10 - Loss: 0.5988 - Train Accuracy: 0.6713 - Test Accuracy: 0.6828
Epoch 5/10: 100%|████████████████████████| 625/625 [07:43<00:00, 1.35it/s]
Epoch 5/10 - Loss: 0.5835 - Train Accuracy: 0.6864 - Test Accuracy: 0.6828
Epoch 6/10: 100%|████████████████████████| 625/625 [07:55<00:00, 1.31it/s]
Epoch 6/10 - Loss: 0.5679 - Train Accuracy: 0.7005 - Test Accuracy: 0.7014
…
Epoch 9/10: 100%|████████████████████████| 625/625 [09:18<00:00, 1.12it/s]
Epoch 9/10 - Loss: 0.5341 - Train Accuracy: 0.7299 - Test Accuracy: 0.7210
Epoch 10/10: 100%|████████████████████████| 625/625 [08:17<00:00, 1.26it/s]
Epoch 10/10 - Loss: 0.5220 - Train Accuracy: 0.7356 - Test Accuracy: 0.7260
モデルのサイズ
