はじめに
AWS Textractで画像からテキスト抽出をやってみました
開発環境
- Windows 10
- Anaconda
- Python 3.6
- OpenCV 4.4.0
- awscli v2
導入
1.awscliをインストールします
Windows での AWS CLI バージョン 2 のインストール、更新、アンインストールを参考にAWSCLIV2.msiをインストールします
2.AWSコンソールからIAMでアクセスキーを生成します
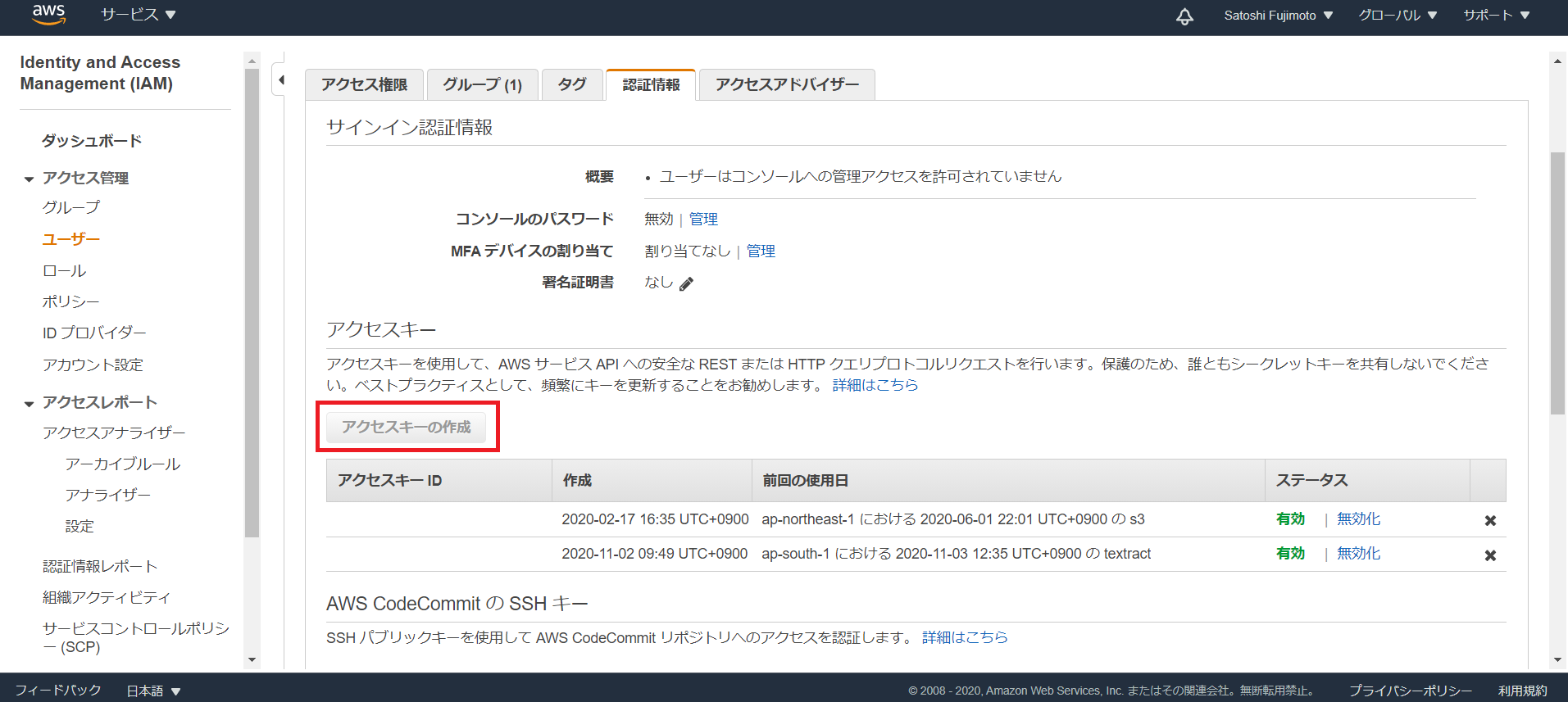
3.コマンドプロンプトでawscliの設定を行います
アクセスキー生成時に得られたAccess KeyとSecret Access Keyを入力します。
デフォルトリージョン名は、Textractが使えるap-south-1(アジアパシフィック ムンバイ)を指定します。
アウトプットフォーマットはjsonとします。
$ aws configure
AWS Access Key ID [None]: XXXX
AWS Secret Access Key [None]: XXXX
Default region name [None]: ap-south-1
Default output format [None]: json
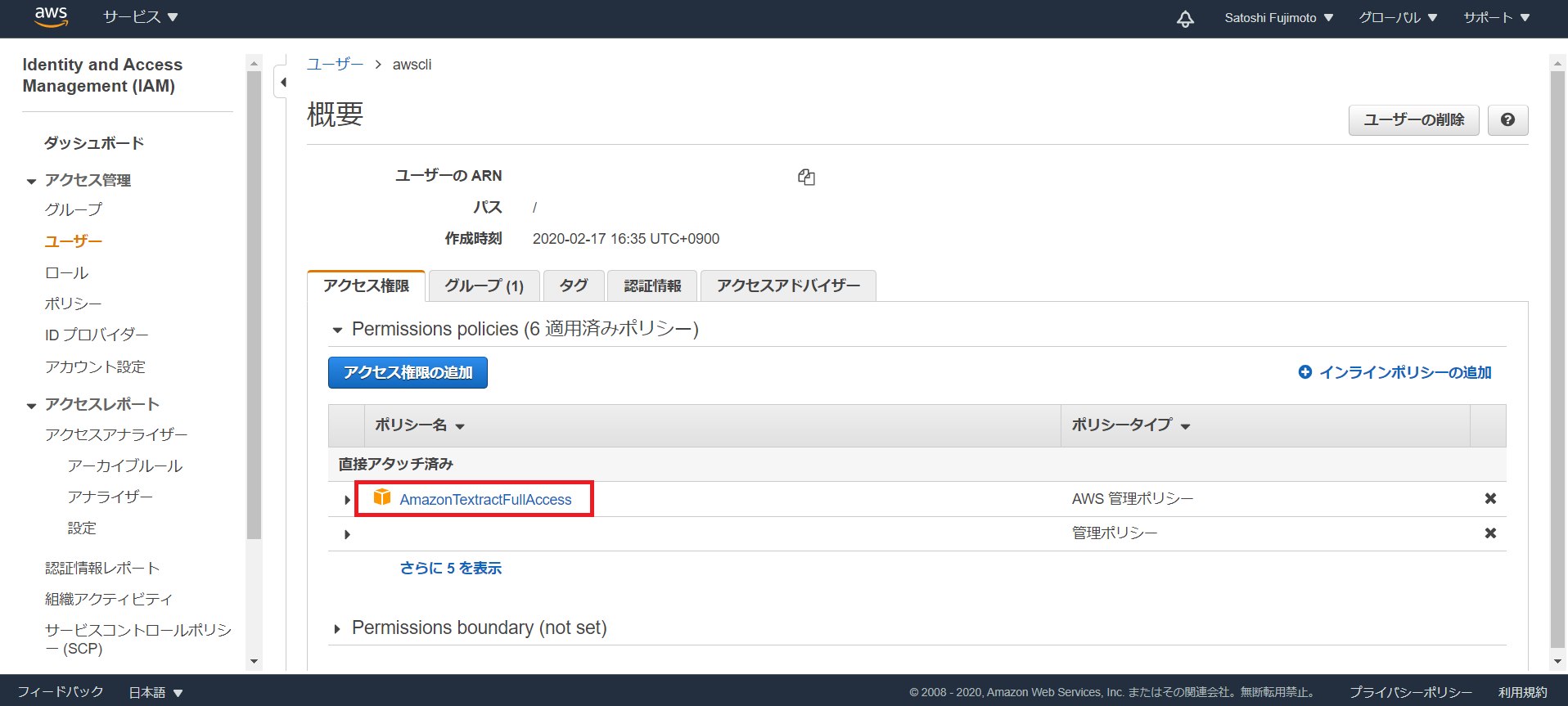
3.IAMのアクセス権限の追加からポリシー「AmazonTextractFullAccess」を追加します
4.anaconda promptを開き、Python 3.6環境を作成します。
$ conda create -n py36 python=3.6
$ conda activate py36
5.ライブラリをインストールします
$ pip install boto3
$ pip install opencv-python
6.下記のコードを実行してみましょう
import boto3
import cv2
import os.path
def process_text_analysis(image):
client = boto3.client('textract')
image_data = cv2.imencode(".png", image)[1].tostring()
response = client.analyze_document(Document={'Bytes': image_data}, FeatureTypes=["TABLES", "FORMS"])
blocks = response['Blocks']
return blocks
def draw_blocks(image, blocks):
height, width = image.shape[:2]
draw = image.copy()
for block in blocks:
if block['BlockType'] == "WORD":
vertices = [(int(width * block['Geometry']['Polygon'][i]['X']), int(height * block['Geometry']['Polygon'][i]['Y'])) for i in range(len(block['Geometry']['Polygon']))]
cv2.putText(draw, block['Text'], vertices[0], cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA)
cv2.rectangle(draw, vertices[0], vertices[2], (0, 255, 0))
return draw
filename = "338px-Atomist_quote_from_Democritus.png"
image = cv2.imread(filename, cv2.IMREAD_COLOR)
blocks = process_text_analysis(image)
print("Blocks detected: " + str(len(blocks)))
draw = draw_blocks(image, blocks)
cv2.imshow("draw", draw)
cv2.waitKey(0)
| input | output |
|---|---|
 |
 |
お疲れ様でした。