本記事は「完全に理解したTalk Advent Calendar 2021」の25日目の記事です。
すみません、遅刻しました。
こんにちは、最近、検索エンジンに入門したエンジニアです。
先日、友人との会話の中で「機密性の高い情報だからサーバーには送れないんだけど、件数が多いからどうにかフロントエンドだけで完結する検索システムが作れないかなあ」という話がありました。
そこで今回は、バックエンドに一切サーバーを用意せず、フロントエンドだけで完結する検索エンジンがないか調べてみました。
ちなみに、私は普段はバックエンドのシステムを作っている人間なので、フロントエンドも検索エンジンも完全に理解したクオリティであることはご承知おきください。
そもそもどんな機能が欲しい?
検索システムというと、Apache SolrやElasticsearchといったミドルウェアを思い浮かべると思います。
これらは、バックエンドサーバーを用意して、その上で検索エンジンを構築して運用していくことになります。
もちろん、ドキュメント数やリクエスト数が多いシステムであれば、安定的に稼働させるためにちゃんとした基盤を作ったほうがよいでしょう。
しかし、ちょっとした検索デモや自前のホームページとかブログサイトに検索機能をつける場合であれば、画面だけで完結してくれると嬉しいですよね。
もしかしたら、私と同じように情報セキュリティ的な観点からサーバーに置けないようなデータに対して検索をしてみたいという場面もあるかもしれません。
では、そもそも検索システムを作る上であってほしい機能はどのようなものでしょうか。
Solrなどの検索エンジンの基本機能として思い浮かぶものは
- 完全一致
- 部分一致
- ソート
- トークン化
- ストップワード処理
- 大文字小文字、半角全角の表記揺れ程度のあいまい検索
といったところでしょうか。
より高度な機能になると
- スペルミスを伴うあいまい検索
- ベクトル検索
- ハイライト
- facetやstats
- ディープページング
- replicationやshardingといった可用性を上げるための仕組み
などが挙げられると思います。
もちろん、SolrやElasticsearchクラスになると、ここに挙げきれないほど多岐にわたる機能がありますが、私が普段よく使う機能はこの辺りです。
なので、高度な仕組みまでは望まないとしても、基本機能が簡便に実装できることが選定基準になってきそうです。
調べてみたところ、やはり同じように思う人がいるのか、これらの機能をもつフロントエンド完結の検索エンジンがいくつか見つかりました。
fast-fuzzy vs flexsearch vs fuse.js vs fuzzy vs lunr vs search-index | npm trends
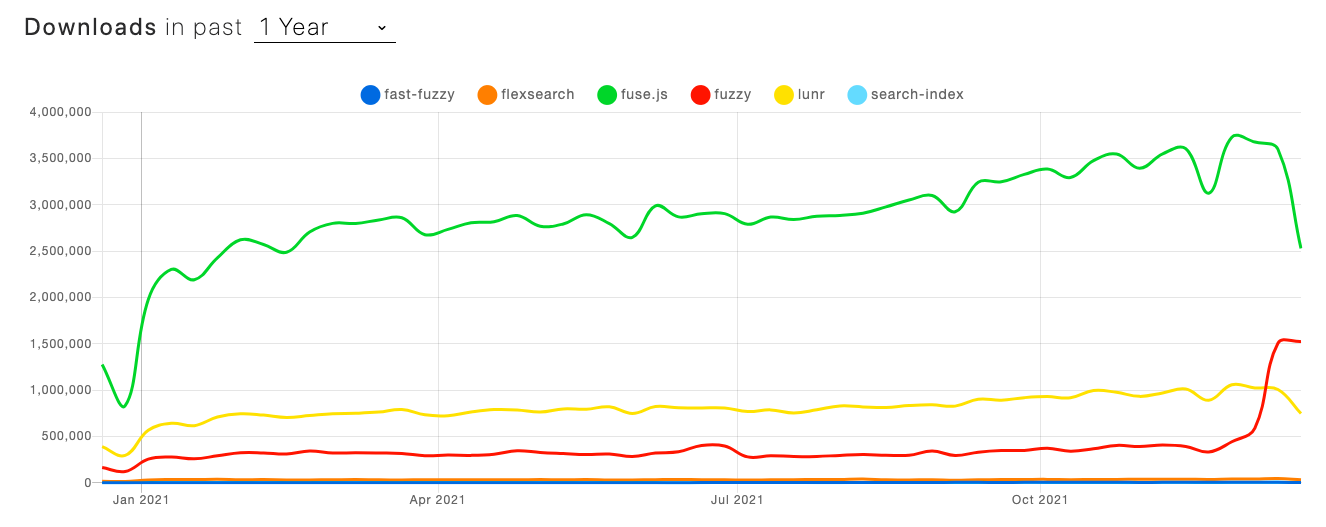
GitHubのスター数やnpmのダウンロード数を比べるとこの中ではFuse.jsが圧倒的です。
なので、今回はFuse.jsに焦点を当てて完全に理解してみようと思います。
Fuse.js完全に理解した
Fuse.jsはREADMEを意訳するに「他のライブラリに依存しない軽量なJavascript製のあいまい検索ができる検索エンジン」のようです。
Apache-2.0 LicenseのOSSなので、商用利用も可能です。
krisk/Fuse: Lightweight fuzzy-search, in JavaScript
主なドキュメントはドキュメントページです。
What is Fuse.js? | Fuse.js
英語を読むのが苦手だという方は、日本語に翻訳してくれているブログ記事を見つけたので、合わせて見てみるといいかもしれません。
JSであいまい検索ができるFuse.jsの使い方
ドキュメントページのLive Demoをみると分かりやすいのですが、レスポンス結果にクエリに対するヒットScoreもあり、かなりSolrやElasticsearchに概念的に近い印象を受けました。
[
{
"item": {
"title": "The Lock Artist",
"author": {
"firstName": "Steve",
"lastName": "Hamilton"
}
},
"refIndex": 1,
"score": 0.15609486447437038
}
]
インストール方法は簡単で、npmで入ります。
fuse.js - npm
$ npm i fuse.js
npm i fuseではないので注意が必要です!!これだと別物が入ってしまいます。1
無事インストールできたら、検索対象のドキュメントやオプションを指定してインスタンス作成するだけで使えてしまいます。なんと簡単なんだ!!
import Fuse from 'fuse.js'
const documents = [
{
"title": "Old Man's War",
"author": {
"firstName": "John",
"lastName": "Scalzi"
}
},
{
"title": "The Lock Artist",
"author": {
"firstName": "Steve",
"lastName": "Hamilton"
}
}
]
const options = {
includeScore: true,
keys: [
"title",
"author.firstName"
]
};
const fuse = new Fuse(documents, options)
検索対象とするフィールド(Fuse.jsでいうところのkeys)はシングルフィールドでもマルチフィールドでもOKです。
基本的な検索
and や or といった論理式を使った検索をサポートしています。
同じフィールドや異なるフィールド間でandやorを取ることができます。
Logical Query Operators | Fuse.js
// and検索
const result = fuse.search({
$and: [{ author: 'abc' }, { title: 'xyz' }]
})
// or検索
const result = fuse.search({
$or: [{ author: 'abc' }, { author: 'def' }]
})
より高度な検索
useExtendedSearchオプションをtrueにするとより高度な検索もできるようになります。
Examples | Fuse.js
先ほどは$andや$orのように書きましたが、拡張検索モードであれば、ANDは半角スペースで、ORはパイプ(|)で表せます。
そのほかにも以下のような検索ができます。
| Token | Match type | Description |
|---|---|---|
jscript |
あいまい一致 |
jscriptに表記揺れ等で一致するドキュメント |
=scheme |
完全一致 |
schemeに完全一致するドキュメント |
'python |
部分一致 |
pythonを含むドキュメント |
!ruby |
部分不一致 |
rubyを含まないドキュメント |
^java |
前方完全一致 |
javaで始まるドキュメント |
!^earlang |
前方完全不一致 |
earlangで始まらないドキュメント |
.js$ |
後方完全一致 |
.jsで終わるドキュメント |
!.go$ |
後方完全不一致 |
.goで終わらないドキュメント |
const options = {
includeScore: true,
useExtendedSearch: true,
keys: ['title']
}
const fuse = new Fuse(books, options)
// Search for items that include "Man" and "Old",
// OR end with "Artist"
fuse.search("'Man 'Old | Artist$")
実装側でサポートしても良いですし、ユーザー側で直接検索窓にabc | defのように入力してもらう絞り込みオプションとして提供するのもありでしょう。
あいまい検索については、英語であれば特別な実装いいらずで表記揺れも吸収して検索してくれています。
ただ、やはり日本語とは相性が悪いようでそのままでは誤字だとうまくヒットしませんでした。
うまくいかない場合は、locationとdistanceオプションを調整するようなのですが、いかんせん完全に理解したレベルの私ではいい感じの調整は見つけられませんでした。
エンコード&トークン化
自然言語処理あるあるなのですが、基本的に英語を想定して作られているので、この手のものはそのままでは日本語を扱うには不十分だったりします。
そのため、一部の機能は自前で日本語化対応してあげる必要があります。
代表的なものがエンコード処理とトークン化です。
日本語では、漢字、平仮名、カタカナ、全角半角が入り混じった文章やクエリが入力されます。
完全一致とすると、「ぱんだ」と検索しても「パンダ」の文章はヒットしません。
でも、私たちからすればどちらも![]() なのでちゃんとヒットして欲しいですよね。
なのでちゃんとヒットして欲しいですよね。
そこで、エンコード処理によって入力をすべてカタカナに変換するなどして表記を揃えるようにします。
トークン化は文章を単語ごとに分割する処理です。
詳しくは以下の記事にわかりやすくまとまって合わせて読んでみてください。
誰でもわかる全文検索入門
トークン化も表記揺れ対策ですが、ヒット漏れを防ぐだけでなく、過剰ヒットの抑制のためにも使われます。
例えば、「京都」と検索すると、「京都」はもちろん部分一致だと「東京都」もヒットしてしまいます。
そこで、文章を単語単位に区切って完全一致や前方一致を取ることで過剰ヒットを防ぎます。
これらをどれだけ頑張るかが検索の出来を決めると言っても過言ではないと思います。
ただ、残念ながらFuse.jsにはいずれも日本語非対応の機能なので、自分で作ることにします。
今回は、エンコードはmojiを、トークン化はtiny-segmenterやn-gramを使って行うことにします。
import moji from "moji";
import { trigram } from 'n-gram';
import TinySegmenter from "tiny-segmenter";
const segmenter = new TinySegmenter();
function _tokenize(text, tokenizer) {
if (tokenizer === "trigram") {
return trigram(text)
} else {
return segmenter.segment(text)
}
}
function tokenize(text, tokenizer) {
const query = moji(text).convert("HK", "ZK").convert("ZS", "HS").convert("ZE", "HE").toString().trim()
return _tokenize(query, tokenizer).map((word) => {
if (word !== " ") {
return moji(word).convert("HG", "KK").toString().toLowerCase();
}
}).filter(v => v)
}
function encode(text) {
return moji(text).convert("HK", "ZK").convert("ZS", "HS").convert("ZE", "HE").convert("HG", "KK").toString().trim().toLowerCase();
}
これをドキュメントやクエリの前処理として組み込んでやることで表記揺れに少しは強くなります。
インデックス化
これまで、検索部分のお話をしましたが、検索をするには検索対象となるドキュメントを事前にインデックス登録しておく必要がありますね。
これは簡単で、以下のようにFuse.jsのインスタンス作成時にオプションと一緒に渡してあげれば完了です。
オプションはデフォルト値をそのまま使うのであれば不要です。
const fuse = new Fuse(documents, options);
そのほかにもaddやremove関数でインデックスの追加や削除もできます。
Methods | Fuse.js
const fruits = ['apple', 'orange']
const fuse = new Fuse(fruits)
fuse.add('banana')
console.log(fruits.length)
// => 3
肝心の入力データですが、ハードコーディングを除けば、GraphQLやその他APIを使って外部から取ってくればいいと思います。
ただ今回はせっかくなので、APIなどには頼らず、フロントエンドで完結させるべくExcelからデータを読み込んでインデクシングしてみようと思います。
SheetJSを使えば、Excelファイルを読み込んでJSON形式に変換できます。
こんな感じに検索対象となるExcelファイルを用意して、

ボタンクリックでローカルから選択したExcelファイルを読み込めるようにしました。
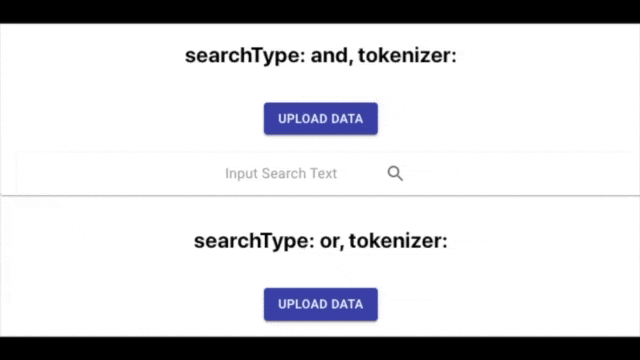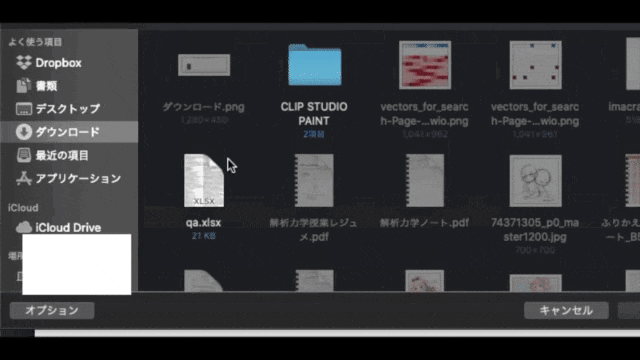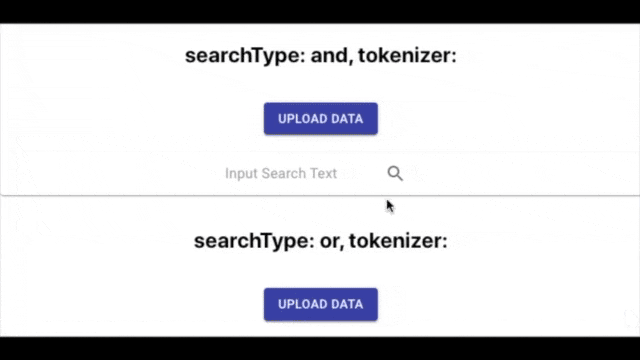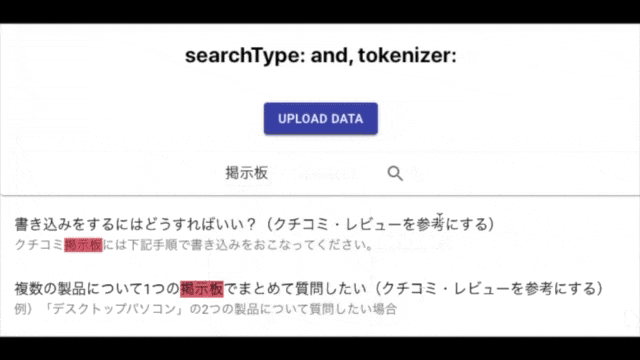
これで外部と通信せずにインデックスデータを動的に入力できます。
あとは、読み込んだExcelデータに先程のエンコードとトークン化を施しておきます。
import React, { useEffect, useState, useRef, createRef } from "react";
import Button from '@material-ui/core/Button'
import XLSX from 'xlsx';
function ImportExcelData(props) {
const fileInput = createRef();
const [fileName, setFileName] = useState("")
const [searchKeys, setSearchKeys] = useState([])
const [documents, setDocuments] = useState([])
const tokenizer = props.tokenizer
const searchType = props.searchType
const handleTriggerReadFile = () => {
if (fileInput.current) {
fileInput.current.click()
}
}
const handleReadFile = (fileObj) => {
if (fileObj) {
setFileName(fileObj.name)
fileObj.arrayBuffer().then((buffer) => {
const workbook = XLSX.read(buffer, { type: 'buffer', bookVBA: true })
const firstSheetName = workbook.SheetNames[0]
const worksheet = workbook.Sheets[firstSheetName]
const data = XLSX.utils.sheet_to_json(worksheet)
const orgKeys = Object.keys(data[0])
var docs = new Array();
data.forEach((doc) => {
var _doc = new Object();
Object.keys(doc).forEach((key) => {
_doc[key] = doc[key]
_doc[`search_${key}`] = encode(doc[key])
_doc[`tokenized_${key}`] = tokenize(doc[key], tokenizer)
})
docs.push(_doc)
})
var _searchKeys = orgKeys
orgKeys.forEach((key) => {
_searchKeys.push(`search_${key}`)
_searchKeys.push(`tokenized_${key}`)
})
setSearchKeys(_searchKeys)
setDocuments(docs)
})
}
}
return (
<div>
<div style={{ padding: "20px" }}>
<Button variant="contained" color="primary" onClick={() => handleTriggerReadFile()}>upload data</Button>
<form style={{ display: "none" }}>
<input
type="file"
accept="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
ref={fileInput}
onChange={(e) => {
e.preventDefault()
handleReadFile(e.currentTarget.files[0])
}}
/>
</form>
</div>
</div>
);
};
ハイライト対応
includeMatchesをtrueにすると、ヒットした単語やヒットした語が何文字目にあるかが取得できるようになります。
Options | Fuse.js
ハイライティング部分は自前で作る必要はあるものの、該当箇所をハイライトさせることもできます。
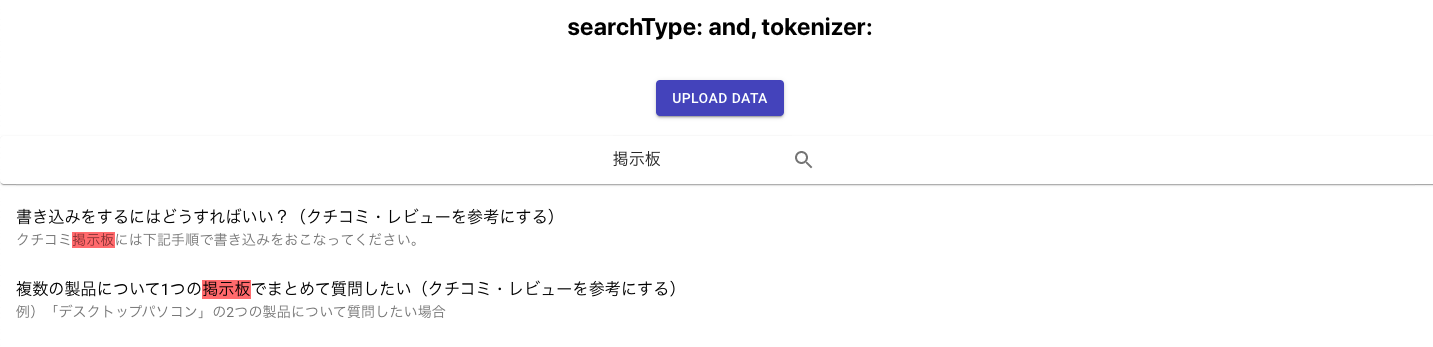
その他
そのほかにもフィールドごとに重みをつけてScoreを算出するブースティングのようなこともできるなど、便利な機能があります。
CPUやメモリ負荷やレスポンス性能といったスペック面に関しては、正直検証不足なのでどこまで使えるかはなんとも言えません。
ただ、100ドキュメントくらいの規模であれば、インデックス化も検索も特に気にならない程度で結果が返ってきました。
総評としては、他のライブラリと独立しつつ、洗練された基本的な機能だけで構成されているので、独自記法も少なく、最小限の学習コストでそれなりのものが作れると思います。
裏を返せば、ちょっと複雑なことがしたいとなると、自分であれこれ組み合わせたり、自作する部分が多いとも言えます。
今回は、トークン化やハイライトなど自前でカスタマイズしたかったので頼りませんでしたが、関連ライブラリ、ラッパーライブラリもあります。
React, Vue, Angularなどメジャーどころのラッパーは大体あるようです。
また、ハイライト部分もやってくれるラッパーもあるようです。
FlexSearch完全に理解した
比較のために、もう1つの候補であったFlexSearchも試してみました。
実は最初はこちらに目をつけていたのですが、Solrなどとは使い勝手がたいぶ違ったのでFuse.jsで調査し直しました。
nextapps-de/flexsearch: Next-Generation full text search library for Browser and Node.js
主なドキュメントはGitHubのREADMEになります。
なんとかドキュメントを読み解いて使えるようになりましたが、Solrとは使い勝手は結構違っていました。
ブラウザまたはNode.jsから使えるとのことでしたが、あまりReactとは相性が良くないのかもしれません。
私が完全に理解した状態なだけも気がしますが、READMEに書かれているとおりに模写しただけではうまく動きませんでした。
あいまい検索とかもできるようですが、機能ではなく実装で対応するようで使い勝手はテクニカルでした。
そもそも同じ検索フィールドに対してand, or, not検索機能をデフォルトでは持っていなさそうで、Scoreといった概念もなかったので、私が思い描いていた検索エンジンの使い勝手ではなさそうでした。
良い点としては、Fuse.jsでは拡張オプションで指定していた前方一致や後方一致などの部分一致が、組み込み関数で指定できるのは便利そうでした。
また、トークン化やエンコードをオプションで一括定義できるので、Fuseのように都度都度定義しなくてよいのもありがたかったです。
実装的な部分を書く余裕がなかったので、需要がありそうであればそのうち書くかもしれません。
まとめ
ということで、今回はフロントエンド完結の検索エンジンについて完全に理解してみました。
バックエンドで動かす検索エンジンに可用性は劣るものの、基本機能や部分的には高度な検索もできそうということがわかりました。
英語ならそのまま、日本語でもカスタマイズ次第では、ブログサイトや小規模なサイトの検索エンジンはフロントエンドだけで賄えてしまいそうです。
日々みなさんがグーグル先生に聞いているように、Webと検索技術が切っても切れない関係になっている今、フロントエンドエンジニアのみなさんなどが、この機に少しでも検索技術に興味をもってくれると嬉しいですね。
この記事が、みなさんのよい検索ライフの一助になれば幸いです。それでは。