はじめに
本記事の目的は、国土交通省が公開している「水文水質データベース」から観測データを自動取得する方法を紹介することです。国土交通省や気象庁といった公機関は、天気・河川水位といった計測データを一般公開しており、「水文水質データベース」はその1つです。(サイトurl: http://www1.river.go.jp/)
データによっては数十年もの蓄積があり、気候変動の調査やビジネスへの活用が期待できると考えています。
水文水質データベースの概要をサイトから引用します
このデータベースは水文水質にかかわる国土交通省水管理・国土保全>局が所管する観測所における観測データを公開することを目的として> います。掲載対象としているデータは、雨量、水位、流量、水質、底質、地下水位、地下水質、積雪深、ダム堰等の管理諸量、海象です。
しかし、水文水質データベースは有益なデータが豊富に揃っていながらも、CSV形式等でのダウンロードが不可であるなど少し利用が難しいです。そこで、PythonによるWebスクレイピングの方法をソースコード共に紹介し、水文水質データベースを有効活用ができる様にしたいと考えました。今回は「河川の水位」をターゲットにSeleniumとBeautifulSoupを用いてWebからデータ取得を行い、機械学習などに利用しやすい様にPandasのDataFrameで扱える様にします。
※注意
水文水質データベースのツールによるデータ自動取得に関して以下の記載があります
ツール等による、自動的なデータ収集等はサーバに負荷がかかり、情報提供できなくなる恐れがありますので原則としてご遠慮ください。ご理解・ご協力お願いします。
データを自動取得する方法を掲載しておいて難ですが、節度を守ってデータ取得を行うようにお願いたします。
水文水質データベースからデータを取得する手順
Webスクレイピングは以下の手順で進めます。
1.HTMLのソースを取得
2.データ記載された表の部分を取得
3.データ値を切り出す
本章でその概要をします。また、今回は東京都と神奈川を分ける多摩川の「田園調布(下)」観測所のデータを取得します。
自動取得するHTMLソース
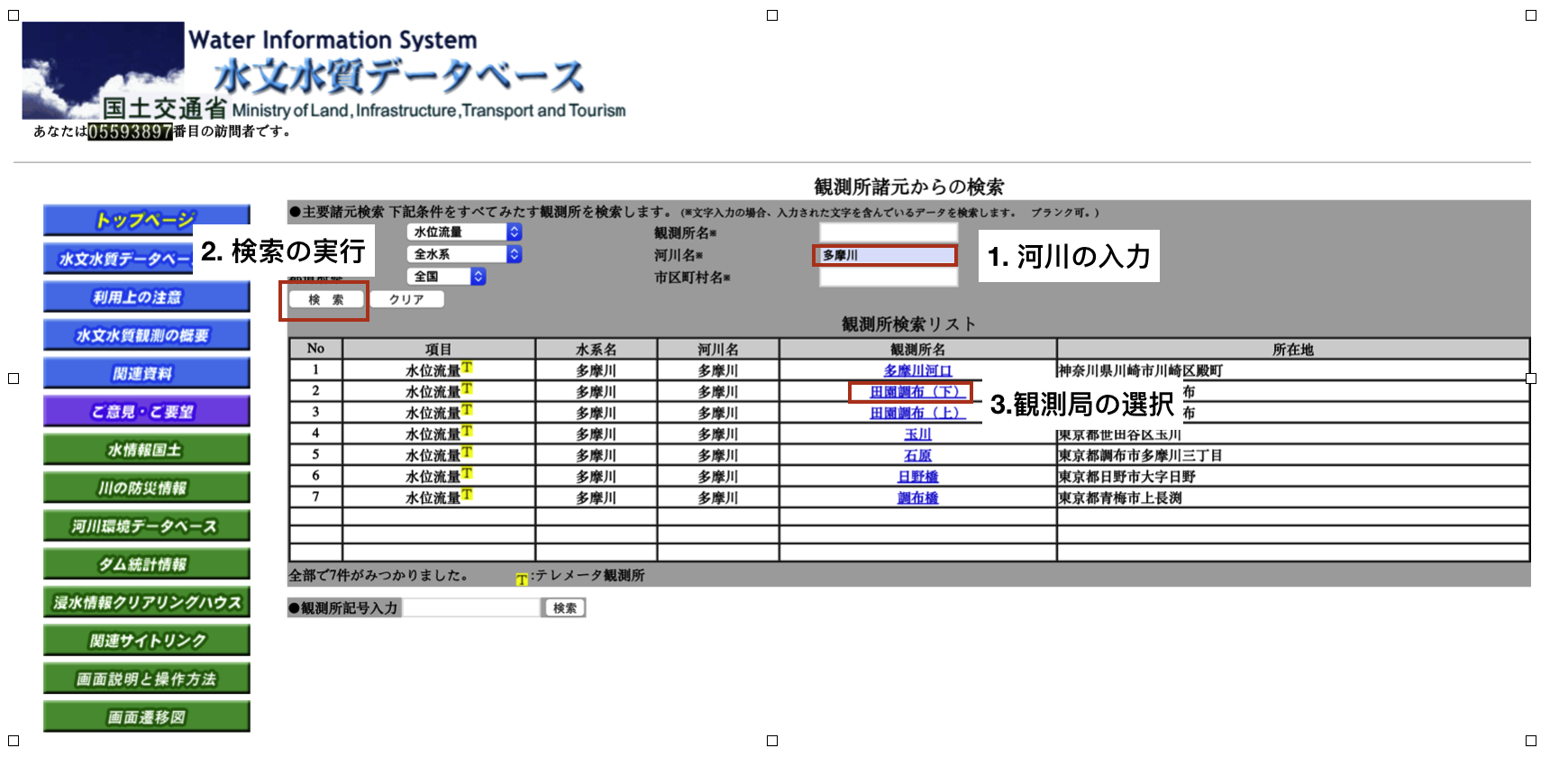
データの取得対象である水位観測局を検索します。図1の「水系単位の観測所一覧検索」をクリックし観測局検索画面に遷移します。
続いて観測局を検索するために図2の観測局検索画面で、河川名欄に「多摩川」と入力し「田園調布(下)」をクリックし観測局の詳細情報
を表示します。
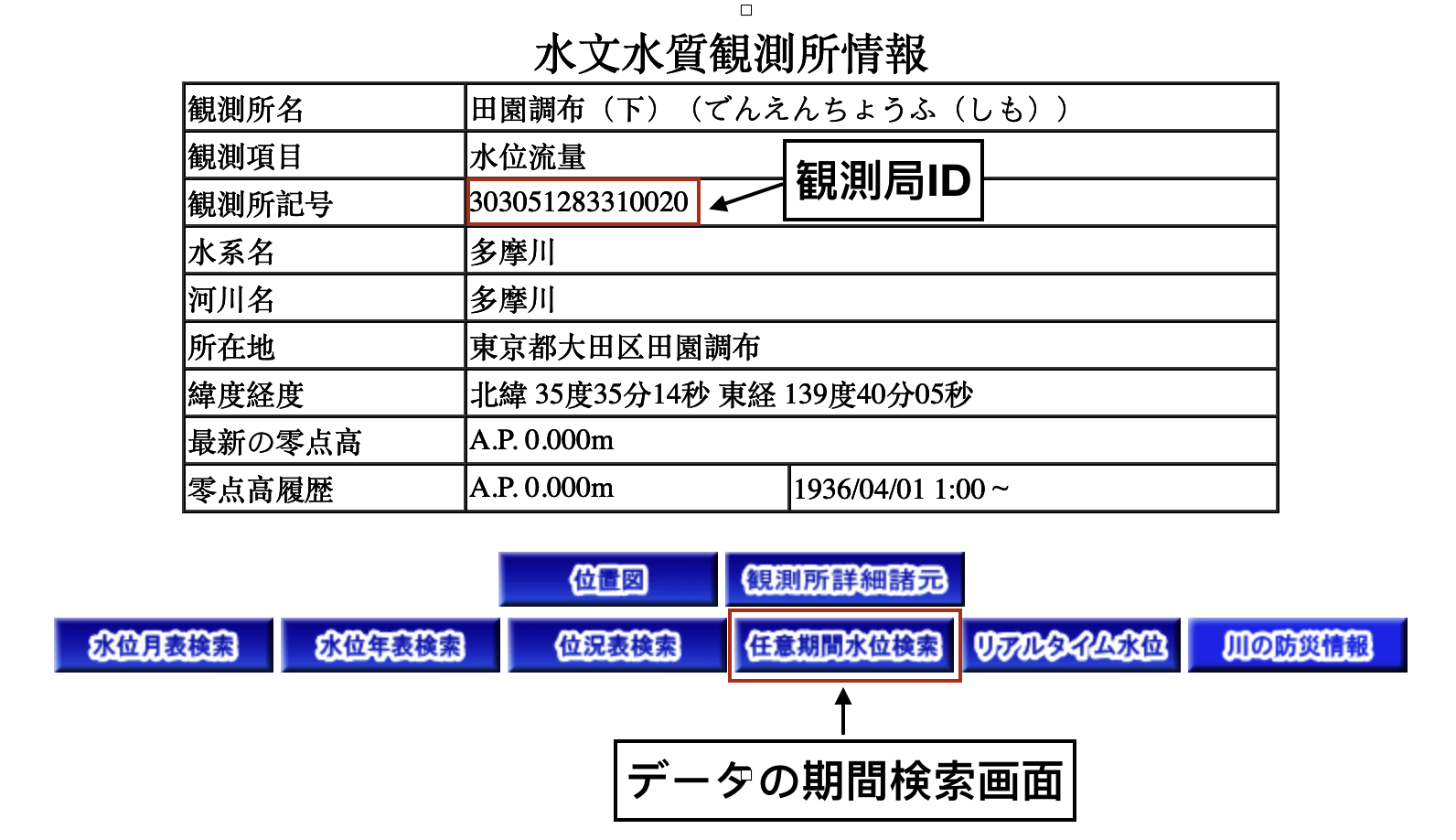
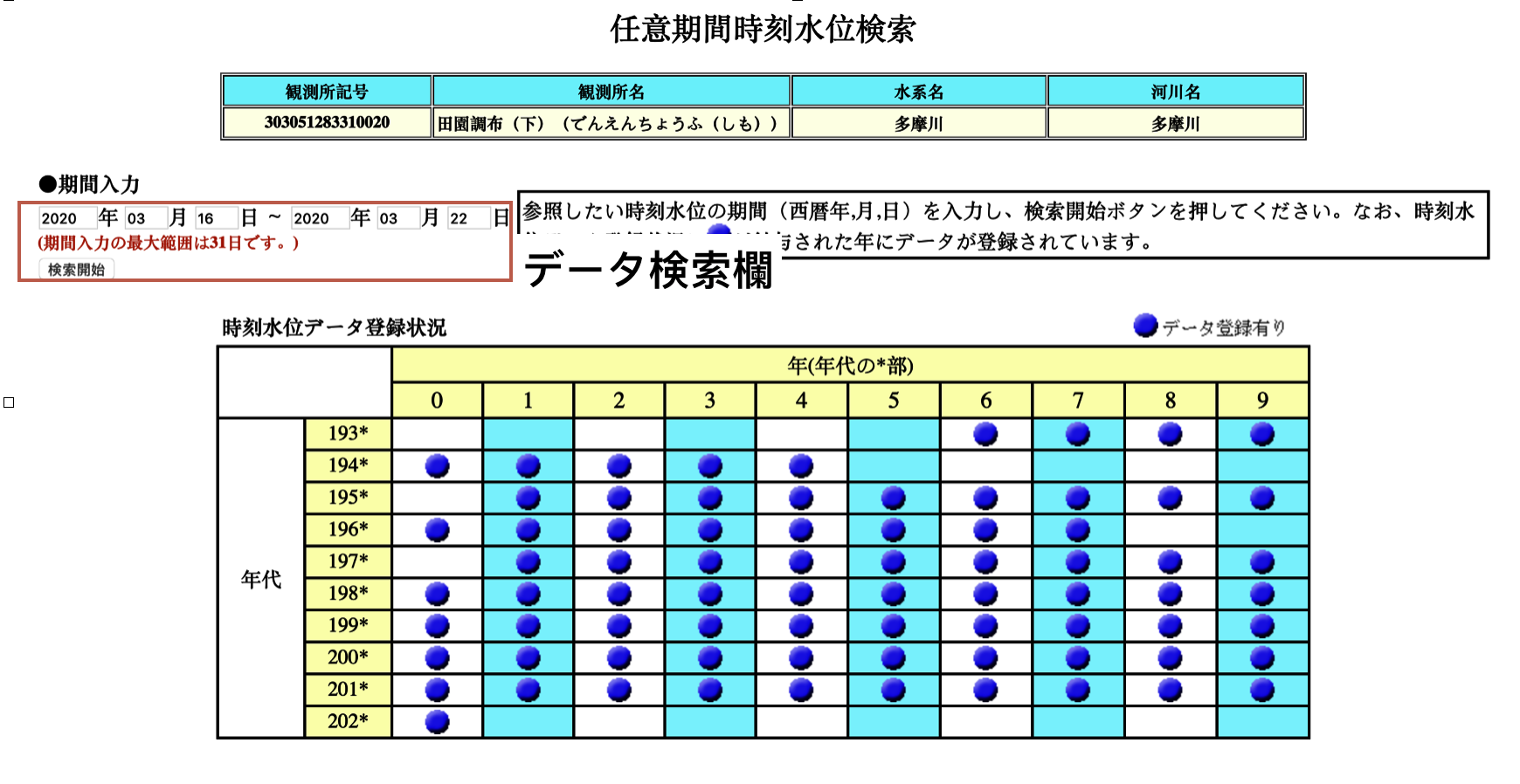
図3の観測所情報画面に観測局IDという項目がありますが、これはスクレイピングをする上で必須の情報ですので控えておきます。また、「任意期間水位検索」ボタンをクリックすることで水位データの検索画面に遷移します。図4で示すデータ検索画面で期間を入力し水位データを取得します。ここで注意が必要なのは検索の期間は31日までです。
図4の下方に取得可能期間が記載されていますが、1930年代からデータが取れるという恐ろしい内容になっています。
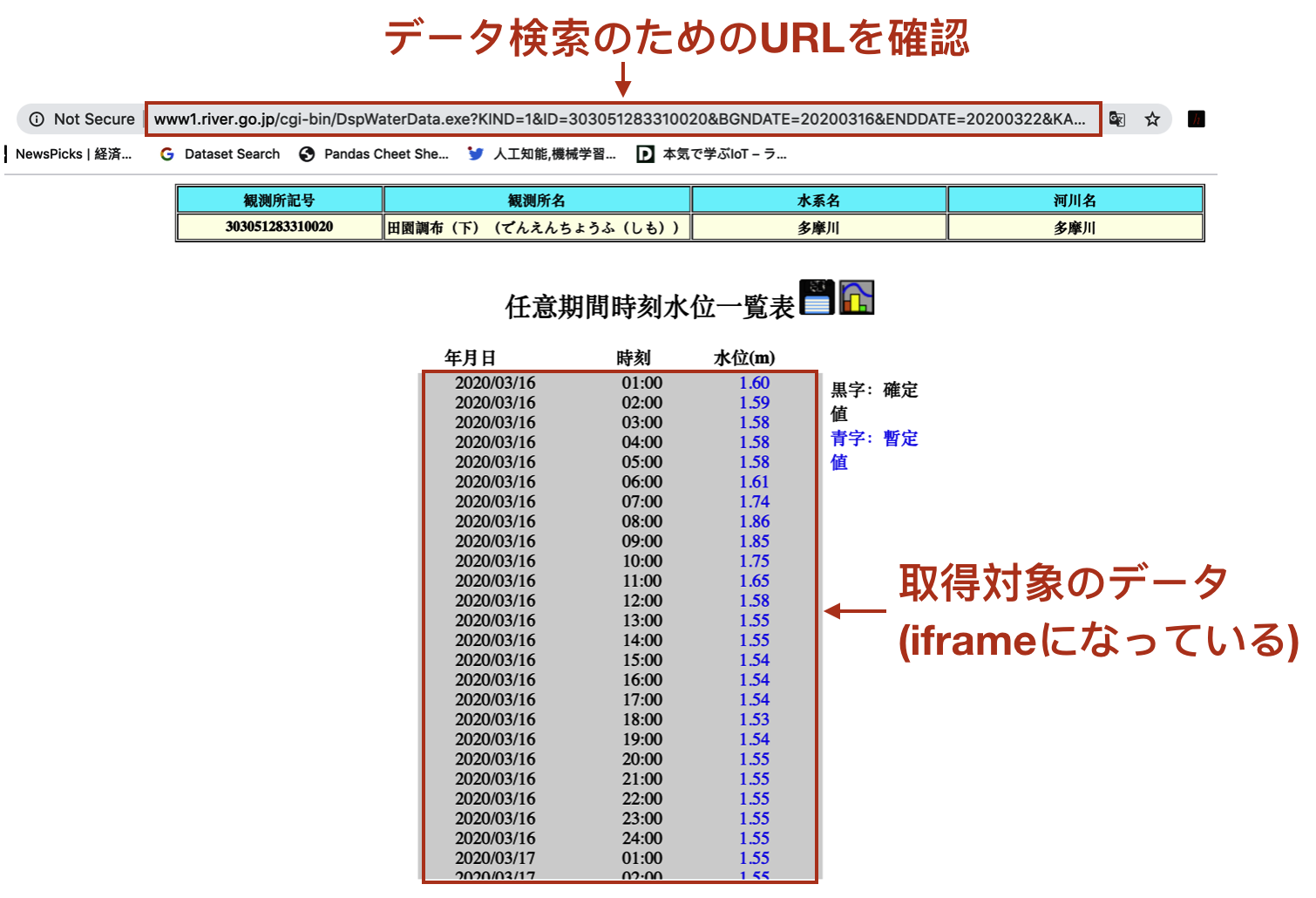
図5が検索結果の画面です。注目すべき点はURLを見ると検索のクエリは観測局IDと開始日付と終了日付から構成されるということと、データ取得を行う表の部分はiframeタグであることです(ブラウザの開発者ツールで確認してください)。したがって、検索条件を付加したURLでリクエストを行い、表の部分だけを取得すれば所望の処理が実現できます。
▪️図1: 水文水質データベース トップ画面

▪️図2: 水位観測局の検索
▪️図3: 水位観測所情報画面
▪️図4: 水位データ検索画面
▪️図5: データ取得を行う対象の画面
SeleniumとBeautifulSoupを用いたWebスクレイピング
前章で紹介した手順に沿って実際にデータを取得するプログラムを記載します。ソースの取得にはSeleniumを、HTMLを解析した必要なデータだけを抽出する操作をBeautifulSoupを用い、PandasのDataFrameの型でデータを扱います。
Seleniumのセットアップ
SeleniumはWebブラウザの操作を自動化するためのフレームワークです。環境構築や使い方は次の記事を参考にしました。わかりやすいく書かれているのでご参照ください!
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
HTMLソースの取得
検索条件に合致する河川水位データが記載されたHTMLのソースを取得します。
まずは本記事において必要なパッケージのインポート宣言
from bs4 import BeautifulSoup
from selenium import webdriver
import pandas as pd
import datetime
import matplotlib.pyplot as plt
SeleniumによるWebブラウザのドライバーを生成し、GETメソッドでHTMLのソースを取得します。
今回はSelenium公式のDockerイメージでドライバのサーバーを立てる方法を用いています。
この環境の立て方や使い方は以下から引用しています
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
## Driverの生成
# Chrome のオプションを設定する
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# Selenium Server に接続する
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
desired_capabilities=options.to_capabilities(),
options=options)
検索条件である観測所ID、検索開始・終了日付を宣言しURLを生成します
## 検索条件の定義
# ※水文水質データベースでは一回に30日までのデータしか取得できません
station_id = 303051283310020
start_date_test = '20200101'
end_date_test = '20200120'
## リクエストURLの生成
url_base = 'http://www1.river.go.jp/cgi-bin/DspWaterData.exe?KIND=1&ID={0}&BGNDATE={1}&ENDDATE={2}&KAWABOU=NO'
url_request = url_base.format(station_id, start_date_test, end_date_test)
以下でSeleniumを用いてURLでリクエストを送信し、
iframe部のHTMLソースを取得してからBeautifulSoupでHTMLの解析を行います。
解析ではtableタグの要素を取得します。
# URLからソースを取得
driver.get(url_request)
# 水位データを取得するためにifrmaを取得
iframe = driver.find_element_by_tag_name('iframe')
driver.switch_to.frame(iframe) # ここでiframeの操作に切り替える
# iframeのソースを取得し表データの'tr'タグを全て取得する
soup = BeautifulSoup(driver.page_source, 'html.parser')
table = soup.findAll("table")[0]
rows = table.findAll("tr")
ここで注意が必要なのは6行目の
driver.switch_to.frame(iframe)
の部分です。このメソッドを呼ぶことでiframeの操作ができるようになります。
取得したrowsの中身を確認します
print(rows)
[<tr>
</tr>, <tr>
<td align="left" height="10" width="40%">2020/01/01</td>
<td align="left" height="10" width="30%"> 01:00</td>
<td align="left" height="10" width="30%"><font color="#0000ff"> 1.56</font></td>
</tr>, <tr>
〜中略〜
<td align="left" height="10" width="40%">2020/01/20</td>
<td align="left" height="10" width="30%"> 24:00</td>
<td align="left" height="10" width="30%"><font color="#0000ff"> 1.52</font></td>
</tr>]
配列形式でtableタグ内の要素が取得できています。
データの抽出と変換
続いてタグから値だけを取り出しDataFrameの形式に変換していきます。
# tdタグから値を取得し配列に格納する
wl_data_list = []
for row in rows:
list_tmp = []
td_list = row.findAll(['td'])
for td in td_list:
list_tmp.append(td.get_text().replace('\u3000', ''))
wl_data_list.append(list_tmp)
取得したrowsの中身を確認します
print(wl_data_list)
[[], ['2020/01/01', '01:00', '1.56'], ['2020/01/01', '02:00', '1.56'],
['2020/01/01', '03:00', '1.56'], ['2020/01/01', '04:00', '1.55'],
['2020/01/01', '05:00', '1.55'], ...
['2020/01/20', '22:00', '1.53'], ['2020/01/20', '23:00', '1.52'],
['2020/01/20', '24:00', '1.52']]
欲しいデータのみが配列で取得できています。
取得したデータから日付と時間を結合しDataFrameに変換します。
# 配列をPandasに変換し日付と時刻を結合する
df_wl = pd.DataFrame(wl_data_list,columns=['date', 'time', 'water_lev'])
df_wl.loc[:,'date'] = df_wl.loc[:,'date'] + ' ' + df_wl.loc[:,'time']
df_wl.drop('time', axis=1, inplace=True)
df_wl.dropna(how='all', inplace=True)
# 'time'をdatetime型に'水位'をfloat型に変換する
df_wl['date'] = df_wl['date'].astype('str').apply(str2datetime)
df_wl['water_lev'] = pd.to_numeric(df_wl['water_lev'], errors='coerce')
df_wl.set_index('date', inplace=True)
df_wl.sort_index(inplace=True)
8行目の
df_wl['date'] = df_wl['date'].astype('str').apply(str2datetime)
では文字列の日時をdatetimeに変換しています。
水文水質データベースの時刻は01:00-24:00の表記になっている一方で、
Pandasは時刻を00:00-23:00の範囲で扱っています。
その変換は自前で定義したstr2datetimeの関数を用いています。
その関数を以下に示します。
def str2datetime(string):
"""
Stringの日時データをdatetime型に変換する。
'YYYY/MM/DD 24:00'表記の日時を'YYYY/MM/DD+1 00:00'に変換する。
Args:
string (String): 日時の文字列。'YYYY/MM/DD HH:mm'の表記を前提とする。
Returns:
date (datetime.datetime): 日時のdatetime変換後の形式
"""
if string[-5:] == '24:00':
string = string[:-5] + ' ' + '00:00'
date = datetime.datetime.strptime(string, "%Y/%m/%d %H:%M")
date += datetime.timedelta(days=1)
else:
date = datetime.datetime.strptime(string, "%Y/%m/%d %H:%M")
return date
こうして出来上がったDataFrameを可視化します
df_wl.plot()
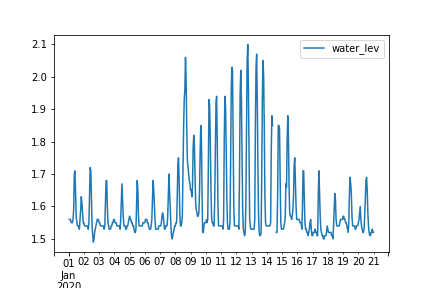
思った通りにデータが取得できていそうです!
まとめ
Webスクレイピングを用いて水文水質データベースから河川水位データを自動取得する方法を紹介しました。Selenium、BeautifulSoupを活用しています。記事では20日分のデータしか取得していませんが、githubにさらに長期間に渡ってデータを取得可能なコードをアップしていますので興味のある方はご覧ください。
以下がgithubのURLです
https://github.com/Sampeipei/qiita/blob/master/Web_scraping_river_water_level.ipynb
また、スクレイピングでこんなデータを取得したい!というのがありましたら是非コメントお願いいたします。