前置き
適当に読んでまとめている自分用のメモですので,お気になさらず
今回読んだ論文は以下のものです.
https://ieeexplore.ieee.org/abstract/document/7858394
Abstract
LSTMは文字列処理などで大きな功績を残しているが,この回帰的な構造はCPUやGPUでの実装に向いていない.FPGAはエネルギー効率がよく,非常に柔軟であるため,回帰的な構造に適したアクセラレータとして組むことが期待できる.本論では計算の最適化に加えて,通信の最適化を行う.結果として,7.26 GFLOP/Sのピーク性能を得た.
Optimization Analysis
最適化を施すためには以下の制約を考慮する必要がある
- 計算
- 通信
計算の最適化
ゲート計算の最適化
ソフトウェアレベルのプロファイリングでは計算のボトルネックになっている部分は各LSTMゲートの中の計算(それはそう…)
入力ベクタの長さを $L_i$ ,隠れ層ベクタの長さを $L_h$ とすると,浮動小数点演算の回数は次のようになる.隠れ層は一層のみと仮定する.
$$
(L_i+L_h) \times L_h \times 4 \times 2 + L_h \times (8+4+4)
$$
なお,LSTMが以下のように計算できることに注意する
$$i_{t}=\sigma\left(W_{x i} x_{t}+W_{h i} h_{t-1}+b_{i}\right)$$
$$f_{t}=\sigma\left(W_{x f} x_{t}+W_{h f} h_{t-1}+b_{f}\right)$$
$$c_{t}=\tanh \left(W_{x c} x_{t}+W_{h c} h_{t-1}+b_{f}\right)$$
$$\tilde{c_{t}}=f_{t} \odot c_{t-1}+i_{t} \odot \tilde{c_{t}}$$
$$o_{t}=\sigma\left(W_{x o} x_{t}+W_{h o} h_{t-1}+b_{o}\right)$$
$$h_{t} \odot \tanh \left(c_{t}\right)$$
すなわち,一項目が行列計算に当たり,二項目はその和をとる部分と思われる.
多くの場合,$L_i < L_h$なため,計算量は$O(L_h^2)$.
計算資源がハードウェア及び設計のスケーラビリティに制限されているため,タイリングすべきである.
タイル間の通信はパイプライン化して処理することでスループットを最大化する.同タイルレベルでは多くのループを展開し,計算を並行処理することでレイテンシを最小化する.
タイリング
ここで言うタイリングはおそらく,計算の要素を細かくわけることを言っていると思う.
本論においては以下の要素をタイリングする.
- 各ゲートのループ単位
- 入力ベクタ及び重み行列
活性化関数の最適化
活性化関数はLSTMにおいて2番目に計算頻度が高い部分である.
浮動小数点の割り算は非常に多くのハードウェア資源を要するため,計算精度とハードウェア資源とのトレードオフとなる.具体的には活性化関数を簡略化する手法が考えられ,本論では区分線形関数によって非線形関数を近似(PLAN)する.PLANを利用したとしても本論では誤差率の平均は0.63%に留まった.
通信の最適化
深層学習で使用する入力やモデルは大きすぎるため,FPGAチップ上のメモリには載せることができず,多くの場合外部のDRAM上に配置する.しかし,最近のLSTM及びRNNのモデルは10M以下であるため,一部または全体を載せることが可能.これによってチップ外のメモリにアクセスするレイテンシを減少させることができる.本論では一部を載せる折衷的な方法を採用する.
最適化の方法は他にもある.推論を行うために必要なデータ転送量は計算式から
$$
(L_i + L_h) \times L_h \times 4 + L_h \times 4
$$
と表せる.つまり計算量は$O(L_h^2)$.さらに,こうしたデータ,すなわち行列やベクタは最適化のために転置やタイリングされる必要がある.結果として効率的なアクセスが難しくなり,バンド幅を確保することが難しくなる.
したがってランダムアクセスのオーバヘッドを抑制するためにアクセスがシーケンシャルになるように並べ替える(まあ,アクセス順番は設計に応じて一意に定まりそうなので比較的簡単にできそう).この再構成命令はオフラインで行うため,再構成によってパフォーマンスは絶対に低下しない.それまでの間はデータアクセスにピンポン方式で動くように二つのインプットバッファと二つのアウトプットバッファを実装する.さらに,Data Dispatcherを設計し,DRAMとFPGA間でのデータ利用のバンド幅を最大化する.
Implementation
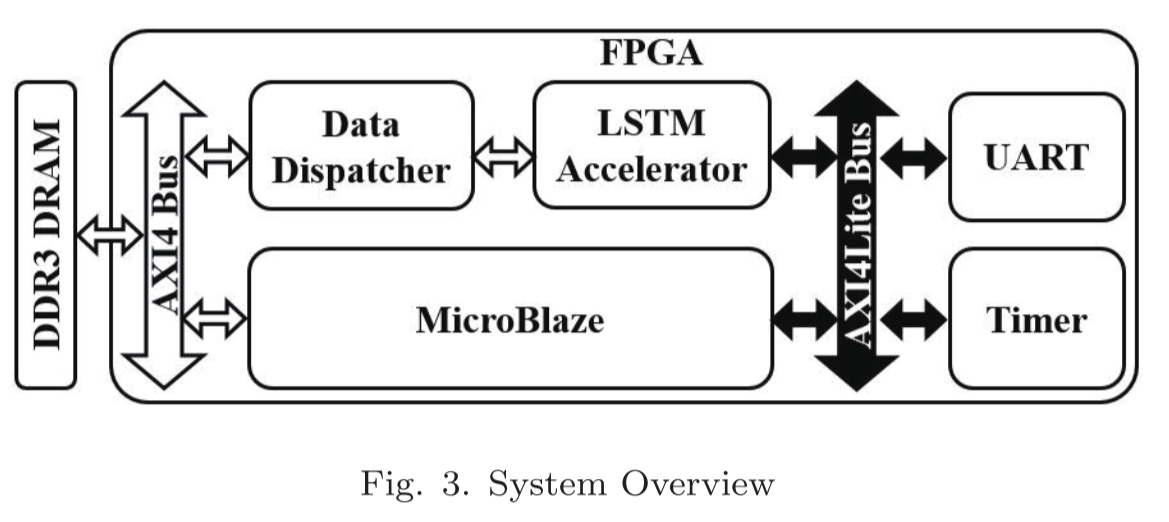
システムの全体像
- DDR3 DRAMは入力ベクタ,出力ベクタ,パラメータを保持
- LSTM AcceleratorはIPコアとしてパッケージングされている
- LSTM Acceleratorの初期化,実行時間の計測,アクセラレータ-DRAM間データ通信にMicroBlazeを使用.
- Data Dispacherは二つのFIFOを用いてLSTM Acceleratorと通信
- Data Dispacherはmulti-IPインタフェースを使用することでAXI4バスの物理的なデータ幅を全て使用する
- UARTモジュールは計算結果をホストに戻す役割
- TimerはLSTM Acceleratorの実行時間を計測する
IPコア
機能回路を構成するための部分的な回路情報で,FPGA/ASICの開発などプログラマブルロジックデバイスを用いた開発で利用される.ストレージ系,ペリフェラル系,映像処理系,画像処理系などの機能が実装されている.
MicroBlaze
ザイリンクスによる,ザイリンクス製FPGA向けに構築したソフトプロセッサコア.MicroBlazeはザイリンクスのFPGAの汎用メモリと論理回路で、32bitソフトプロセッサとして実装している.
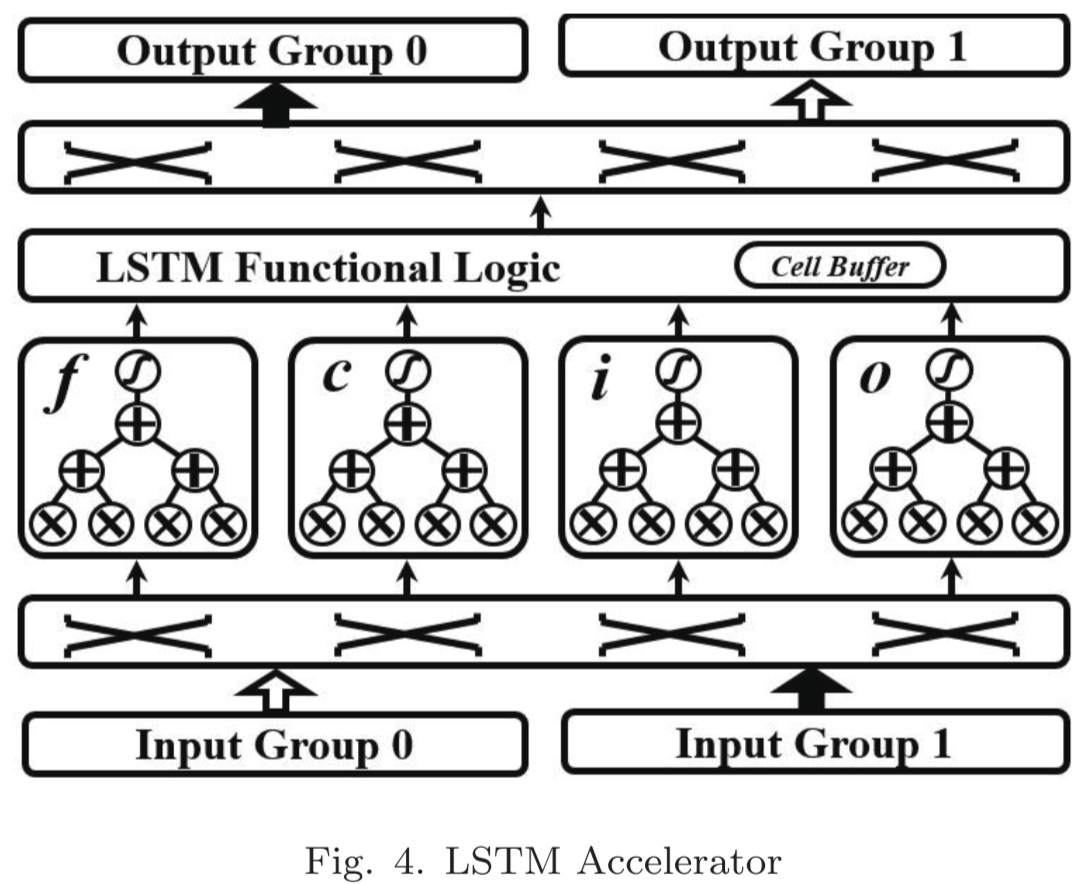
LSTM Accelerator
チップ上のデータバッファは二つの入力,及び出力に分けられており,ピンポン方式で回帰的にデータ通信をする.
中心的な部分は4つのゲートで構成されており,それぞれの出力はゲートベクタとなる.データのフェッチはクロスバーを通して行われる.LSTM Functional Logicは要素ごとの積,ゲートベクタの和,アクティベーション等の計算を行う.最後にクロスバーを通してアウトプットバッファに蓄えられる.LSTMの状態はCell Bufferに格納される.
タイリングされたベクタは各LSTMゲートに入力されたのち,並列に処理される.総和計算は木構造で行うことでレイテンシを最小化する.全体の処理はパイプライン化されている.