序論
Motoです。メーカー研究職勤務。
継続学習のモチベーション維持法の1つとしてQiitaにoutputしていくことにしました。
目標は年間100投稿。つまり月7-8投稿、週2投稿を目安として頑張っていきたいです。
質ももちろん大事ですが、気にしだすと結局やらない。。というのが私の特性なので
雑でもいいからとにかくやる!という意識で雑に論文を読んでいく【雑論】というハードルを下げたタイトルにしてみました。未来の自分に祈る!!怠惰な自分頑張れ!
[本日の論文Title]:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
URL:https://arxiv.org/abs/2010.11929
論文読み時間:1H
←論文難易度の指標にならないかを個人的にメモしてます
1.どんなもの?
・NLP(自然言語処理タスク)のデファクトスタンダードともなってきてTransformerを画像認識に応用した研究
・事前学習を利用すると、最新のCNNに匹敵する性能
2.先行研究と比べてどこがすごい?
・これまでTransformerを画像に適用すると精度がでなかったりしたが、
一般的なTransformerをできる限りそのままの形で画像に適用することを提案し高い精度を達成した点
3.技術や手法のキモはどこ?
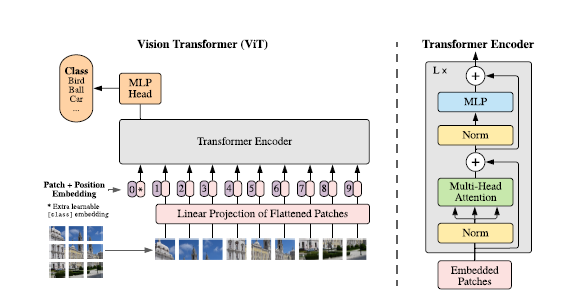
・画像をgrid上に分割し、それぞれの画像パッチをTransformerでいう単語のように見なして入力とした点
・TransformerのEncorder+Headといったアーキテクチャで実現
・大規模データセットで学習させた事前学習モデルを小規模データセットを用いたタスクにてfine tuneingすると精度が出る点
・ ViTが大きなモデルであるほど大きなデータセットでの事前学習の効果が強く表れる
→事前学習とfine tuningが高精度のキモ
↓ViTのアーキテクチャ
4.その他、工夫や得られた知見(細かいところ)
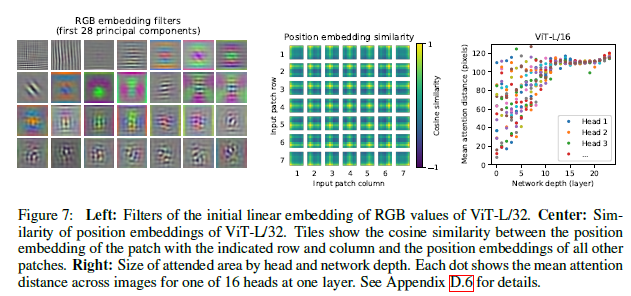
・ 画像パッチは1次元化された後、Position Embedding(位置エンコーディング)されて入力とされる
・同じ行・列の位置エンコーディングの類似度は似るように学習されている
・位置情報に加えて分類タスクの場合、先頭に[class]をEmbeddingする
→パッチ埋め込みと呼ばれる
・オリジナルのTransformerとの差分は、Normの位置と活性化関数GELUを採用した部分
・CNNは下位層で局所的、上位層で大域的な特量表現を得ることが知られているが、
ViTでは下位層で局所的+大域的な特量表現、上位層で大域的な特量表現を得ている
→逆に言えば、ViTは層を重ねても異なる表現を獲得しにくいとも捉えられる
・局所的な表現は特に重要で、これが行われていないと性能の劣化が顕著に起こる
→CNNのパフォーマンスは下位層でしっかりと局所的な特量表現を得ることができているから実現するという解釈になる
・ハイブリット・アーキテクチャとして画像パッチをCNNで畳み込んで得られた特徴マップに変換したのちに入力するアイディアもアリだとされている
・ViTのモデルサイズが小さい場合にCNNとのハイブリット型の効果が大きく出るが、モデルサイズが大きい場合は効果は小さくなる
・ViTにおけるスキップコネクションは重要であることも示されている
・ViTの空間情報はある領域に集中しているが、CNNは幅広い領域に拡散していて情報がぼやける傾向にあることがわかる
・ViTはメモリ効率がCNNよりも優れている
・事前学習よりもfine tuningの際の解像度を大きくするとよい
・パッチのサイズは事前学習とfine tuningで一定
・fine tuning時に足りない位置エンコーディングは内挿で補完
5. 議論はある?
・事前学習について、ViTのfew-shot特性をさらに分析すると有望(本論文では十分に言及されていないから)
・ViTで最適化されていない部分は、パッチ抽出と解像度調整(事前学習の解像度とギャップができる場合に行うべき)であるとされている
・メモリ効率が良いが、Attentionの計算複雑度O(N^2)がボトルネック
6.感想
・メモリ効率は良いとのことだけど実際エッジに乗せると速度はどうなるんだろうと思いました。
(組み込んでみて同じくらいの規模のCNNと比較してみたい)
・事前学習の影響が高いということで、自己教師系の事前学習手法は要チェックだなと思いました。
・結果の示し方が面白くて参考になるなと思いました。(Size of attended area by head and network depthの表とか)