基本統計量の一覧は大体毎日見るが、意外とその作り方とパターンの説明が少ないと思う。
そのためよく使う作り方を示す。
- proc means を使う方法(標本の基本統計量 sample)
- proc means を使う方法(母集団の基本統計量 population)
- データセットを自作する方法
1) proc means を使う方法(標本の基本統計量 sample)
コード
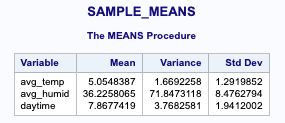
一番シンプルだが、自由度n-1のいわゆる不偏分散を使用する。
分散
s^{2}=\frac{1}{n-1}\sum_{i=1}^{n}\left ( x_{i}-\overline{x} \right )^{2}
%let sourceDS = 使用するデータセット;
TITLE SAMPLE_MEANS;
proc means data=&sourceDS mean var std;
var avg_temp avg_humid daytime;
run;
出力
2) proc means を使う方法(母集団の基本統計量 population)
コード
vardef=n がオプションで追加される。これは
分散の定義(definition of variance) の設定をしている。
自由度(degrees of freedom) は n つまりデータの個数にすることを意味する。。
よって下記で表す分散を使用する。
分散
\sigma^{2}=\frac{1}{n}\sum_{i=1}^{n}\left ( x_{i}-\overline{x} \right )^{2}
%let sourceDS = 使用するデータセット;
TITLE POPULATION_MEANS;
proc means vardef=n data=&sourceDS mean var std;
var avg_temp avg_humid daytime;
run;
出力

3) データセットを自作する方法
コード
手間は増えるが
- 一覧で見たい時、
- 独自に取得したい統計量を追加する時、
- コードをまとめてしまいたい時、etc
にはどうしてもこうなる。
しかしマクロ化すれば良いだけなので作る価値は十分にある。
ポイントは基本統計量の変数を自作する際のCOL:だ。
これでCOL1のようにCOL+数字の変数すべてを計算の範囲に指定している。
これによりCOL変数の数を気にしなくても良くなる。
SASの関数の引数にするときは(of COL:)のようにof をつけることに注意しよう。
%let sourceDS = 使用するデータセット;
%let popDS01 = 基本統計量の元となるデータセット;
TITLE 使用するデータセット;
proc print data=&sourceDS;
run;
/* データのタテヨコを入れ替える*/
proc transpose data=&sourceDS out=&popDS01;
run;
TITLE 基本統計量の元となるデータセット;
proc print data=&popDS01;
run;
/* 基本統計量の変数を自作する */
data &popDS01;
set &popDS01;
N_ = N(of COL:); /* データの個数 */
Avg_ = mean (of COL:); /* 平均 */
Var_ = (N_ -1)/ N_ * var(of COL:); /* 母集団の分散 */
Std_ = sqrt(Var_); /* 母集団の標準偏差 */
Var_S_ = var(of COL:); /* 標本の分散(不偏分散) */
Std_S_ = sqrt(Var_S_); /* 標本の標準偏差(不偏標準偏差) */
attrib
_NAME_ LABEL="項目名"
N_ LABEL="個数"
Avg_ LABEL="平均"
Var_ LABEL="分散"
Std_ LABEL="標準偏差"
Var_S_ LABEL="不偏分散"
Std_S_ LABEL="標本標準偏差"
;
run;
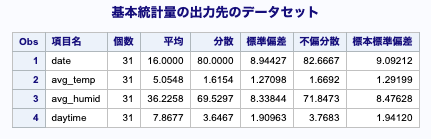
TITLE 基本統計量の出力先のデータセット;
proc print data=&popDS01 label;
var _NAME_ N_ Avg_ Var_ Std_ Var_S_ Std_S_
;
run;
quit;
出力
終わりに
質問、間違いなどがあればコメントください。