Step Functions Distributed Map が発表されましたね!
先日の AWS re:Invent にて、Step Functions Distributed Map が発表(GA)されました!
(Distributed Map の公式リリースは以下。日本語でリリース内容を知りたい方はDevelopersIOによる速報を参照)
上のリンクの通り、公式リリースでは手動でAWSコンソール上から実現する手順が記載されています。
しかしながら、実際に商用で利用する場合には、AWS CDK や Serverless Framework などを用いて管理したいところです。
そこで本記事では、Serverless Framework を用いて、Step Functions Distributed Map を構成することを最終目標に、そもそもMapステートってなに?というところから順に書いていきます。
Step Functions の Mapステートとは
Step Functions とは
AWS Step Functions は、AWS の提供するワークフローサービスで、データ処理やマイクロサービスのオーケストレーションなどに活用されます(参考)。
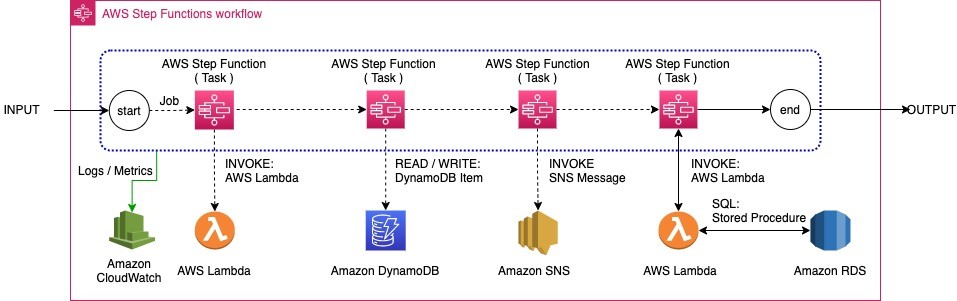
参考に、AWS公式が提示する事例の画像を見てみます(以下)。AWSの様々なサービスを順序よく実行できることがなんとなくイメージできるかなと思います。
Map ステートとは何か ・ 何が嬉しいか
ここで、こういったワークフローの中に 「1000個の要素を持つ配列のそれぞれについて処理を行うタスク」 があると考えてみましょう。
仮にこの処理が1つの要素あたり10秒かかるとすると、3時間程度 かかってしまうことになります(10秒 x 1,000要素 = 10,000秒)。
この部分を40並列で実行できれば、この3時間ほどかかっていた処理を 約4分 に短縮することができます(10,000秒 / 40 = 250秒)。
それを簡単に実現できるのが Map ステートという設定になります。
従来の Mapステートの問題点
従来の Mapステートでは、この 並列処理実行数に40程度の制限 がありました。
そのため、40並列以上を達成したい場合、並列処理をネストしてどうにかしろと公式がアナウンスしていました。
(英語版からは既に削除されている記述のため、日本語版ドキュメントをスクショしたものを以下に添付します。自動翻訳なので日本語があれですが)

ちなみにですが、英語版ドキュメントでは従来バージョンのことを Inlineモード と呼んでおり、将来的には日本語ドキュメントもその呼称になるものと思われます。
Distributed Mapの何がすごいか
もうおおよそ予想がついてることと思われますが、Distributed Map を用いると、最大で 10,000並列 まで可能になります。
すごい!!!!!!!
並列実行させるサービスでも並列実行可能な上限が変わります。Lambdaの場合はデフォルトの同時実行可能数が1000のため、上限の引き上げを行わなければ、1000より大きい値を設定するとエラーとなります
Serverless Framework で実現する方法
それでは、Distributed Map のすごさがわかったところで、Serverless Framework と Lambda を使って実際に動かす方法をステップ別に説明していきます(エラーハンドリングとかは今回は無視)。
※ 最近使い始めたTypeScriptで書いていきます(が、動けばいいだけのコードではあるのでご容赦を)
※ AWS CLI や Serverless Frameworkの細かな設定や解説まで書くと長くなりすぎるので要点だけ書いていきます
※ バージョンはこれで試してます
$ sls --version
Running "serverless" from node_modules
Framework Core: 3.25.1
Plugin: 6.2.2
SDK: 4.3.2
Step1: Lambda 関数の作成
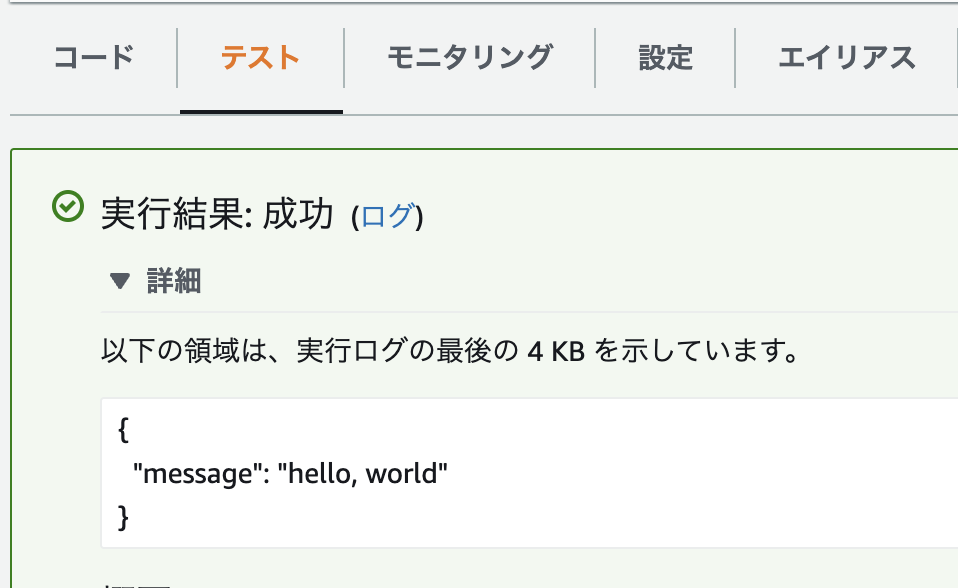
とりあえず Hello, world してくれる関数を用意します。
export const hello = (_event, _context, callback) => {
callback(null, { message: "hello, world" });
};
Serverless Frameworkでは、以下のように functions: の下に各 Lambda の定義を書いていきます。
(複数 Lambda を使用する場合は、 hello と同階層に複数設定が並ぶ形ですね)
functions:
hello:
handler: handler.hello
諸々設定できたら、以下でAWS上にデプロイできます。
$ sls deploy
AWSコンソールから手動で Lambda をテスト実行するとちゃんと動いてくれます。
Step2: Step Functions workflow の作成
それでは、同じ要領で複数の Lambda を作っていき、それを Step Functions workflow でつなげてみます。
今回は、以下の2つの処理を行うワークフローを作ることとします。
- 0 ~ 9 までの10個の要素を持つ配列を作成
- 1で作成した配列の各要素を2倍にした配列を作成
まずは、Step1と同様にして2つの Lambda を作ります。
/**
* 0 ~ 9 までの10個の数値を持つ配列を作成
*/
export const firstFunction = (_event, _context, callback) => {
const values = [...Array(10)].map((_, i) => i);
callback(null, values);
};
/**
* 受け取った配列の各要素を2倍した配列を作成
*/
export const secondFunction = async (event, _context, callback) => {
const result = event.map((x) => x * 2);
callback(null, { result: result });
};
functions:
first-function:
handler: handler.firstFunction
second-function:
handler: handler.secondFunction
これを Step Functions で取り扱うには、serverless-step-functions というプラグインを導入する必要がありますので、$ yarn add --dev serverless-step-functions などとしておきましょう(このプラグインのGitHubレポジトリ)。
あとは、以下のように Serverless Framework の設定ファイルに記述し、$sls deploy すればOKです(この後に紹介する図の雰囲気で設定内容は理解できるので詳細は割愛)。
plugins:
- serverless-step-functions
stepFunctions:
stateMachines:
sampleStateMachine:
name: sampleStateMachine
definition:
StartAt: FirstState
States:
FirstState:
Type: Task
Resource:
Fn::GetAtt: [first-function, Arn]
Next: SecondState
SecondState:
Type: Task
Resource:
Fn::GetAtt: [second-function, Arn]
End: true
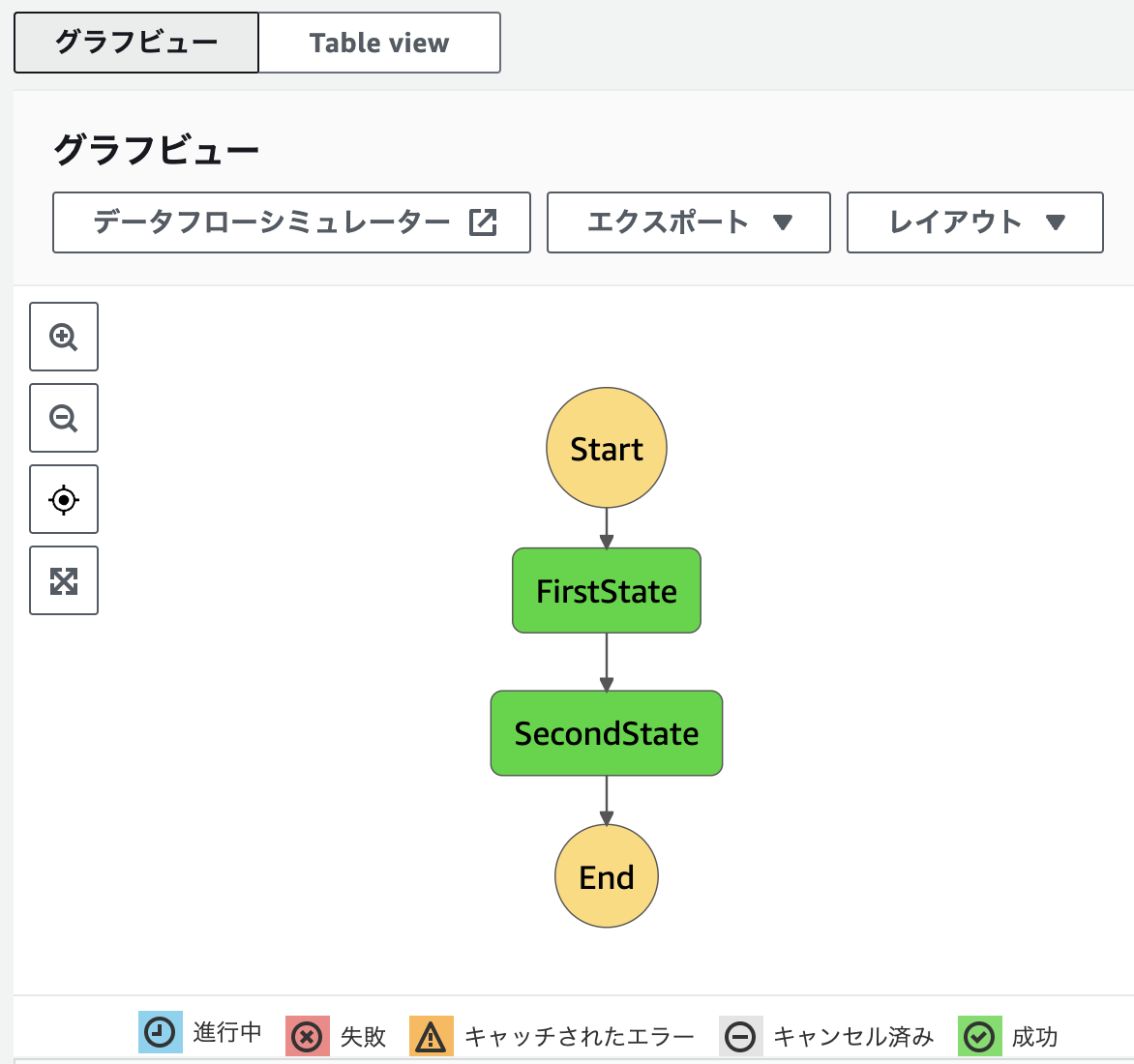
AWSコンソールから該当のステートマシンを見にいくと、このような図を見ることができます。順序よく実行されそうな雰囲気が漂っていますね。それぞれの State が各 Lambda に対応しています。
実際に実行してみると、以下のように実行状態を確認できます(今回はすぐに完了してしまったので全て緑)
復習ですが、今回はこのようなワークフローでした。
- 0 ~ 9 までの10個の要素を持つ配列を作成
- 1で作成した配列の各要素を2倍にした配列を作成
最終的な実行結果を見てみると、確かにうまくいっていることがわかります。

ちなみにですが、各ステートの入出力を確認することもできます。
( FirstState の返り値が次の SecondState に Step Functions により渡されているのが分かります)

Step3: Mapステート (Inline モード)の適用
次に並列処理を実装してみましょう。並列処理の威力をわかりやすくするために10秒かかる処理を無理やり入れてみます。
- 0 ~ 9 までの10個の要素を持つ配列を作成
- (並列処理) 各要素の値を 10秒待った後 2倍する
- 2で実行された結果を表示
まずは例によって各関数を実装します。
/**
* 0 ~ 9 までの10個の数値を持つ配列を作成
*/
export const firstFunction = (_event, _context, callback) => {
const values = [...Array(10)].map((_, i) => i);
callback(null, values);
};
/**
* 受け取った値を10秒待った後に2倍する
*/
export const secondFunction = async (event, _context, callback) => {
const sleep = async (ms: number) => {
return new Promise((resolve) => setTimeout(resolve, ms));
};
await sleep(10000);
callback(null, { secondFunctionResult: event * 2 });
};
/**
* 並列処理された結果をどのように受け取るかを確認するための関数
*/
export const finalFunction = async (event, _context, callback) => {
callback(null, { finalResult: event });
};
※ serverless framework の Lambda 関数の処理時間のデフォルトは6秒であり、10秒間待つ処理を行えないため、今回は適当にタイムアウトの時間を伸ばしておきます
functions:
first-function:
handler: handler.firstFunction
second-function:
handler: handler.secondFunction
timeout: 30
final-function:
handler: handler.finalFunction
設定は以下のように行います。ポイントは以下の2つですかね。
- 並列処理を行いたいステートについて
Type: Mapと設定- その中に
Iteratorという項目を作り、並列処理させたい Lambda について記載
- その中に
-
MaxConcurrencyで最大並列実行数を指定
stepFunctions:
stateMachines:
sampleStateMachine:
name: sampleStateMachine
definition:
StartAt: FirstState
States:
FirstState:
Type: Task
Resource:
Fn::GetAtt: [first-function, Arn]
Next: SecondState
SecondState:
Type: Map
MaxConcurrency: 5
Iterator:
StartAt: MyMapTask
States:
MyMapTask:
Type: Task
Resource:
Fn::GetAtt: [second-function, Arn]
End: true
Next: FinalState
FinalState:
Type: Task
Resource:
Fn::GetAtt: [final-function, Arn]
End: true
デプロイしてみると以下の図を見ることができます。並列処理してくれそうな雰囲気が漂っていますね。
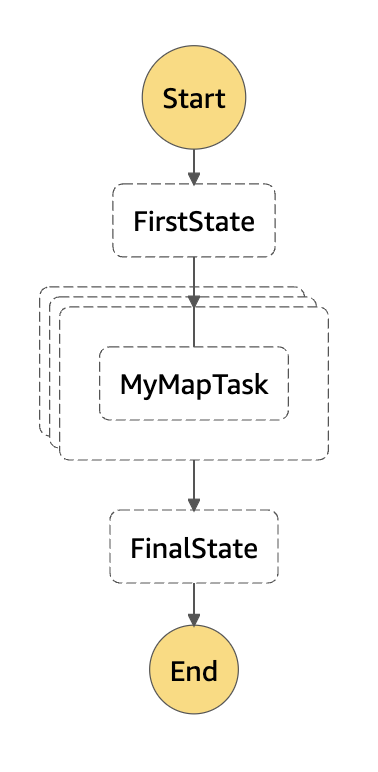
実行し、結果を見てみましょう。
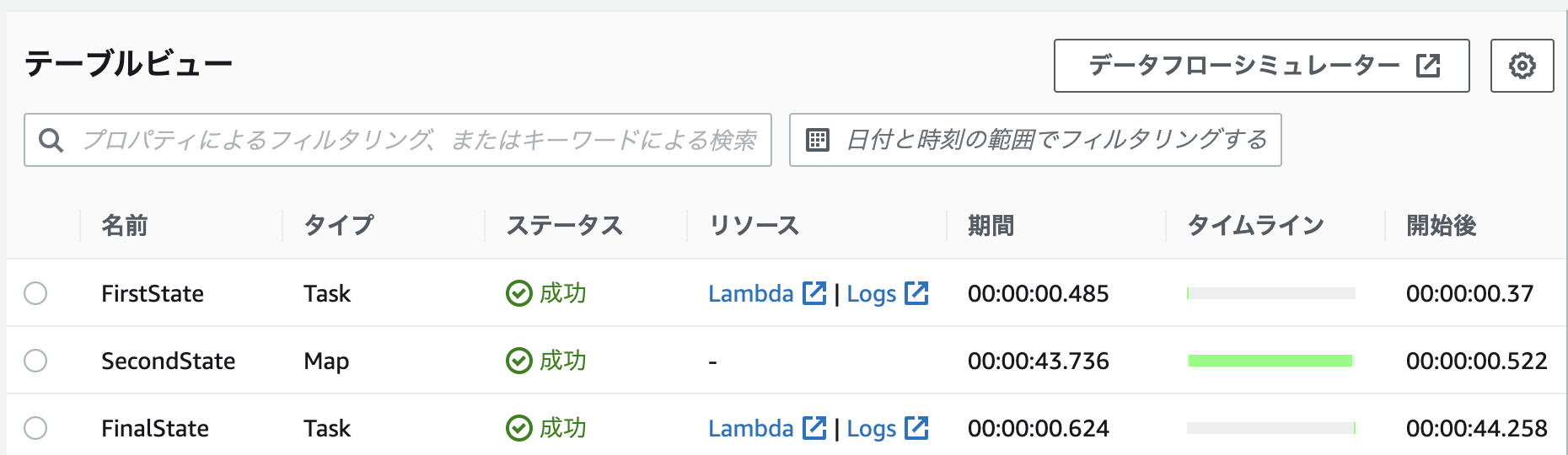
まずは各処理にかかった時間から見ていきます。
10秒かかるタスクが10個あるので、並列に実行した場合に1分40秒はかかるタスクが、5並列で実行したことで、合計20秒程度で完了したことが分かります。
また、最初の5個のタスクが完了するまで待ってから 残りの5つについても処理を行っている様子がよく分かるかと思います。この辺りも勝手に調整してくれるのは楽ですね。

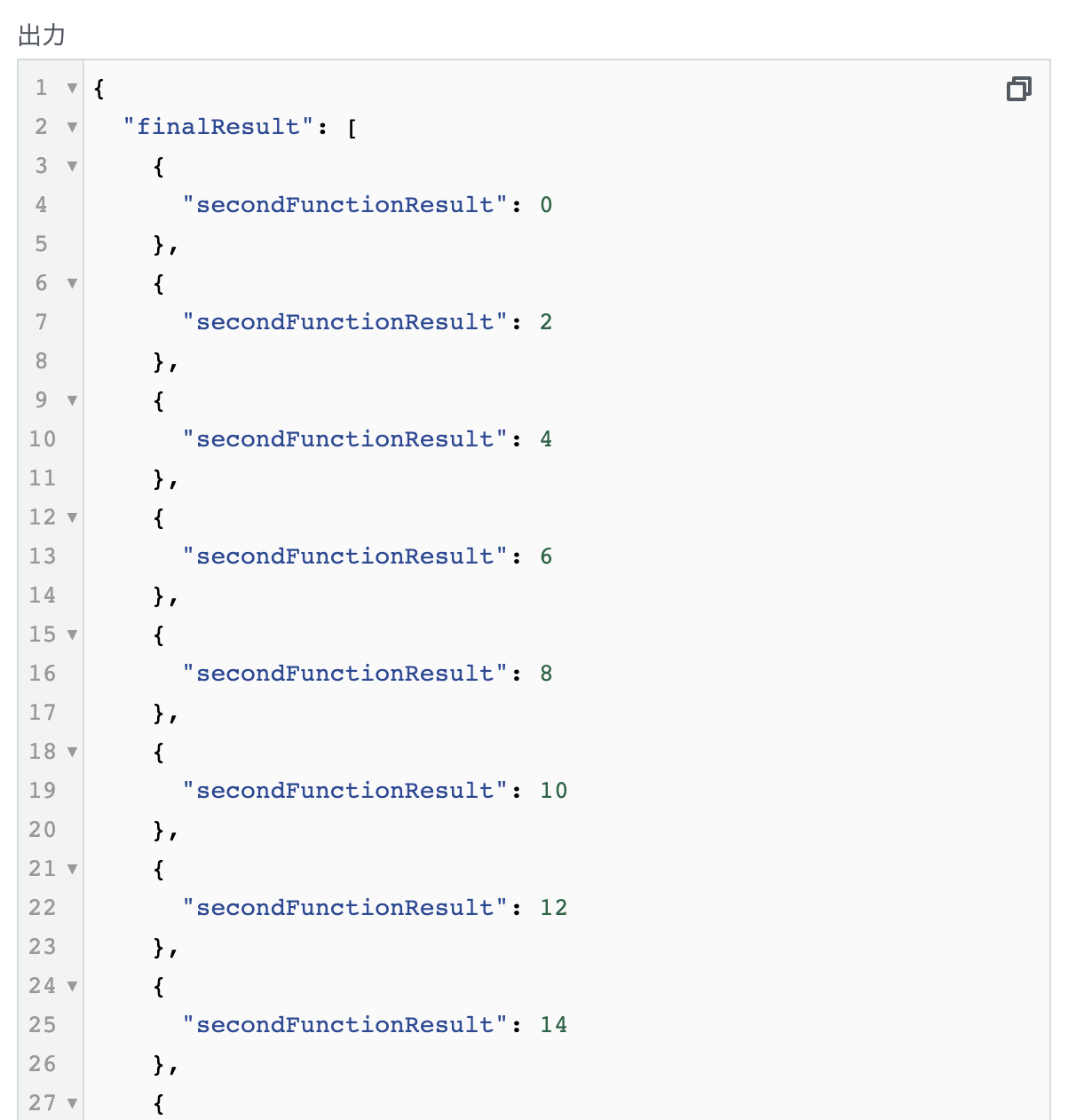
次に肝心の出力結果ですが、こちらもうまく動いてくれたことが分かります。
また、下が見切れていて少し分かりづらいですが、 各並列処理の返り値を配列にまとめた上で、次のステートに渡される ことが確認できますね。
試しに1000個のタスクを用意し、MaxConcurrencyを500に設定してみたのですが、50並列相当の時間がかかりました。ドキュメントの通り、40を超えるような設定はあまり意味ないですね。
Step4: Distributed Map の適用
最後にメインの Distributed Map の設定方法を見ていきましょう。この記事を執筆した2022年12月8日現在では、日本語ドキュメントには項目自体が存在しないため、英語ドキュメントを確認する必要があります(東京リージョン対応してるんだから、項目くらい追加しておいてくれると嬉しいなと思わないではない)。
そのドキュメントはこちらですね。
これにより、ItemProcessor という項目の中で、Mode を Distributed に、ExecutionType を適当に設定することで使用可能ということがわかります。

Inline モードのMapステート(従来型)のドキュメントには記載があるのですが、 Iterator というオプションが非推奨となっており、その代わりとして新たに作られたもののようです。
(ちなみに、こちらを使いたい場合は Mode に Inline を設定)

というわけで、Iterator の代わりに ItemProcessor と各種項目を設定してみたくなるのですが、これをやるとまだプラグイン側が対応していないために $ sls deploy 実行時にエラーがでてしまいます。
しかし!ここで諦めてはいけません。
試した結果 Iterator はそのままに、Mode: "Distributed" と ExecutionType を設定することで何故か動くことが分かりました。
つまりは、基本的には、このように3行追加するだけで、新機能の恩恵に預かることができるのです!
(と言いつつ、実際には states:StartExecution をこのステートマシンに追加で許可しておかないと動かないので注意。もちろん lambda:InvokeFunction も忘れずに)
SecondState:
Type: Map
MaxConcurrency: 500
Iterator:
ProcessorConfig: ← 追加
Mode: DISTRIBUTED ← 追加
ExecutionType: STANDARD ← 追加
StartAt: MyMapTask
ということで、最後にこのワークフローを試してみましょう。
並列数は 500 で試してみます!
- 0 ~ 999 までの 1000個 の要素を持つ配列を作成
- (並列処理) 各要素の値を 10秒待った後 2倍する
- 2で実行された結果を表示
処理中のスクショがこちらです。500個動いてますねー

処理時間も、並列処理でなければ3時間程度かかるところが、40秒程度で完了しています。すばらしい!
1000個のタスクを実行する場合、20sec ~ 30sec 程度のオーバーヘッドが発生するようです。そのため、1000タスク × 10sec / 500並列 = 20sec という想定よりは時間がかかります
終わりに
AWSからのちょっと早い素敵なクリスマスプレゼントでしたね。
これからも良いサーバレス & 並列処理ライフを〜