はじめに
テキストからAivisSpeechで音声ファイルを作り、Blenderで取り込みます。
これをPythonで行う方法を紹介します。
下記のVOICEVOXの記事をAivisSpeechに変えたものです。
AivisSpeechの準備
AivisSpeechは、感情豊かな合成音声を簡単に使える無料の音声合成ソフトウェアです。
下記からインストーラーをダウンロードしてインストールしてください。
※ Q&Aによると、現在実装されているAivisSpeechの基本機能は今後も永久に無料だそうです。
インストールしたら、起動してください。
VOICEVOXに似て使いやすそうです。
起動したら、GUIでも使えますが、Webサーバーとしても使えます。そのため、以下の処理中は起動したままにしておいてください。
Blenderからはcurlを使ってWebサーバーの方にアクセスします。
もし、curlが入ってなければ、インストールしておいてください。
※ Web APIは、VOICEVOX互換です。
BlenderのPythonによる音声作成の手順
Blenderを起動してください。今回は、バージョン4.3で動作確認しています。
BlenderでPythonを実行する方法については、下記を参考にしてください。
Scriptingワークスペースを開いてください。
テキストエディターの「新規」を押し、次のコードをコピペしてください。
import subprocess
import time
from pathlib import Path
import bpy
# アニメーション用の設定
bpy.context.scene.frame_end = 67 # 終了フレームを67に設定
bpy.context.scene.render.image_settings.file_format = "FFMPEG"
bpy.context.scene.render.image_settings.color_mode = "BW"
bpy.context.scene.render.ffmpeg.format = "MPEG4"
bpy.context.scene.render.ffmpeg.audio_codec = "AAC"
fps = bpy.context.scene.render.fps # Frames Per Second
se = bpy.context.scene.sequence_editor
# delete all sequence
for s in se.sequences_all:
se.sequences.remove(s)
# サンプルの設定データ
lines = [
# オフセット秒、スピーカーID、テキスト
["0", "888753760", "3D CGなら"],
["1.6", "888753760", "ブレンダー!"],
]
header = "Content-Type: application/json"
tmp = Path(bpy.context.scene.render.filepath)
if not tmp.is_dir():
tmp = Path("/tmp")
if not tmp.is_dir():
tmp = Path("/temp")
for i, line in enumerate(lines, 1):
try:
second, *minutes = map(float, reversed(("0:" + line[0]).split(":")))
speaker = int(line[1])
text = line[2]
except (IndexError, ValueError):
print(f"Error at line {i}: {line}")
break
frame_start = int((minutes[0] * 60 + second) * fps)
url = f"localhost:10101/{{}}?speaker={speaker}"
text_file = tmp / "text.txt"
text_file.write_text(text)
# クエリ作成
cmd = f'curl -s -X POST {url.format("audio_query")} --get --data-urlencode text@{text_file}'
result = subprocess.run(cmd.split(), capture_output=True, check=False)
query_file = tmp / "query.json"
query_file.write_text(result.stdout.decode())
# 音声合成
cmd = f'curl -s -H {header} -X POST -d @{query_file} {url.format("synthesis")}'
result = subprocess.run(cmd.split(), capture_output=True, check=False)
audio_file = tmp / f"audio{i:03}.wav"
audio_file.write_bytes(result.stdout)
# 音声シーケンス作成
ss = se.sequences.new_sound(
audio_file.name, str(audio_file), i * 2, frame_start
)
ss = se.sequences.new_effect(
f"txt{i:03}",
"TEXT",
i * 2 + 1,
frame_start,
frame_end=ss.frame_final_end,
)
ss.text = text
time.sleep(0.1)
※ VOICEVOX互換なので、元記事の localhost:50021 を localhost:10101 にしてスピーカーIDを変更するだけでも動きます。
テキストメニューの「スクリプト実行」を選び、実行してください。
数秒ほどで音声シーケンスが作成されます。
音声シーケンスの確認
作成した音声シーケンスを確認してみましょう。
画面左上の3Dビューポートをビデオシーケンサーに切り替えます。
下記のように、2つの音声シーケンスが確認できます。
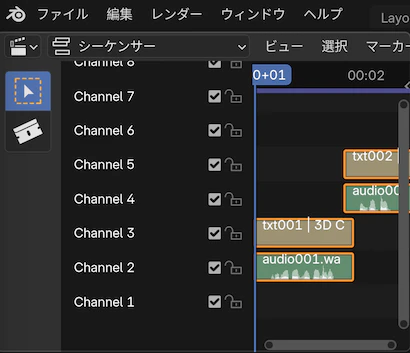
カーソルが音声シーケンスの画面上にある状態でスペースキーを押すと再生/停止を切り替えできます。
アニメーションレンダリング
レンダーメニューの「アニメーションレンダリング」を選んでください。アニメーションファイルが出力されます。
デフォルトの出力パス(例:/tmp)に0001-0067.mp4というファイルで作成されます。
アニメーションでは、音声とテキストが表示されます。
スピーカーIDの決め方
スピーカーIDは、音声合成モデルのスタイルを識別する整数です。
今回使った888753760は、デフォルトの音声合成モデルAnneliのノーマルスタイルになります。
どのような音声合成モデルのスタイルが利用できるかは、Web APIから取得できます。
具体的に見てみましょう。
AivisSpeechを起動した状態で、 http://localhost:10101/ をブラウザで開いていください。
次のような画面が表示されます。
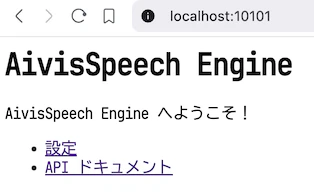
「API ドキュメント」をクリックしてください。Swagger UIの画面が開きます。
この中から「その他」の /speakers をクリックしてください。
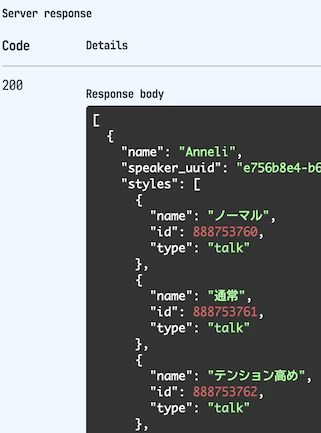
「Try it out」を押して表示される「Execute」をクリックすると、少し下に「インストールされている音声合成モデルとそのスタイルの一覧」が表示されます。
さいごに
Blenderで、3Dオブジェクトのアニメーションがあれば、今回のスクリプトで文字と音声を追加できます。
いろいろ試してみてはいかがでしょうか?
以上