概要
日本地図を県別に色分けするPythonのライブラリ(japanmap)を作成したので紹介します。
実行例は、JupyterLab上で確認しています。
インストール
pipでインストールできます。NumPy、OpenCV、Pillowも一緒にインストールされます。openpyxlは、Excelファイルの読み込みで使います。
pip install -U japanmap jupyterlab matplotlib pandas openpyxl
JupyterLabは、jupyter labで起動します。
都道府県コードとは
都道府県コード(以降、県コードと略す)は、JIS X 0401により定められた、各都道府県ごとの01から47のコードです。
プログラムでは整数で扱います(頭の0を無視します)。
県名確認
pref_namesで県コードごとの県名がわかります。
from japanmap import pref_names
pref_names[1]
>>>
'北海道'
pref_codeで県名に対する県コードがわかります。
from japanmap import pref_code
pref_code("京都"), pref_code("京都府")
>>>
(26, 26)
groupsで八地方区分ごとの県コードがわかります。
from japanmap import groups
groups["関東"]
>>>
[8, 9, 10, 11, 12, 13, 14]
白地図
pictureで白地図(ラスタデータ)を取得できます。
%config InlineBackend.figure_formats = {"png", "retina"}
import matplotlib.pyplot as plt
from japanmap import picture
plt.rcParams["figure.figsize"] = 6, 6
plt.imshow(picture());

県を色で塗ることもできます。
plt.imshow(picture({"北海道": "blue"}));
PNGファイルへの保存
savefigでファイルに保存できます。
plt.imshow(picture({"北海道": "blue"}))
plt.savefig("japan.png")
隣接情報
is_faced2seaで県コードに対して、庁所在地を含むエリアが海に面しているかわかります。
from japanmap import is_faced2sea
for i in [11, 26]:
print(pref_names[i], is_faced2sea(i))
>>>
埼玉県 False
京都府 True
is_sandwiched2seaで県コードに対して、庁所在地を含むエリアが海に挟まれているかわかります。(連続でない海辺が2つ以上あるか)
from japanmap import is_sandwiched2sea
for i in [2, 28]:
print(pref_names[i], is_sandwiched2sea(i))
>>>
青森県 False
兵庫県 True
adjacentで県コードに対して、庁所在地を含むエリアが隣接する県コードがわかります。
from japanmap import adjacent
for i in [2, 20]:
adj = " ".join(pref_names[j] for j in adjacent(i))
print(pref_names[i], ":", adj)
>>>
青森県 : 岩手県 秋田県
長野県 : 群馬県 埼玉県 新潟県 富山県 山梨県 岐阜県 静岡県 愛知県
境界線のベクトルデータ
get_dataで各県の点リストと点のindexリストを取得できます。この戻り値を使うと、pref_pointsで県の境界のリストを取得できます。
from japanmap import get_data, pref_points
qpqo = get_data()
pnts = pref_points(qpqo)
pnts[0] # 北海道の境界座標(経度緯度)リスト
>>>
[[140.47133887410146, 43.08302992960164],
[140.43751046098984, 43.13755540826223],
[140.3625317793531, 43.18162745988813],
...
pref_mapで境界線データを可視化できます。
from japanmap import pref_map
svg = pref_map(range(1, 48), qpqo=qpqo, width=2.5)
svg

SVGファイルへの保存
pref_mapは、SVG形式です。次のようにしてファイルに保存できます。
from pathlib import Path
Path("japan.svg").write_text(svg.data)
関東だけをグレースケールにする例です。
pref_map(groups["関東"], cols="gray", qpqo=qpqo, width=2.5)

県別データ(人口)を使って、県の面積比を変換
人口比で地図上の面積比を変換してみましょう。
人口データは、次の手順で取得できます。
- 総務省統計局のページを開く(https://www.stat.go.jp/)
- 上の「統計データ」の「分野別一覧」を開く(https://www.stat.go.jp/data/guide/1.html)
- 「人口推計」を開く(https://www.stat.go.jp/data/jinsui/index.html)
- 「推計結果」を押し「結果の概要」を開く(https://www.stat.go.jp/data/jinsui/2.html)
- 目次の「II. 各年10月1日現在人口」を押し、一番上の
年を開く- 2024年9月現在は「2023年(令和5年)」(https://www.stat.go.jp/data/jinsui/2023np/index.html)
- 「II 結果の概要」を押し、「第2表 都道府県、男女別人口…」を押してExcelファイルをダウンロードする(例:
05k2023-2.xlsx)
ダウンロードしたExcelファイルをpandasで開いてみましょう。
import pandas as pd
df = pd.read_excel(
"05k2023-2.xlsx",
names=["都道府県", "男女計", "男", "女"],
index_col=0,
usecols=[2, 4, 5, 6],
skiprows=11,
nrows=47,
)
df[:3]
| 都道府県 | 男女計 | 男 | 女 |
|---|---|---|---|
| 北海道 | 5092 | 2405 | 2688 |
| 青森県 | 1184 | 559 | 626 |
| 岩手県 | 1163 | 562 | 602 |
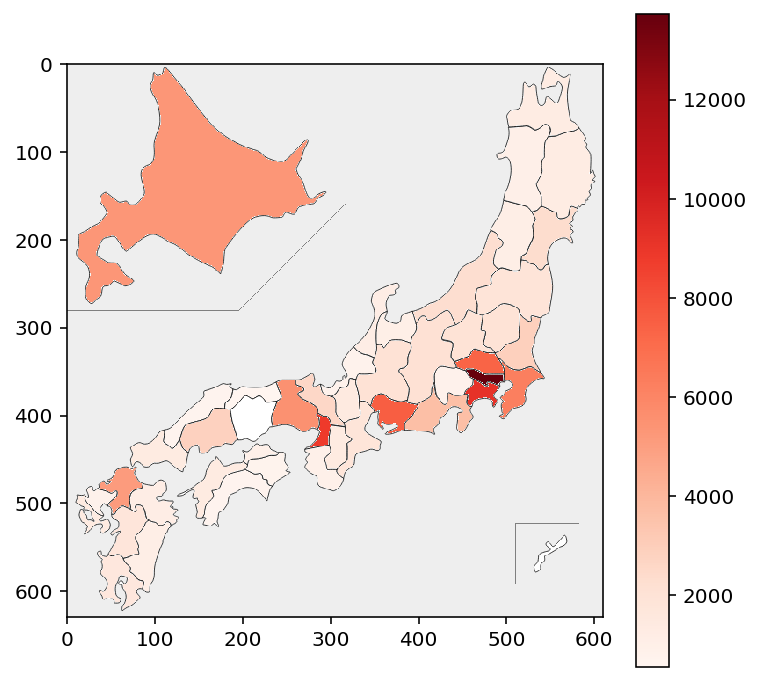
人口比の多い順に表示してみましょう。東京都の比の5.32389は、県平均の約5.3倍であることを表しています。
df["比"] = df.男女計 / df.男女計.mean()
df.sort_values("比", ascending=False)[:10]
| 都道府県 | 男女計 | 男 | 女 | 比 |
|---|---|---|---|---|
| 東京都 | 14086 | 6914 | 7172 | 5.32389 |
| 神奈川県 | 9229 | 4578 | 4651 | 3.48816 |
| 大阪府 | 8763 | 4191 | 4572 | 3.31203 |
| 愛知県 | 7477 | 3726 | 3751 | 2.82598 |
| 埼玉県 | 7331 | 3640 | 3691 | 2.7708 |
| 千葉県 | 6257 | 3099 | 3158 | 2.36487 |
| 兵庫県 | 5370 | 2551 | 2819 | 2.02963 |
| 福岡県 | 5103 | 2418 | 2685 | 1.92871 |
| 北海道 | 5092 | 2405 | 2688 | 1.92455 |
| 静岡県 | 3555 | 1754 | 1801 | 1.34363 |
可視化してみます。
trans_areaで県の面積を指定した比率に変換できます。
たとえば、県ごとの変換比率を[2, 1, 1, 1, ...]とすると、北海道が元の面積の2倍、他県が元の面積と同じ比率になります。
次では、人口が平均の2倍であれば面積を2倍にするように表示しています。
from japanmap import trans_area
qpqo = get_data(move_hokkaido=True, move_okinawa=True, rough=True)
pref_map(range(1, 48), qpqo=trans_area(df.男女計, qpqo), width=2.5)

なるべく、ラフにして歪みを減らしたのですが、なかなか厳しいです。
白地図上で人口を可視化
次のようにすると、人口の多い県を濃い赤で可視化できます。
cmap = plt.get_cmap("Reds")
norm = plt.Normalize(vmin=0, vmax=df.男女計.max())
fcol = lambda x: "#" + bytes(cmap(norm(x), bytes=True)[:3]).hex()
pic = picture(df.男女計.apply(fcol))
plt.colorbar(plt.imshow(pic, cmap, norm));
4色問題
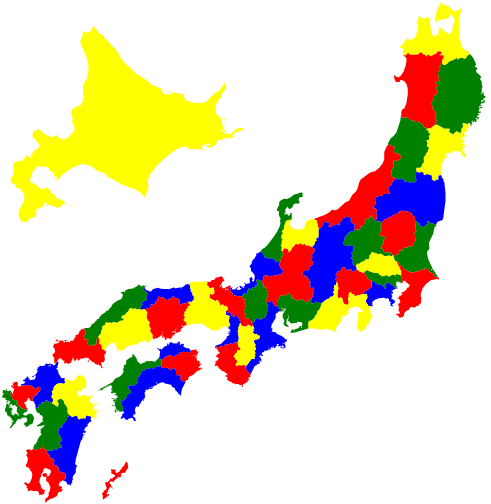
隣接情報を使って4色問題を解いてみましょう。
1つの県を1色とし、隣接する県は異なるように、日本全体を4色で塗りましょう。このように隣り合うもの同士に違う色を割当てる問題を、頂点彩色問題とよびます。
頂点彩色問題とは、グラフ上で隣接する頂点が異なる色になるように、最小の色数で頂点に色を割り当てる問題です。
この応用としては、たとえば、携帯電話の基地局ごとの周波数を決める問題があります。(異なる色→異なる周波数→電波が干渉しないので話せる)

4色問題を解く
どのような平面地図であっても隣接するエリアが異なるようにして、必ず4色以内で塗り分けられることが、数学的に証明されています。しかし、どのように塗り分けたらよいかは、自明ではありません。ここでは、数理最適化を解いて求めることにしましょう。
数理最適化は、コストの最小化などを解くときに使われますが、目的関数がない制約だけの問題でも解くことができます。数理最適化で用いるパッケージPuLPについては、最適化におけるPythonを見てください。
- 数理モデル
(1)で決めないといけないことは、変数、目的関数、制約条件の3つ - 変数:
47都道府県 * 4色 = 188個の0または1しか取らない変数を用意する- 変数は、パッケージpandasの表で管理する。この変数表
(2)を使うことで制約条件をわかりやすく書くことができる
- 変数は、パッケージpandasの表で管理する。この変数表
- 目的関数:今回は設定しない
- 制約条件:1県ごとに1色とする
(3)。隣接した県同士は、異なる色にする(4) - ソルバーを実行し解を求める
(5) - 変数表に、新しい列
Valを追加し結果を設定する(6)
次のコードを実行するためには、追加でPuLPが必要です(pip install pulp)。
import pandas as pd
from pulp import LpBinary, LpProblem, LpVariable, lpSum, value
from japanmap import adjacent, pref_map, pref_names
m = LpProblem() # 数理モデル(1)
df = pd.DataFrame(
[(i, pref_names[i], j) for i in range(1, 48) for j in range(4)],
columns=["Code", "県", "色"],
)
df["Var"] = [ # 変数表(2)
LpVariable(f"Var{i:03}", cat=LpBinary) for i in df.index
]
for i in range(1, 48):
m += lpSum(df[df.Code == i].Var) == 1 # 1県1色(3)
for j in adjacent(i):
for k in range(4): # 隣接県を違う色に(4)
m += lpSum(df.query("Code.isin([@i, @j]) and 色 == @k").Var) <= 1
m.solve() # 求解(5)
df["Val"] = df.Var.apply(value) # 結果設定(6)
四色 = ["red", "blue", "green", "yellow"]
cols = df[df.Val > 0].色.apply(四色.__getitem__).reset_index(drop=True)
pref_map(range(1, 48), cols=cols, width=2.5)
以上