IP アドレス (IPv4) の文字列表現の正当性を検証するプログラムの記事を読みました。 プログラミングの練習の題材としては興味深く手頃でとても良いと思います。
面白そうなので私もプログラムを書いてみることにしました。 以下の記事では段階を踏んで考え方を記述します。
文法を整理する
IP アドレスは 0~255 までの値を四つ並べたものであり、それぞれの間はピリオドで区切るというだけの構造ですのでそれを構文図 (Syntax diagram) の形で表現するとこうなります。
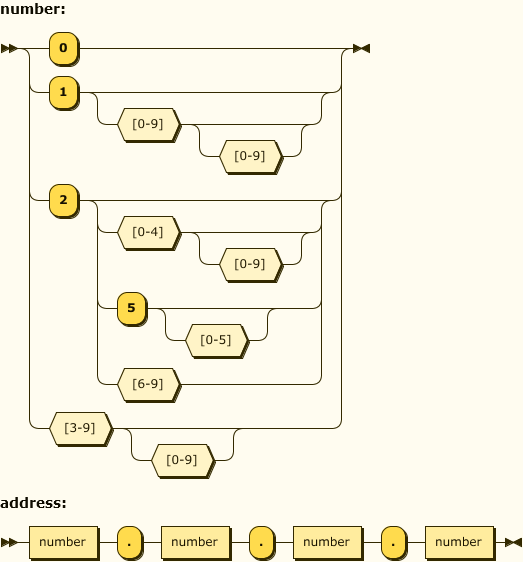
更に共通部分を統合するとこう書けます。
状態遷移図から見る文法
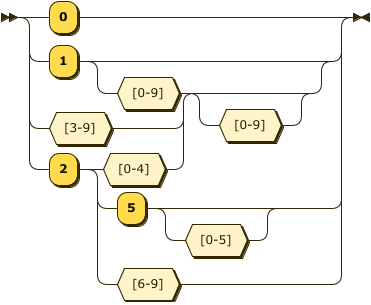
構文図はどのような構文を受け付けるかということを表していますがプログラムにするにあたっては視点を変えて「状態」に着目すると入力によって状態が変更されていくという形が見えてきます。
つまり、構文図における入力の入力間の線の部分を状態として抽出して入力は状態をつなぐ線の形として表現したもの、いわゆる状態遷移図ではこうなります。 (ここで $ は終端を便宜的に表しています。)
こんな単純な例でも線がごちゃごちゃしてきました。 状態遷移は表の形で表すこともできます。 現在の状態と入力から次の状態を導き出す表の形に変形してみましょう。
| 入力 | 開始 | S1 | S2 | S3 | S4 | S5 |
|---|---|---|---|---|---|---|
0 |
S5 | S3 | S3 | S5 | S5 | エラー |
1 |
S1 | S3 | S3 | S5 | S5 | エラー |
2 |
S2 | S3 | S3 | S5 | S5 | エラー |
3 |
S3 | S3 | S3 | S5 | S5 | エラー |
4 |
S3 | S3 | S3 | S5 | S5 | エラー |
5 |
S3 | S3 | S4 | S5 | S5 | エラー |
6 |
S3 | S3 | S5 | S5 | エラー | エラー |
7 |
S3 | S3 | S5 | S5 | エラー | エラー |
8 |
S3 | S3 | S5 | S5 | エラー | エラー |
9 |
S3 | S3 | S5 | S5 | エラー | エラー |
$ |
エラー | 完了 | 完了 | 完了 | 完了 | 完了 |
表というのはプログラムに使うには実に扱いやすい形式であることは言うまでもありません。 そのまま二次元配列にしてしまえばよいので。
プログラム
以上の考え方からプログラムを書くと最終的にこうなりました。
address_parse.h
// 文字列表現の 0~255 を解釈して返却値で返す。
// 解釈に成功した場合は残りの文字列の位置を rest にセットする。
// エラーの場合は -1 を返し、 rest は問題のある箇所がセットされる。
int parse_number(const char* input, const char** rest);
// IP アドレスの文字列表現をパースして result に格納する。
// 正しいフォーマットとしてパースが完了した場合には 1 を返し、
// そうでなかった場合には 0 を返す。
// 0 が返されたときは result の内容は信頼できない。
_Bool parse_address(const char* input, unsigned char result[static 4]);
address_parse.c
#include "address_parse.h"
#include <stdio.h>
// 状態遷移表
// -1 はエラー、 -2 は完了を表す
static const int state_tranition[][6] = {
{5, 3, 3, 5, 5, -1},
{1, 3, 3, 5, 5, -1},
{2, 3, 3, 5, 5, -1},
{3, 3, 3, 5, 5, -1},
{3, 3, 3, 5, 5, -1},
{3, 3, 4, 5, 5, -1},
{3, 3, 5, 5, -1, -1},
{3, 3, 5, 5, -1, -1},
{3, 3, 5, 5, -1, -1},
{3, 3, 5, 5, -1, -1},
{-1, -2, -2, -2, -2, -2}};
int parse_number(const char* input, const char** rest) {
int state = 0, result = 0;
while (1) {
int ch = *input;
// 数値でないものは仮に 10 として扱う
ch = (ch >= '0' && ch <= '9') ? ch - '0' : 10;
state = state_tranition[ch][state];
if (state < 0) break;
result = result * 10 + ch;
input++;
}
*rest = input;
return state == -2 ? result : -1;
}
_Bool parse_address(const char* input, unsigned char result[static 4]) {
const char* rest = input;
for (int i = 0;; ++i) {
int r = parse_number(rest, &rest);
if (r == -1) return 0;
result[i] = r;
if (i == 3) {
if (*rest != '\0') return 0;
break;
}
if (*rest != '.') return 0;
++rest;
}
return 1;
}
testcase.c
#include <assert.h>
#include "address_parse.h"
int main(void) {
const char* rest;
// 正常ケース
const char* input_string = "16";
int result = parse_number(input_string, &rest);
assert(result == 16);
assert(rest == &input_string[2]);
// エラーケース① 大きすぎる値
input_string = "256";
result = parse_number(input_string, &rest);
assert(result == -1);
assert(rest == &input_string[2]);
// エラーケース② 数値でないもの
input_string = "abc";
result = parse_number(input_string, &rest);
assert(result == -1);
assert(rest == input_string);
// エラーケース③ 余計な冒頭のゼロ
input_string = "01";
result = parse_number(input_string, &rest);
assert(result == -1);
assert(rest == &input_string[1]);
// IP アドレスの構文解析
unsigned char result_address[4];
result = parse_address("123.45.67.8", result_address);
assert(result == 1);
assert(result_address[0] == 123);
assert(result_address[1] == 45);
assert(result_address[2] == 67);
assert(result_address[3] == 8);
}
makefile
UNAME = $(shell uname -s)
EXE =
ifneq (,$(findstring MINGW, $(UNAME)))
EXE=.exe
endif
testcase$(EXE) : testcase.o address_parse.o
$(CC) $^ -o $@
%.o : %.c
$(CC) -c $< -o $@
address_parse.o : address_parse.c address_parse.h
testcase.o : testcase.c address_parse.h
check : testcase$(EXE)
./$<
clean :
rm -rf testcase$(EXE) address_parse.o testcase.o
まとめ
最終的に出来上がったプログラムはそこそこ簡潔なのですが、たぶんプログラムだけを見ても何をやっているのかよくわからないと思います。 構文図・状態遷移図を含めて考え方は文書化して残しておくのが望ましいでしょう。