Treasure Data
2011年 日本人が米国で創業
2018年 ソフトバンク傘下のARM社が買収(https://jp.techcrunch.com/2018/08/03/arm-treasure-data/)
どんなサービスを提供しているかというと、百聞は一見にしかずということでこちら。
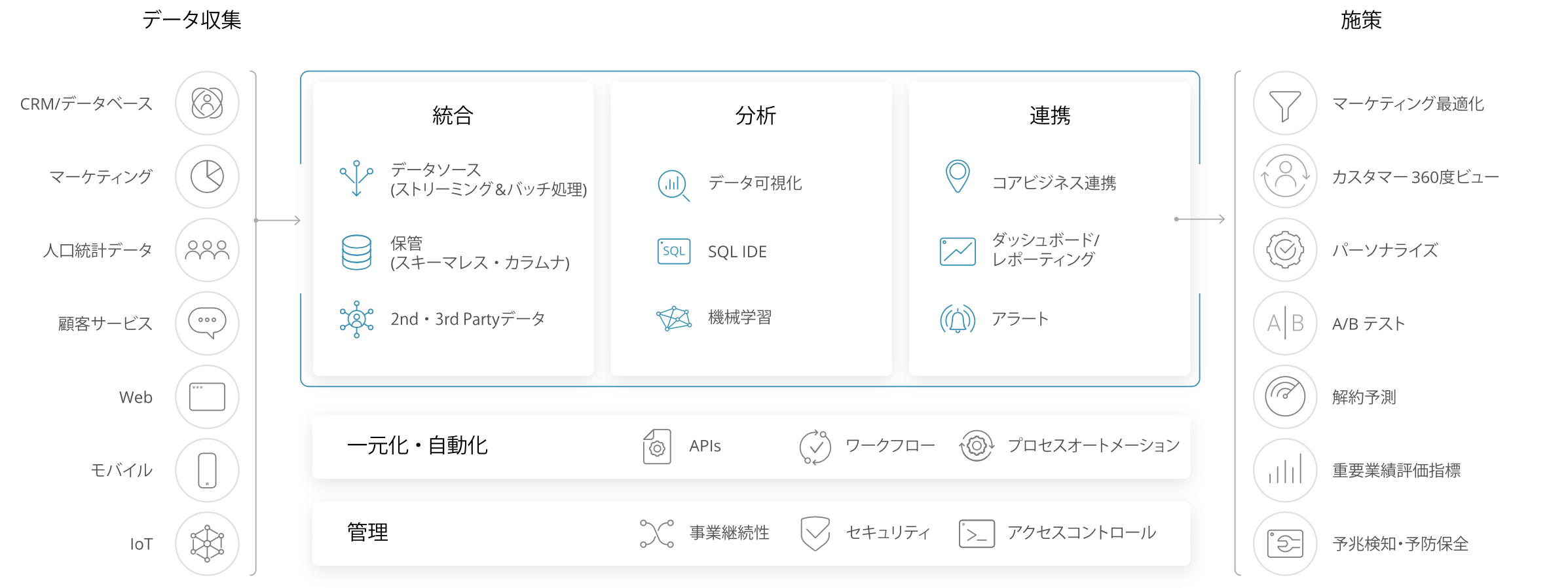
要は、「様々なデータソースをよしなに使いやすく整理して、分析まで実施し、ユーザーへ連携」といったかんじかと思います。
ここでいう機会学習はどこまでできるのか個人的には気になる。
また、通常オンプレミスだと、データ量のピークに合わせて巨大なデータストレージを確保する必要がありました。
その為システム投資や運用費が必要になります。
一方Treasure Dataはクラウドを使用している為、必要な分だけ使用する為、そういった投資や運用コストが不要になります。
Treasure DataとHadoop
概要
Treasure DataはHadoopも一部に使いつつ、Hadoopでの問題点を解決してトータルで使いやすくしたサービス
https://qiita.com/Lewuathe/items/95961787a151ba4d1ae2
Hadoopは大量のデータを扱うにあたって、分散処理を可能にしデータ分析をより身近なものにした画期的発明でした。
しかし、それでもやはりHadoopにも問題点はありました。そこでHadoopの利便性を向上させより使いやすくしたのがTreasure Data Serviceです。
Treasure Data特徴
(引用元 https://sios.jp/products/bigdata/treasuredata/hadoop-treasuredata-04.html)
| 内容 | Hadoop | Treasure Data |
|---|---|---|
| 処理速度 | データを参照する場合には一旦全データを呼び出すため処理速度が遅くなってしまうという問題を抱えています。 | 「カラムナ×タイムインデックス」という独自技術を採用。通常の「Apache Hadoop」とは異なり必要なファイルのみを呼び出すため、高速でのデータ参照が可能です。 |
| インターフェース | HDFSやMapReduceといった独自のインターフェースに慣れる必要があります。そしてHDFSやMapReduceの取り扱いに慣れるまでには、相応の時間を要することとなります。 | HDFSではなくAmazon Simple Storage Service(Amazon S3)を利用してストレージを実装。また計算処理機能については、Amazon Elastic Compute Cloud (Amazon EC2)を活用しています。そして「Treasure Data Service」は、さまざまなインターフェースも装備。そのためデータベースへの接続、データマートとの連携、CSV形式やTSV形式でのエクスポートなどを容易に行うことが可能です。そのため通常の「Apache Hadoop」を導入した場合と比べて、ユーザーは短時間で必要な機能を利用できるようになります。 |
| クエリー | - | 多くのエンジニアに親しまれているSQLスタイルのクエリーインターフェースが提供されます。そしてSQLスタイルのクエリー文はシステム上でMapReduce形式に変換され、並列処理を実行。そのためユーザーは、たとえプログラミングスキルを有していなくとも「Apache Hadoop」を利用することができるのです。 |
| データ・コレクター | - | データ・コレクターである「Treasure Agent」を搭載。この「Treasure Agent」のおかげで、ユーザーはデータベースの構造やデータの格納形式を設計することなくデータを投入することができます。具体的には「Treasure Agent」を利用して、ストリーミングでログ収集を行う場合には、ユーザーのアクションから分析を開始するまでに必要な時間は約5分程度であり、短時間で処理することが可能です。(※また、この処理方法が適さない場合においても、「Embulk」というバッチ処理専用のツールを利用することで、同様のログ収集を行うことが可能となります。) |
| オンプレ/クラウド | 「Apache Hadoop」をオンプレミスで導入する場合、サーバ環境の構築やシステム設定などにかなりの時間がかかります。したがって「Apache Hadoop」を導入して、実際にビッグデータの分析などを開始できるまでには通常半年から1年程度はかかってしまうと言われているのです。 | Treasure Data Service」はクラウド型の統合サービス。そのため「Apache Hadoop」と同等の分散処理環境を、クラウド環境によって利用することが可能です。したがって、わずか数日程度でビッグデータ分析を開始することができます。 |
| スケールアウト | オンプレミス型サービスのひとつとして「Apache Hadoop」を利用する場合にはシステム停止が懸念されるため、安易にスケールアウトを行うことはできません。 | クラウド環境で実現される「Treasure Data Service」であれば、無停止でスケールアウトを実現することができます。そのためシステムを稼働させたまま、データ量に応じた適切な環境を常に維持することができます。 |
追記
ここでいう機会学習はどこまでできるのか個人的には気になる。
上記について少し調べたので追記。
[Hivemall]
https://www.treasuredata.co.jp/press_release_jp/20160218_hivemall_machine_learning/
https://qiita.com/onunu/items/69beeed32a8e852674f0
https://dev.classmethod.jp/hadoop/hadoop-advent-calendar-10-introduction-hivemall/
Open source
https://www.treasuredata.co.jp/opensource/
ML
https://support.treasuredata.com/hc/en-us/categories/360001001934-Machine-Learning
Introduction TD ML
https://support.treasuredata.com/hc/en-us/articles/360011818033-Introduction-to-Treasure-Machine-Learning