トレノケート株式会社という人材育成専門企業のマーケティング部に所属するSatoです。
AWS認定トレーニング(AWS研修)のPR兼広報担当になって、はや1年。
深刻化する日本のIT人材不足に対し「エンジニアの本音を社会に広めたい」、「AWSをもっと盛り上げたい!!」という一心で、先月から#トレノケートAWS川柳大賞という川柳企画を始めました。
本記事では、その企画で活用したAWSの集計処理についてご紹介します。
「#トレノケートAWS川柳大賞」大反響!!とその裏でよぎる一抹の不安……
1月28日から募集を開始したこの企画は、社内外含めたくさんの方にご支援をいただいています。
最大3万円のAmazonギフトカードが当たるということもあり、大反響です。
WebとXから応募をいただく中で、Xについては目視できないほどの応募(ポスト)が……!
本当に嬉しい限りです。
そして、とっても面白いです(笑)
AWSのPR兼広報担当2年目のひよっこの私にとって、正直AWSのテクニカルな部分は分からないことも多いですが(おい)、川柳の頭文字をAWSと絡めたり、AWSのバージニアリージョンが登場したり、サラリーマン川柳ばりにAWSの抱負やあるある川柳をたくさんのエンジニアの皆様が考え、投稿してくださいます。
そして、毎日のX投稿に「いいね」をしながら、ふと頭をよぎる不安。
集計処理どうしよう……
膨大なテキスト情報の集計。そして分類
そうです。集計作業が膨大でとても手作業では対応しきれないことに気づいたんです。
応募〆切は2月28日、翌3月には、結果発表が控えています。このままでは集計が間に合いません。
色々な集計ツールを探す中で、私は「もしかしたら、AWSを使って何かできるかもしれない」と考えました。
そこで普段から、大変お世話になっているAWS認定講師の髙山さんに相談をさせていただきました。
社内ではMr.Botの異名を持ち、何事にもBe Speedyな方です。
ご相談をしたところ、秒で案をいただき、当日中に準備、翌日には処理可能な基盤ができていました。(はやい、早すぎる……)

前置きが長くなりましたが、下記では、髙山さんより実際に行っていただいたAWSの処理を伺いました。
原文ままです。どうぞご確認ください!
集計作業を助けるAWSの分析処理
X に投稿された川柳について、頻出キーワードを分析したいという要望がマーケティングから上がってきました。X から検索して人が分類するのは無茶なので、テキストマイニングする仕組みを AWS で準備しました。リアルな現場の声ですね。
キーワード分析基盤
大層なタイトルを掲げましたが、なんてことないテキストを Amazon Comprehend に読み込ませてキーワード抽出をする仕組みを作りました。

Amazon Comprehend は、日本語に対応したテキストマイニング処理ができる AI サービスです。文脈からキーフレーズを抽出したり、感情分析をおこなうことができます。
Amazon Comprehend(テキストのインサイトや関係性を検出)| AWS
今回は、川柳なので感情分析するには情報量が足りないので難しいですが、キーフレーズ抽出を利用できれば頻出キーワードを抜き出すのはお茶の子さいさいです。
データの抽出
弊社マーケティング担当より、 X から 「#AWS 川柳」の投稿を抽出した CSV データを貰いました。

中身を見てみると、X の投稿データなので、投稿本体以外にも様々なデータ項目があります。なんなら、改行もそのまま入っている CSV データです。厄介ですね。
あきらかに本企画の趣旨と違う内容だったり、中には短歌もあったりしました。重複データもありますね。
これではまともな分析ができないので、データのクレンジングが必要です。
データクレンジング
今回のデータは、実際のデータを見ながらデータのクレンジングと加工をやるほうが効率が良さそうです。こういった場面では、AWS Glue DataBrew が活躍します。
ビジュアルデータ準備 - AWS Glue DataBrew - AWS
具体的なレシピについては、いずれ弊社のブログで紹介しますが、以下のような処理を用意したら最適なデータになりました。
- 不要な項目の削除
- URL の除去
- 文字列によるデータのフィルタリング(川柳っぽい文字列)
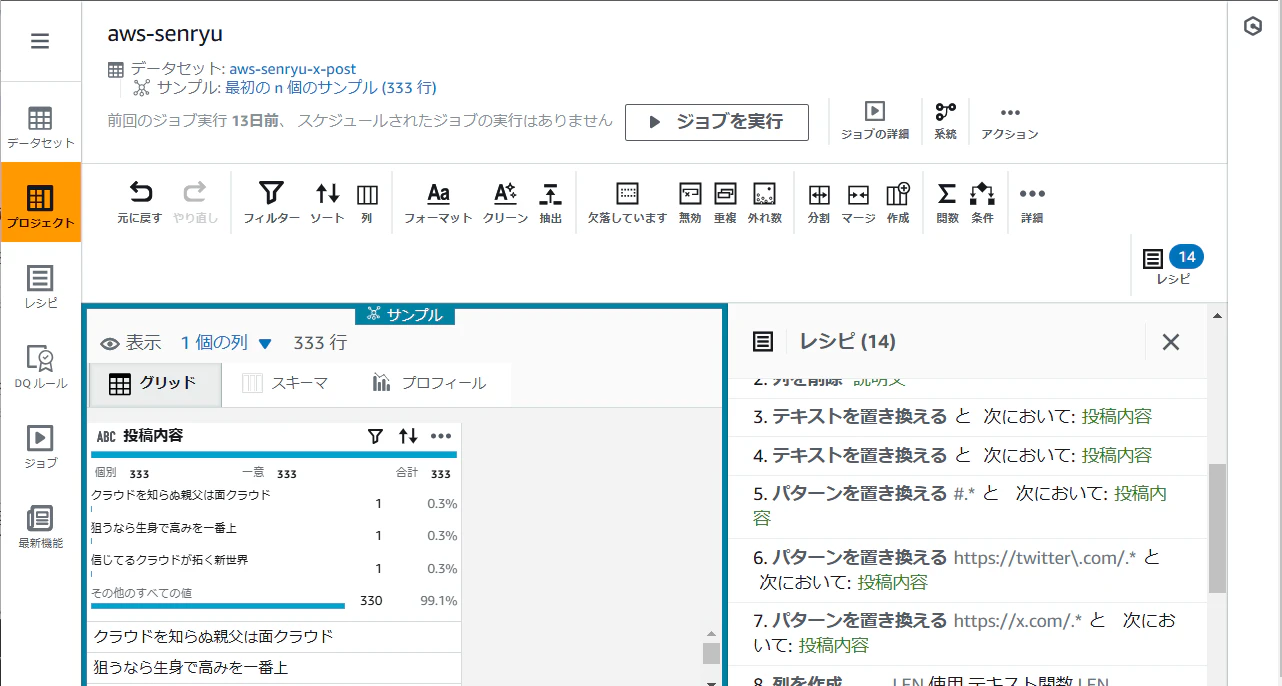
作成したものは、ジョブとして定義されるので、S3 バケットに生データを用意して、ジョブを実行します。
これで、川柳っぽいものだけが抽出できます。
キーワード抽出
今回は、AWS Lambda から Amazon Comprehend を呼び出してキーワードを抜き出し、キーワードごとにカウントをしていくロジックを用意しました。
import json
import os
import logging
import boto3
import unicodedata
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
# Get S3 bucket name from environment variable
bucket_name = os.environ['S3_BUCKET_NAME']
# Get S3 prefix from environment variable
prefix = os.environ['S3_PREFIX']
# Get S3 report prefix from environment variable
report_prefix = os.environ['S3_REPORT_PREFIX']
# Create S3 client
s3_client = boto3.client('s3')
# Create Comprehend client
comprehend_client = boto3.client('comprehend')
# Get list of objects in S3 bucket with given prefix
response = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
# Get list of objects
objects = response['Contents']
# Initialize dictionary to store key phrases and count
results = {}
# Initialize to sentence array
sentences = []
# Loop through objects and add keys to list
for key in objects:
logger.info(f"Object: {key['Key']}")
# Get object from S3
obj = s3_client.get_object(Bucket=bucket_name, Key=key['Key'])
# Read object content
content = obj['Body'].read().decode('utf-8')
# Parse file as csv
rows = content.split('\n')
# Loop through rows and add to list
skipped = False
for row in rows:
if not skipped:
skipped = True
continue
if row == '':
continue
# Detect key phrases using comprehend each fifteen sentences
if len(sentences) == 15:
logger.info(f"Sentences: {sentences}")
# Detect key phrases using comprehend
key_phrases = comprehend_client.batch_detect_key_phrases(TextList=sentences, LanguageCode='ja')
# Loop through key phrases and add to dictionary
for result in key_phrases['ResultList']:
# Get key phrases data
phrases = result['KeyPhrases']
# Loop through key phrases and add to dictionary
logger.info(phrases)
for key_phrase in phrases:
# Get key phrase data
phrase = key_phrase['Text']
# Normalize key phrase
phrase = unicodedata.normalize('NFKC', phrase)
# Add key phrase to dictionary
if phrase in results:
results[phrase] += 1
else:
results[phrase] = 1
# Reset sentence array
sentences = []
else:
# Add sentence to array
sentences.append(row)
# Make a csv file from key phrases and count
csv = 'key_phrase,count\n'
for p, count in results.items():
csv += p + ',' + str(count) + '\n'
# Convert utf-8 to cp932
csv = csv.encode('cp932', 'ignore')
# Write csv file to S3
s3_client.put_object(Bucket=bucket_name, Key=f'{report_prefix}/key_phrases.csv', Body=csv)
return {
'statusCode': 200,
'body': json.dumps('Key phrases written to S3')
}
ちなみにこのコードは、ほぼほぼ Amazon Q Developer に作ってもらいました。
生データが用意されてから、ETLジョブの作成、キーワード抽出まで、実際にはかかった時間は、正味3時間くらいです。クラウド最高です。
川柳の集計もAWS認定資格の取得も頑張ります
ということで、クラウド最高、AWS最強です。
来月は、作っていただいたAWS分析処理を活用しながら、集計作業を頑張っていきます。
気づけば、AWSPR担当も2年目突入です。今年の目標はAWS 認定クラウドプラクティショナーへの申し込みと資格取得。
2025年中の取得を目指し、粛々と勉強頑張ります。
最後に、この場を借りて御礼を。
やりたいと思えることやっていいよと背中を押してくれ、そしてそのチャレンジを全力で応援しサポートしてくれる会社と同僚には本当に感謝してもしきれません。
また、今回の川柳企画は、AWSを盛り上げたいという想いに賛同いただいたたくさんのAWS関係者の皆様に審査という形でご支援いただき、多方面でのAWS愛を感じることができています。本当にありがとうございます。
私個人としては、まさか、本企画の実施許可をAWSジャパンより二つ返事でのご快諾いただけるとは思ってもみませんでしたし、AWSジャパンのトレーニング本部長 岩田様にも審査員としてご参画いただけるなんて……!
AWSの俊敏性(アジリティ)な姿勢は、こんなところにも垣間見えました。
本記事でご紹介したAWS川柳企画について、詳細はこちらよりご確認ください。