手元に記事保存のログがたくさんあったので、知識皆無のところからがんばってみました。
結論から言うと付け焼き刃では難しいです。
以下全部Python
最終目的
実用に耐えうるレコメンド(「おすすめの記事はこれ!」)をやる。
今回使用するデータ
- 誰(user_id)が
- いつ(いわゆる
%Y-%m-%d %H:%M:%S %zの形) - どの記事(article_id)を保存したか
が36088497件。ユーザの数は410401人、記事は1272699本くらい。時間でいったら5年分くらい貯まっている。
各ユーザの性別や年齢、どのカテゴリ/キーワードに興味があるか、記事がどういう内容なのかといった情報は今回使わない方針で行く。
注意点は、
- 「保存していない」と「そもそも読んですらいない」の区別がつかない
- ユーザからのレート(1〜5とかで評価するやつ)はない
- 映画とか売り物の商品とかと比較して、時間経過で推薦する価値がすぐ下がる
よくあるレコメンドの例題では1〜5でレーティングされていて、下手すると学習データセット内では全アイテムにレートの値が存在していたりする。例題のデータは理想的すぎなのでは。
時間や日の単位で状況が変わるので、なるべく早く手軽に計算してレコメンドに反映させるか、長く使い回せるような形での運用が望ましい。
後述の全ての処理において(というか行列生成の段階で既に)メモリ16GBが耐えきれず3600万件全て使えなかった。
約20日分に絞ると、783407件/107573人/34585本でユーザ数 > 記事数になった。これでもまだ耐えられなくて、1/3に減らしたり5日分にしたり……。
Spotifyは20M曲24M人をさばいているらしい。
Algorithmic Music Recommendations at Spotify
使用するライブラリについて
言語にpythonを採用したため、ライブラリはnumpy、scipy、pandas、scikit-learn等を使用した。
pandasはRと同じことをやるのに便利(参考: Comparison with R / R libraries — pandas 0.18.1 documentation)だが、非常に遅い。一時的にpandas.DataFrameからnumpy.ndarrayを取り出して処理するだけでも大きく改善する。
pandas.DataFrameで計算をやってしまうとかなり遅いが、データを保持する分には負担にならないので、ファイルから読んだり表を持っておいたりする手段としてはアリ。
DaskというNumPyやDataFrameを並列処理するパッケージもある。
いろいろやる前のデータ処理
生データが user_id\t%Y-%m-%d %H:%M:%S %z\tarticle_id\n の状態なので、インデックスにuser_idを、カラムにarticle_idを持つ行列に変換する。
今回扱う題材の場合、スパース行列となるので、scipy.sparseでちまちま表を作った方が良い。最初は入門機械学習にあったreshapeのcastにならってpandasのpivotを使ったが、さすがにしんどい。
Pythonの疎行列ライブラリscipy.sparseの基本 – はむかず!
いろいろやってみる
クラスタリング
巷のクラスタリングの例題はたいてい検出や分類を題材にしている。つまり正解ラベルが存在する。
今回は正解も何もないので、K-means法で分類してもらう。
分類するだけならさておき、数万かける数万のサイズの行列を2次元や3次元のグラフにプロットするには次元削減が必要である。
PCA
scikit-learnでPCAをする。sklearn.decomposition.PCAはメモリをもりもり食べるので、2016年8月1日〜20日の更に1/3だけ使った。
青クラスタが22319人、緑クラスタが932人、シアンクラスタが124人というありさま。
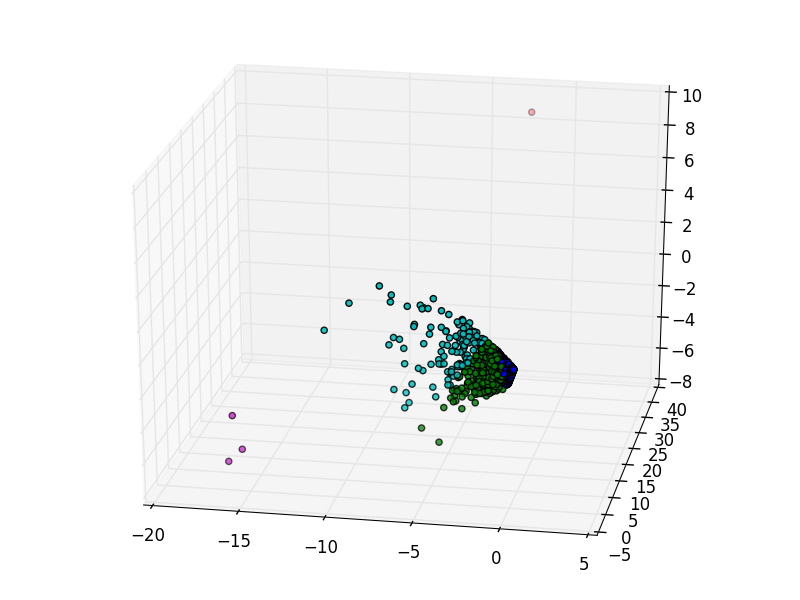
これではあんまりなので、
高次元データの可視化の手法をSwiss rollを例に見てみよう | ALBERT Official Blog
で紹介されている手法を試してみる。
KPCA
KPCAはPCAを改良したものらしい。KはKernelのKで、いろいろなカーネル関数を試すことができ、さらにパラメータが存在してチューニングが大変。一応scikit-learnに頼めないこともない。
関東CV勉強会 Kernel PCA (2011.2.19)
Scikit learnより グリッドサーチによるパラメータ最適化
sklearn.decomposition.KPCAはPCAと比べてメモリもりもり食べないし、CPUも750%とか使ってくれるので早い。でも3600万件までくるとメモリが耐えられない。
まずはkernel=rbfをやったあと5クラスタに分けてみる、が変わらず。
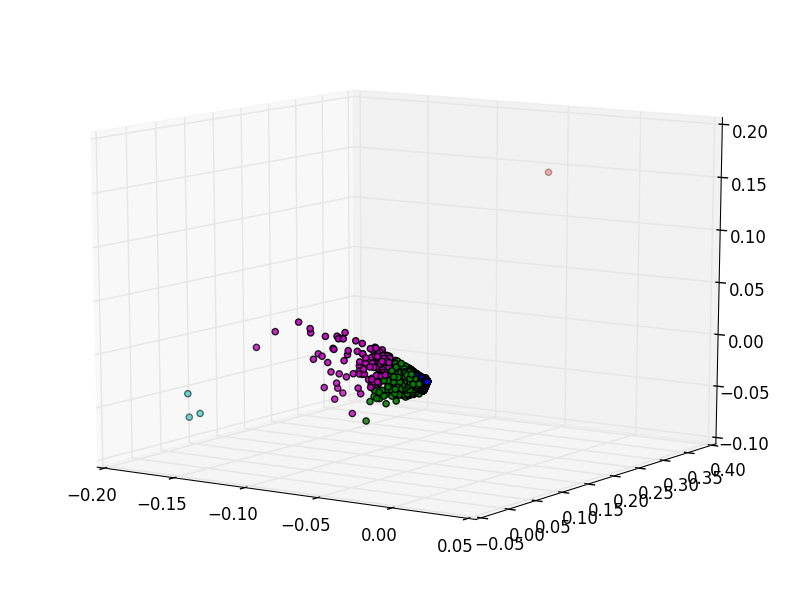
kernel=cosineでやったら__見た目は__うまく行った。
青: 22302、緑: 251、赤: 274、シアン: 426、マゼンタ: 126
結局中央にほとんどが集中しているので数としては全然ばらけていない。
Isomap
Isomap+K-meansをやってみる。
pythonでのやり方: Scikit-learnでIsomap
が、並列でやってくれないのかいつまでもCPU使用率100%で計算が終わらないのであきらめた。かといってメモリを使っている様子もない、何をやっているんだろう……。
レコメンド
巷にあふれている分類検出認識と違って明確な正解ラベルが存在しないので、性能評価は今回はなし。
一応評価のやり方については論文がいくつか出ている。評価に使うメトリクスはRMSEやPrecision&Recallなどよくあるやつとして、テストデータの切り出し方やハイパパラメータの選び方の方が問題っぽい。
An evaluation Methodology for Collaborative Recommender Systems
A Survey of Accuracy Evaluation Metrics of Recommendation Tasks
Deep Learningのハイパパラメータの調整
ベイズ最適化入門
How to divide dataset into training and test set in Recommender Systems?
How to split train/test of extreme sparse dataset of recommender system?
How to measure and evaluate the quality of recommendation engines - Quora
判別させる方のチューニングの話も
いまさら聞けないDeep Learning超入門(終):深層学習の判別精度を向上させるコツとActive Learning (1/2)
機械学習してみる
記事の特徴を使わないとなるとコンテンツベースでレコメンドはできないので、協調フィルタリングを試してみる。
Mahoutを試し忘れてた。
アイテムベース協調フィルタリング
入門機械学習に載っていたk近傍法利用のアイテムベースの協調フィルタイングを真似る(R→Python+pandasへの移植)だけでもレコメンドは完成する。この本に載っていたのはRのライブラリを推薦するというシナリオ。使ったか使ってないかの2値で、今回考える保存記事とかたちは似ている。とりあえずレコメンドしたいならこれだけでOK。何かしらの値は出る。
pandas.DataFrame.apply や pandas.DataFrame.applymap は非常に遅くなるので、 numpy.ndarray でmapする。
ハイブリッド協調フィルタリング
アイテムベース協調フィルタリングに何かもう1つ合わせてみる。
試しに"A hybrid collaborative filtering method for multiple-interests and multiple-content recommendation in E-Commerce"という論文のアルゴリズムで実装してみた。これはアイテムベースにユーザベースも足すというもの。
コンテンツベースとのハイブリッドだとかユーザが事前に登録したキーワードを使うものだとか、レコメンドに使えるデータの種類が豊富なら試せるものは多い。
k近傍のkの数ぶん記事やユーザが集まらない問題も起きて正直駄目だった。
datasketchのMinHash LSHでハッシュ値をうまく使うなどするとかなり軽くできる。
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
ディープラーニングしてみる
知識が足りないのでろくにチューニングもできない。
TensorFlow
TensorFlowでもできると思うんだけどみんな画像認識ばかりしててどうしたら良いかわからない。
tensorboardで見れたら面白かった。
Amazon DSSTNE
相変わらずチューニング対象の項目が多すぎるとはいえ、今回のデータセットと同じ状況のレコメンドを意識したものなので、サンプルの設定をそのまま使い回せばレコメンド結果を得られる。
環境構築の方法については、Amazonがオープンソースで公開したディープラーニングのライブラリ「DSSTNE」を使ってみるや公式リポジトリのsetupに書かれている。ただし、g2.2xlarge+DSSTNE用AMIでやったら以下の点に引っかかった。
- Amazon製のAMIだが実態はUbuntuなのでユーザ名はubuntu。
- Amazon DSSTNEの
makeで2度こけた。- NVIDIA cuDNNはNVIDIAに登録しないと使えなくなったので、ユーザ登録して持ってくる必要がある。CUDAのバージョンに合ったバージョンのものを持ってくる。
-
compute_60が駄目と言われて止まったので、Makefile.inc中の-gencode arch=compute_60,code=sm_60を消してごまかす。
あとはマニュアルにある通り。
サンプルにあるmovie lensのデータ(約310MB)と当方のデータセット(5日分の保存ログから約1/5だけ使用、約4.4GB)を同設定でまわして実行時間を比べたところ、
| データセット | generate input data | generate output data | train | predict |
|---|---|---|---|---|
| movie lens | 0m33.970s | 0m33.436s | 1m32.081s | 1m37.684s |
| 記事保存 | 2m46.042s | 2m48.913s | 0m11.721s | 6m26.139s |
とだいぶ増していた。4.4GBのファイルを読み込む分があるので比例してしんどくなる。
同設定で23.5GB(5日分ぜんぶ)を与えたら train の段階で cudaMalloc GpuBuffer::Allocate failed out of memory された。
出力されるファイルのサイズは全部合わせても元のファイルほどにはならないっぽい。
設定については長くなるから別記事にまとめます。
http://qiita.com/S_Shimotori/items/0a983c81f766c22bebf1
まとめ
しっかり勉強しよう