はじめに
ゼロから作るDeep Learning1を読んで、MNISTの手書き文字を認識するニューラルネットワークを作りました(長いのでコードは省略)。
本の通り、誤差逆伝播法で損失関数の勾配を算出し、Wやbを更新していくものです。
GitHub上にソースコードがありますが、極力コピペせずに本を読みながら自分でコードを書くようにしました。とはいえ、構成はGitHubのものとほぼ同じです。ソフトマックスやクロスエントロピー関数、シグモイド関数などをを関数として作成、レイヤーやネットワークをクラスとして作成しています。
(パラメータの更新にはAdamを使うなどちょっと変えていますが)
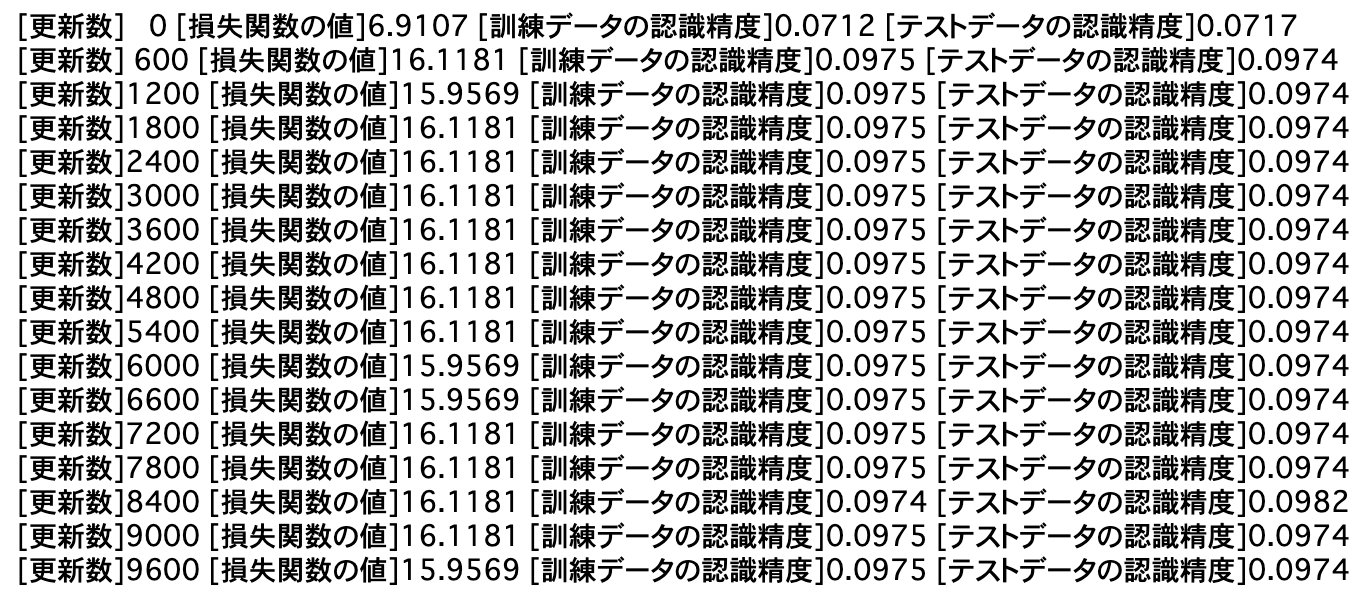
結果↓ (こちら2の記事のコードを使って出力しています)
勾配確認↓

認識精度10%なので当てずっぽうレベル。勾配もあってない。予測できない。
原因追求でやったこと
・手動で順伝播、逆伝播(行列計算)をして、ニューラルネットワークの結果と照合する
⇨手動の結果とニューラルネットワークの結果は一致。ニューラルネットワーク関連(レイヤの実装など)に問題はなさそう。
・ニューラルネットワーク内部で使用している関数(ソフトマックス、交差エントロピー、シグモイド、relu)を確認する
⇨それぞれ簡単なarrayを入れて計算しても変なところは見当たらず。
そこで本のGitHubからこれらの関数をコピペして学習させてみた。ソフトマックスを入れ替えてみたところ↓

こいつだ・・・・・・
どこがいけなかったか
↓ソフトマックス容疑者
def softmax(x):
c = np.max(x)
return np.exp(x - c) / np.sum(np.exp(x - c))
↓正しいソフトマックス(本のGitHubからコピペ)
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x))
バッチ(サンプル数が2以上の時)ではソフトマックス関数の分母が各サンプルの指数関数の和ではなく、全サンプルの指数関数の和になっていました。これが原因でした。
(ソフトマックス関数の動作検証をした時は1次元のarrayを入れていたので気づかなかったのが悪い)
参考文献
[1]斎藤康毅著 ゼロから作るDeep Learning
本のGitHub:https://github.com/oreilly-japan/deep-learning-from-scratch
[2]ゼロから作るDeep Learningで素人がつまずいたことメモ:4章
https://qiita.com/segavvy/items/bdad9fcda2f0da918e7c