1. はじめに
現在、ポートフォリオ作成として、記事投稿サービスのようなものを開発中であり、その1機能として画面に日間/週間/月間等のランキングを表示する機能(以降、ランキング表示機能と記す)を作成している。
そのランキング表示機能を作成するために行ったテーブル設計+αの内容を本記事に記す。
今後同様な機能を開発する機会があろう未来の自身のため、あるいはこれから似たような機能を作る方のためになるかもしれないと思い、思考過程を文書化する目的で本記事を執筆している。
※なお、投稿主は学生時代から情報分野を専攻して知識は持っているものの、学生時代はDBを使わないJavaアプリだったり、就職後の実務ではDBを扱った機能の設計も開発もこれまで行ったことがない(という一種の闇を背負ってしまった)ため、まともにテーブル設計するのは実は今回が初めてです。ご意見ご指摘等あれば頂けると幸いです。またQiita初投稿ですのでご容赦を。
2. 前提:ランキング表示機能概要
前提として、ランキング表示機能は、日間/週間/月間/総合/トレンドの5項目のランキングを表示するものとする。各ランキングは以下により決定する。
| 種類 | 評価基準 |
|---|---|
| 日間ランキング | 1日の「いいね数」の合計 |
| 週間ランキング | 1週間(7日間)の「いいね数」の合計 |
| 月間ランキング | 1ヶ月(30日間)の「いいね数」の合計 |
| 総合ランキング | 全期間の「いいね数」の合計 |
| トレンドランキング | 1日の「いいね数」&1日の「アクセス数」で評価した結果 |
ランキングは常に最新の状態を表示する必要性は薄いと考えられるため、集計は一定期間に1回行う方針としても良いとする。
※蛇足だが、使用言語等は以下を使用する。
・ プログラミング言語:Java
・ フレームワーク:Spring Framework
・ DB:Postgresql
3. テーブル設計
本章では、ランキング表示機能のためのテーブル設計の思考過程を記していく。
以降「いいね数」「アクセス数」は、まとめて「カウントデータ」と記す。
3.1. まずはシンプルなものを考えてみる
最初から性能面等を気にすると思考が複雑化するので一旦考えない。何事もシンプルで済むならそれに越したことはないため、まずはテーブルをシンプルに済ませることはできないかを考えた。
何を考えたかというと、機能概要からカウントデータに関連するものは以下がテーブルで持つ候補になると考えられるが、そのうち1週間/1ヶ月/全期間の各カウントデータが本当に必要かということ。
・1日のカウントデータ
・1週間のカウントデータ
・1ヶ月のカウントデータ
・全期間のカウントデータ
1週間/1ヶ月/全期間のカウントデータを集計するために必要なデータの最小単位は1日のカウントデータである。そのため、日にちごとのカウントデータさえ記録すれば、プログラム側で各期間のカウントデータを求めることは可能である。
この考えに基づけば、以下のようなテーブルで機能自体は実現できる。
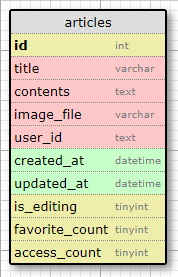
図1. 記事テーブル
※記事投稿サービスとしては他にも必要なテーブルはあるが、本記事ではランキング表示機能に関わるものに限定する
3.2. 性能面も考慮に入れて考えていく
図1のテーブルのデータのうち以下2つの独立性の高いユースケースに分かれる。
| データ種類 | データを扱う局面 | 更新契機 |
|---|---|---|
| (カウントデータ) | ランキングを表示する | いいねボタン押下/記事ページアクセス時 |
| 上記以外 | 記事ページを表示する | 記事作成/編集時 |
図1のテーブルだと、カウントデータ更新中にカウントデータ以外のデータも一緒に更新不可となるため、図1のテーブルは以下のように分割することで、両者が同時更新可能になる。

図2. カウントデータ分割後のテーブル
以降、図2のテーブルをベースに性能面の検討を進める。
(言うまでもないかもしれないが)図2のテーブルでもまだ性能面に問題がある。大きく以下2点の問題があると考え、各問題点を解消するための設計を考えた。
(問題点1) ページ表示時に毎回ランキング集計 = ランキングの集計演算の時間大
(問題点2) 日々のカウントデータを格納 = レコード数増大によるパフォーマンス劣化
3.2.1. 問題点1:ランキングの集計演算の時間大
日にち毎のカウントデータがあれば、1週間/1ヶ月/全期間のカウントを求めることはできるが、裏を返せばユーザがランキングが表示されるページにアクセスする度に各期間のカウントデータを集計しなければならない。
この問題を解消するためには、1日/1週間/1ヶ月/全期間のカウントデータの集計結果を別テーブルに保持し、ランキング表示時は、そのテーブルを参照するだけで済むようにすればよいと考えた(集計は定期実行処理により一定間隔で行う)。
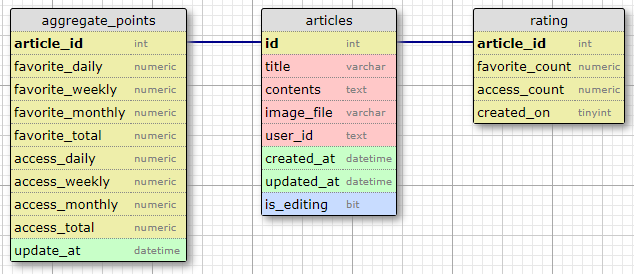
図3. 図2のテーブルにカテゴリデータ集計テーブル追加後
こうすることで、都度集計する必要がなくなる上に、ratingテーブルは日々のカウントデータ追加/更新、aggreagate_pointsテーブルは、(ランキング表示時の)カウントデータの参照というように、役割分担とテーブルアクセスの分散ができる。
3.2.2. 問題点2:レコード数増大によるパフォーマンス劣化
図1のテーブルでは、各記事に対して日にち毎のカウントデータを保持することになるため、投稿記事と稼働日数が増える程にレコード数が指数関数的に増大する一方である。それにより、DBの容量圧迫及びデータ検索速度の低下に繋がる。そのため、レコード数削減のため施策を2つ考えた。
(施策1) 1記事当たり30日分のレコードまでとする
全期間のカウントデータは、日々のカウントデータを加算し続ければ、最新の状態に保てるため、過去30日分のカウントデータまで削減しても問題ない(全期間のカウントデータは図2のように別テーブルを保持する)。
(施策2) 過去30日分のデータを1レコードにまとめる
図1のテーブルで保持するデータを過去30日に削減しても、レコード数=全投稿記事数×30となるため少なくなったとは言えない(投稿記事数が1万件あれば、レコード数は30万になる)。1ヶ月のカウントデータ合計を得るためには、毎回以下のSQLで当該記事のデータ30件を抽出する必要があるため、データが増えるほど検索に時間がかかる。
SELECT * FROM rating WHERE articl_id=[当該記事のid];
であれば、最初から30日分のデータをひとかたまりのデータにすれば、データ30件を抽出する手間を省ける上、レコード数=全投稿記事数に抑えられると考えた。
当日のカウントデータは頻繁に更新されるが、それ以外の過去のカウントデータは、最新データの追加/最古データの削除を行うのみである。そのため、プログラム側でこれらの操作が容易にできる形式で過去30日分をひとまとめにすれば、1レコードのデータとして保存しても問題はない。
DBにはJSONやXMLデータで格納できるものもあり(今回使用するPostgresqlは両方格納可能である)、JSONまたはXMLの方がプログラム側でもデータを扱いやすいため、30日分のデータはJSONまたはXML形式で1レコードに格納することにする。
データ形式をJSONやXMLとすることでパフォーマンスは落ちることが懸念されるが、データに変更を加えるタイミングは、定期実行処理により一定間隔で行うため、全体のパフォーマンスから見れば微々たるものである。

図4. 図2のテーブルにレコード数削減施策適用後
・過去30日分のカウントデータをJSON形式にする場合の例
{
rating_info: [
{
"favorite_count":"12"
"date":"2019-04-17"
},
{
"favorite_count":"15"
"date":"2019-04-16"
},
:(略)
}
・過去30日分のカウントデータをXML形式にする場合の例
<rating_info>
<day_rating>
<favorite_count>12</favorite_count>
<date>2019-04-17</date>
</day_rating>
<day_rating>
<favorite_count>15</favorite_count>
<date>2019-04-16</date>
</day_rating>
</rating_info>
3.3. テーブル最終形
3.2節で考えた結果を組み合わせると、以下のようなテーブルになる。
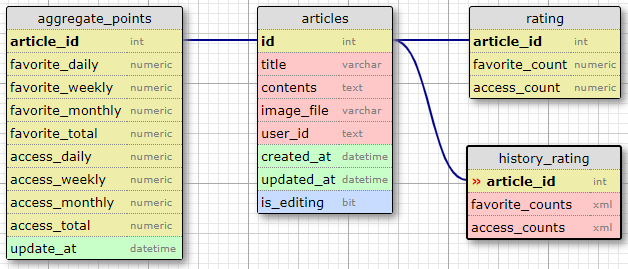
図5. 最終形テーブル
これにより、以下の通りユーザの操作等によってアクセスするテーブルを分けることもできたため、あとはidをキーに各テーブルにインデックスを作成すれば、テーブルへの格納データが多くてもパフォーマンスを保てると考える。
| テーブル | 役割 | テーブル参照契機 | テーブル更新契機 | 参照頻度 | 更新頻度 |
|---|---|---|---|---|---|
| daily_rating | 当日のカウント集計 | 定期実行処理 | 記事ページ表示時/いいねボタン押下 | 1日に1回 (*1) |
高 (*2) |
| history_rating | 過去30日分の履歴格納 | 定期実行処理 | 定期実行処理 | 1日に1回 (*1) |
1日に1回 (*1) |
| aggregate_points | 週間/月間/総合のカウントデータ保持 | ランキングページ表示時 | 定期実行処理 | 高 | 1日に1回 (*1) |
(*1) 定期実行処理を24時間に1回行う場合
(*2) レコードの追加/削除は、記事の追加/削除に依存
4. 定期実行処理(カウントデータの集計)
申し訳程度のプログラミング要素を記す。
今回はJava+Spring Frameworkを使用するが、Spring Frameworkにはタスクを定期実行できる機能があるため、これを使用する。
@Scheduled(cron = "0 0 0 * * *", zone = "Asia/Tokyo")
public void updateAggregateData() {
//...
}
cronオプションには、左から秒(0-59)、分(0-59)、時(0-23)、日(1-31)、月(1-12)、曜日(0:日,1:月,2:火,3:水,4:木,5:金,6:土,7:日)を設定するため、上記ソースのようにすれば、毎日0時0分0秒に定期実行可能となる。
5. 最後に
最後に砕けた文面で適当に綴ります。
書いていて思ったのが、最初の方で1週間/1ヶ月などのカウントデータは、日にち毎のデータから求められるから必要ないのでは?と思って外したのに、性能面を考えると結局必要だという手の平返しして突っ込み要素を作り込んだなと。
1週間/1ヶ月などのカウントデータは、とりあえずテーブルに入れておいて損はなさそうという教訓に。
今回書いた内容は、圧倒的感覚派な投稿主が頭の中で感覚とイメージで考えた内容をちゃんと文書化しようという個人的な目的もあって書きました。
とんでもない間違いを犯してないか確認もとい調べながらとはいえ、これだけ書くのに合計24時間弱かかったため、文書書くの苦手だなと勝手に自身で再確認しました(学生の頃は3年間毎週Wordで6~8ページのこの記事位のガチ資料作成していましたが、全盛期から年月が経ちすぎて当時の感覚残ってないというのも再確認)。アウトプットが課題です。
テーブル設計&DB初心者と言っても過言ではないので、DB設計徹底指南書やSQLアンチパターン等の文献読み進めたりして学ぶことは色々あると思っています。なので、本記事のネタにした記事投稿サービスの開発と、その次に予定しているテーブル数/カラム数多めのサービスの開発通して実践力を付ける&時々ここにも学びをアウトプットしていければと思ってます。
以上
※一応twitterやってます
https://twitter.com/SYM_souten
参考サイト
(1) プライマリキーを使った1:1関連でカラム数の多いテーブルを分割する
(3) WWW SQL Designer ※ER図作成に使用