1. Intel 64 CPU互換レイヤー「Rosetta 2」でサポートする命令等
Intelが出している MacCPUID と言うユーティリティはIntel Macに採用されているCPUの機能などを調べるユーティリティであるが、Rosetta環境で使用すると、ソフト側から見た仮想Intel64ハードウェアの機能を調べることができる。
これが実行したところであるが、ベンダーストリングこそ "VirtualApple" となっているものの、CPUはWestmere世代のプロセッサ互換として認識されている。
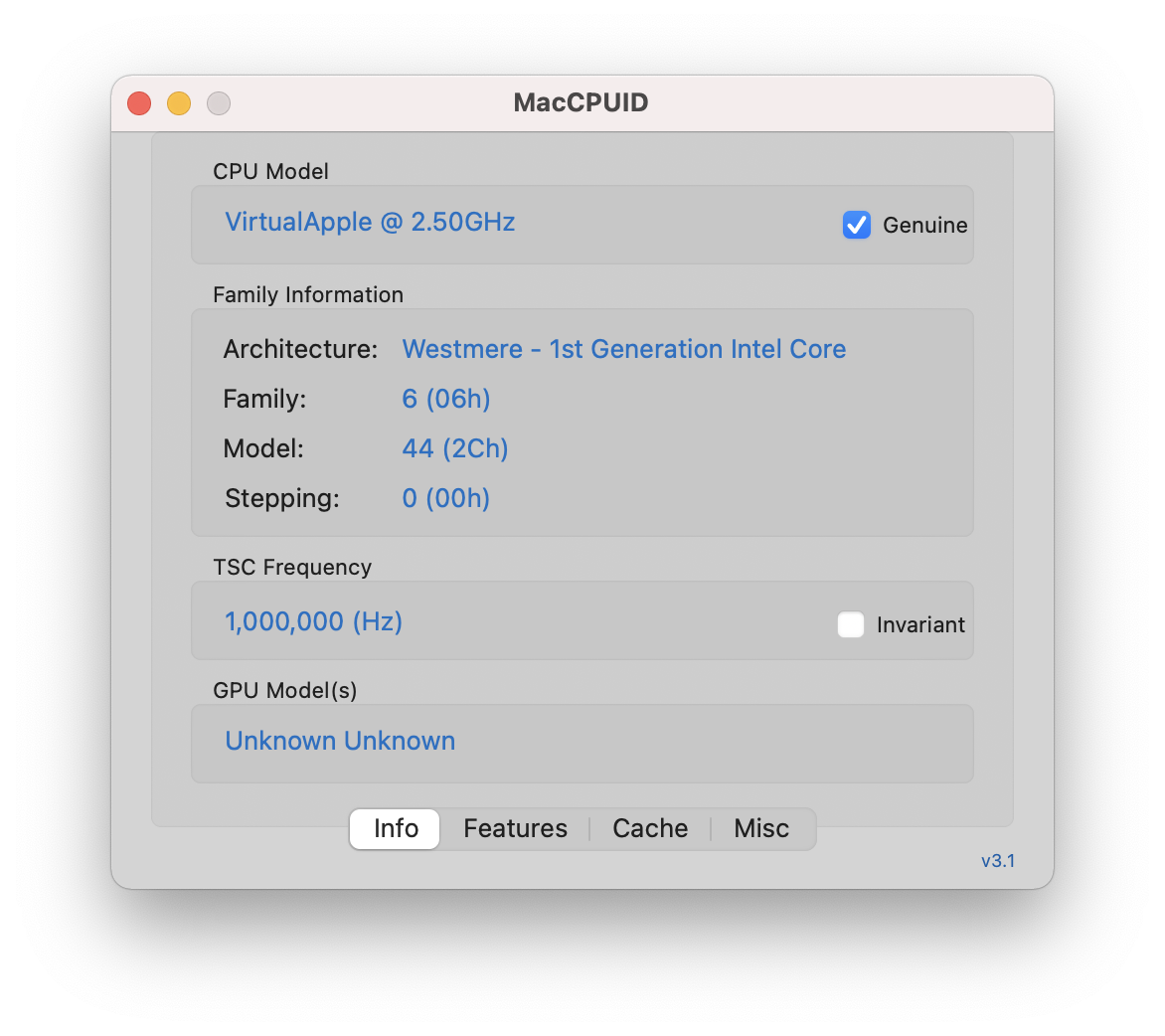
また、CPUの機能はWestmere世代の第1世代(32nm版)Core i*シリーズと同等である。
AESやPCLMULQDQなどはサポートするが、AVX以降の命令はサポートされない。
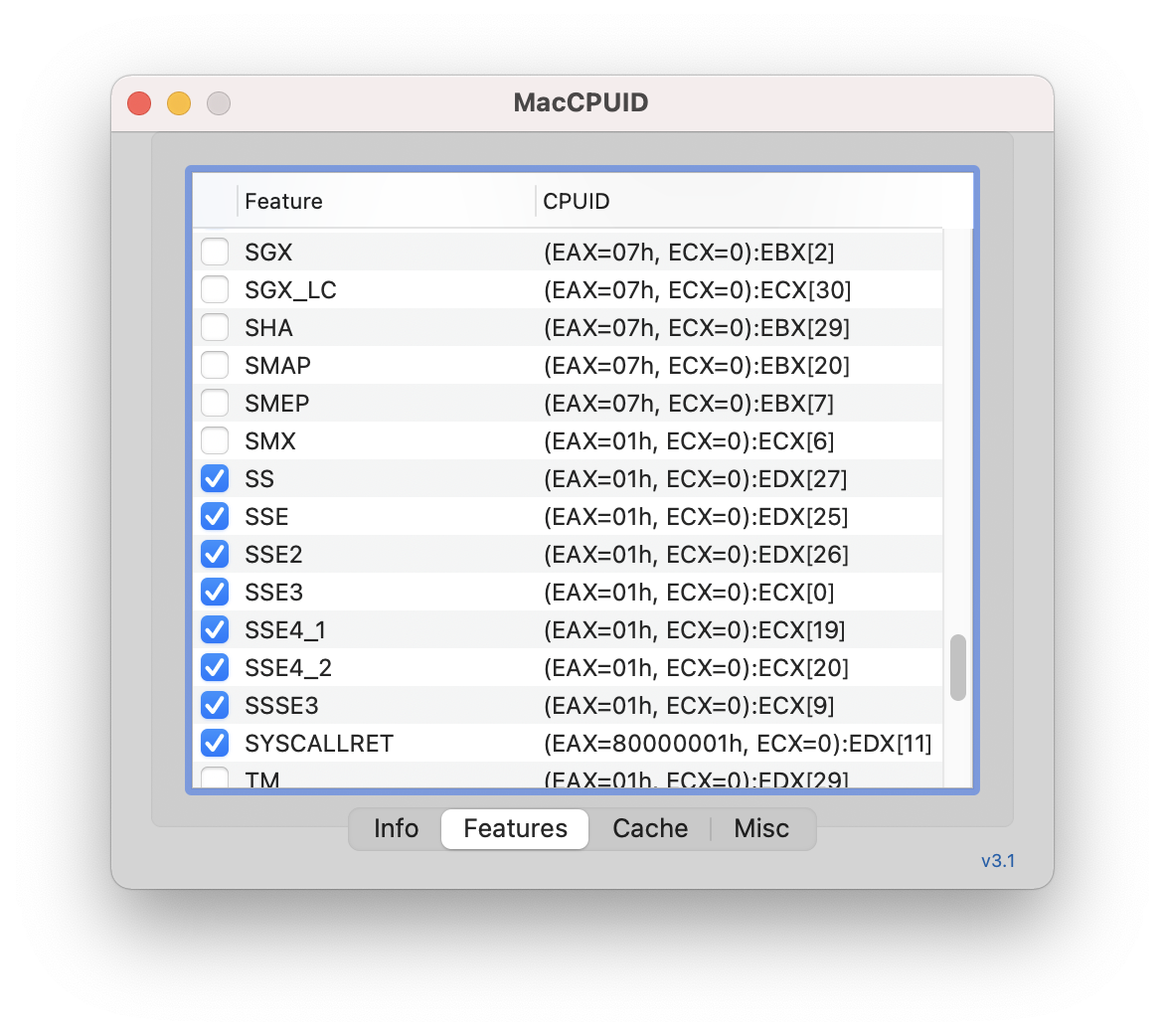
決め打ちでAVXなどの最新の命令を使っている場合は、Rosettaでの動作に注意が必要である。
AVXに対応してないx86-64マシンをエミュレーションしているので、そういうコードは当然エラー吐いて死ぬ。
2. M1ネイティブでサポートする命令
2.1 -march=native は使えません
gcc/clangにおける-march=nativeオプションはコンパイルホストCPUで使える命令を自動的に調べて使える全ての命令の中から選んで最適化してくれるためのオプションである。-O2とか-O3とセットで使うことが多いであろう。
基本的には下記のコマンドを実行すればmarch=nativeで有効化される機能フラグを見ることができるのだが、現行のApple M1向けclangコンパイラは-march=native自体がサポートされていないのでエラーを吐いて失敗する。
% echo | clang -E - -march=native -###
clang: error: the clang compiler does not support '-march=native'
2.2. ネイティブコンパイラでデフォルトで有効になっている命令を調べる
じゃあ何が有効なのか、と言うことで、とりあえず調べてみよう。
最初のM1 Macのコンパイラである以上は最小の命令セットはサポートするはずである。
-march=nativeを外して実行してみよう。
% echo | clang -E - -###
出力は長いので省略するが、Target CPU周りのパラメータを抜粋すると以下の通り。
"-target-cpu" "vortex"
"-target-feature" "+v8.3a"
"-target-feature" "+fp-armv8"
"-target-feature" "+neon"
"-target-feature" "+crc"
"-target-feature" "+crypto"
"-target-feature" "+fullfp16"
"-target-feature" "+ras"
"-target-feature" "+lse"
"-target-feature" "+rdm"
"-target-feature" "+rcpc"
"-target-feature" "+zcm"
"-target-feature" "+zcz"
"-target-feature" "+sha2"
"-target-feature" "+aes"
2.3. M1でサポートする命令を調べる
M1のCPUのスペックなどは sysctl hwコマンドで調べることができる。
% sysctl hw
hw.ncpu: 8
hw.byteorder: 1234
hw.memsize: 17179869184
hw.activecpu: 8
hw.physicalcpu: 8
hw.physicalcpu_max: 8
hw.logicalcpu: 8
hw.logicalcpu_max: 8
hw.cputype: 16777228
hw.cpusubtype: 2
hw.cpu64bit_capable: 1
hw.cpufamily: 458787763
hw.cpusubfamily: 2
hw.cacheconfig: 8 1 1 0 0 0 0 0 0 0
hw.cachesize: 3618652160 65536 4194304 0 0 0 0 0 0 0
hw.pagesize: 16384
hw.pagesize32: 16384
hw.cachelinesize: 128
hw.l1icachesize: 131072
hw.l1dcachesize: 65536
hw.l2cachesize: 4194304
hw.tbfrequency: 24000000
hw.packages: 1
hw.osenvironment:
hw.ephemeral_storage: 0
hw.use_recovery_securityd: 0
hw.use_kernelmanagerd: 1
hw.serialdebugmode: 0
hw.optional.floatingpoint: 1
hw.optional.watchpoint: 4
hw.optional.breakpoint: 6
hw.optional.neon: 1
hw.optional.neon_hpfp: 1
hw.optional.neon_fp16: 1
hw.optional.armv8_1_atomics: 1
hw.optional.armv8_crc32: 1
hw.optional.armv8_2_fhm: 1
hw.optional.armv8_2_sha512: 1
hw.optional.armv8_2_sha3: 1
hw.optional.amx_version: 2
hw.optional.ucnormal_mem: 1
hw.optional.arm64: 1
hw.targettype: J293
うーん、よくわからない。
ここで hw.optional.armv8_2_sha3 のフラグが 1 であることに注目したい。ARMv8.2-AにおけるSHA3拡張命令セットは D = A XOR B XOR C の操作を1命令で処理できる veor3 命令なども含んでおり、暗号処理や疑似乱数生成などでは相応のパフォーマンスが期待できる。
一方ではCortex-A77などではサポートしているDot Product命令などは欠いているように見える。NPU(Neural Engine)を使わせたいので機械学習で有用な畳み込み演算を積極サポートする気がないのかもしれない。
(サポートしているが列挙されていないのか本当にサポートされていないのか詳しい方は調べてみてください)
補足 (12/4追記)
どうやらサポートする命令はMacOS上で表示されているだけに留まらないようです。
Hypervisor.framework上で動くようにカスタマイズされたqemuでFedora 33 aarch64を動かし、/proc/cpuinfoを確認してみると・・・こんなにもサポートする命令がありました。
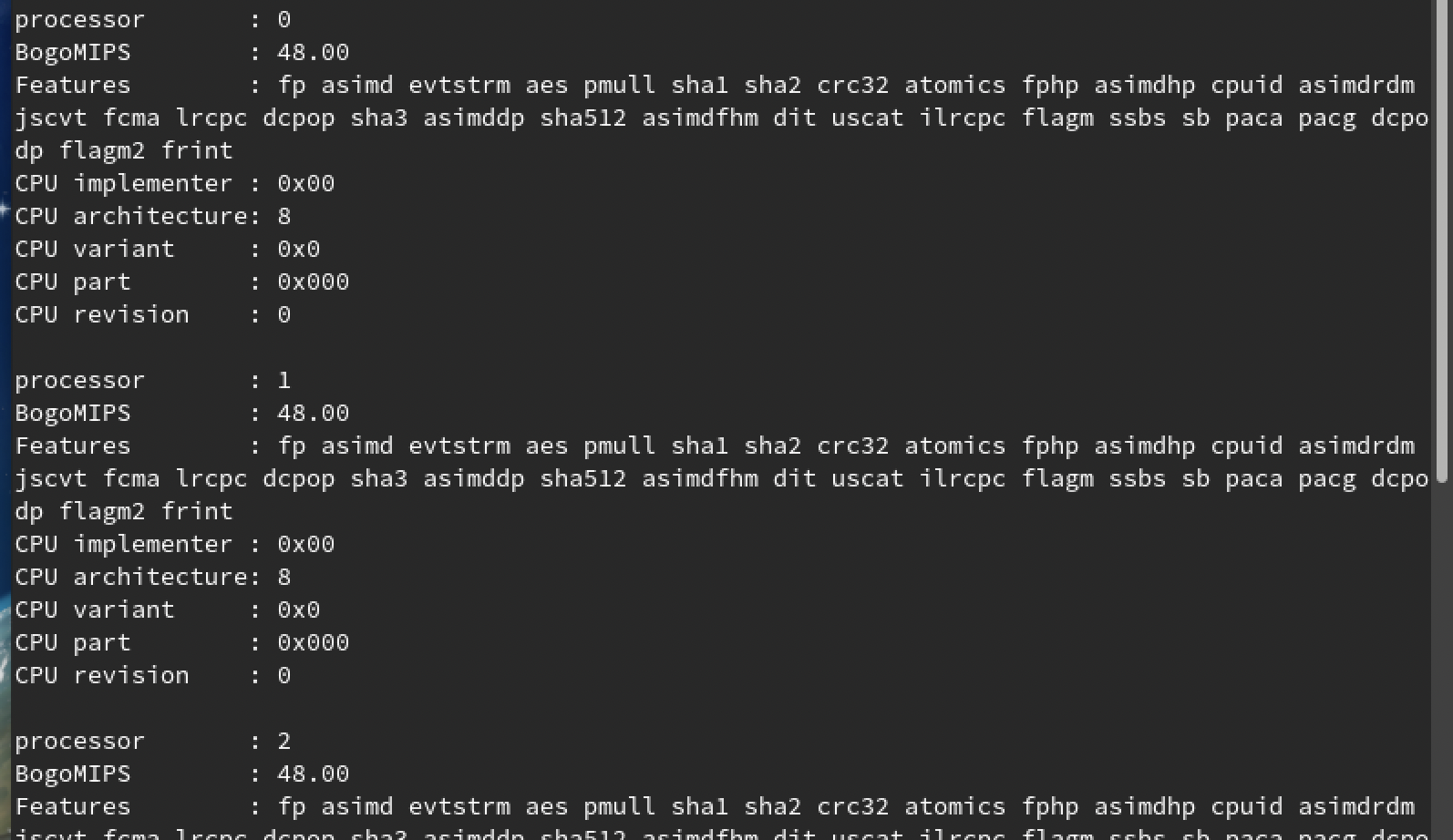
macOS上でもHWCAPを叩けばレジスタの値直接取得できるかもしれない(未検証)
2.4. M1における veor3 命令の効果を試してみる
組み込み関数が用意されていないのでインラインアセンブリで呼び出す。
SHA3拡張にてサポートされる veor3 命令はARMには珍しい4オペランド命令である。こんな感じでラップしてやればとりあえずは他の組み込み関数と同じように使えるはずである(呼び出し元コードの最適化には制約がかかる)。
inline uint32x4_t veor3q_u32_wrapper(uint32x4_t a, uint32x4_t b, uint32x4_t c)
{
uint32x4_t r;
# if defined(USE_NEON_SHA3)
__asm__ __volatile__(
"eor3.16b %0,%1,%2,%3"
:"=w"(r)
:"w"(a), "w"(b), "w"(c)
);
# else
r = veorq_u32(a, b);
r = veorq_u32(r, c);
# endif
return r;
}
XOR操作は暗号や疑似乱数で多用するので、複合命令がサポートされていれば、相応のパフォーマンスが期待できる。
ここで標準でSIMDが効く乱数としては定番(と言っておきたいかもしれない)SFMTを試してみたい。
同プログラムは4年前からARMのNEON(Advanced SIMD)命令をサポートしており(正確に言うと「ねじ込んだ」)、Raspberry Pi 3/4やAndroid NDK, iOSなどの対応CPUでも利用可能だ。
SFMT-neon.hのneon_recursion()関数ではveor3命令に置換可能な箇所が2箇所あるはずなのでこれに置換しよう。
ビルドするには Makefile.aarch64 を修正する必要がある。コンパイラを clang に修正し、 -march=armv8.3a+sha3 -DUSE_NEON_SHA3 などのオプションを加えてビルドしてみる。 なお +sha3 がないと先の改造したSFMT-neon.hがエラーを吐くし、勿論、先にも言った通り -march=native は現状使えません。
* SFMT(AARCH64-NEON)
% ./test-neon-M19937 -s
32 bit BLOCK:79ms for 100000000 randoms generation
32 bit SEQUE:101ms for 100000000 randoms generation
64 bit BLOCK:78ms for 50000000 randoms generation
64 bit SEQUE:85ms for 50000000 randoms generation
* 同 VEOR + VEOR → VEOR3 置換版
% ./test-neon-M19937 -s
32 bit BLOCK:74ms for 100000000 randoms generation
32 bit SEQUE:96ms for 100000000 randoms generation
64 bit BLOCK:74ms for 50000000 randoms generation
64 bit SEQUE:80ms for 50000000 randoms generation
効果は+5〜6%程度と限定的だが、後続のApple Sillicon(M2?)版以降のMacがM1の機能を網羅するであろうことを考えれば。多少でも性能が求められる用途では積極的に使っていきたい。
(補論) Intelと比べてどうなの?
SFMTのGitHubの方には最近AVX2/AVX-512対応のコードがマージされている(正確に言うとこれも「した」)ので、こちらも参考までに。
MacBookPro 2020(Intel)
Core i7-1068NG7 @ 2.3GHz(-> Max 4.1GHz)
macOS BigSur 11.0.1
SSE2(128-bit)/AVX2(256-bit)/AVX-512(256-bit)
% ./test-sse2-M19937 -s
32 bit BLOCK:35ms for 100000000 randoms generation
32 bit SEQUE:64ms for 100000000 randoms generation
64 bit BLOCK:35ms for 50000000 randoms generation
64 bit SEQUE:50ms for 50000000 randoms generation
% ./test-avx2-M19937 -s
32 bit BLOCK:32ms for 100000000 randoms generation
32 bit SEQUE:60ms for 100000000 randoms generation
64 bit BLOCK:32ms for 50000000 randoms generation
64 bit SEQUE:47ms for 50000000 randoms generation
% ./test-avx512-M19937 -s
32 bit BLOCK:26ms for 100000000 randoms generation
32 bit SEQUE:54ms for 100000000 randoms generation
64 bit BLOCK:25ms for 50000000 randoms generation
64 bit SEQUE:40ms for 50000000 randoms generation
性能向上は限定的だがAVX-512がサポートにされているのは流石最後のIntel Macといった感じ。パフォーマンスの伸びも良くIntelの面目躍如にして有終の美である。128ビットのSSE2でも十分な数字が出ている。と言うよりSFMTが構造上256ビット以上のSIMDに不向きであろう。
シングルスレッドで大きいところでM1に対して2〜3倍の性能差となると、メインメモリ帯域がそれほど重要でなくSIMDを多用する用途であれば、発熱の大きさなどに目を瞑ってもまだIntelの方が優勢とみなす余地はある。
なお、Windowsの方は第11世代(Tiger Lake)採用のノートPCなども出ているので、第10世代(Ice Lake)止まりで今後新機種はARMに置き換わるであろうIntel Macを買う必要があるかというと疑問である(AVX-512対応で最初で最後のMacとしてなら価値あるかも)
追試(2020.12.11)
ちょっと命令組み替えてみたところ、NEON(ASIMD)の性能が劇的に向上しIntel版MBP13-2020に迫るスコアを叩き出した。ちょっとわけがわからない。
他のARMアーキテクチャ(Cortex-A7x系)でもおそらく高速化できるであろう。
この改修内容は斎藤氏の承認次第公式レポジトリに反映予定である。
https://github.com/MersenneTwister-Lab/SFMT/pull/7
* SFMT(AARCH64-NEON)
% ./test-asimd-M19937 -s
32 bit BLOCK:44ms for 100000000 randoms generation
32 bit SEQUE:78ms for 100000000 randoms generation
64 bit BLOCK:44ms for 50000000 randoms generation
64 bit SEQUE:62ms for 50000000 randoms generation
* 同 VEOR + VEOR → VEOR3 置換版
% ./test-sha3-M19937 -s
32 bit BLOCK:37ms for 100000000 randoms generation
32 bit SEQUE:71ms for 100000000 randoms generation
64 bit BLOCK:37ms for 50000000 randoms generation
64 bit SEQUE:55ms for 50000000 randoms generation