こんにちは。
ソニーセミコンダクタソリューションズの岡(ゆ)と申します。
今回はAITRIOSのDeveloper Siteで公開されているConsole REST API Specificationを用いてエッジAIデバイスからAITRIOSのクラウドに送信された推論結果のデータの取得をしてみた(GUIアプリ編)という記事を投稿します。
この記事の要約
AITRIOSのConsole REST APIを利用してメタデータを取得してみた の内容を取り込んだPC上で動作するGUIアプリケーションを作成します。
下記図のようなアプリとなります。

実行環境に関して
下記の実行環境を使用しました。
基本的にはLinuxのPython環境があれば実行できる内容となります。
ここでは、Windows10/WSL2/Ubuntu-22.04 を使用していますが、Native Ubuntu-22.04 など、同様の環境であれば実行できると思います。
- Windows10
- WSL(WSL2) 2.1.5.0
- Ubuntu-22.04
- python 3.10.12
- python3-venv 3.10.6
GUIアプリの内容
前述の記事の内容は Jupyter Notebook で下記のステップを順次実行して結果を確認するものでしたが、今回はこれをそのままGUIアプリに実装します。
- Step1 AITRIOSに接続されているDevice一覧情報を取得する
- Step2 選択されたDeviceにおける画像ディレクトリ情報を取得する
- Step3 選択されたディレクトリ内の画像情報を取得し表示する
- Step4 画像に紐づいた推論結果を取得する
- Step5 推論結果をDeserializeする
- Step6 推論結果を画像に重ね合わせる
GUI部分についてはPySide2を使います。
なお、アプリを作成するためにいくつかのPythonパッケージをインストールすることになるのですが、venvを使用して仮想環境にインストールします。
手順さえ守れば通常使用しているUbuntuのPython環境はそのまま維持することができますので、安心してお試しください。
Python venvのインストールと使い方
既にPython venv環境をお使いの方は、この項はスキップしてください。
下記のパッケージをインストールします。
sudo apt install python3-dev python3-pip python3-venv
使い方です。
任意のディレクトリで下記を実行します。
python3 -m venv ./venv
venv ディレクトリが作成されます。
次に下記コマンドで venv をアクティベートします。
. venv/bin/activate
プロンプトの頭に"(venv)"が付加された状態になると思います。
venv 環境に入った状態で再度インストールされているパッケージを確認すると、最低限のパッケージしか入っていない状態になっていることがわかります。
(venv):~$ pip3 list
Package Version
---------- -------
pip 22.0.2
setuptools 59.6.0
この状態から任意のパッケージをインストールすることで、特定の用途向けの環境を作成することができるというわけです。
下記のコマンドを実行することで仮想環境を終了することができます。
deactivate
アプリの開発
それでは早速アプリをつくってみましょう。
アプリ作成用のディレクトリを作成します。
mkdir aitrios-app
このディレクトリ下で Python の venv環境を作ります。
cd aitrios-app
python3 -m venv ./venv
venv ディレクトリが作成されます。
なお、今後、この環境をしばらく使い続ける場合、次に使うときはこの作業はスキップできます。
次に下記コマンドで venv をアクティベートします。
. venv/bin/activate
プロンプトの頭に"(venv)"が付加された状態になっていることを確認します。
今回使用するPythonパッケージをインストールします。
pip install opencv-python-headless requests flatbuffers PySide2
下記の内容で aitrios-app.py を作成します。
まず、ソースコード中のgcs_okta_domain、base_url、client_id、client_secret について、下記の通り取得した値をセットしてください。
- base_url と base_url は、AITRIOS Developer Siteの Guides -> 用途で探す -> Console REST API 使い方ガイド のページ中にある「PortalおよびConsoleのエンドポイント情報」のリンクから取得できます(アクセス権が必要となります)。
- base_url は、日本国内であれば、"End point information for each region is as follows." -> Japan に記載されているURLです。
- gcs_okta_domain は、"Portal Endpoint" に記載されているURLです。
- client_id と client_secret は、Get Started の「3.6.2. AITRIOSにアクセスするためのクライアントを取得する」の手順で取得できます。
import base64
import cv2
import numpy as np
import requests
import json
from data_deserializer import get_deserialize_data
import os,sys,re
from PySide2.QtWidgets import QApplication, QWidget, QPushButton, QTextEdit, QLabel, QComboBox
from PySide2.QtGui import QPixmap, QImage
base_url = "{base_url}"
client_id = "{client_id}"
client_secret = "{client_secret}"
gcs_okta_domain = "{gcs_okta_domain}"
colors = [
(255, 0, 0),
(255, 128, 0),
(255, 255, 0),
(128, 255, 0),
(0, 255, 0),
(0, 255, 255),
(0, 128, 255),
(0, 0, 255),
(128, 0, 255),
(255, 0, 255),
(255, 0, 128),
(255, 255, 255),
(192, 192, 192),
(128, 128, 128),
(0, 0, 0),
]
class Utils:
@staticmethod
def Base64Decoder(data):
if type(data) is str:
data = data.encode("utf-8")
_decoded_data = base64.decodebytes(data)
return _decoded_data
@staticmethod
def Base64EncodedStr(data):
if type(data) is str:
data = data.encode("utf-8")
_encoded_data = base64.b64encode(data)
_encoded_str = str(_encoded_data).replace("b'", "").replace("'", "")
return str(_encoded_str)
@staticmethod
def Base64ToCV2(img_str):
_img_str = img_str # デフォルト値としてimg_strを代入
if "base64," in img_str:
# DATA URI の場合、data:[<mediatype>][;base64], を除く
_img_str = img_str.split(",")[1]
# Base64文字列をデコードし、バイト列に変換
_img_data = base64.b64decode(_img_str)
# バイト列をNumPy配列に変換
_nparr = np.frombuffer(_img_data, np.uint8)
# NumPy配列をOpenCVの画像形式に変換
_img = cv2.imdecode(_nparr, cv2.IMREAD_COLOR)
image_rgb = cv2.cvtColor(_img, cv2.COLOR_BGR2RGB)
return image_rgb
class ConsoleRESTAPI:
def __init__(self, baseURL, client_id, client_secret, gcs_okta_domain):
# Project information
self.BASE_URL = baseURL
CLIENT_ID = client_id
CLIENT_SECRET = client_secret
self.GCS_OKTA_DOMAIN = gcs_okta_domain
self.AUTHORIZATION_CODE = Utils.Base64EncodedStr(CLIENT_ID + ":" + CLIENT_SECRET)
##########################################################################
# Low Level APIs
##########################################################################
def GetToken(self):
headers = {
"accept": "application/json",
"authorization": "Basic " + self.AUTHORIZATION_CODE,
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded",
}
data = {
"grant_type": "client_credentials",
"scope": "system",
}
response = requests.post(
url=self.GCS_OKTA_DOMAIN,
data=data,
headers=headers,
)
analysis_info = json.loads(response.text)
token = analysis_info["access_token"]
return token
def GetHeaders(self, payload):
token = self.GetToken()
headers = {"Accept": "application/json", "Authorization": "Bearer " + token}
if payload != {}:
headers.setdefault("Content-Type", "application/json")
return headers
def Request(self, url, method, **kwargs):
params = {}
payload = {}
files = {}
url = self.BASE_URL + url
# set parameters
for key, val in kwargs.items():
if val != None:
if key == "payload":
# payload
payload = json.dumps(val)
elif key == "files":
# multipart/form-data
files = val
else:
# check parameters
if "{" + key + "}" in url:
# path parameter
url = url.replace("{" + key + "}", val)
else:
# query parameter
params.setdefault(key, str(val))
# create header
headers = self.GetHeaders(payload=payload)
# call request
try:
response = requests.request(
method=method, url=url, headers=headers, params=params, data=payload, files=files
)
analysis_info = json.loads(response.text)
except Exception as e:
return response.text
return analysis_info
def GetDevices(
self, connectionState=None, device_name=None, device_id=None, device_group_id=None
):
ret = self.Request(
url="/devices",
method="GET",
connectionState=connectionState,
device_name=device_name,
device_id=device_id,
device_group_id=device_group_id,
)
return ret
def GetImageDirectories(self, device_id=None):
ret = self.Request(url="/devices/images/directories", method="GET", device_id=device_id)
return ret
def GetImages(
self, device_id, sub_directory_name, order_by=None, number_of_images=None, skip=None
):
ret = self.Request(
url="/devices/{device_id}/images/directories/{sub_directory_name}",
method="GET",
device_id=device_id,
sub_directory_name=sub_directory_name,
order_by=order_by,
number_of_images=number_of_images,
skip=skip,
)
return ret
def GetInferenceResults(
self, device_id, NumberOfInferenceresults=None, filter=None, raw=None, time=None
):
ret = self.Request(
url="/devices/{device_id}/inferenceresults",
method="GET",
device_id=device_id,
NumberOfInferenceresults=NumberOfInferenceresults,
filter=filter,
raw=raw,
time=time,
)
return ret
class AitriosApp(QWidget):
"""
"""
def __init__(self):
super(AitriosApp, self).__init__()
self.setAcceptDrops(True)
self.console_api = ConsoleRESTAPI(base_url, client_id, client_secret, gcs_okta_domain)
self.initUi()
def button1action(self, value):
response = self.console_api.GetDevices()
devices = {"devices": []}
for device in response["devices"]:
devices["devices"].append(device["device_id"])
self.textEdit1.append(json.dumps(devices))
self.comboBox1.clear();
self.comboBox1.addItems(devices["devices"])
def button2action(self, value):
device_id = self.comboBox1.currentText()
self.textEdit1.append("device_id: " + device_id)
response = self.console_api.GetImageDirectories(device_id)
directories = {"directories": []}
for directory in response[0]["devices"][0]["Image"]:
directories["directories"].append(directory)
self.textEdit1.append(json.dumps(directories))
self.comboBox2.clear();
self.comboBox2.addItems(directories["directories"])
def button3action(self, value):
device_id = self.comboBox1.currentText()
sub_directory = self.comboBox2.currentText()
response = self.console_api.GetImages(device_id, sub_directory)
image_data = response["images"]
self.textEdit1.append("Saved image count: " + json.dumps(response["total_image_count"]))
# 画像群から最新の1枚を選択
image_name = image_data[-1]["name"]
img_base64 = image_data[-1]["contents"]
self.textEdit2.append(image_name)
img = Utils.Base64ToCV2(img_base64)
latest_image_ts = image_name.replace(".jpg", "")
self.textEdit2.append(latest_image_ts)
response = self.console_api.GetInferenceResults(device_id=device_id, NumberOfInferenceresults=1, time=latest_image_ts)
if len(response) == 0:
self.textEdit2.append("no matched inference data")
return
self.textEdit2.append(json.dumps(response))
inference_list = response[0]["inferences"]
self.textEdit2.append(inference_list[0]["O"])
deserialize_data = get_deserialize_data.get_deserialize_data(inference_list[0]["O"])
self.textEdit2.append(json.dumps(deserialize_data))
img_np = np.array(img)
for index in range(len(deserialize_data)):
color = colors[index]
# 矩形の描画
cv2.rectangle(img_np, (deserialize_data[str(index+1)]['X'], deserialize_data[str(index+1)]['Y']), (deserialize_data[str(index+1)]['x'], deserialize_data[str(index+1)]['y']), color\
,thickness=1, lineType=cv2.LINE_4, shift=0)
# 文字列の描画 {class id} : {score}
class_text = str(deserialize_data[str(index+1)]['C']) + ': ' + str(deserialize_data[str(index+1)]['P'])
cv2.putText(img_np,
text=class_text,
org=(deserialize_data[str(index+1)]['X'], deserialize_data[str(index+1)]['Y']),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.3,
color=color,
thickness=1,
lineType=cv2.LINE_4)
if index == 1:
break
# OpenCVの画像をQPixmapに変換
height, width, channel = img_np.shape
bytesPerLine = 3 * width
qImg = QImage(img_np.data, width, height, bytesPerLine, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(qImg)
# QLabelを作成し、QPixmapを設定してウィンドウ上に表示
self.label.setPixmap(pixmap)
self.label.setGeometry(210,30,width,height)
self.label.show()
def initUi(self):
self.button1 = QPushButton(u'getDevices',self)
self.button1.move(5,5)
self.button1.clicked.connect(self.button1action)
self.comboBox1 = QComboBox(self)
self.comboBox1.move(90,5)
self.button2 = QPushButton(u'getImageDir',self)
self.button2.move(200,5)
self.button2.clicked.connect(self.button2action)
self.comboBox2 = QComboBox(self)
self.comboBox2.move(290,5)
self.button3 = QPushButton(u'getImageAndInferences',self)
self.button3.move(380,5)
self.button3.clicked.connect(self.button3action)
self.textEdit1 = QTextEdit(self)
self.textEdit1.setVerticalScrollBarPolicy
self.textEdit1.move(5,30)
self.textEdit1.resize(200,320)
self.textEdit1.setReadOnly(1)
self.textEdit2 = QTextEdit(self)
self.textEdit2.setVerticalScrollBarPolicy
self.textEdit2.move(5,355)
self.textEdit2.resize(530,80)
self.textEdit2.setReadOnly(1)
self.label = QLabel(self)
self.label.move(5,0)
self.label.setGeometry(220,30,0,0)
self.label.show()
self.show()
def main():
"""
"""
app = QApplication(sys.argv)
w = AitriosApp()
w.setWindowTitle('AitriosApp')
w.resize(550, 440)
w.move(0, 0)
sys.exit(app.exec_())
if __name__ == '__main__':
main()
aitrios-sample-application-check-data-tool-pythonをクローンし、必要なファイルをコピーします。
git clone https://github.com/SonySemiconductorSolutions/aitrios-sample-application-check-data-tool-python.git
cp -R aitrios-sample-application-check-data-tool-python/src/data_deserializer ./
これでアプリの実装が完了です。
アプリの実行
想定どおりに作業が行われていれば、下記コマンドを実行することでGUIアプリが立ち上がると思います。
もし、立ち上がらない場合には、もう一度作業手順の見直しをお願いしますm_m
python3 aitrios-app.py
起動した直後はこのような状態になっていると思います。

"getDevices"ボタンをクリックすると、下記の内容が実行されます。
- Step1 AITRIOSに接続されているDevice一覧情報を取得する

デバイスが複数ある場合は、ドロップダウンリストから対象のデバイスを選択します。
"getImageDir"ボタンをクリックすると、下記の内容が実行されます。
- Step2 選択されたDeviceにおける画像ディレクトリ情報を取得する

ドロップダウンリストから実行したい画像ディレクトリを選択します。
"getImageAndInferences"ボタンをクリックすると、下記の内容がまとめて実行されます。
- Step3 選択されたディレクトリ内の画像情報を取得し表示する
- Step4 画像に紐づいた推論結果を取得する
- Step5 推論結果をDeserializeする
- Step6 推論結果を画像に重ね合わせる
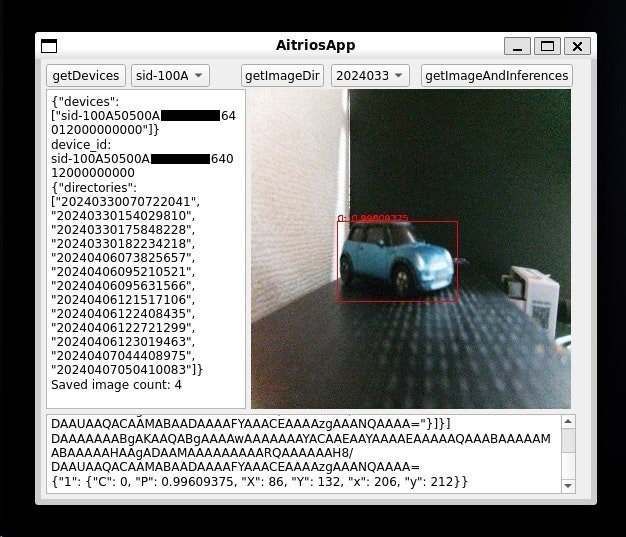
推論結果が重ね合わせた画像がGUIアプリ上に表示されました!
このように、AITRIOSのConsole REST API を使うことで、AITRIOSのAIによる推論結果を自由に活用することができます。
困った時は
もし、記事の途中でうまくいかなかった場合は、気軽にこの記事にコメントいただいたり、以下のサポートのページもご覧ください。
コメントのお返事にはお時間を頂く可能性もありますがご了承ください。
また、記事の内容以外で AITRIOS についてお困りごとなどあれば以下よりお問い合わせください。
さいごに
今回はAITRIOSのDeveloper Siteで公開されているConsole REST APIを用いてデータの取得から可視化を行うGUIアプリを作成してみました。
こういったことを行うことで、お客様のニーズに合わせてAITRIOSのデータ取得と解析をアプリケーション上で行うことができます。
お読みいただきありがとうございました!