DETR の Backbone と Transformer を分離し、Backbone を AITIROS のデバイスで、Transformer をPCで動かす
はじめに
ソニーセミコンダクタソリューションズ(株) AITRIOS カスタマーサポートの松岡です。
AITRIOS のエッジデバイスや Raspberry Pi AI Camera は、イメージセンサーにAI処理機能を搭載したIMX500 を採用しており、デバイス上でAI処理を実行します。
これらのデバイス向けに、AIモデルを簡単に使えるよう、クラス分類や物体検出などのAIモデル学習ツールが弊社ならびに他社様から提供されています。
また、開発者の方がご自身のAIモデルを作成して、デバイス上で動作させることもできます。
しかし、モデルサイズやレイヤー制約があり、どのようなAIモデルでも実行できるわけではありません。
しかし個人的意見ですが、エッジデバイスや Raspberry Pi AI CameraをPCやクラウドと連携させて、それぞれの特徴に応じてAIモデル機能を分担させると、動作の効率化や高機能化など新しいメリットを出せるのでは、と思っています。
そこで今回は、単純ですが、物体検知モデル DETR (DEtection TRansformer) を使って AITRIOS の応用を試してみたので、ご紹介します。
一般にDETR は推論の計算が重いと言われており、連続動作させた時にはリソースや電力の消費が懸念されます。
他方、上記の AITIROS のデバイスは、消費電力は比較的低いのですが軽量の深層学習モデルしか動かせません。
そこで DETR の一部を AITIROS のデバイスで分担し、必要な時にだけ DETR 全体を実行するシステムを作ります。
- Backbone と Transformer を分離し、Backbone はAITIROS のデバイスで動かし、Transformer はPCで動かします。
- Backbone にクラス分類を追加し、AITIROS のデバイスからは features と クラス分類の probabilities を出力します。
- Transformer は、クラス分類の probabilities に基づいて、何か物体がある確率が高い場合に動かします。
映像を Feature に変換して送信するので、個人情報が無くなるメリットもあるかもしれません。

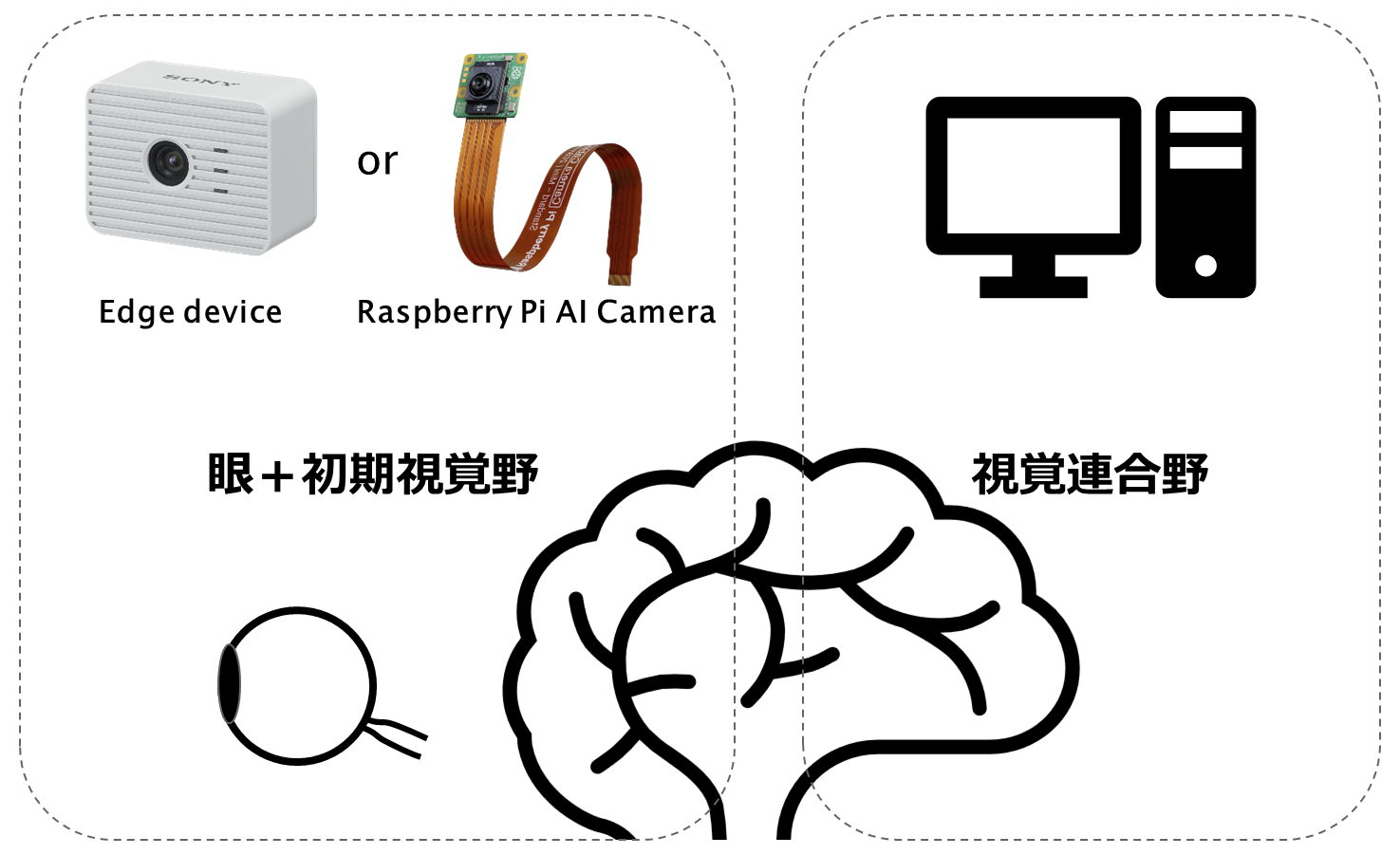
余談ですが、下記の図は、本記事でご紹介するシステムを脳で例えたイメージです。
脳は機能ごとに複数の領域(野)に分かれていて、これらの野が協調しながら並列に処理を行っています。
この脳の構造に照らし合わせたとき、エッジデバイスもしくは Raspberry Pi AI Camera は初期視覚野での特徴抽出までの処理に、PCは視覚連合野での複雑な認識処理に該当するのでは、と思っています。
もし AITRIOS をご存じなければ、こちらのサイトもご覧頂けると幸いです。
なお、AITIROS の Console Developer Edition は、法人様向けのサービスです。
- AITRIOS の Site: https://www.aitrios.sony-semicon.com/
- AITRIOS の Developer Site: https://developer.aitrios.sony-semicon.com/
- AITRIOS のデバイスで Object Detection してメタデータを取得してみた
ここからは、処理の実装と実行について説明します。
長くなりますので、記事を3つに分けて説明します。
-
本記事:
Backbone を MobileNetV2 に置き換えて学習した上で、ネットワークを Backbone と Transformer の2つに分離します。
さらに Backbone に Classifier を追加してクラス分類モデルを転移学習します。
その上で、Classifier 付きの Backbone と、分離した Transformer の2つのモデルを使い、Python で物体検出の動作を確認します。 -
別記事1(作成中):
AITRIOS の Console Developer Edition を使用し、エッジデバイスで Backbone を、PC で Transformer を動作させます。
エッジデバイスには、Classifier 付き Backbone を量子化してデプロイします。
エッジデバイスで推論を実行し、Console 経由で Output tensor を PC に定期的に取得します。
そのうえで、クラス分類の probabilities に基づき物体がある確率が高い場合に、Transformer を動かして物体検出を行います。 -
別記事2:
Raspberry Pi AI Camera で Backbone を、Raspberry Pi で Transformer を動作させます。
Raspberry AI Camera には、Classifier 付き Backbone を量子化して デプロイします。
Raspberry Pi AI Camera で推論を実行し、Output tensor を Raspberry Pi に定期的に取得します。
そのうえで、クラス分類の probabilities に基づき物体がある確率が高い場合に、Transformer を動かして物体検出を行います。
- 本記事に関する誤りや不備の指摘、ご質問などがありましたら、記事にコメントしてください。
コメントへのご返答にはお時間を頂いたり、ご返答できない可能性もありますがご了承ください。 - 本記事はあくまで応用事例を紹介するものであり、実際に動作させたときの性能や品質を保証するものではありません。
- 第三者特許の調査はしておりません。
- AITRIOSの不具合につきましては、AITRIOSのサポートページからご確認ください。
実装環境
-
GPU
GPU 必須です。
本記事はシングルGPUを前提に執筆していますが、DETR の学習には非常に時間がかかるので、マルチGPUが望ましいと思います。 -
Docker
Dockerfile と Python の requirements.txt を、この後に記載します。
量子化で使用する Model compression toolkit (MCT) version 2.0.0 の要件から、Python 3.11 と PyTorch 2.1 をインストールします。
なお、量子化の説明は本記事にはありません。別記事で説明します。 -
リポジトリ
DETR(https://github.com/facebookresearch/detr) の Main ブランチをクローンもしくはダウンロードします。
さらに detr のフォルダをコピーし、もう一同じ内容のフォルダを作成します。DETR から Backbone を分離すると、入力が RGB画像から Feature に変わります。
RGB画像入力と Feature 入力を切り替えられるようにするには、コード変更量が多くなりそうだったため、2つのフォルダで使い分けることにしました。 -
データセット
https://cocodataset.org/#home から、下記のデータセットをダウンロードして使用します。
- 2017 Train images
- 2017 Val images
- 2017 Train/Val annotations
Dockerfile
FROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
ARG python_version="3.11.5"
WORKDIR /app
RUN apt update && \
apt install -y \
wget \
bzip2 \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
libgl1
# Install pyenv
RUN apt-get -y install build-essential libssl-dev libffi-dev libncurses5-dev zlib1g zlib1g-dev libreadline-dev libbz2-dev libsqlite3-dev liblzma-dev
RUN curl https://pyenv.run | bash
ENV PYENV_ROOT /root/.pyenv
ENV PATH $PATH:$PYENV_ROOT/bin
ENV PATH $PATH:/root/.pyenv/shims
RUN echo 'eval "$(pyenv init -)"' >> /root/.bashrc
RUN . ~/.bashrc
COPY ./requirements.txt ./requirements.txt
RUN pyenv install ${python_version} \
&& pyenv global ${python_version} \
&& pip install -r requirements.txt
RUN pip install networkx==3.1
RUN pip install numpy==1.26.4
RUN pip install --no-cache-dir torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121
requirements.txt
model-compression-toolkit==2.0.0
torchvision==0.16.0
onnx==1.16.1
onnxruntime
onnxruntime-extensions
pycocotools==2.0.8
cython
submitit
scipy==1.14.0
PyYAML==6.0.1
jsonschema
opencv-python
MobileNetV2 への Backbone 変更と、DETR の学習
学習用にクローンした detr フォルダで、Backbone を MobileNetV2 に変更して、DETR の学習を行います。
Backbone は、次の2点を変更します。
-
ネットワーク を Resnet から MobileNetV2 に変更
-
MobileNetV2 の feature 出力に、Convolution レイヤー を接続
これは、エッジデバイスに Backbone をデプロイした際に、エッジデバイスから送信する Output tensor サイズを小さくするための追加です。
和を取るだけの処理で、学習は行いません。

学習にあたっては、平均 0 分散 1 へのデータセットの RGB値標準化を、[0..1]へのレンジ正規化に変更します。
エッジデバイスと Raspberry Pi AI Camera では、センサーの8bit RGB値が標準化されずにAIモデルに入力されるので、推論と学習を整合させるためです。
コードの変更
models/mobilnet_backbone.py
Backbone を MobileNetV2 を用いて定義します。
models フォルダに新規にファイルを置きます。
from collections import OrderedDict
import torch
import torch.nn.functional as F
import torchvision
from torch import nn
from torchvision.models._utils import IntermediateLayerGetter
from typing import Dict, List
from util.misc import NestedTensor, is_main_process
from .position_encoding import build_position_encoding
import numpy as np
from .backbone import Joiner
from torchvision.models.mobilenet import mobilenet_v2
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone:
parameter.requires_grad_(False)
return_layers = {"18": "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
num_channels_moboinet=1280
self.num_channels = 256
self.resize = torch.nn.Conv2d(in_channels=num_channels_moboinet,out_channels=self.num_channels,kernel_size=(1,1),bias=False)
step = int(num_channels_moboinet/self.num_channels)
weight = np.array( [[0 if i<j or (j+step-1)<i else 1 for i in range(num_channels_moboinet) ] for j in range(0,num_channels_moboinet, step) ] , dtype = 'float32' )
weight = weight.reshape(self.num_channels,num_channels_moboinet,1,1)
self.resize.weight = nn.Parameter(torch.from_numpy(weight))
self.resize.requires_grad = False
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
y = torch.stack( [self.resize(tensor).to(x.device) for tensor in x ] )
out[name] = NestedTensor(y, mask)
return out
class Backbone(BackboneBase):
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = mobilenet_v2(weights='IMAGENET1K_V1').features
super().__init__(backbone, train_backbone, return_interm_layers)
def build_backbone(args):
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
models/detr.py
新規に作成した models/mobilnet_backbone.py の build_backbone が、DETR モデル作成で呼ばれるようにするため、 models/detr.py の import を変更します。
#from .backbone import build_backbone
from .mobilnet_backbone import build_backbone
実験などでデータセットを変更する場合、クラス数を変更できるようすると便利です。
この場合、build 関数内の下記コードを変更します。
#num_classes = 20 if args.dataset_file != 'coco' else 91
num_classes = 20 if args.dataset_file != 'coco' else args.num_of_classes
メンバー変数 args.num_of_classes は、この後で main.pyの get_args_parser 関数に追加します。
datasets/transforms.py
学習画像のRGB値の値域を、推論時のAIモデル入力画像の値域と整合させるため、 データセットのレンジ正規化を行う関数を datasets/transforms.py に追加します。
class NormalizeWithoutStandardization(object):
def __call__(self, image, target=None):
if target is None:
return image, None
target = target.copy()
h, w = image.shape[-2:]
if "boxes" in target:
boxes = target["boxes"]
boxes = box_xyxy_to_cxcywh(boxes)
boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)
target["boxes"] = boxes
return image, target
datasets/coco.py
データセット取得時に、新たに作成したレンジ正規化関数 NormalizeWithoutStandardization が呼ぶれる様にするため、datasets/coco.py の make_coco_transforms 関数を変更します。
def make_coco_transforms(image_set):
normalize = T.Compose([
T.ToTensor(),
#T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
T.NormalizeWithoutStandardization()
])
COCOデータセット内のアノテーションと画像のサブフォルダへのパスは、datasets/coco.py のこちらで定義されています。
修正が必要な時の参考にしてください。
PATHS = {
"train": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),
"val": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),
}
main.py
get_args_parser 関数にクラス数の引数 num_of_classes を追加します。
get_args_parser.num_of_classes は、この後の Classifier の学習で import して参照します。
なお、データセットを変更したときにだけ使用します。
parser.add_argument('--num_of_classes', default=91, type=int, help='the number of classes')
学習の実行
Backbone を MobileNetV2 に変更したDETR を、学習させます。
下記は、自分がシングルGPUで学習した時の例です。
python main.py --coco_path /data/image/coco --epochs 300 --lr 5e-5 --lr_backbone 5e-6 --batch_size 8 --output_dir mobilenet
原著では、4 images per GPU で16台の GPU で学習し、batch数は 64 でした。
ですが上記の例では、GPUのメモリ制約から batch_size = 8 で、シングルGPUで学習しました。
また、batch_size を小さくしたので、原著より学習率を 1/2 に落としました。
学習には非常に時間がかかるので、もし環境をお持ちでしたら、https://github.com/facebookresearch/detr の説明に従ってマルチGPUで学習した方が良いと思います。
どうしてもDETR の学習の途中で学習率を変更する場合、main.py に下記の変更を入れた上で、--resume オプションを使って実行します。
if not args.eval and 'optimizer' in checkpoint and 'lr_scheduler' in checkpoint and 'epoch' in checkpoint:
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
#Add the code below to change the learning rate halfway.
optimizer.param_groups[0]['lr'] = args.lr
optimizer.param_groups[1]['lr'] = args.lr_backbone
DETRのネットワーク分割と重みの保存
ここからは、クローンした detr フォルダをコピーした、feature 入力の実装用フォルダで実装します。
ここからは、このフォルダを Separated DETR 動作検証フォルダと呼びます。
学習用にクローンしたフォルダは、ここからは使用しません。
ここではまず、DETR の学習結果を読み込み、ネットワークを Backbone と transformer に分離して重みを保存します。
メインとなるのは、新たに作成する save_saparated_networkin.py です。
このコードでは、Backbone と transformer の2つのネットワークを作成し、それぞれのネットワークにDETR の学習済み重みを読み込みんだ後、それぞれの重みを保存します。
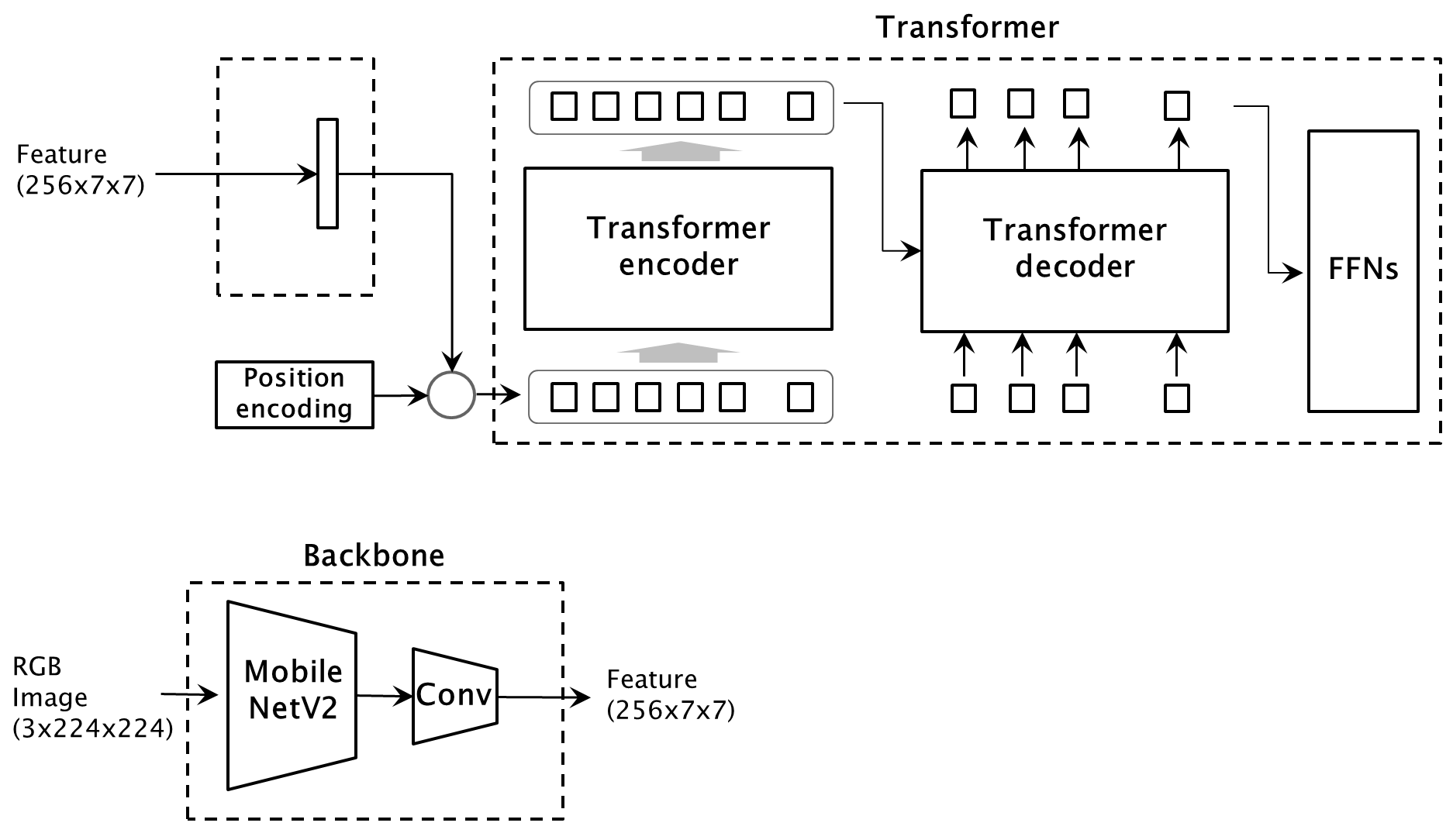
Transformer の分離は、モデル部分を切り出すのではなく、単純に DETR の入力を feature に変更することで代替します。
そのため、次の変更を行います。
- 入力の Nested tensor を、RGB画像から、feature に変更
- DETR の Backbone を、Interpolate だけ残した Backbone に変更
コードの変更
util/misc_for_separation.py
DETR の入力を RGB画像から feature に変更するため、Nested tensor を変更します。
import os
from typing import Optional, List
import torch
from torch import Tensor
from util.misc import _max_by_axis,NestedTensor
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
if tensor_list[0].ndim == 3:
batch_shape = tensor_list.shape
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
models/backbone_for_separation.py
feature に対して Interpolate だけ施す backbone を定義します。
models フォルダに新規にファイルを置きます。
import torch
import torch.nn.functional as F
from torch import nn
from typing import Dict, List
from util.misc import NestedTensor, is_main_process
from .position_encoding import build_position_encoding
import numpy as np
from .backbone import Joiner
class BackboneBase(nn.Module):
def __init__(self):
super().__init__()
self.num_channels = 256
def forward(self, tensor_list: NestedTensor):
out: Dict[str, NestedTensor] = {}
x = tensor_list.tensors
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
y = torch.stack( [tensor.to(x.device) for tensor in x ] )
out['0'] = NestedTensor(y, mask)
return out
def build_backbone(args):
position_embedding = build_position_encoding(args)
backbone = BackboneBase()
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
models/detr.py
変更した nested_tensor_from_tensor_list と build_backbone が、DETR モデル作成で呼ばれるようにするため、models/detr.py の import を変更します。
from util.misc import (NestedTensor, # nested_tensor_from_tensor_list,
accuracy, get_world_size, interpolate,
is_dist_avail_and_initialized)
from util.misc_for_separation import nested_tensor_from_tensor_list
#from .backbone import build_backbone
from .backbone_for_separation import build_backbone
データセット変更に伴うクラス数変更に対応するため、build 関数内の下記コードを変更します。
build 関数の変更
#num_classes = 20 if args.dataset_file != 'coco' else 91
num_classes = 20 if args.dataset_file != 'coco' else args.num_of_classes
models/mobilnet_backbone.py
学習用にクローンしたフォルダにある、「MobileNetV2 への Backbone 変更と、DETR の学習」で作成した models/mobilnet_backbone.py を、Separated DETR 動作検証フォルダにコピーします。
save_saparated_network.py で、Backbone 関数をインポートします。
main.py
学習用にクローンしたフォルダにある、「MobileNetV2 への Backbone 変更と、DETR の学習」で修正した main.py を、Separated DETR 動作検証フォルダにコピーします。
save_saparated_network.py で、get_args_parser 関数をインポートします
save_saparated_network.py
DETR の学習結果を読み込み、ネットワークを Backbone と transformer に分離して重みを保存するメインのコードです。
クローンした detr フォルダをコピーした、Separated DETR 動作検証フォルダの直下に新規にファイルを置きます。
import argparse
from pathlib import Path
import numpy as np
import torch
import util.misc as utils
from models import build_model
from models.mobilnet_backbone import Backbone
from main import get_args_parser
def main(args):
device = torch.device(args.device)
backbone = Backbone(args.backbone, args.lr_backbone, args.masks, args.dilation)
backbone.to(device)
model, criterion, postprocessors = build_model(args)
model.to(device)
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'], strict=False)
extracted_state_dict = {}
for key, value in checkpoint['model'].items():
if key.startswith('backbone.0'):
extracted_state_dict[key] = value
new_state_dict = backbone.state_dict()
for key, value in extracted_state_dict.items():
new_key = key.replace('backbone.0.', '')
if new_key in new_state_dict:
new_state_dict[new_key] = value
backbone.load_state_dict(new_state_dict, strict=False)
# save model
torch.save(model.state_dict(), args.transformer_path)
torch.save(backbone.state_dict(), args.backbone_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser('Save weights of the separated netoworks', parents=[get_args_parser()])
parser.add_argument('--backbone_path', type=str, default='moblienetv2_backbone.pth', help='The path to the backbone')
parser.add_argument('--transformer_path', type=str, default='transformer.pth', help='The path to the transformer model')
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
コードの実行
save_saparated_network.py を実行します。
args を流用しているので、読み込む学習結果の重みは --resume オプションを流用します。
下記は、DETR 学習用にクローンしたフォルダにある学習結果の重みを、フォルダごと Separated DETR 動作検証フォルダにコピーした前提に立っています。
python save_saparated_network.py --resume ./mobilenet/checkpoint.pth
Backbone への Classifier Layer 追加とクラス分類学習
分離して保存した Backbone に、線形結合層と Sigmoid 活性化関数からなるClassifier layer を追加し、COCO データセットでクラス分類を学習します。

Backbone は、Transformer用 の feature と、クラス分類の probabilities を出力します。
Convolution Layer は、先述のとおり、エッジデバイスから送信する Output tensor サイズを小さくするための単純加算レイヤーです。
コード
for_separation/my_coco.py
クラス分類用の、COCOデータセットの Dataloader を定義します。
for_separation フォルダを新たに作成し、ここに新規にファイルを置きます。
import os
import torch
import torch.utils.data
from PIL import Image
from pycocotools.coco import COCO
class CocoClassificationDataset(torch.utils.data.Dataset):
def __init__(self, annotation_file : str, image_folder : str, num_of_classes : int, transform=None):
self.image_folder = image_folder
self.transform = transform
self.coco = COCO(annotation_file=annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
self.categories = sorted(self.coco.getCatIds())
self.num_of_classes = num_of_classes
def __getitem__(self, index):
img_id = self.ids[index]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
coco_annotations = self.coco.loadAnns(ann_ids)
path = self.coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.image_folder, path))
labels = torch.zeros(self.num_of_classes)
for ann in coco_annotations:
cat_id = ann['category_id']
class_index = self.categories.index(cat_id)
labels[class_index] = 1
if self.transform is not None:
img = self.transform(img)
return img, labels
def __len__(self):
return len(self.ids)
for_separation/mobilenet.py
Transformer 用の feature と、クラス分類の probabilities を出力するモデルを定義し、for_separation フォルダに新規にファイルを置きます。
MobliNetV2 の Classifier layer に Sigmoid 活性関数を追加し、途中の feature を出力するようにしたモデルです。
Classifier layer の線形結合層のみ学習します。
IntermediateLayerGetter を使った feature 取得でなぜかエラーが出たので、register_forward_hook で代替しました。
import torch
import torch.nn.functional as F
import torchvision
from torch import nn
from torchvision.models._utils import IntermediateLayerGetter
import numpy as np
from torchvision.models.mobilenet import mobilenet_v2
class mobilenet_with_feature_output(nn.Module):
def __init__(self, num_of_classes : int):
super().__init__()
self.backbone = mobilenet_v2(weights='IMAGENET1K_V1')
self.backbone.classifier[1] = nn.Linear(in_features=1280, out_features=num_of_classes)
model.classifier = nn.Sequential(
model.classifier[0],
model.classifier[1],
nn.Sigmoid()
)
layer = dict([*self.backbone.named_modules()])['features.18']
layer.register_forward_hook(self.hook_fn)
for name, parameter in self.backbone.named_parameters():
if name.startswith('classifier'):
parameter.requires_grad_(True)
else:
parameter.requires_grad_(False)
num_channels_moboinet=1280
self.num_channels = 256
self.resize = torch.nn.Conv2d(in_channels=num_channels_moboinet,out_channels=self.num_channels,kernel_size=(1,1),bias=False)
step = int(num_channels_moboinet/self.num_channels)
weight = np.array( [[0 if i<j or (j+step-1)<i else 1 for i in range(num_channels_moboinet) ] for j in range(0,num_channels_moboinet, step) ] , dtype = 'float32' )
weight = weight.reshape(self.num_channels,num_channels_moboinet,1,1)
self.resize.weight = nn.Parameter(torch.from_numpy(weight))
self.resize.requires_grad = False
def hook_fn(self, module, input, output):
global intermediate_output
intermediate_output = output
def forward(self, tensors):
y = self.backbone(tensors)
feature = self.resize(intermediate_output)
return y, feature
train_classifier.py
Classifier 付き backbone 学習用のメインファイルです。
クローンした detr フォルダをコピーした、Separated DETR 動作検証フォルダの直下に新規にファイルを置きます。
import numpy as np
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from for_separation.mobilenet import mobilenet_with_feature_output
from for_separation.my_coco import CocoClassificationDataset
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--backbone_path', type=str, default='moblienetv2_backbone.pth', help='The path to the backbone')
parser.add_argument('--annotation_file', type=str, default='/data/image/coco/annotations/instances_train2017.json', help='The path to the annotation file')
parser.add_argument('--image_folder', type=str, default='/data/image/coco/images/train2017', help='The path to the image folder')
parser.add_argument('--classifier_model_path', type=str, default='backbone_with_classifier_weight.pth', help='The path to the clasiffier model')
parser.add_argument('--num_of_epoch', default=10, type=int, help='the number of epoch')
parser.add_argument('--num_of_classes', default=91, type=int, help='the number of classes')
args = parser.parse_args()
batch_size=32
model = mobilenet_with_feature_output(num_of_classes = args.num_of_classes)
checkpoint = torch.load(args.backbone_path, map_location='cpu')
new_state_dict = model.state_dict()
for key, value in checkpoint.items():
new_key = key.replace('body', 'backbone.features')
if new_key in new_state_dict:
new_state_dict[new_key] = value
model.load_state_dict(new_state_dict, strict=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.AdamW(model.parameters())
train_dataset = CocoClassificationDataset(
annotation_file = args.annotation_file,
image_folder = args.image_folder,
num_of_classes = args.num_of_classes,
transform = transforms.Compose([
transforms.Resize(size=(224,224)),
transforms.ToTensor(),
transforms.Lambda(lambda x: x.repeat(3, 1, 1) if x.shape[0] == 1 else x)
])
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
len = len(train_loader.dataset)
model = model.eval()
for epoch in range(args.num_of_epoch):
running_loss = 0.0
corrects = 0
for images, target in train_loader:
images = images.to(device, non_blocking=True)
target = target.to(device, non_blocking=True)
output,_ = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"epoch:{epoch + 1}, loss: {running_loss / len}")
torch.save(model.state_dict(), args.classifier_model_path)
コードの実行
Classifier 付き backbone の学習を実行します。
python train_classifier.py
動作の確認
本記事での最後に、分離した Classifier 付き backbone と Transformer を通しで動かして、物体検出動作を確認します。
なお、ここでは検出動作確認だけ行います。
クラス分類の probabilities に基づく検出動作の実行は、実際にデバイスを使う別記事の中で行います。
コード
detect.py
物体検出の関数と、バウンディングボックスを画像に描画する関数を定義します。
物体検出の関数は、Google Colab のコードを使用しました。
Separated DETR 動作検証フォルダの直下に、新規にファイルを置きます。
こちらのコードは、別記事でもインポートして使用します。
import numpy as np
import torch
import cv2
from util.box_ops import box_cxcywh_to_xyxy
def rescale_bboxes(out_bbox, device, size):
''' Soruce: Google Colab '''
''' URL: https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_attention.ipynb'''
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).to(device)
return b
def detect(feature, model, device, size):
''' Soruce: Google Colab '''
''' URL: https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_attention.ipynb'''
# mean-std normalize the input image (batch-size: 1)
outputs = model(feature)
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.8
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], device, size)
return probas[keep], bboxes_scaled
def draw_boxes(image, scores, boxes, image_path):
scores_txt = []
for i in scores:
scores_txt.append('{} : {:.3f}'.format(torch.argmax(i).item(),torch.amax(i).item()))
j = 0
for i in boxes.tolist():
cv2.rectangle(image, (int(i[0]), int(i[1])), (int(i[2]), int(i[3])), (0, 0, 255),1)
cv2.rectangle(image, (int(i[0]), int(i[1])), (int(i[0] + 9 * len(scores_txt[j])), int(i[1]) + 14 ), (0,255,255),thickness=-1)
cv2.putText(image,scores_txt[j],(int(i[0])+2, int(i[1])+12),cv2.FONT_HERSHEY_PLAIN,1,(0,0,0),1,cv2.LINE_AA)
j += 1
mat_img = cv2.addWeighted(image, 0.5, image, 0.5, 0)
return mat_img
validate_separated_detr.py
分離したClassifier 付き backbone と Transformer の重みを読み込んで、通して物体検出を実行するメインのコードです
Separated DETR 動作検証フォルダの直下に、新規にファイルを置きます。
import argparse
import json
from pathlib import Path
import numpy as np
import torch
from models import build_model
from for_separation.mobilenet import mobilenet_with_feature_output
from main import get_args_parser
from PIL import Image
import torchvision.transforms as T
from detect import detect, draw_boxes
import cv2
def main(args):
device = torch.device(args.device)
classifier = mobilenet_with_feature_output(num_of_classes = args.num_of_classes)
classifier.to(device)
classifier.load_state_dict(torch.load(args.classifier_path, map_location=torch.device('cpu')))
classifier.eval()
model, criterion, postprocessors = build_model(args)
model.to(device)
checkpoint = torch.load(args.transformer_path, map_location='cpu')
model.load_state_dict(checkpoint)
model.eval()
transform = T.Compose([
T.Resize(size=(224,224)),
T.ToTensor(),
])
im = Image.open(args.image_path)
img = transform(im).unsqueeze(0).to(device)
with torch.no_grad():
probabilities,feature = classifier(img)
scores, boxes = detect(feature, model, device, im.size)
cv2_img = cv2.cvtColor( np.array(im, dtype=np.uint8), cv2.COLOR_RGB2BGR)
ret_img = draw_boxes(cv2_img, scores, boxes, args.image_path)
cv2.imwrite(args.resutlt_image_path, ret_img)
if __name__ == '__main__':
parser = argparse.ArgumentParser('Test', parents=[get_args_parser()])
parser.add_argument('--image_path', type=str, default='000000271057.jpg', help='The path to an image')
parser.add_argument('--resutlt_image_path', type=str, default='out.jpg', help='The path to an result image')
parser.add_argument('--classifier_path', type=str, default='backbone_with_classifier_weight.pth', help='The path to the clasiffier model')
parser.add_argument('--transformer_path', type=str, default='transformer.pth', help='The path to the transformer model')
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
実行
--image_path オプションで指定した画像から物体を検出し、結果を-resutlt_image_path オプションで指定した画像に保存します。
結果画像には、バウンディングボックス、クラスID、確率 が書き込まれます。
実験等で、dim_feedforward や hidden_dim などの Transformer のパラメータを変更した場合、オプションでその値を設定してください。
python validate_separated_detr.py --image_path /data/image/coco/train2017/000000025411.jpg --resutlt_image_path result.jpg
長い記事ですが、ここまでお付き合いいただきありがとうございます。
ただ、残念ながら思っていたほどの精度は得られませんでした。
原因は Backbone を変えたことではなく、学習にあるのではと思っています。
詳しい方がおられましたら、ぜひ改善方法をコメントしてくださると嬉しいです。
| 良い検出 | 二重で検出 | 失敗した検出 | |
|---|---|---|---|
| ファイル名 | 000000025411.jpg | 000000013529.jpg | 000000065865.jpg |
| 検出結果 | 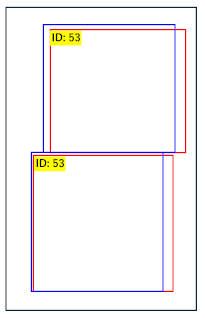 |
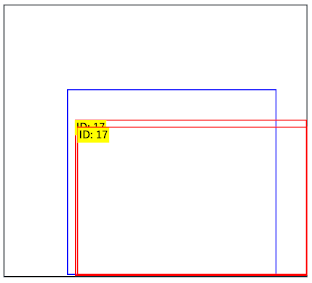 |
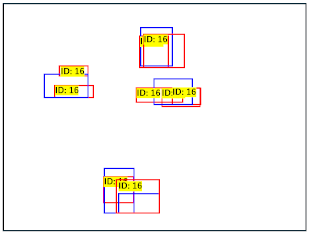 |

デバイスでの実行(別記事)
このあと別記事で、実際にデバイスを使って、クラス分類の probabilities に基づいた検出動作を実装します。
-
AITRIOS の Console Developer Edition をご利用の場合: 別記事1
AITRIOS の Console Developer Edition を使用し、エッジデバイスで Backbone を、PC で Transformer を動作させます。
-
Raspberry Pi AI Camera をご利用の場合: 別記事2
Raspberry Pi AI Camera で Backbone を、Raspberry Pi で Transformer を動作させます。
もしAITRIOSをご存じなければ、こちらのサイトもご覧ください。
- AITRIOS の Site: https://www.aitrios.sony-semicon.com/
- AITRIOS の Developer Site: https://developer.aitrios.sony-semicon.com/
困った時は
もし、記事の途中でうまくいかなかった場合は、気軽にこの記事にコメントください。
コメントのお返事にはお時間を頂く可能性もありますがご了承ください。
また、記事の内容以外で AITRIOS についてお困りごとなどあれば以下よりお問い合わせください。