Separating DETR's Backbone and Transformer: Running the Backbone on Device of AITIROS and the Transformer on PC
Introduction
I'm Matsuoka from Sony Semiconductor Solutions Corporation's AITRIOS Customer Support.
The Edge Devices of AITRIOS and Raspberry Pi AI Camera utilize the IMX500, which incorporates AI processing capabilities in the image sensor, enabling AI processing directly on the device.
For these devices, our company and others provide AI model training tools for tasks such as classification and object detection, making it easy to use AI models.
Additionally, developers can create and run their own custom AI models on these devices.
However, due to model size and layer constraints, not all AI models can be executed on these devices
However, in my opinion, Edge Devices and Raspberry Pi AI Cameras can offer new benefits such as improved operational efficiency and enhanced functionality.
I think this can be achieved by collaborating with PCs and cloud services, and distributing AI model functions according to the characteristics of each platform.
In this article, I'll share a simple application trial of AITRIOS using the DETR (DEtection TRansformer) object detection model.
DETR is generally known for its computationally intensive inference, therefore continuous operation may raise concerns about resource and power consumption.
On the other hand, while devices of AITRIOS mentioned above have relatively low power consumption, they can only run lightweight deep learning models.
Here, we will make a AITRIOS device perform part of the DETR process to create a system that executes the entire DETR only when necessary.
- Separate the Backbone and Transformer, running the Backbone on a device of AITRIOS and the Transformer on a PC.
- Add class classification to the Backbone. The AITRIOS device will output features and class classification probabilities.
- Activate the Transformer based on the class classification probabilities, only when there's a high probability of object presence.
Converting the images into features before transmission may also offer the benefit of eliminating personal information.
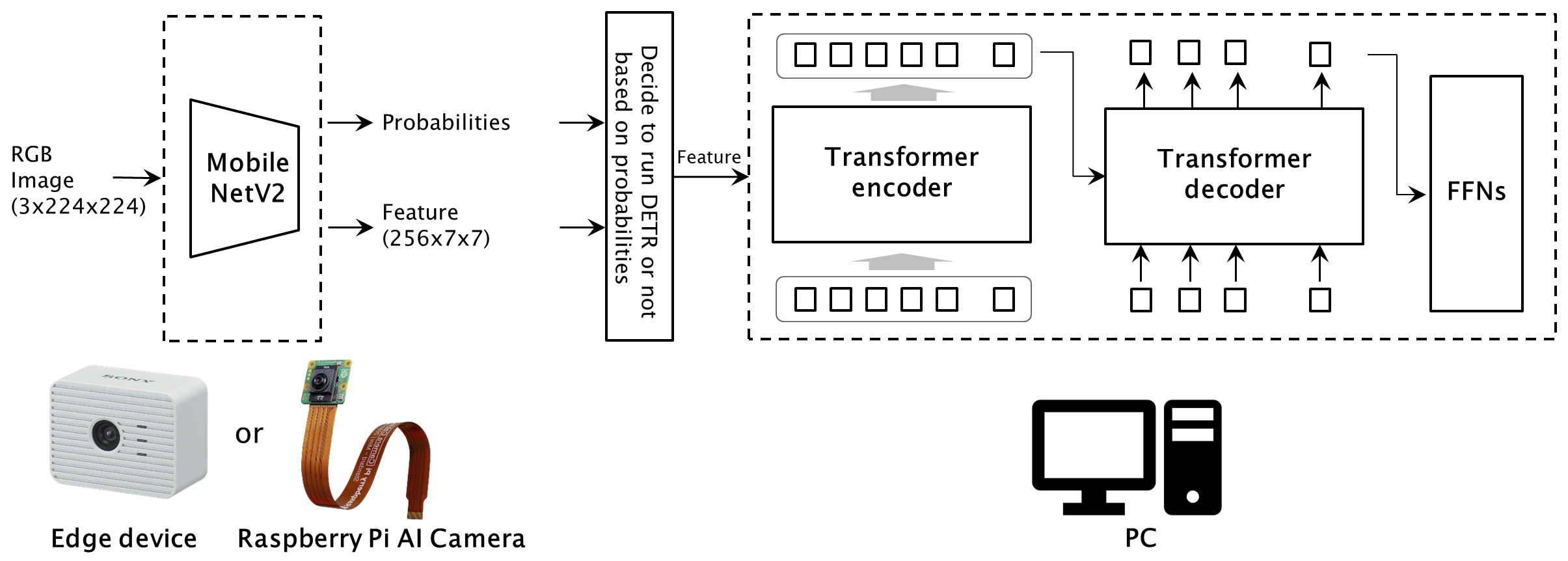
As a side note, the figure below illustrates the system introduced in this article, using the brain as an analogy.
The brain is divided into multiple areas based on function, with these areas working in parallel and in coordination.
When compared to this brain structure, I believe the Edge Device or Raspberry Pi AI Camera corresponds to the processing up to feature extraction in the early visual cortex, while the PC corresponds to the complex recognition processing in the visual association areas.

If you're not familiar with AITRIOS, we'd appreciate it if you could take a look at this site.
Please note that the Console Developer Edition of AITIROS is a service for corporate customers.
- Site for AITRIOS: https://www.aitrios.sony-semicon.com/
- Developer Site for AITRIOS: https://developer.aitrios.sony-semicon.com/
From here, we will explain the implementation and execution of the process.
As this is a lengthy topic, we will divide the explanation into three separate articles.
-
This article:
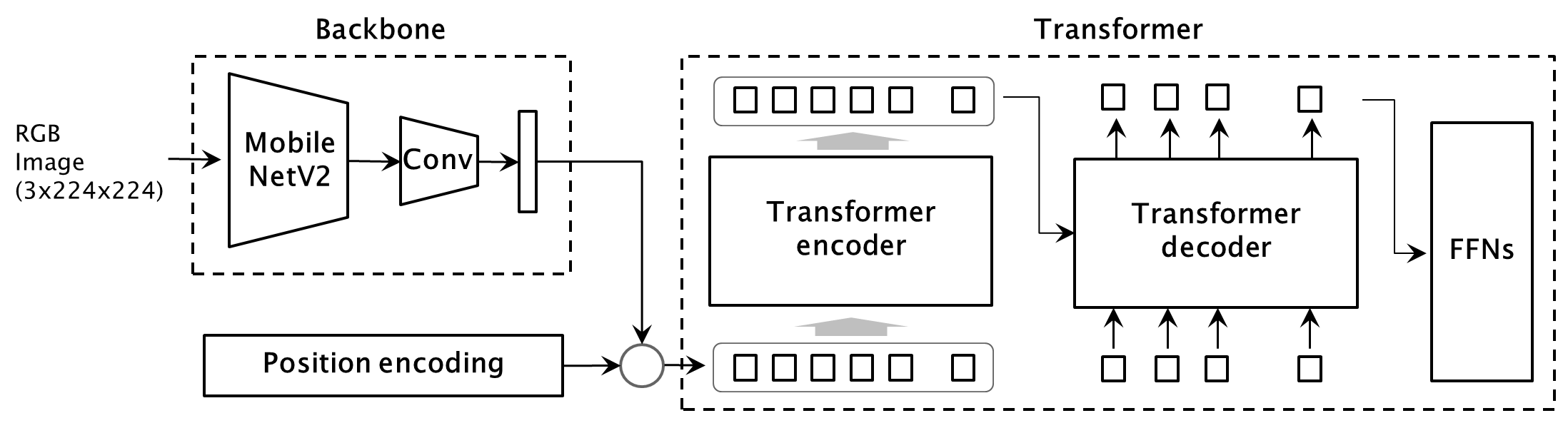
We will replace the Backbone with MobileNetV2 and train it, then separate the network into two parts: the Backbone and the Transformer.
Furthermore, we will add a Classifier to the Backbone and perform transfer learning for a classification model.
Finally, we will use Python to verify the object detection operation using two models: the Backbone with the added Classifier and the separated Transformer.
-
Using the Console Developer Edition of AITRIOS, we will run the Backbone on an Edge Device and the Transformer on a PC.
We will quantize the Backbone with the added Classifier and deploy it to the Edge Device.
The Edge Device will perform inference, and we will periodically retrieve the output tensor on the PC via the Console.
Based on the classification probabilities, when there's a high likelihood of object presence, the Transformer will be activated to perform object detection.
-
We will run the Backbone on a Raspberry Pi AI Camera and the Transformer on a Raspberry Pi.
We will quantize the Backbone with the added Classifier and deploy it to the Raspberry Pi AI Camera.
The Raspberry Pi AI Camera will perform inference, and we will periodically retrieve the output tensor on the Raspberry Pi.
Based on the classification probabilities, when there's a high likelihood of object presence, the Transformer will be activated to perform object detection.
- If you notice any errors or omissions in this article, or have any questions, please leave a comment on the article.
Please understand that it may take some time to respond to comments, and in some cases, we may not be able to respond. - This article is intended to introduce an application example and does not guarantee the performance or quality when implemented.
- We have not conducted any third-party patent searches.
- For any issues related to AITRIOS, please refer to the AITRIOS support page.
Implementation Environment
-
GPU
GPU is required.
This article assumes a single GPU setup, but multi-GPU is preferable for DETR training due to its time-consuming nature. -
Docker
Dockerfile and Python requirements.txt will be provided later.
Python 3.11 and PyTorch 2.1 are installed to meet Model Compression Toolkit (MCT) version 2.0.0 requirements for quantization.Note: Quantization are not covered in this article but will be explained separately.
-
Repository
Clone or download the main branch of DETR from https://github.com/facebookresearch/detr.
Create a duplicate of the detr folder.Separating the Backbone from DETR changes the input from RGB images to Features.
Two folders are used to switch between RGB image input and Feature input, avoiding extensive code modifications. -
Dataset
Download the following datasets from https://cocodataset.org/#home:
- 2017 Train images
- 2017 Val images
- 2017 Train/Val annotations
Dockerfile
FROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
ARG python_version="3.11.5"
WORKDIR /app
RUN apt update && \
apt install -y \
wget \
bzip2 \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
libgl1
# Install pyenv
RUN apt-get -y install build-essential libssl-dev libffi-dev libncurses5-dev zlib1g zlib1g-dev libreadline-dev libbz2-dev libsqlite3-dev liblzma-dev
RUN curl https://pyenv.run | bash
ENV PYENV_ROOT /root/.pyenv
ENV PATH $PATH:$PYENV_ROOT/bin
ENV PATH $PATH:/root/.pyenv/shims
RUN echo 'eval "$(pyenv init -)"' >> /root/.bashrc
RUN . ~/.bashrc
COPY ./requirements.txt ./requirements.txt
RUN pyenv install ${python_version} \
&& pyenv global ${python_version} \
&& pip install -r requirements.txt
RUN pip install networkx==3.1
RUN pip install numpy==1.26.4
RUN pip install --no-cache-dir torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121
requirements.txt
model-compression-toolkit==2.0.0
torchvision==0.16.0
onnx==1.16.1
onnxruntime
onnxruntime-extensions
pycocotools==2.0.8
cython
submitit
scipy==1.14.0
PyYAML==6.0.1
jsonschema
opencv-python
Changing backbone network to MobileNetV2 and training DETR
We'll modify the backbone network to MobileNetV2 and train DETR using the cloned detr folder
Two main changes to the Backbone:
-
Replace ResNet with MobileNetV2
-
Add a Convolution layer to MobileNetV2's feature output
This addition reduces the output tensor size when deploying the Backbone to Edge Devices.
It's a simple summation process and doesn't require training.
For training, we'll also change the dataset's RGB value standardization from mean 0, variance 1 to range normalization [0..1].
This aligns inference and training, as Edge Device and Raspberry Pi AI Camera input 8-bit RGB values to AI models without standardization.
Code Changes
models/mobilnet_backbone.py
We define the backbone using MobileNetV2.
Place this new file in the model's folder.
from collections import OrderedDict
import torch
import torch.nn.functional as F
import torchvision
from torch import nn
from torchvision.models._utils import IntermediateLayerGetter
from typing import Dict, List
from util.misc import NestedTensor, is_main_process
from .position_encoding import build_position_encoding
import numpy as np
from .backbone import Joiner
from torchvision.models.mobilenet import mobilenet_v2
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone:
parameter.requires_grad_(False)
return_layers = {"18": "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
num_channels_moboinet=1280
self.num_channels = 256
self.resize = torch.nn.Conv2d(in_channels=num_channels_moboinet,out_channels=self.num_channels,kernel_size=(1,1),bias=False)
step = int(num_channels_moboinet/self.num_channels)
weight = np.array( [[0 if i<j or (j+step-1)<i else 1 for i in range(num_channels_moboinet) ] for j in range(0,num_channels_moboinet, step) ] , dtype = 'float32' )
weight = weight.reshape(self.num_channels,num_channels_moboinet,1,1)
self.resize.weight = nn.Parameter(torch.from_numpy(weight))
self.resize.requires_grad = False
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
y = torch.stack( [self.resize(tensor).to(x.device) for tensor in x ] )
out[name] = NestedTensor(y, mask)
return out
class Backbone(BackboneBase):
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = mobilenet_v2(weights='IMAGENET1K_V1').features
super().__init__(backbone, train_backbone, return_interm_layers)
def build_backbone(args):
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
models/detr.py
To use the build_backbone function in the newly created models/mobilnet_backbone.py during DETR model creation, we modify the import statement in models/detr.py:
#from .backbone import build_backbone
from .mobilnet_backbone import build_backbone
It's useful to allow changing the number of classes when modifying datasets for experiments. In this case, we change the following code in the build function:
#num_classes = 20 if args.dataset_file != 'coco' else 91
num_classes = 20 if args.dataset_file != 'coco' else args.num_of_classes
The member variable args.num_of_classes will be added to the get_args_parser function in main.py later.
datasets/transforms.py
To align the RGB value range of training images with that of inference input images for the AI model, we add a function for dataset range normalization to datasets/transforms.py.
class NormalizeWithoutStandardization(object):
def __call__(self, image, target=None):
if target is None:
return image, None
target = target.copy()
h, w = image.shape[-2:]
if "boxes" in target:
boxes = target["boxes"]
boxes = box_xyxy_to_cxcywh(boxes)
boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)
target["boxes"] = boxes
return image, target
datasets/coco.py
To ensure that the newly created range normalization function RangeNormalize is called when retrieving the dataset, we modify the make_coco_transforms function in datasets/coco.py.
def make_coco_transforms(image_set):
normalize = T.Compose([
T.ToTensor(),
#T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
T.NormalizeWithoutStandardization()
])
The paths to the annotation files and image subfolders within the COCO dataset are defined in datasets/coco.py. Please refer to this when modifications are necessary.
PATHS = {
"train": (root / "train2017", root / "annotations" / f'{mode}_train2017.json'),
"val": (root / "val2017", root / "annotations" / f'{mode}_val2017.json'),
}
main.py
We add the num_of_classes argument to the get_args_parser function to allow specifying the number of classes. This get_args_parser.num_of_classes will also be imported and referenced in the subsequent Classifier training.
Note that this is used only when changing the dataset.
parser.add_argument('--num_of_classes', default=91, type=int, help='the number of classes')
Running the Training
We'll now train the DETR model with the modified MobileNetV2 backbone.
Here's an example of training on a single GPU:
python main.py --coco_path /data/image/coco --epochs 300 --lr 5e-5 --lr_backbone 5e-6 --batch_size 8 --output_dir mobilenet
The original paper used 16 GPUs with 4 images per GPU, resulting in a batch size of 64. This example uses a single GPU with a batch size of 8 due to GPU memory constraints. The learning rate has been reduced to 1/2 of the original due to the smaller batch size.
Training takes a considerable amount of time. It's recommended to use multi-GPU training as described in https://github.com/facebookresearch/detr, if you have multi-GPUs.
If you need to change the learning rate during the training of DETR, add the following changes to main.py and use the --resume option when running.
if not args.eval and 'optimizer' in checkpoint and 'lr_scheduler' in checkpoint and 'epoch' in checkpoint:
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
#Add the code below to change the learning rate halfway.
optimizer.param_groups[0]['lr'] = args.lr
optimizer.param_groups[1]['lr'] = args.lr_backbone
Splitting DETR Network and Saving Weights
From this point, we'll implement in the folder copied from the cloned detr folder, which is for feature input implementation.
We'll refer to this folder as the "Separated DETR Verification Folder" from now on.
We won't be using the folder cloned for training anymore.
First, we'll load the DETR training results, separate the network into Backbone and Transformer, and save their weights. The main script for this process is the newly created save_separated_network.py.
This code creates two networks, backbone and transformer, loads the trained DETR weights into each network, and then saves their respective weights.

For the Transformer separation, we'll simply change the DETR input to features instead of extracting the model part. Therefore, we'll make the following changes:
- Change the input Nested tensor from RGB images to features
- Modify DETR's backbone to a backbone that only retains the Interpolate function
Code Changes
util/misc_for_separation.py
We modify the Nested tensor to change DETR's input from RGB images to features.
import os
from typing import Optional, List
import torch
from torch import Tensor
from util.misc import _max_by_axis,NestedTensor
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
if tensor_list[0].ndim == 3:
batch_shape = tensor_list.shape
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
models/backbone_for_separation.py
We define a backbone that only applies Interpolation to the features.
Place a new file in the model's folder.
import torch
import torch.nn.functional as F
from torch import nn
from typing import Dict, List
from util.misc import NestedTensor, is_main_process
from .position_encoding import build_position_encoding
import numpy as np
from .backbone import Joiner
class BackboneBase(nn.Module):
def __init__(self):
super().__init__()
self.num_channels = 256
def forward(self, tensor_list: NestedTensor):
out: Dict[str, NestedTensor] = {}
x = tensor_list.tensors
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
y = torch.stack( [tensor.to(x.device) for tensor in x ] )
out['0'] = NestedTensor(y, mask)
return out
def build_backbone(args):
position_embedding = build_position_encoding(args)
backbone = BackboneBase()
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
models/detr.py
We modify the imports in models/detr.py to ensure that the updated nested_tensor_from_tensor_list and build_backbone are called during DETR model creation.
from util.misc import (NestedTensor, # nested_tensor_from_tensor_list,
accuracy, get_world_size, interpolate,
is_dist_avail_and_initialized)
from util.misc_for_separation import nested_tensor_from_tensor_list
#from .backbone import build_backbone
from .backbone_for_separation import build_backbone
We modify the following code within the build function to accommodate the change in the number of classes due to dataset modifications.
build 関数の変更
#num_classes = 20 if args.dataset_file != 'coco' else 91
num_classes = 20 if args.dataset_file != 'coco' else args.num_of_classes
models/mobilnet_backbone.py
Copy the models/mobilnet_backbone.py, which was created in "Changing backbone network to MobileNetV2 and training DETR" section, from the cloned folder for training to the Separated DETR Verification Folder.
In save_separated_network.py, we import the Backbone function.
main.py
Copy the main.py, which was modified in "Changing backbone network to MobileNetV2 and training DETR" section, from the folder cloned for training to the Separated DETR Verification Folder.
In save_separated_network.py, we import the get_args_parser function.
save_saparated_network.py
This is the main code that loads the DETR training results, separates the network into Backbone and transformer, and saves their weights.
We place this new file directly under the Separated DETR Verification Folder, which is a copy of the cloned detr folder.
import argparse
from pathlib import Path
import numpy as np
import torch
import util.misc as utils
from models import build_model
from models.mobilnet_backbone import Backbone
from main import get_args_parser
def main(args):
device = torch.device(args.device)
backbone = Backbone(args.backbone, args.lr_backbone, args.masks, args.dilation)
backbone.to(device)
model, criterion, postprocessors = build_model(args)
model.to(device)
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'], strict=False)
extracted_state_dict = {}
for key, value in checkpoint['model'].items():
if key.startswith('backbone.0'):
extracted_state_dict[key] = value
new_state_dict = backbone.state_dict()
for key, value in extracted_state_dict.items():
new_key = key.replace('backbone.0.', '')
if new_key in new_state_dict:
new_state_dict[new_key] = value
backbone.load_state_dict(new_state_dict, strict=False)
# save model
torch.save(model.state_dict(), args.transformer_path)
torch.save(backbone.state_dict(), args.backbone_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser('Save weights of the separated netoworks', parents=[get_args_parser()])
parser.add_argument('--backbone_path', type=str, default='moblienetv2_backbone.pth', help='The path to the backbone')
parser.add_argument('--transformer_path', type=str, default='transformer.pth', help='The path to the transformer model')
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
Code Execution
We execute save_separated_network.py.
As we're reusing args, we utilize the --resume option to load the trained weights.
The following assumes that the trained weights in the folder cloned for DETR training have been copied to the Separated DETR Verification Folder, along with their folder structure.
python save_saparated_network.py --resume ./mobilenet/checkpoint.pth
Adding a Classifier Layer to the Backbone and Training for Class Classification
We add a Classifier layer, consisting of a linear combination layer and a Sigmoid activation function, to the saved separated backbone. We then train it for class classification using the COCO dataset.
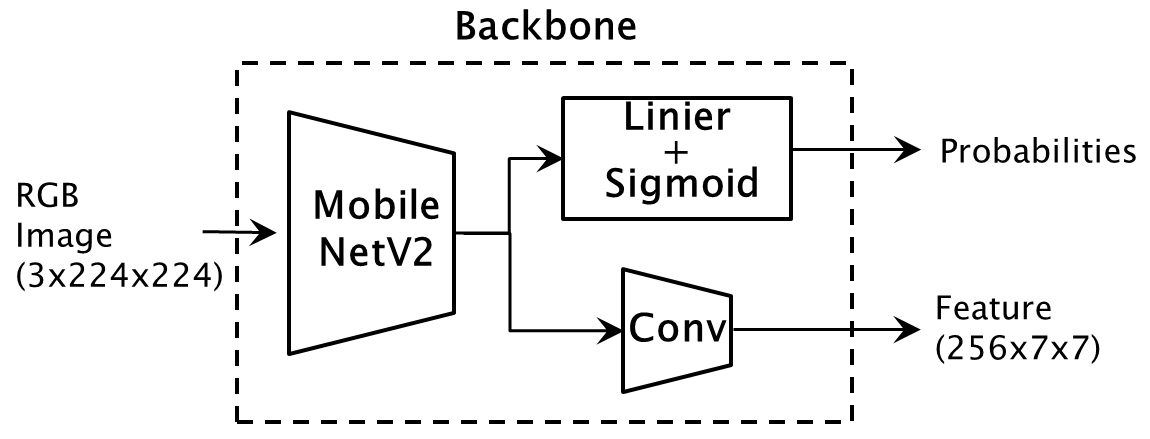
The Backbone outputs features for the Transformer and probabilities for class classification.
As mentioned earlier, the Convolution Layer is a simple addition layer designed to reduce the size of the Output tensor sent from an Edge Device.
Code
for_separation/my_coco.py
We define a Dataloader for the COCO dataset for class classification.
We create a new folder for_separation and place this new file in it.
import os
import torch
import torch.utils.data
from PIL import Image
from pycocotools.coco import COCO
class CocoClassificationDataset(torch.utils.data.Dataset):
def __init__(self, annotation_file : str, image_folder : str, num_of_classes : int, transform=None):
self.image_folder = image_folder
self.transform = transform
self.coco = COCO(annotation_file=annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
self.categories = sorted(self.coco.getCatIds())
self.num_of_classes = num_of_classes
def __getitem__(self, index):
img_id = self.ids[index]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
coco_annotations = self.coco.loadAnns(ann_ids)
path = self.coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.image_folder, path))
labels = torch.zeros(self.num_of_classes)
for ann in coco_annotations:
cat_id = ann['category_id']
class_index = self.categories.index(cat_id)
labels[class_index] = 1
if self.transform is not None:
img = self.transform(img)
return img, labels
def __len__(self):
return len(self.ids)
for_separation/mobilenet.py
We define a model that outputs feature for the Transformer and probabilities for class classification. We place this new file in the for_separation folder.
In this model, Sigmoid activation function is added to the Classifier layer of MobileNetV2. And this model outputs intermediate features. We only train the linear combination layer of the Classifier layer.
I encountered an error when using IntermediateLayerGetter for feature extraction, so I used register_forward_hook as an alternative.
import torch
import torch.nn.functional as F
import torchvision
from torch import nn
from torchvision.models._utils import IntermediateLayerGetter
import numpy as np
from torchvision.models.mobilenet import mobilenet_v2
class mobilenet_with_feature_output(nn.Module):
def __init__(self, num_of_classes : int):
super().__init__()
self.backbone = mobilenet_v2(weights='IMAGENET1K_V1')
self.backbone.classifier[1] = nn.Linear(in_features=1280, out_features=num_of_classes)
model.classifier = nn.Sequential(
model.classifier[0],
model.classifier[1],
nn.Sigmoid()
)
layer = dict([*self.backbone.named_modules()])['features.18']
layer.register_forward_hook(self.hook_fn)
for name, parameter in self.backbone.named_parameters():
if name.startswith('classifier'):
parameter.requires_grad_(True)
else:
parameter.requires_grad_(False)
num_channels_moboinet=1280
self.num_channels = 256
self.resize = torch.nn.Conv2d(in_channels=num_channels_moboinet,out_channels=self.num_channels,kernel_size=(1,1),bias=False)
step = int(num_channels_moboinet/self.num_channels)
weight = np.array( [[0 if i<j or (j+step-1)<i else 1 for i in range(num_channels_moboinet) ] for j in range(0,num_channels_moboinet, step) ] , dtype = 'float32' )
weight = weight.reshape(self.num_channels,num_channels_moboinet,1,1)
self.resize.weight = nn.Parameter(torch.from_numpy(weight))
self.resize.requires_grad = False
def hook_fn(self, module, input, output):
global intermediate_output
intermediate_output = output
def forward(self, tensors):
y = self.backbone(tensors)
feature = self.resize(intermediate_output)
return y, feature
train_classifier.py
This is the main file for training the backbone with a Classifier.
Place this new file directly under the Separated DETR Verification Folder, which is a copy of the cloned detr folder.
import numpy as np
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from for_separation.mobilenet import mobilenet_with_feature_output
from for_separation.my_coco import CocoClassificationDataset
import argparse
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--backbone_path', type=str, default='moblienetv2_backbone.pth', help='The path to the backbone')
parser.add_argument('--annotation_file', type=str, default='/data/image/coco/annotations/instances_train2017.json', help='The path to the annotation file')
parser.add_argument('--image_folder', type=str, default='/data/image/coco/images/train2017', help='The path to the image folder')
parser.add_argument('--classifier_model_path', type=str, default='backbone_with_classifier_weight.pth', help='The path to the clasiffier model')
parser.add_argument('--num_of_epoch', default=10, type=int, help='the number of epoch')
parser.add_argument('--num_of_classes', default=91, type=int, help='the number of classes')
args = parser.parse_args()
batch_size=32
model = mobilenet_with_feature_output(num_of_classes = args.num_of_classes)
checkpoint = torch.load(args.backbone_path, map_location='cpu')
new_state_dict = model.state_dict()
for key, value in checkpoint.items():
new_key = key.replace('body', 'backbone.features')
if new_key in new_state_dict:
new_state_dict[new_key] = value
model.load_state_dict(new_state_dict, strict=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.AdamW(model.parameters())
train_dataset = CocoClassificationDataset(
annotation_file = args.annotation_file,
image_folder = args.image_folder,
num_of_classes = args.num_of_classes,
transform = transforms.Compose([
transforms.Resize(size=(224,224)),
transforms.ToTensor(),
transforms.Lambda(lambda x: x.repeat(3, 1, 1) if x.shape[0] == 1 else x)
])
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
len = len(train_loader.dataset)
model = model.eval()
for epoch in range(args.num_of_epoch):
running_loss = 0.0
corrects = 0
for images, target in train_loader:
images = images.to(device, non_blocking=True)
target = target.to(device, non_blocking=True)
output,_ = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"epoch:{epoch + 1}, loss: {running_loss / len}")
torch.save(model.state_dict(), args.classifier_model_path)
Code Execution
Execute the training of the backbone with Classifier.
python train_classifier.py
Verification of Operation
Finally in this article, we will run the separated backbone with Classifier and the Transformer to verify the end-to-end object detection functionality.
Note that we will only check the detection operation here.
The execution of detection based on class classification probabilities will be carried out in a separate article where we use the device.
Code
detect.py
We define functions for object detection and for drawing bounding boxes on an image.
The object detection function uses code from Google Colab.
Place this new file directly under the Separated DETR Verification Folder.
This code will also be imported and used in separate articles.
import numpy as np
import torch
import cv2
from util.box_ops import box_cxcywh_to_xyxy
def rescale_bboxes(out_bbox, device, size):
''' Soruce: Google Colab '''
''' URL: https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_attention.ipynb'''
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).to(device)
return b
def detect(feature, model, device, size):
''' Soruce: Google Colab '''
''' URL: https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_attention.ipynb'''
# mean-std normalize the input image (batch-size: 1)
outputs = model(feature)
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.8
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], device, size)
return probas[keep], bboxes_scaled
def draw_boxes(image, scores, boxes, image_path):
scores_txt = []
for i in scores:
scores_txt.append('{} : {:.3f}'.format(torch.argmax(i).item(),torch.amax(i).item()))
j = 0
for i in boxes.tolist():
cv2.rectangle(image, (int(i[0]), int(i[1])), (int(i[2]), int(i[3])), (0, 0, 255),1)
cv2.rectangle(image, (int(i[0]), int(i[1])), (int(i[0] + 9 * len(scores_txt[j])), int(i[1]) + 14 ), (0,255,255),thickness=-1)
cv2.putText(image,scores_txt[j],(int(i[0])+2, int(i[1])+12),cv2.FONT_HERSHEY_PLAIN,1,(0,0,0),1,cv2.LINE_AA)
j += 1
mat_img = cv2.addWeighted(image, 0.5, image, 0.5, 0)
return mat_img
validate_separated_detr.py
This is the main code that loads the weights of the separated backbone with Classifier and the Transformer and executes end-to-end object detection.
Place this new file directly under the Separated DETR Verification Folder.
import argparse
import json
from pathlib import Path
import numpy as np
import torch
from models import build_model
from for_separation.mobilenet import mobilenet_with_feature_output
from main import get_args_parser
from PIL import Image
import torchvision.transforms as T
from detect import detect, draw_boxes
import cv2
def main(args):
device = torch.device(args.device)
classifier = mobilenet_with_feature_output(num_of_classes = args.num_of_classes)
classifier.to(device)
classifier.load_state_dict(torch.load(args.classifier_path, map_location=torch.device('cpu')))
classifier.eval()
model, criterion, postprocessors = build_model(args)
model.to(device)
checkpoint = torch.load(args.transformer_path, map_location='cpu')
model.load_state_dict(checkpoint)
model.eval()
transform = T.Compose([
T.Resize(size=(224,224)),
T.ToTensor(),
])
im = Image.open(args.image_path)
img = transform(im).unsqueeze(0).to(device)
with torch.no_grad():
probabilities,feature = classifier(img)
scores, boxes = detect(feature, model, device, im.size)
cv2_img = cv2.cvtColor( np.array(im, dtype=np.uint8), cv2.COLOR_RGB2BGR)
ret_img = draw_boxes(cv2_img, scores, boxes, args.image_path)
cv2.imwrite(args.resutlt_image_path, ret_img)
if __name__ == '__main__':
parser = argparse.ArgumentParser('Test', parents=[get_args_parser()])
parser.add_argument('--image_path', type=str, default='000000271057.jpg', help='The path to an image')
parser.add_argument('--resutlt_image_path', type=str, default='out.jpg', help='The path to an result image')
parser.add_argument('--classifier_path', type=str, default='backbone_with_classifier_weight.pth', help='The path to the clasiffier model')
parser.add_argument('--transformer_path', type=str, default='transformer.pth', help='The path to the transformer model')
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
Execution
The code detects objects from the image specified by the --image_path option and saves the result to the image specified by the --result_image_path option.
The result image will include bounding boxes, class IDs, and probabilities.
If you have changed Transformer parameters such as dim_feedforward or hidden_dim for experiments, please set those values using options.
python validate_separated_detr.py --image_path /data/image/coco/train2017/000000025411.jpg --resutlt_image_path result.jpg
Thank you for your patience throughout this lengthy article.
Unfortunately, the accuracy did not meet my expectations.
I believe the issue may stem from the training process rather than the changes made to the the backbone.
If anyone has expertise in this area, I would appreciate any suggestions for improvement.
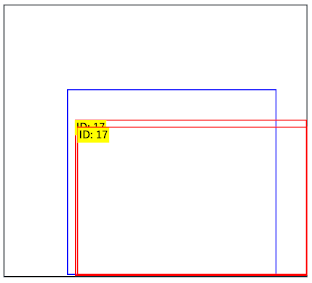
| Good detection | Double detection | Failed detection | |
|---|---|---|---|
| File name | 000000025411.jpg | 000000013529.jpg | 000000065865.jpg |
| Detection results |  |
 |
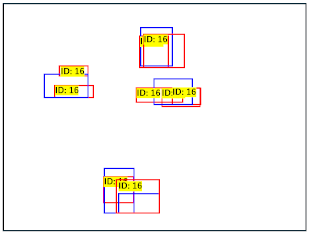 |

In consideration of copyright, the COCO images are presented in a concealed manner.
Execution on Devices (Separate Articles)
In subsequent articles, we will implement detection operation based on class classification probabilities using actual devices.
-
If you're using Console Developer Edition of AITRIOS: Separate Article 1
Using Console Developer Edition of AITRIOS, we will run the Backbone on an Edge Device and the Transformer on a PC.
-
If you're using Raspberry Pi AI Camera: Separate Article 2
We will run the Backbone on the Raspberry Pi AI Camera and the Transformer on the Raspberry Pi.
If you're not familiar with AITRIOS, please also check these sites:
- AITRIOS Site: https://www.aitrios.sony-semicon.com/
- AITRIOS Developer Site: https://developer.aitrios.sony-semicon.com/
When you need assistance
If you encounter any issues while navigating through this article, feel free to leave a comment.
We appreciate your understanding that it may take some time to respond to your inquiries.
Additionally, if you have any concerns or questions about AITRIOS beyond the content of this article, please contact us through the link below.