みんな大好きmmap(2)を使って、ファイルを仮想メモリ空間にMAP_SHAREDでマップすると、そのメモリへの書き込みがファイルに反映される。このメモリへの書き込み、いつ誰がどうやって検出しているのだろう。
仮想記憶とMMU
mmap(2)の機構、CPUの機能から考えると、大体2つの仕組みが考えられる。その前に、OSの動き、CPUの機能について簡単に説明しておく。
OSの重要な役割の一つは、各タスク (Unix系の用語ではプロセス) に独立の仮想メモリ空間を与えることである。あるプロセスの100番地には、(指定なき場合) 別のプロセスの100番地とは別な物理メモリが割り当てられる。PCやサーバ、スマートフォンなど、フルのLinuxの動作するようなCPUにおいて、仮想メモリ空間と物理メモリ空間のマッピングを行うハードウェアがMMU (Memory Management Unit) である。現在の多くのCPUは、MMUを内蔵しているが、かつてはCPUの近くに外付けされることもあった。Linuxは、メモリをあるサイズのページに分けて管理するページング型のMMUを前提としている。
x86_64やARM、Powerなど、現在主流の多くのCPUでは、原則ページのサイズは4KiBである。4KiBは12bitであるから、64bitの仮想メモリアドレスは、下位12bitのページオフセットと、上位52bitの仮想メモリ空間のページ番号 (仮想ページ番号) で表すことができる。
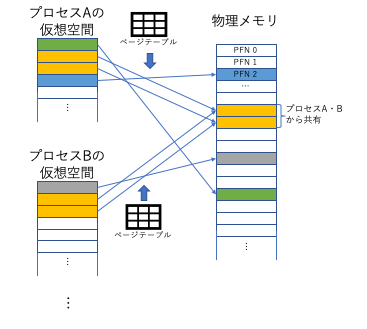
MMUは、メモリ上に置かれたページテーブルという表を使って、仮想メモリ空間のページを物理メモリ空間のページに変換する。ページテーブルは、仮想ページ番号をインデックスとする配列といえる。実際には仮想メモリ空間は疎に使われることを利用して、多段階 (x86-64では4〜5段) にすることで、ページテーブルのサイズを圧縮している。またx86-64では64bitのうち実際には48bitしか使われていない。x86-64のページテーブルの各エントリ (PTE: Page Table Entry) は、64bitの幅を持ち、上位側に物理ページ番号 (PFN: Page Frame Number)、下位12bitにはページに関する各種情報をビットマップで持つ。本稿で重要なのは、下位側にある情報である。x86-64では以下のような情報を持つが、他のアーキテクチャでも (名前こそ違え) 同じような情報を持つ。
-
P (Present) bit: 1にセットされているとき、当該仮想ページに対応する物理ページが存在する (マップされている) ことを示す。P bitが0にクリアされている場合、物理的にメモリが割り当てられていないため、この仮想ページへのアクセスはページフォルトとなる。余談であるが、x86においては、P bitがクリアされているときも、上位bitで表されるPFNに対応する物理メモリが投機的にアクセスされてしまうことがあるのが、L1TF脆弱性である。P bitがクリアされているとき上位にOSが使用する情報を格納することは仕様上許されており、Linuxではswap領域内の位置の情報などを格納することがある。
-
D (Dirty) bit: 当該仮想ページに書き込みアクセスがあると、CPUによって自動的にセットされる。自動的にクリアされることはないので、クリアするのはOSの役割である。
-
A (Accessed) bit: 当該ページにアクセスがあると、CPUによって自動的にセットされる。自動的にクリアされることはないので、クリアするのはOSの役割である。
-
R/W (Read/Write) bit: クリアされている時、当該ページはリードオンリーとなり、書き込みは許されない。
 (出典: Intel® 64 and IA-32 Architectures Software Developer Manual Volume 3A)
(出典: Intel® 64 and IA-32 Architectures Software Developer Manual Volume 3A)
プロセスがP bitがクリアされているページにアクセスしようとすると、ページフォルト (x86用語では#PF) という例外がOSに通知される。OSは、#PFを受けてページテーブルを適当に書き換え、プロセスの実行を再開してもよいし、不正メモリアクセス (Unix系OSでは典型的にはsegmentation faultシグナル) としてエラーにしてもよい。プロセスがR/W bitがクリアされているページに書き込みしようとしたときにもOSに#PF (write fault) が通知され、同様にページテーブルを適当に書き換え、プロセスの実行を再開しても良いし、エラーにしてもよい。
DとAは「CPUが変更することがある」というのが大きな特徴である。ページテーブルの他の部分をCPUが変更する事はなく、OSのみが変更する。またD、AともCPUは0から1にすることはあっても、逆に1から0にクリアすることはない。
ページキャッシュとキャッシュの書き出し
LinuxなどたいていのUnix系OSでは、ストレージのデータをメモリにキャッシュしているが、これはページ単位で行なわれるため、ページキャッシュと呼ばれる。ファイルのmmapは、このページキャッシュを仮想メモリ空間にマップすることで実現される。通常のwrite(2) (pwrite(2)、writev(2)などを含む) では、書き出しに先立ってページキャッシュを作成し (つまり、ストレージからページ全体の内容を読み出して)、このページキャッシュを書き換える。write(2)などのとき、OSはページキャッシュが書き換えられてストレージ上の原本との整合性が失われたことが把握できる。原本との整合性が失われたページのことをダーティページと呼ぶが、ダーティページは適切なタイミングでストレージに書き出され、原本と同じ状態、すなわちクリーンなページとなる。Linuxで、この書き出しを担当するのがかつてのbdflush、pdflush、最近のbdi flusherで、SIer各社秘伝のタレと化しているsysctlのチューニングパラメータ vm.dirty_ratioとかそのへんは、このbdi flusherの動作を変えるものである。
mmapの場合は事情が難しくなる。プロセスはファイルをmmapした領域を含め、メモリに勝手に書き込む。いつどこに書き込んだかは、普通にはOS (カーネル) からわからないわけだ。なんらかの方法で、プロセスがmmapされた領域に書いたこと、またどのページに書いたかを検出して、そのページをダーティとしなければならない。
余談だが、かつての実装の中には、mmap(2)はページキャッシュを使うものの、write(2)などでは別に用意されたバッファキャッシュという機構を使うものがあり、2つのキャッシュの間で余計なコピーが発生するとか、mmap(2)とwrite(2)などを同時並行的に使うとファイルの内容が壊れるなどといった問題があるものもあった (Linux-2.2まで、NetBSD-1.5までなど)。現在ではwrite(2)などにもページキャッシュを使うよう改良されており、このような問題は発生しない。
mmap域への書き込みの検出
先に書いたMMUの機能を踏まえると、mmap域への書き込みの補足方法として、2種類のやり方が考えられると思う。
-
PTEのD bitがセットされているものを探し出してダーティとする。ストレージに書き出すときにD bitをクリアする。
1a. 全てのページテーブル (全てのプロセスの仮想空間に対応する) をスキャンして探す。
1b. 全ての物理ページに対して、それを指すPTEを調べて探す。 -
R/W bitをクリアしておき、発生した#PF (write fault) を捉えてそのページをダーティとすると同時にR/W bitをセットしてプロセスを再開させる。ストレージに書き出す時にR/W bitをクリアする。
ページテーブルの調査は実はすでに行っていて、A bitを見ている。ページキャッシュは、長い間使われないと解放される (しないとメモリがいっぱいになってしまう) が、その「長い間使われていない」判定に使われる。これを、ページ置換アルゴリズムという。
たとえば、以下のようなアルゴリズムで解放するキャッシュを決める。まず、ページキャッシュに使われているページを全てリストに登録しておく。新たにページキャッシュとして確保されたページは、リストの末尾に追加していく。空きメモリが足りなくなってくると、このリストを先頭からスキャンし、ページを参照しているPTEのA bitを調べる。クリアされたままのページは、しばらく利用されていないと考えられるため、解放するが、セットされていれば、リストの末尾に移動する。これにより、リストは先頭付近が最近の利用頻度が低いページ、末尾付近がよく利用されているページに並んでくると考えられる (LRU: Least Recently Used順)。ここではページキャッシュについて書いたが、匿名メモリでも同様の処理をすることによって、swap領域に退避するページを決定することができる。
実際には、リストから外した後inactiveと呼ばれる別なリストに登録し、解放をしばらく待つことが一般的だ。最初に説明したリストをactiveリストと呼び、active、inactive、空きの比率を一定割合に保つようにする。また、上記を素朴に実装すると、スキャンが大きく偏るため、全体を効率よく公平にスキャンするための工夫もなされる。そのほか、スキャンはいつどういう条件で実行するか、とか、どれくらいのページを移動するか、とか、ページキャッシュと匿名メモリをどれくらい同様な、あるいは異なったあつかいにするか、などOSやバージョンによって細かな違いがあるが、大まかな動作はこんな感じだ。
mmapに話を戻す。1aのやり方 (仮に、ページテーブルスキャン方式と呼ぶ) は、PTEの調査をストレートに実行するものだ。D bitとA bitを同時に調査できる。複数の仮想空間からマップされている領域 (実行ファイルや共有ライブラリなど) は、使用中の全メモリを一周する間に複数回調べられることになる。
1bのやり方 (仮に、物理ページスキャン方式と呼ぶ) は、物理ページから、それをマップしている仮想空間、仮想アドレスを調べる方法が必要となる。A bitも同時に調査できるため、使用中の全物理ページを辿るには、先ほどのactive/inactiveリストを利用することができる。利用頻度に応じたスキャンの最適化はできそうだ。
1aにしても、1bにしても、一定の期間の間に使用中の全ページを調査する必要がある。さもないと、ダーティとなったページが長期間にわたって検出できなくなってしまう。ただ、1aの場合には、プロセススケジューラと連携して、最近スケジュールされていないプロセスの仮想空間のスキャンはスキップする、といった最適化は考えられる。
2つ目のやり方 (仮に、write fault捕捉方式と呼ぶ) では、#PFの処理が重いのではないかという点が問題になると思われる。あまりwrite faultが頻発すると、そのプロセスの実行が遅くなる可能性がある。メモリの近隣の領域にはまとまったアクセスがあることが知られているが (アクセスの局所性)、一度write faultが発生してR/W bitをセットした後しばらくページをダーティのままにしておき、書き出しの直前にR/W bitをクリアする、というようなことで、複数回のメモリ書き込みをまとめてストレージに書き出すような工夫などで軽減する必要がある。一方で、ダーティになる瞬間を捉えることができるため、ダーティとなった30秒後にストレージに書き出す (書き出し始める) ことを保証する、とか、ダーティページの数を一定以内に保つ、といったことが実現するのが容易になる。
長くなったので本稿はここまで。実際に幾つかのOSSのOSのソースコードを調べてみたところ、実際に1bの物理ページスキャン方式と、2のwrite fault捕捉方式については利用しているOSが見つかったので、次稿で紹介したい。