背景
最近Hadoopを触りずつ、資料があまりまとめていないと感じていますので、今回は私用のWindowsにあるVMwareで、Ubuntuのインストールしてから、Hadoop3のインストールと環境構築、SingleNodeClusterとしてMapReduceサンプルの実行までやってみようと思います。
Hadoopの紹介などは割愛させていただきます。
実装
目次
1、色々
2、Hadoop3のインストールと環境構築
3、MapReduceサンプルの実装
1、色々
VMware:VMware Workstation Pro 15.5.0
Ubuntuのisoダウンロード:https://jp.ubuntu.com/download
今回のバージョンはUbuntu 22.04です。
2、Hadoop3のインストールと環境構築
主に下記のページに参考
https://hadoop.apache.org/docs/r3.2.3/index.html
ユーザー作成(必須ではない)
Hadoopユーザーを作成します。
sudo adduser Hadoop sudo
SSHの設定
sudo -u hadoop ssh-keygen -b 4096 -C hadoop
sudo -u hadoop ssh-copy-id localhost
Javaとopensshのインストール
sudo apt install openjdk-8-jdk openssh-server -y
Hadoopインストール
今回はhadoop-3.2.3を選択します。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
/optに解凍
sudo tar -zxvf hadoop-3.2.3.tar.gz -C /opt
ユーザーhadoopにフォルダの権限を設定
sudo chown hadoop:hadoop -R /opt/hadoop-3.2.3
Hadoop環境構築
ユーザーhadoopに切り替え
su hadoop
~/.bashrcに環境変数設定
vim ~/.bashrc
下記の内容を追加
export HADOOP_HOME=/opt/hadoop-3.2.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
そして
source ~/.bashrc
HADOOP_HOMEに移動
cd /opt/hadoop-3.2.3
JAVA_HOMEをetc/hadoop/hadoop-env.shに追加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
etc/hadoop/core-site.xmlの<configuration></configuration>に追加
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
etc/hadoop/hdfs-site.xmlの<configuration></configuration>に追加
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hdfs/datanode</value>
</property>
etc/hadoop/mapred-site.xmlの<configuration></configuration>に追加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
etc/hadoop/yarn-site.xmlの<configuration></configuration>に追加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
ここまで環境の設定が完了しました。
検証として、下記のコマンドを実行します。
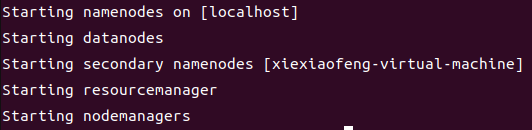
start-dfs.sh
start-yarn.sh
実行成功すると、下記のようになります。
コマンドjpsによりも現状確認できます。
停止したい時は
stop-dfs.sh
stop-yarn.sh
3、MapReduceサンプルの実装
準備として、先ずは下記のコマンドを実行します。
hadoop classpath
得られたclasspathをvalueとして、mapred-site.xmlおよびyarn-site.xmlに追加します。
(org.apache.hadoop.mapreduce.v2.app.MRAppMasterエラーを回避するため)
・mapred-site.xml
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.2.3/etc/hadoop:/opt/hadoop-3.2.3/share/hadoop/common/lib/*:/opt/hadoop-3.2.3/share/hadoop/common/*:/opt/hadoop-3.2.3/share/hadoop/hdfs:/opt/hadoop-3.2.3/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.3/share/hadoop/hdfs/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/*:/opt/hadoop-3.2.3/share/hadoop/yarn:/opt/hadoop-3.2.3/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.3/share/hadoop/yarn/*
</value>
</property>
・yarn-site.xml
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.2.3/etc/hadoop:/opt/hadoop-3.2.3/share/hadoop/common/lib/*:/opt/hadoop-3.2.3/share/hadoop/common/*:/opt/hadoop-3.2.3/share/hadoop/hdfs:/opt/hadoop-3.2.3/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.3/share/hadoop/hdfs/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/*:/opt/hadoop-3.2.3/share/hadoop/yarn:/opt/hadoop-3.2.3/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.3/share/hadoop/yarn/*
</value>
</property>
今回は添付されたサンプルプログラムwordcountsを実行します。
inputとoutputファイルをhdfs上に作成
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -mkdir -p /user/hadoop/output
countしたいテキストファイルを作成
vim ~/inputcount #内容は英語で、適当で
作成したテキストファイルをhdfsにコピー
hdfs dfs -put ~/inputcount /user/hadoop/input
最後は実行
hadoop jar /opt/hadoop-3.2.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount input output
実行成功すると下記のようなメッセージが表示されます。

下記のlsコマンドによりも結果ファイルが確認できます。
hdfs dfs -ls /user/hadoop/output
最後
雑談ですが、
「今更Hadoopで、Sparkの方が良いではないか」という感想もよく湧きます。元々はSpark勉強のためHadoopの本を見に始めました。やはりインフラの部分を体験しないと色々理解できないので、または案外面白いから、ということですね。
次はSparkの実装をやってみようと思います。