はじめに
プログラミング初心者の私がPythonを使ってYahoo Newsをスクレイピングしてみたのでその手順を書き記したいと思います。(自分用のメモみたいなもの)
事前にBeautiful Soupとrequestsのインストールが必要です。
やること
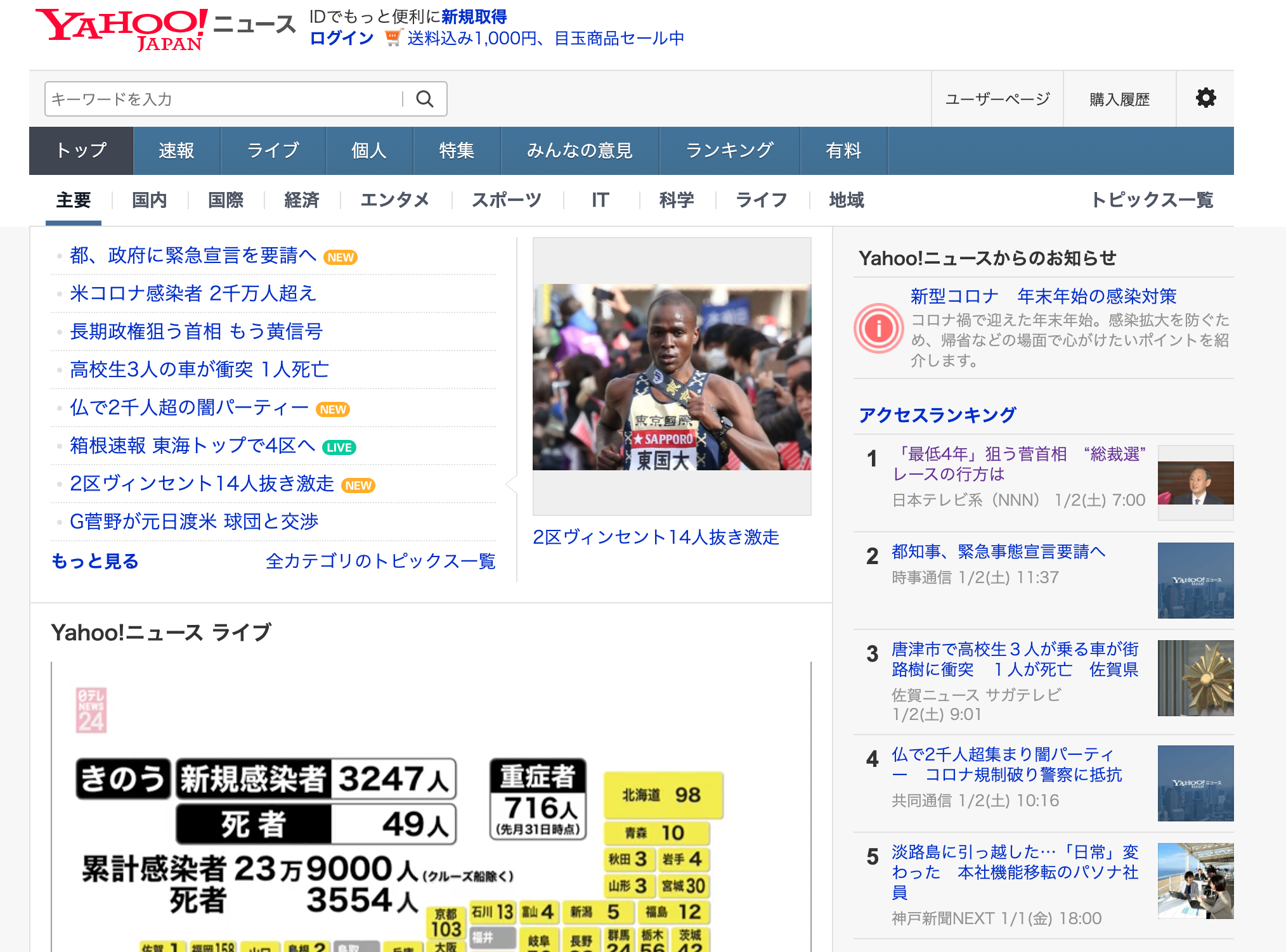
今回はYahoo Newsのアクセスランキングを取得してみます。画像の右下に「アクセスランキング」というものがありますね。これを1位から5位までスクレイピングで取得します。
書いたコード
短いコードですがたったこれだけでスクレイピングができてしまいます。(BeautifulSoupしゅごい)
import requests
from bs4 import BeautifulSoup
url = 'https://news.yahoo.co.jp/'
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
ranking = soup.find(class_="yjnSub_section")
items = ranking.find_all("li",class_="yjnSub_list_item")
print("【アクセスランキング】")
for i,item in enumerate(items):
text = item.find("p", class_="yjnSub_list_headline")
news_url = item.find("a")
print(str(i+1) + "位:" + text.getText())
print(news_url.get('href'))
いざ、ターミナルで実行

ちゃんと動いてくれました。
(なんか、若干ランキング変動してるけど大体合ってるからヨシ!)
ざっと解説
Chrome上で右クリック→検証でHTMLが閲覧できるのでそれを活用します。
ranking = soup.find(class_="yjnSub_section")
アクセスランキングはsectionタグのyjnSub_sectionというクラスに入っていたので、この部分を取得します。
items = ranking.find_all("li",class_="yjnSub_list_item")
ranking変数には、まだ1位から5位のニュースの情報が丸々入っているので、リスト化してitems変数に入れます。それぞれのニュースはliタグのyjnSub_list_itemというクラスに入っていたので、この部分を取得します。
text = item.find("p", class_="yjnSub_list_headline")
記事のタイトルを取得します。pタグのyjnSub_list_headlineというクラスに入っていたので、この部分を取得します。
news_url = item.find("a")
記事のURLはaタグに入っていたので、この部分を取得します。
print(str(i+1) + "位:" + text.getText())
print(news_url.get('href'))
textとnews_urlにはいらん部分まで入ってるのでtext.getText()とnews_url.get('href')で必要な部分だけを出力するようにします。
これで無事スクレイピングができるようになりました。
最後に
Pythonを使えばこんな感じに簡単にスクレイピングができてしまいます。
是非興味があったらやってみてください。
ただし、サイトによってはスクレイピングを禁止しているところもあるのでそこは注意。