はじめに
ChatGPTは流暢な文章を生成してくれるため非常に有用ですが、2021年9月までのテキストデータでしか学習されておらず、それ以降の事項については出力に反映されることはありません。
先日ChatGPTにブラウジング機能が追加され、この問題は解決されましたが、Web上でオープンになっている情報しか用いることができません。
そこで今回は、自分で用意した外部の情報を、LlamaIndexというライブラリを用いてLLM(大規模言語モデル)に組み込む方法について検証します。
LlamaIndexとは
まずはじめに、LlamaIndexとはどのようなものなのでしょうか。こんな時はChatGPT(ブラウジング)に聞いてみましょう。
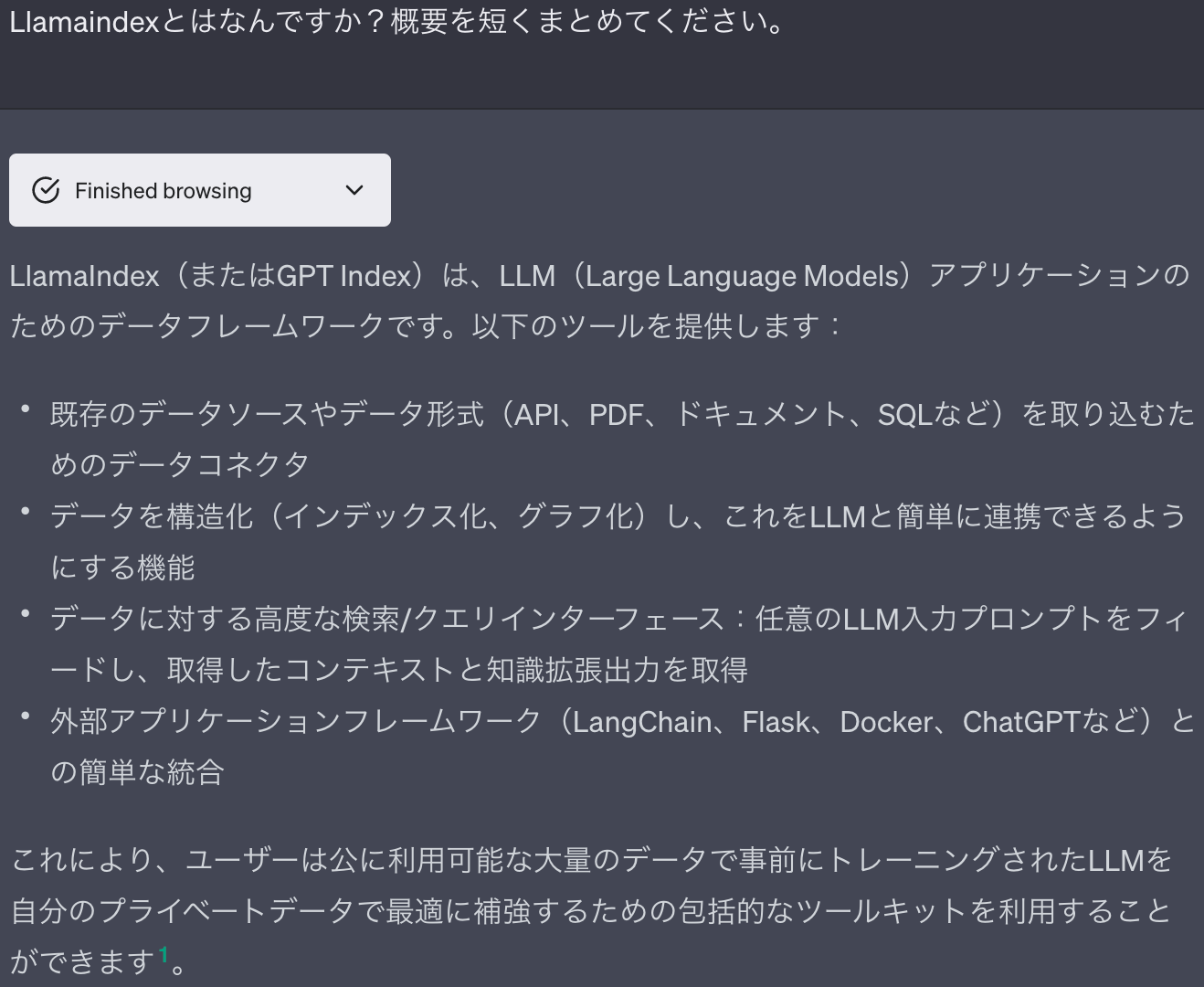
簡潔にまとめると、公のデータで学習されたLLMと独自に用意したデータとを円滑に繋ぐためのツールであることがわかります。
検証方法
データの準備
今回は、ChatGPTに出力してもらった架空のTech系ベンチャーで行われた架空の会議の議事録を用いることにします。
出力してもらったものをテキストファイルにコピー&ペーストしてデータの準備は完了です。
なお、今回用いるデータは以下のものです。


APIキーの取得
今回の検証ではOpenAIのAPI(有料)を用います。こちらのページにアクセスし"Create new secret key"というボタンからAPIキーを取得し、忘れずにメモしておきます。
ライブラリのインストール
今回はGoogle Colaboratoryを使って検証していきたいと思います。以下を実行してLlamaIndexをインストールします。
!pip install llama-index
APIキーの設定
先ほど取得したOpenAIのAPIキーを設定します。
import os
os.environ["OPENAI_API_KEY"] = "具体的なAPIキー"
インデックスの作成
データを読み込み・変換し、インデックスを作成しています。
また、先ほど作成したテキストデータは、"data"というフォルダを作成しその中に置いてあります。
from llama_index import SimpleDirectoryReader
from llama_index import GPTVectorStoreIndex
documents = SimpleDirectoryReader(input_dir="./data").load_data()
index = GPTVectorStoreIndex.from_documents(documents)
クエリエンジンの作成と質問応答
最後に、クエリエンジンを作成し、入力した質問に応答するBotの完成です。
query_engine = index.as_query_engine()
while True:
Q = input("Q: ")
if Q == "exit":
break
response = query_engine.query(Q)
answer = response.response
print("A: " + answer[1:])
検証結果
最後のセルを実行すると、以下のように質問を入力できるようになります。

いくつか質問を投げかけてみた回答を以下に貼り付けます。なお、"exit"と入力すると終了します。
Q: 今回の会議のメンバーは?
A: 今回の会議のメンバーは、CEO(鈴木)、CTO(佐藤)、CFO(田中)、CMO(高橋)、プロダクトマネージャー(中村)、ビジネス開発(山本)です。
Q: どんな結論になった?
A: 結論として、スマートシティへの進出を決定したことになりました。インフラ投資は大きな課題ですが、社会的影響力とブランドイメージの向上は大きな魅力であるということが確認されました。
Q: 最終的に誰がどんな役割を担うことになった?
A: CEO(鈴木)がプロジェクトを管理する役割を担い、CTO(佐藤)がAIとIoT技術の統合と最適化に全力を注ぐ役割を担い、CFO(田中)がパートナーシップや補助金を見つける役割を担い、CMO(高橋)がプロジェクトのマーケティングを担う役割を担うことになりました。
Q: エンタメ業界進出を提案したのは誰?
A: プロダクトマネージャー(中村)がエンタメ業界進出を提案したのです。
Q: フィンテックに進出する際に懸念されることは?
A: フィンテックに進出する際に懸念されることは、規制が厳しい業界であること、消費者の信頼を得るのが難しいこと、そしてリスク管理策を考える必要があることです。
Q: exit
「最終的に誰がどんな役割を担うことになった?」に対する回答では中村さんと山本さんがハブられていますが、その他の質問にはある程度の精度で回答してくれているように思います。
まとめ
今回の記事では、LlamaIndexを用いて作った議事録の質問回答botの検証についてご紹介しました。カスタマイズできる余地は多くありますが、それなりのパフォーマンスを発揮してくれたように思います。
今回の記事が皆様のご参考になれば幸いです。
NOVEL株式会社では、業務委託パートナーを募集しています。AIやLLMに興味があるエンジニアやPMの方、大歓迎です。副業としてでも問題ありませんので、ご興味を持たれた方はぜひこちらのフォームよりご応募ください。