Pythonのソースコードで利用できる文字コードについてチュートリアルにある記載とPEPにある記載をまとめます。
チュートリアルの記載について
Python3のチュートリアルでは上記に記載があり、PythonのソースコードはデフォルトではUTF-8でエンコードされているものとして扱われると記載されています。
またデフォルトエンコーディング以外のエンコーディングを利用する際は下記の書式で先頭行に記載すればよいようです。
(shebangを書く場合は、先頭行の次の行に記載する)
# -*- coding: encoding -*-
またencodingとして指定できる文字コードとしては下記ページにあるcodecsでサポートしている文字コードが指定できます。
PEPの記載について
PEPではソースコードで利用する文字コードについて下記に記載がありました。
- PEP 8 – Style Guide for Python Code
- PEP 263 – Defining Python Source Code Encodings
- PEP 3120 – Using UTF-8 as the default source encoding
PEP 3120ではPythonのデフォルトのソースエンコーディングはUTF8を利用するとあり、また歴史的な経緯も記載されています。
PEP 8のsource-file-encodingを見ると、標準ライブラリではutf-8を利用し、非ASCII文字は極力利用せずに、場所や人名のみに利用することが推奨されているようです。
PEP 263を見ると、ドキュメント上では# -*- coding: encoding -*-という書式と記載されていますが。
他の書き方も記載されています。
# coding=<encoding name>
#!/usr/bin/python
# -*- coding: <encoding name> -*-
#!/usr/bin/python
# vim: set fileencoding=<encoding name> :
Pythonではemacsやvimのエディタで設定できるコーディング指定も対応している事がわかります。
より正確には下記の正規表現にマッチすればよいと記載があります。
^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
ちなみにソースコードにBOMがついている場合は、許可される記載はUTF8のみになるようです。
If a source file uses both the UTF-8 BOM mark signature and a magic encoding comment, the only allowed encoding for the comment is ‘utf-8’. Any other encoding will cause an error.
#!/usr/bin/python3
# -*- coding: latin_1 -*-
print("Hello Encoding!")
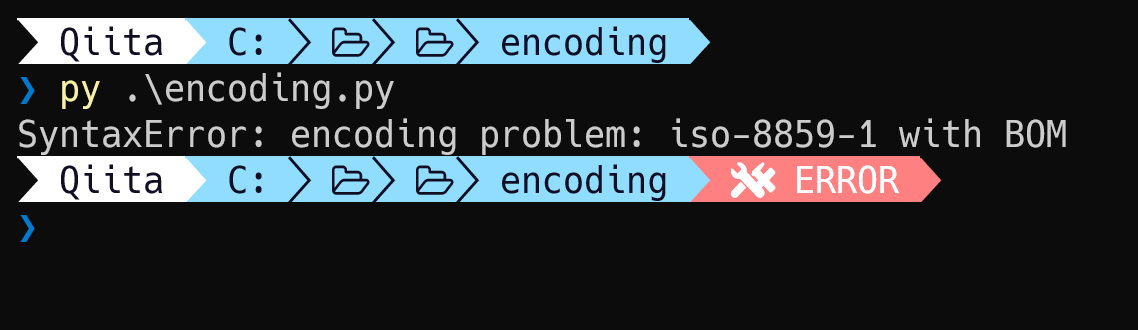
たとえば上記のような# -*- coding: latin_1 -*-でlatin_1を指定したencoding.pyをBOM付きUTF-8で保存して実行してみると下記のようにlatin_1(iso-8859-1)にBOMがついているとエラーとなりました。
まとめ
よくサンプルコードでshebangだったりこのエンコーディング指定をみかけますが。
意味合いを理解して利用したい所ではあります。