背景#
「SEO対策していく」という上長の発言により、自社と競合他社がGoogle検索でどの順位にいるかを調べて可視化するバッチ作成を頼まれた。
SEOという言葉すらよくわかっていなかったが、先輩がElastic SearchとKibanaを使っていたこともあり、挑戦してみることにした。Pythonで実装した理由は特にない。Pythonが好きだから、くらい。
ちなみに今回調査する会社は適当に、
「ドローンメーカー」にした。
理由は、最近ドローンに興味があるから。
環境#
Python : 3.8.3
Selenium : 3.141.0
Elastic Search : 7.10.1-SNAPSHOT
Kibana : 7.10.1
ElasticSearchに関しては、curl -XGET "http:localhost:9200"で返ってくるJsonの"number"より。
Kibanaに関しては、単純にkibana -Vで行けた。
準備#
- indexの作成用jsonを作成
- Elastic Search のインストール
- Kibana のインストール
- selenium, chromedriver-binary のインストール
- ElasticSearch, Kibanaを起動していく
実装#
ファイルは三つ作った。プログラムの流れとしては、
「 keyword.txt から調べたいキーワードを、domain.txt から調べたい競合他社のドメインを取得してrank_observer.py でゴニョゴニョする。そしてそれを CRON で自動化する 」
という感じ。
keyword.txt###
programmable drone
drone company
→キーワードはこんな感じで適当に選んだ。数が多ければ多いほど処理は遅くなる。
domain.txt###
www.dji.com
www.parrot.com
www.yuneec.com
www.kespry.com
www.skydio.com
www.insitu.com
www.delair.aero
www.ehang.com
→ドメインに関しては、「ドローンメーカー おすすめ10選」的なサイトの上から数個を選んだ。
これらのメーカー(ドメイン?)が時系列で検索順位をどう変化させていくかを調査する。
rank_observer.py###
import datetime
import os
import traceback
import smtplib
from lxml import html
import unicodedata
from selenium import webdriver
import chromedriver_binary
from selenium.webdriver.chrome.options import Options
from elasticsearch import Elasticsearch
# Chromeに接続して引数で検索する
def search(driver, word):
driver.get("https://www.google.com")
search = driver.find_element_by_name('q')
search.send_keys(word)
search.submit()
return driver.page_source
# 最初の1ページをパース
def analyze(source):
path_to_link = "//div[@class='yuRUbf']/a/@href"
root = html.fromstring(source)
# アドレスの入ったリストを返す
address = root.xpath(path_to_link)
return address
# 検索後の一覧表示ページ下部にある「次へ」ボタンのリンク先へ飛んで、飛んだ先のリンクを返す
def next_page_source(source, driver):
path_to_next_page = "//td[@class='d6cvqb']/a[@id='pnnext']/@href"
root = html.fromstring(source)
address = root.xpath(path_to_next_page)
if address is None:
return 0
else:
driver.get("https://www.google.com/" + str(address[0]))
return driver.page_source
# 検索結果をcsvファイルとして書き出す
def write(filename, keyword, line, i):
today = datetime.datetime.today()
path = "./data/"
Y = str(today.year) + "/"
M = str(today.month)
MM = M.zfill(2) + "/"
if os.path.exists(path + Y):
if os.path.exists(path + Y + MM):
with open(os.path.abspath(path + Y + MM + keyword + ".csv"), "a") as f:
f.write(str(int(i)+1)+","+line+"\n")
else:
os.makedirs(path + Y + MM)
with open(os.path.abspath(path + Y + MM + keyword + ".csv"), "a") as f:
f.write(str(int(i)+1)+","+line+'\n')
else:
os.makedirs(path + Y)
if os.path.exists(path + Y + MM):
with open(os.path.abspath(path + Y + MM + keyword + ".csv"), "a") as f:
f.write(str(int(i)+1)+","+line+"\n")
else:
os.makedirs(path + Y + MM)
with open(os.path.abspath(path + Y + MM + keyword + ".csv"), "a") as f:
f.write(str(int(i)+1)+","+line+'\n')
# 調べたいキーワードが書かれたテキストファイルからキーワードを取得
def get_keyword():
with open("./keyword.txt", "r", encoding="utf-8") as f:
line = f.read()
keyword = line.splitlines()
return keyword
# 調べたいドメインが書かれたテキストファイルからドメインを取得
def get_domain():
with open("./domain.txt", "r", encoding="utf-8") as f:
line = f.read()
domain = line.splitlines()
return domain
# ドメインリストに乗っているアドレスだけ返す
def check_domain(address, domain):
ok = False
for d in domain:
if d in address:
ok = True
return ok
# ドメインと順位を紐づけるために辞書形に変更
# args = {
# "address" : リンクのリスト, list
# "page_num": 現在のページ数, int
# "keyword" : キーワード, string
# "date" : 日付, date
# "domain" : 指定したドメイン,list
# }
def sophisticate_data(address, page_num, keyword, date, domain):
address_list = []
if len(address) != 0:
for i, content in enumerate(address):
address_dict = {}
# リンクが指定ドメインの中にあるか
print(content, domain)
print(check_domain(content, domain))
if check_domain(content, domain):
# ページ数×10+アドレスの順で検索順位を算出
address_dict["keyword"] = keyword
address_dict["rank"] = i + page_num*10 + 1
address_dict["domain"] = content
address_dict["date"] = date
address_list.append(address_dict)
return address_list
# 上記関数を使用して、キーワード毎に指定したドメインの検索順位を取得する
def parse():
data = []
# キーワードとドメインをセット
keyword = get_keyword()
domain = get_domain()
date = datetime.datetime.today().strftime("%Y/%m/%d")
dir_title = datetime.datetime.today().strftime("%Y_%m_%d")
# どのくらいページ移動するか。1ページ大体10件ある
page_num = 5
for kw in keyword:
time.sleep(10)
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
# 検索欄にキーワードを入れて検索した後に現れる結果画面のソース
source = search(driver, kw)
address = analyze(source)
results = sophisticate_data(address, 0, kw, date, domain)
# 指定したページ数の分だけページを読み込む
for i in range(1,page_num-1):
next_source = next_page_source(source, driver)
if next_page_source == 0:
break
results.extend(sophisticate_data(analyze(next_source), i, kw, date, domain))
source = next_source
time.sleep(10)
driver.quit()
# ファイルに保存
filename = datetime.datetime.today().strftime("%Y_%m_%d") + "_" + kw
for item in results:
write(filename, item["keyword"], str(item["domain"]), item["rank"])
results = sorted(results, key=lambda x:x["rank"])
data.extend(results)
# ここからElasticSearch
# keyword 毎にデータを書き込む
client = Elasticsearch("http://localhost:9200")
for d in data:
body = {}
body["keyword"] = d["keyword"]
body["ranking"] = d["rank"]
body["target_domain"] = d["domain"]
body['get_date'] = d["date"]
client.index(index='sample_index', body=body)
# メール送る
def send_mail(exception, error=True):
program = "rank_observer.py"
FROM = 'error_detecter@sample.xyz'
# 通知先のメアドを設定
TO = ['sample@sample.com']
if error == False:
SUBJECT = f"{exception}"
TEXT = f"{exception}"
else:
SUBJECT = u'エラーを検知しました。'
TEXT = f'監視サーバ内の {program} にて以下のエラーを検知しました。ログ等をご確認ください。\n\n {exception}'
message = "Subject: {}\n\n{}".format(SUBJECT, TEXT)
s = smtplib.SMTP()
s.connect()
s.sendmail(FROM, TO, message.encode("utf-8"))
s.close()
# 実行
# 例外処理
try:
parse()
except Exception as e:
# エラー時のみメール送信
send_mail(traceback.format_exc())
可読性、、いずこに、、って感じのコードだけどコメントアウト多めにすることで先輩のチェックをpassした汗
エラーがあればメールを送るようにした。
あと、これをコピーしても動くかは分からない。パスとかメアドをいじれば大丈夫とはおもう。
0 1 * * * sudo python3 ~/path/to/rank_observer.py >> ~/path/to/data/log.log 2>&1
↑これはcrontabの中身。毎日深夜一時にプログラムを回してくれる。例外のスタックとレースをlog.logっていう可笑しな名前のログファイルに随時書き込ませるようにした。
エラー#
1、elasticsearch.exceptions.SSLError [SSL:WROMG_VERSION_NUMBER]
このエラーが出てきたことはログで明らかなんだけど、どうfixしたか忘れてしまった汗。たしか、
client = Elasticsearch("http://localhost:9200")
ここでSSLに関する引数を消した気がする。use_ssl=Trueだったような、、。
2、ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed:
が一生出てきてchromedriver-binaryをインストールできなかったが、この記事で行けた。
備考#
冗長な書き方だと自分でも思うのでリーダブルコード熟読すべしかと。
次は、別のBIツールor自作して株価の研究もしてみたい。
Kibana でどうやって可視化するかは割愛。イメージ画像だけ載せとく。
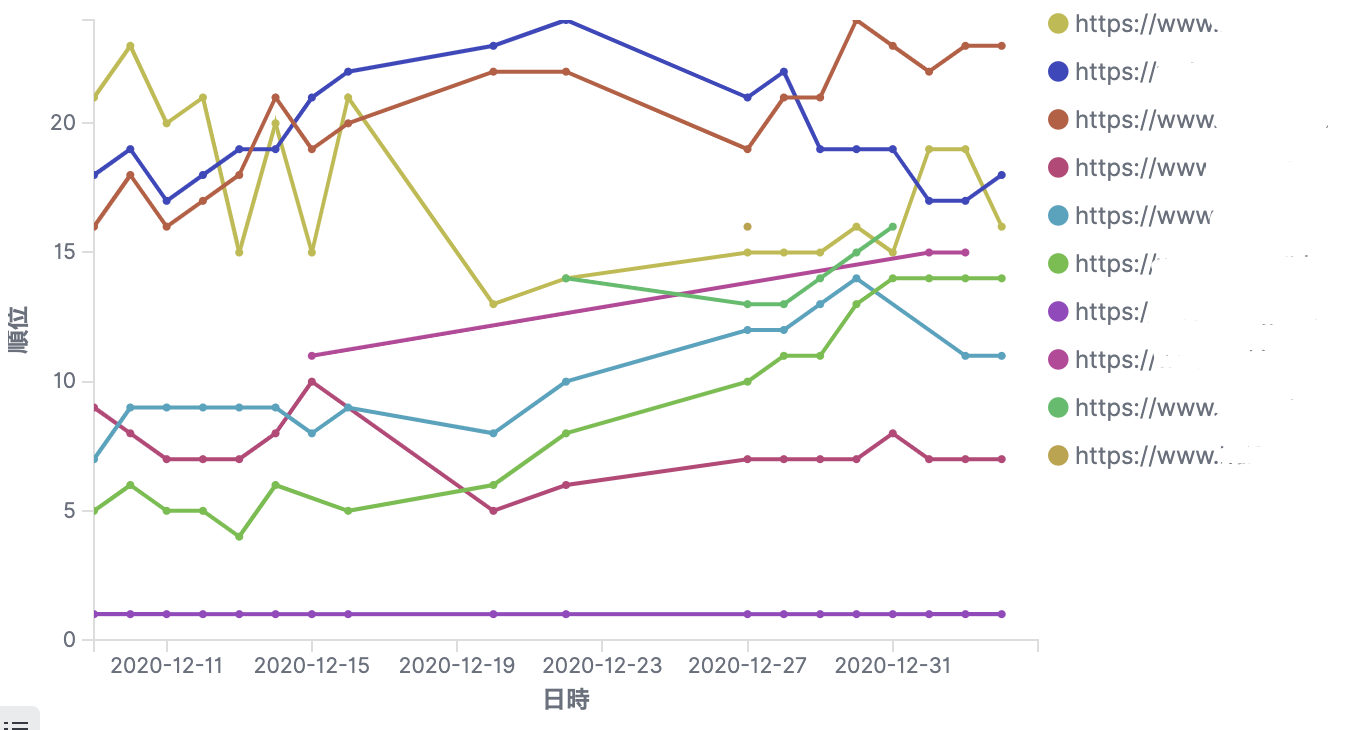
どのメーカーが最近検索順位高いとか低いとかがわかる。これでSEO対策の足掛かりになる、のかもしれない。