概要
システムを運用していると、様々なトラブルが発生する。
サーバのレスポンスが突如遅くなり、その原因を突き詰めるということはインフラエンジニアとして日用茶飯事。
また、トラブルシューティングの方法はエンジニアによって様々だったりする。
自分の場合は
- dstatコマンドでリソース状況を大雑把に確認
- topコマンドでCPU/メモリー毎にソート
- psコマンドでプロセスの状態を確認
- netstatで状態確認
という順番で調査するようにしている。
このように調査することにより、
遠くからどこが問題なのかざっくり見つつ、
問題を突き止めることが比較的容易になるからだ。
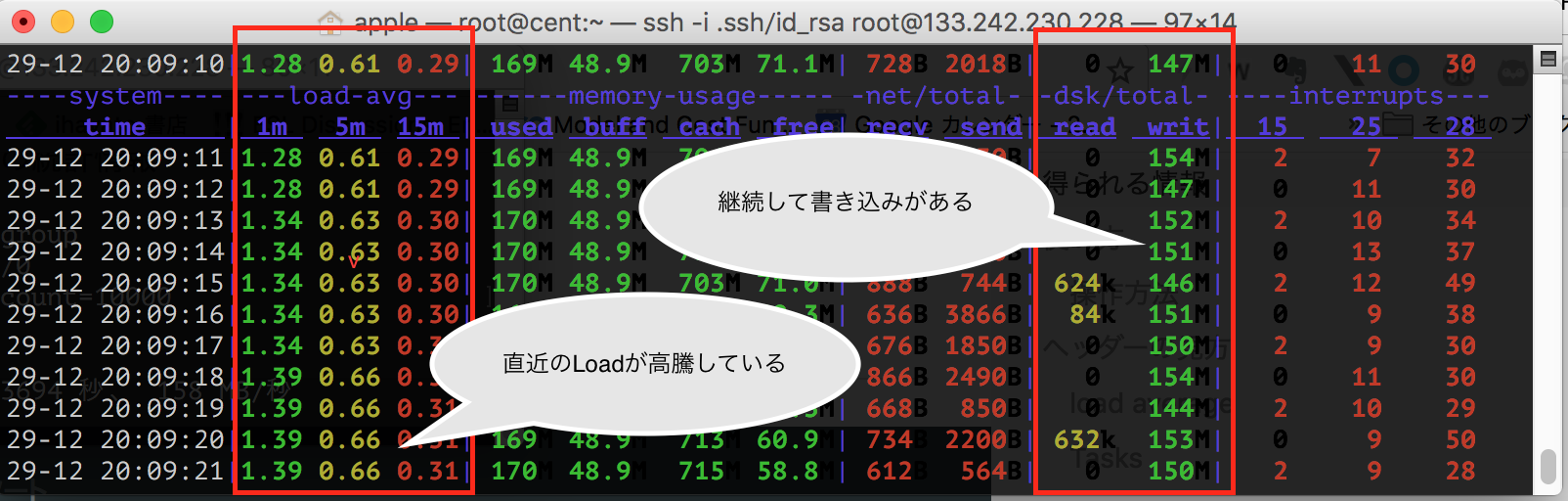
dstatコマンドでリソース状況を大雑把に確認
とりあえず最低限必要な情報を表示する。
dstat -tlmnd
| オプション | 意味 |
|---|---|
| -t | 時間 |
| -l | Load Average |
| -m | Memory |
| -n | Network |
| -d | Disk IO |
状況によっては割り込み回数など、もっと深く見ることも可能。
ただしdstatの場合は横に広がってしまうので(ターミナルの設定次第だけど)
自分は通常はこの程度の出力のみに止めている。
ちなみにLoad averageに限って言うと、負荷のかかる原因は大きく2つある。
- 処理がそもそも重い
- Disk IOがかかっている。
Load averageが高騰している場合は、この点を真っ先に疑う。
topコマンドでCPU/メモリー毎にソート
topコマンドはデフォルトで利用されているCPU順に表示される

CPU/メモリーを利用されている状況に応じて切り替える。
topコマンドの状態でshift+mでメモリー順にソートへ切り替わる。

再度CPU順にソートする場合はshift+p
psコマンドでプロセスの状態を確認する
topコマンドで見つけた怪しそうなプロセスを確認する
psコマンドはエンジニアの中でも、-efオプション派か、auxオプション派かに分かれる(気がする)。
ps -ef
ps aux

見比べてみると、
ps -efの場合は簡易的に
- プロセス番号
- 経過時間
- コマンド
程度はわかるものの、プロセスが消費しているリソースの中身まではわからない。
ps auxオプションの場合、プロセス毎のリソース消費状態がわかる。
[root@cent ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 25172 25063 20 20:34 pts/1 00:00:01 dd if=/dev/zero of=1G.dummy bs=1
root 25174 25159 0 20:34 pts/0 00:00:00 ps -ef
[root@cent ~]#
[root@cent ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 25180 16.3 0.1 108984 1668 pts/1 R+ 20:37 0:06 dd if=/dev/zero of=1G.dummy bs=1M count=10000
root 25189 0.0 0.0 112676 976 pts/0 R+ 20:38 0:00 grep -E --color=auto dd|RSS
[root@cent ~]#
-efオプションにはなく、auxオプションで見れる有益な情報はこの点。

VSZ
仮想メモリーの使用サイズ(キロバイト表示)
RSS
物理メモリーの使用サイズ(キロバイト表示)
物理メモリーと仮想メモリーの違い
- 物理メモリー
物理的にサーバに搭載されたメモリー。
直接プロセスが使うことはない。
もしプロセスが直接、物理メモリーを使ってしまうと、アドレスの変更が頻繁に発生してしまう。
複数のプロセスが開始・終了を繰り返した結果、断片化されたメモリーを使わなければならなくなってしまう。
- 仮想メモリー
すべてのプロセスに独立したメモリーを割り当てる機能。
なお、物理メモリと仮想メモリーの紐付けをページテーブルという機能で行っている。
この機能により、プロセスは他の処理に影響されないようになっている。
STAT
プロセスのステータス
このステータスは主に以下のステータスがある。
| 記号 | 状態 | 説明 |
|---|---|---|
| R | 実行(可能)状態 | CPU時間割り当てしている段階。もしくは実行中。 |
| D | 待機状態 | IO完了待ち。割り込み不能 |
| S | 待機状態 | スリープ状態。割り込み可能 |
| T | 停止状態 | STOPシグナル受信。終了処理中。 |
| W | Swap out | 実メモリーに存在しない |
| Z | ゾンビ状態 | プロセスは完了したが、残っている状態 |
実行を終了したプロセスはゾンビ状態になる。
その後、子プロセスは(というかLinuxカーネルは)、終了したプロセスの親プロセスに対してSIGCHLD(CHLD)シグナルを送信する。
親プロセスがwait()関数で子プロセスの終了を待っている場合、ここで初めてwaitから抜けてることができ、ゾンビ化した子プロセスは終了する。
親プロセスに何らかの問題があり子プロセスを終了できない場合、子プロセスはゾンビ状態のままとなる。
通常は、子プロセスが無くなってから、親プロセスが無くなる。
しかし、子プロセスより先に親プロセスが無くなってしまった場合は
Linuxが最初に起動されるプロセス /sbin/init が引き継ぐ。
親と子プロセスを視覚化
ps axwfオプションを使うことで、
何が親となっていて子プロセスが派生しているのか見ることも可能。
root@558aa0d3fa66:/# ps axwf
PID TTY STAT TIME COMMAND
1 pts/0 Ss 0:00 /usr/bin/python3 -u /sbin/my_init -- bash -l
10 pts/0 S 0:00 /usr/sbin/syslog-ng --pidfile /var/run/syslog-ng.pid -F --no-caps
16 pts/0 S 0:00 /usr/bin/runsvdir -P /etc/service
18 ? Ss 0:00 \_ runsv cron
20 ? S 0:00 | \_ /usr/sbin/cron -f
19 ? Ss 0:00 \_ runsv sshd
17 pts/0 S 0:00 bash -l
32 pts/0 R+ 0:00 \_ ps axwf
root@558aa0d3fa66:/#
netstatで確認
WEBサーバが動いていて、外部からの接続がボトルネックとして考えられる時、
プロセスに加え、netstatで各接続の状態を確認する事がある
netstat -an
オプションの意味は以下の通り。
| オプション | 意味 |
|---|---|
| -a | 全てのアクティブなソケットを表示する |
| -n | ホストやユーザーの名前解決を行わず数字のまま出力する |

赤枠がTCPの状態になる。
| 状態 | 意味 |
|---|---|
| LISTEN | TCPモジュールはリモートホストからのコネクション要求待ち |
| ESTABLISHED | データ転送が行える通常の状態 |
| CLOSING | リモートホストからのコネクション終了要求待ち |
| TIME-WAIT | コネクション終了要求応答確認待ち |
| CLOSED | 終了 |
ステータス状態の詳細はこちら
https://qiita.com/mogulla3/items/196124b9fb36578e5c80
犯人の特定
今回の場合は、ddコマンドでこの処理が負荷を上げていたということにたどり着く。

ユーザー毎の使っているCPU使用率を表示
psコマンドを元にawsで成形することにより、各ユーザーのCPU使用率をまとめて計算することも可能。
ps aux | awk '{ if(NR>1){p[$1] += $3; n[$1]++} }END{for(i in p) print p[i], n[i], i}'
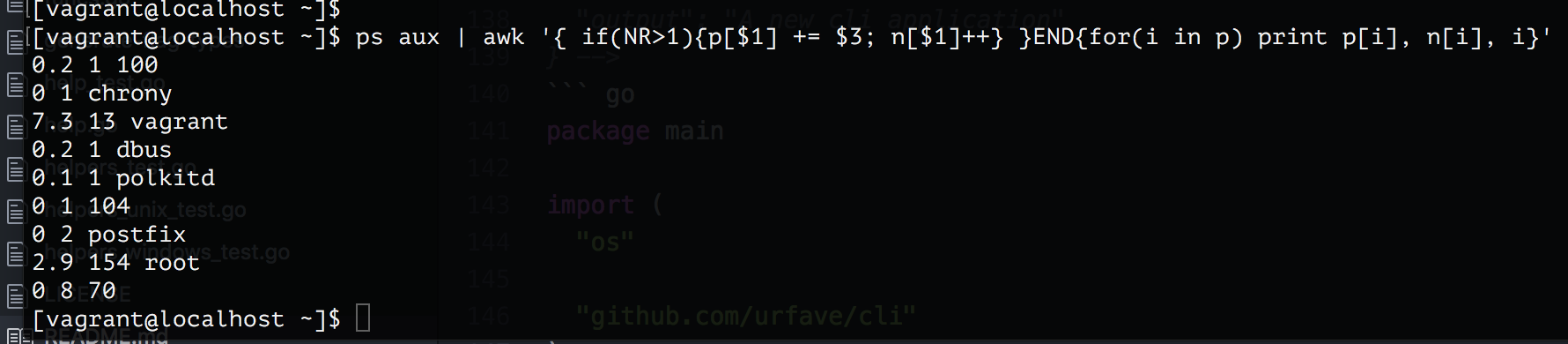 3桁目はCPUだが、4桁目を指定するとメモリーになる。
3桁目はCPUだが、4桁目を指定するとメモリーになる。
ps aux | awk '{ if(NR>1){p[$1] += $4; n[$1]++} }END{for(i in p) print p[i], n[i], i}'
